Bekräfta transformering i dataflödesmappning
GÄLLER FÖR: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Dricks
Prova Data Factory i Microsoft Fabric, en allt-i-ett-analyslösning för företag. Microsoft Fabric omfattar allt från dataflytt till datavetenskap, realtidsanalys, business intelligence och rapportering. Lär dig hur du startar en ny utvärderingsversion kostnadsfritt!
Dataflöden är tillgängliga både i Azure Data Factory och Azure Synapse Pipelines. Den här artikeln gäller för mappning av dataflöden. Om du är nybörjare på transformeringar kan du läsa den inledande artikeln Transformera data med hjälp av ett mappningsdataflöde.
Med Assert-omvandlingen kan du skapa anpassade regler i dina mappningsdataflöden för datakvalitet och dataverifiering. Du kan skapa regler som avgör om värden uppfyller en förväntad värdedomän. Dessutom kan du skapa regler som söker efter rad unikhet. Assert-omvandlingen hjälper till att avgöra om varje rad i dina data uppfyller en uppsättning kriterier. Med Assert-transformering kan du också ange anpassade felmeddelanden när dataverifieringsregler inte uppfylls.
Konfiguration
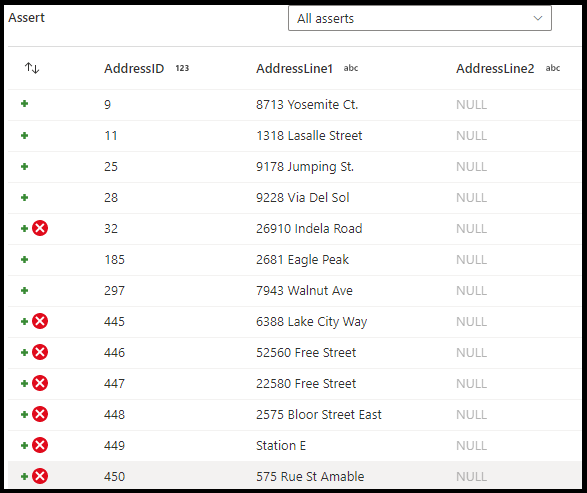
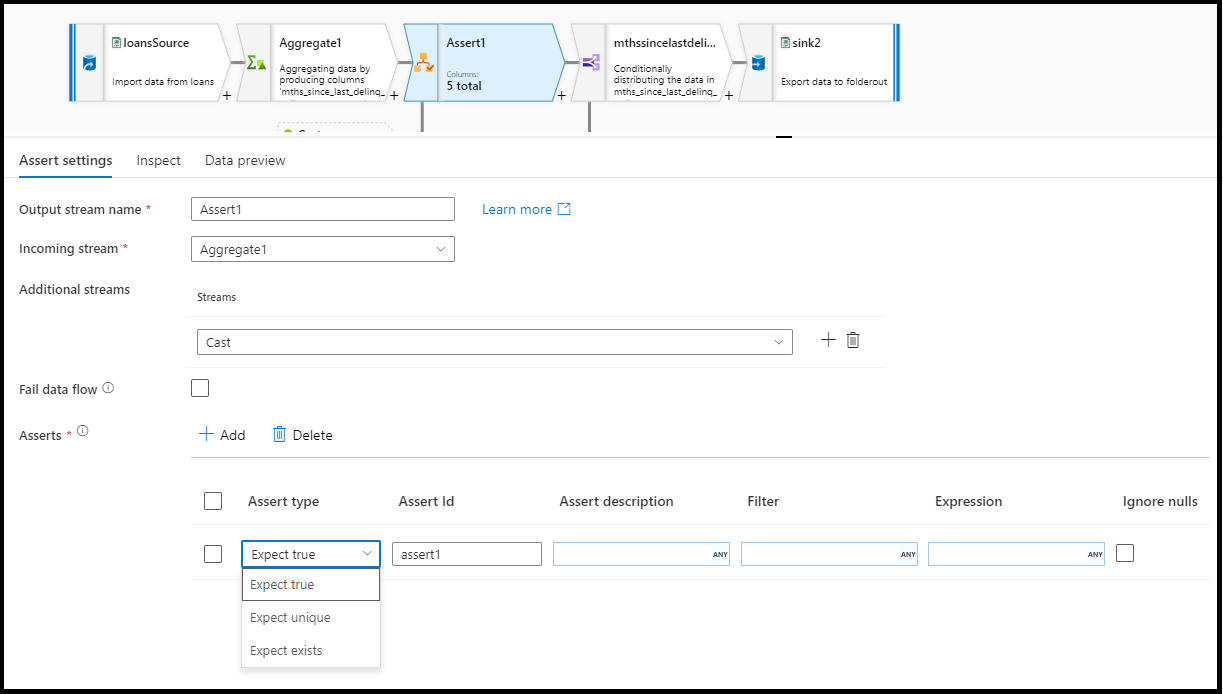
I konfigurationspanelen för kontrollomvandling väljer du typen av kontroll, anger ett unikt namn för försäkran, valfri beskrivning och definierar uttrycket och det valfria filtret. Fönstret för förhandsgranskning av data anger vilka rader som misslyckades med dina kontroller. Dessutom kan du testa varje radtagg nedströms med hjälp av isError() och hasError() för rader som inte har kontrollerats.
Kontrolltyp
- Förvänta dig sant: Resultatet av uttrycket måste utvärderas till ett booleskt sant resultat. Använd den här inställningen för att verifiera domänvärdeintervall i dina data.
- Förvänta dig unik: Ange en kolumn eller ett uttryck som en unikhetsregel i dina data. Använd den här inställningen om du vill tagga dubbletter av rader.
- Förvänta finns: Det här alternativet är bara tillgängligt när du valde en andra inkommande ström. Finns tittar på båda strömmarna och avgör om raderna finns i båda strömmarna baserat på kolumnerna eller de uttryck som du har angett. Om du vill lägga till den andra strömmen för finns väljer du
Additional streams.
Dataflöde vid fel
Välj fail data flow om du vill att dataflödesaktiviteten ska misslyckas omedelbart så snart kontrollregeln misslyckas.
Assert ID
Assert ID är en egenskap där du anger ett (sträng)-namn för din försäkran. Du kan använda identifieraren senare nedströms i dataflödet med hjälp av hasError() eller för att mata ut koden för kontrollfel. Kontroll-ID:t måste vara unika i varje dataflöde.
Kontrollbeskrivning
Ange en strängbeskrivning för din försäkran här. Du kan även använda uttryck och radkontextkolumnvärden här.
Filtrera
Filter är en valfri egenskap där du endast kan filtrera försäkran till en delmängd rader baserat på uttrycksvärdet.
Uttryck
Ange ett uttryck för utvärdering för var och en av dina påståenden. Du kan ha flera kontroller för varje kontrollomvandling. Varje typ av försäkran kräver ett uttryck som ADF måste utvärdera för att testa om försäkran har godkänts.
Ignorera NULLL:er
Som standard innehåller kontrollomvandlingen NULL:er i radkontrollutvärderingen. Du kan välja att ignorera NULLL:er med den här egenskapen.
Fel med direkt kontrollrad
När en försäkran misslyckas kan du också dirigera dessa felrader till en fil i Azure med hjälp av fliken Fel i mottagartransformeringen. Du har också ett alternativ för mottagartransformeringen att inte mata ut rader med kontrollfel alls genom att ignorera felrader.
Exempel
source(output(
AddressID as integer,
AddressLine1 as string,
AddressLine2 as string,
City as string,
StateProvince as string,
CountryRegion as string,
PostalCode as string,
rowguid as string,
ModifiedDate as timestamp
),
allowSchemaDrift: true,
validateSchema: false,
isolationLevel: 'READ_UNCOMMITTED',
format: 'table') ~> source1
source(output(
CustomerID as integer,
AddressID as integer,
AddressType as string,
rowguid as string,
ModifiedDate as timestamp
),
allowSchemaDrift: true,
validateSchema: false,
isolationLevel: 'READ_UNCOMMITTED',
format: 'table') ~> source2
source1, source2 assert(expectExists(AddressLine1 == AddressLine1, false, 'nonUS', true(), 'only valid for U.S. addresses')) ~> Assert1
Dataflödesskript
Exempel
source1, source2 assert(expectTrue(CountryRegion == 'United States', false, 'nonUS', null, 'only valid for U.S. addresses'),
expectExists(source1@AddressID == source2@AddressID, false, 'assertExist', StateProvince == 'Washington', toString(source1@AddressID) + ' already exists in Washington'),
expectUnique(source1@AddressID, false, 'uniqueness', null, toString(source1@AddressID) + ' is not unique')) ~> Assert1
Relaterat innehåll
- Använd Välj transformering för att välja och verifiera kolumner.
- Använd transformering av härledda kolumner för att transformera kolumnvärden.