Transformera data från en SAP ODP-källa med hjälp av SAP CDC-anslutningsappen i Azure Data Factory eller Azure Synapse Analytics
GÄLLER FÖR:  Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Dricks
Prova Data Factory i Microsoft Fabric, en allt-i-ett-analyslösning för företag. Microsoft Fabric omfattar allt från dataflytt till datavetenskap, realtidsanalys, business intelligence och rapportering. Lär dig hur du startar en ny utvärderingsversion kostnadsfritt!
Den här artikeln beskriver hur du använder mappning av dataflöde för att transformera data från en SAP ODP-källa med hjälp av SAP CDC-anslutningsappen. Mer information finns i introduktionsartikeln för Azure Data Factory eller Azure Synapse Analytics. En introduktion till att transformera data med Azure Data Factory och Azure Synapse-analys finns i mappning av dataflöde eller självstudien om att mappa dataflöde.
Dricks
Information om det övergripande stödet för SAP-dataintegrering finns i SAP-dataintegrering med hjälp av Azure Data Factory white paper med detaljerad introduktion till varje SAP-anslutningsapp, jämförelse och vägledning.
Funktioner som stöds
Den här SAP CDC-anslutningsappen stöds för följande funktioner:
| Funktioner som stöds | IR |
|---|---|
| Mappa dataflöde (källa/-) | (1), (2) |
(1) Azure Integration Runtime (2) Lokalt installerad integrationskörning
Den här SAP CDC-anslutningsappen använder SAP ODP-ramverket för att extrahera data från SAP-källsystem. En introduktion till lösningens arkitektur finns i Introduktion och arkitektur till SAP Change Data Capture (CDC) i vårt SAP-kunskapscenter.
SAP ODP-ramverket finns i alla uppdaterade SAP NetWeaver-baserade system, inklusive SAP ECC, SAP S/4HANA, SAP BW, SAP BW/4HANA, SAP LT Replication Server (SLT). Krav och lägsta nödvändiga versioner finns i Krav och konfiguration.
SAP CDC-anslutningsappen stöder grundläggande autentisering eller säker nätverkskommunikation (SNC), om SNC har konfigurerats.
Aktuella begränsningar
Här är de aktuella begränsningarna för SAP CDC-anslutningsappen i Data Factory:
- Du kan inte återställa eller ta bort ODQ-prenumerationer i Data Factory (använd transaktions-ODQMON i det anslutna SAP-systemet för detta ändamål).
- Du kan inte använda SAP-hierarkier med lösningen.
Förutsättningar
Om du vill använda den här SAP CDC-anslutningsappen läser du Krav och konfiguration för SAP CDC-anslutningsappen.
Kom igång
Om du vill utföra aktiviteten Kopiera med en pipeline kan du använda något av följande verktyg eller SDK:er:
- Verktyget Kopiera data
- Azure-portalen
- The .NET SDK
- The Python SDK
- Azure PowerShell
- REST-API:et
- Azure Resource Manager-mallen
Skapa en länkad tjänst för SAP CDC-anslutningsappen med hjälp av användargränssnittet
Följ stegen som beskrivs i Förbereda den länkade SAP CDC-tjänsten för att skapa en länkad tjänst för SAP CDC-anslutningsappen i Azure Portal användargränssnittet.
Egenskaper för datauppsättning
Om du vill förbereda en SAP CDC-datauppsättning följer du Förbereda SAP CDC-källdatauppsättningen.
Transformera data med SAP CDC-anslutningsappen
Det råa SAP ODP-ändringsflödet är svårt att tolka och att uppdatera det korrekt till en mottagare kan vara en utmaning. Till exempel måste tekniska attribut som är associerade med varje rad (t.ex. ODQ_CHANGEMODE) förstås för att ändringarna ska tillämpas korrekt på mottagaren. Dessutom kan ett extrahering av ändringsdata från ODP innehålla flera ändringar av samma nyckel (till exempel samma försäljningsorder). Det är därför viktigt att respektera ordningen på ändringar, samtidigt som du optimerar prestanda genom att bearbeta ändringarna parallellt. Dessutom kräver hantering av ett flöde för insamling av ändringsdata också att hålla reda på tillstånd, till exempel för att tillhandahålla inbyggda mekanismer för felåterställning. Azure Data Factory-mappning av dataflöden tar hand om alla sådana aspekter. Därför är SAP CDC-anslutningen en del av dataflödesmiljön för mappning. Användarna kan därför koncentrera sig på den omvandlingslogik som krävs utan att behöva bry sig om den tekniska informationen om dataextrahering.
Kom igång genom att skapa en pipeline med ett mappningsdataflöde.
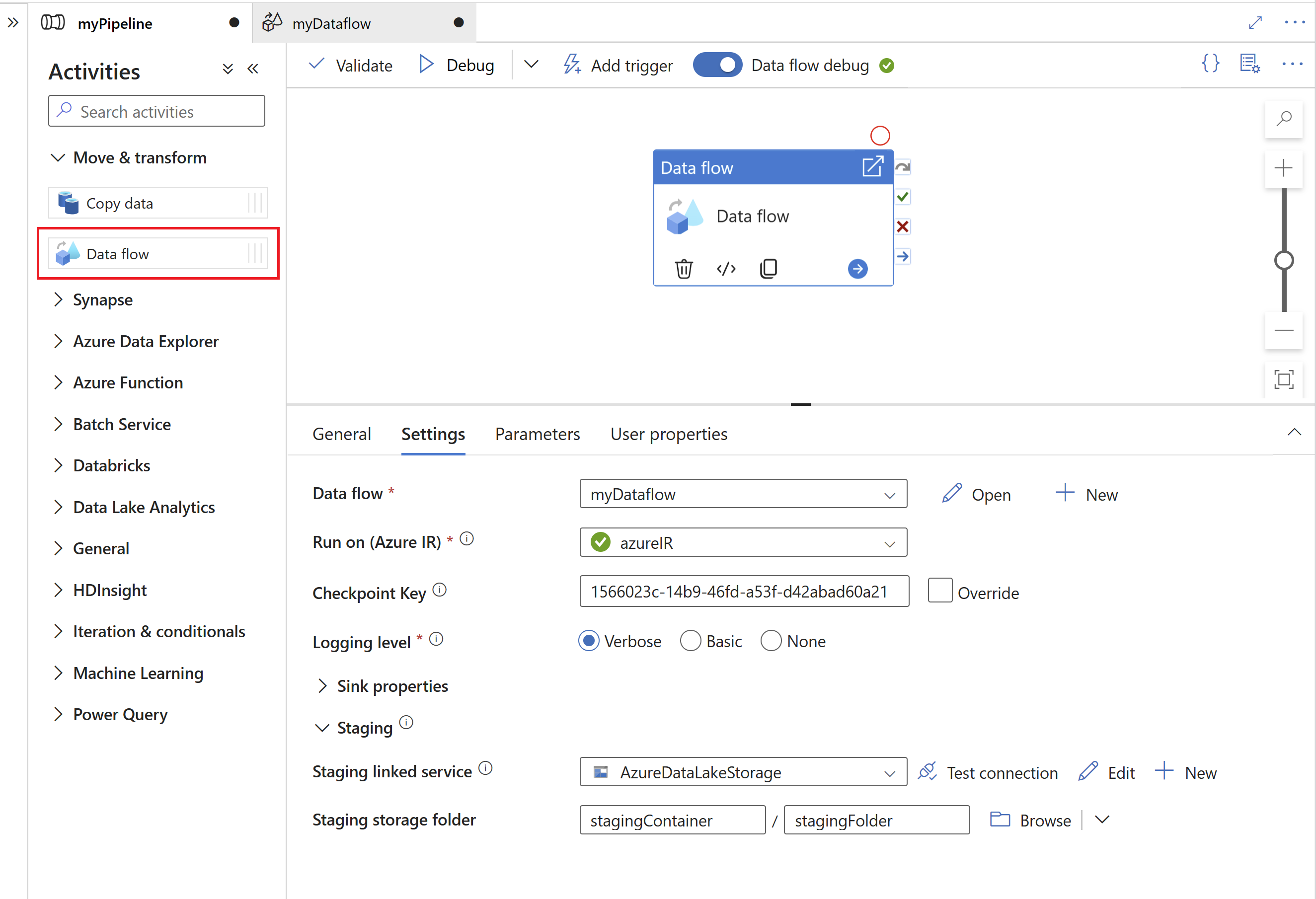
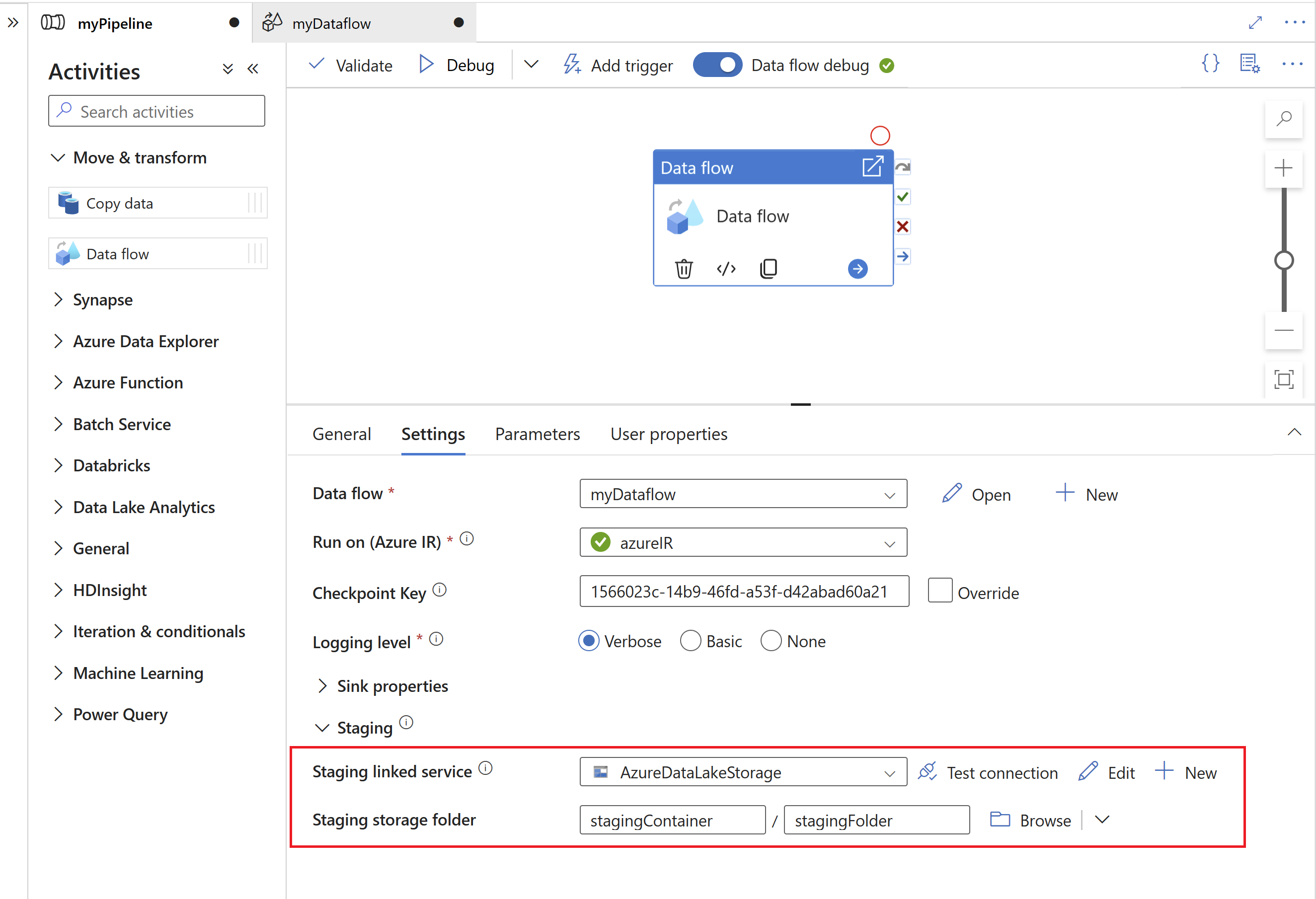
Ange sedan en mellanlagringslänkad tjänst och mellanlagringsmapp i Azure Data Lake Gen2, som fungerar som en mellanliggande lagring för data som extraheras från SAP.
Kommentar
- Den länkade mellanlagringstjänsten kan inte använda en lokalt installerad integrationskörning.
- Mellanlagringsmappen bör betraktas som en intern lagring av SAP CDC-anslutningsappen. För ytterligare optimeringar av SAP CDC-körningen kan implementeringsinformationen, som filformatet som används för mellanlagringsdata, ändras. Därför rekommenderar vi att du inte använder mellanlagringsmappen för andra syften, t.ex. som källa för andra kopieringsaktiviteter eller mappning av dataflöden.
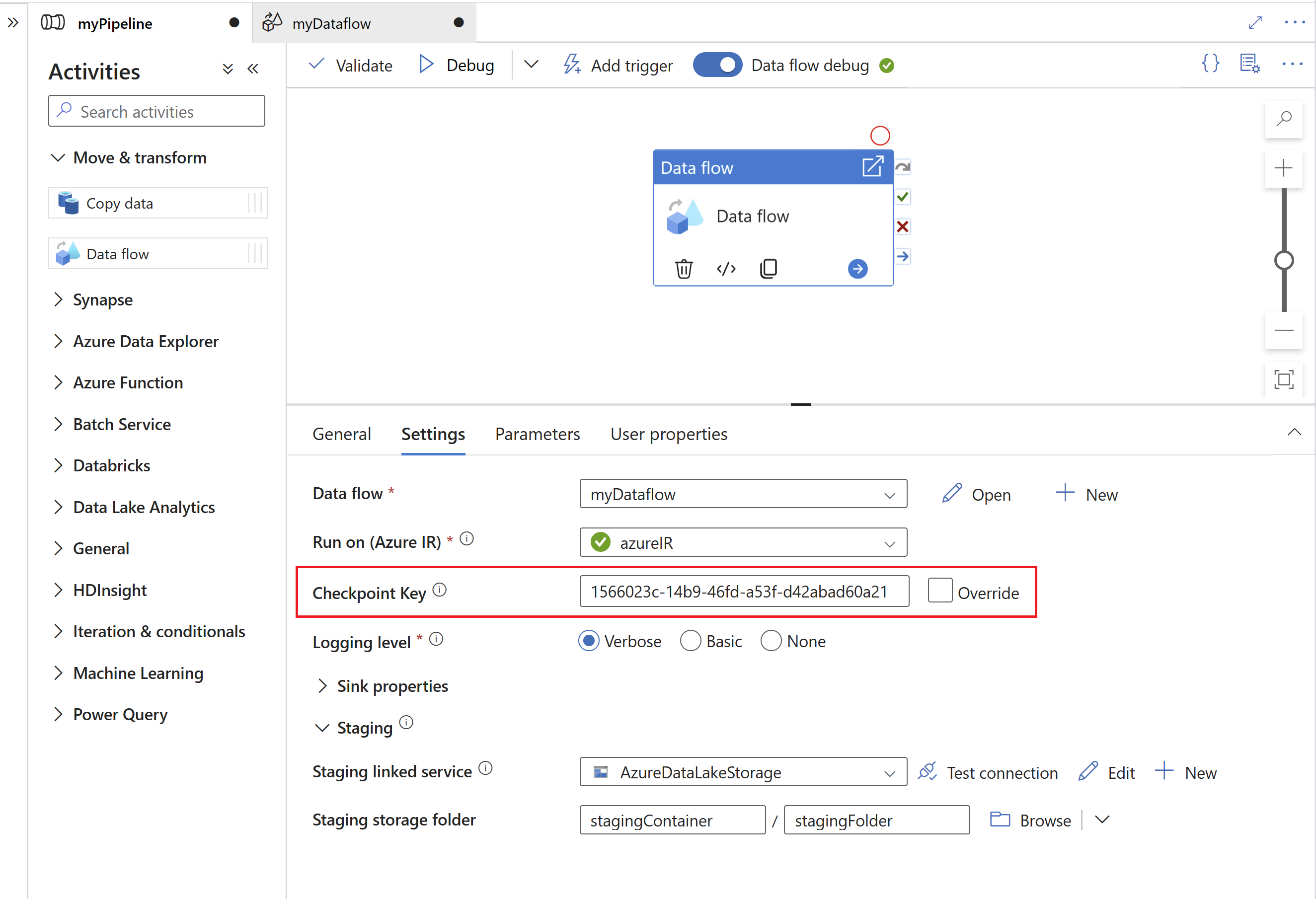
Kontrollpunktsnyckeln används av SAP CDC-körningen för att lagra statusinformation om processen för insamling av ändringsdata. Detta gör till exempel att SAP CDC-mappning av dataflöden automatiskt kan återställas från felsituationer, eller veta om en ändringsdatainsamlingsprocess för ett visst dataflöde redan har upprättats. Det är därför viktigt att använda en unik kontrollpunktsnyckel för varje källa. Annars skrivs statusinformationen för en källa över av en annan källa.
Kommentar
- För att undvika konflikter genereras ett unikt ID som kontrollpunktsnyckel som standard.
- När du använder parametrar för att utnyttja samma dataflöde för flera källor ska du parametrisera kontrollpunktsnyckeln med unika värden per källa.
- Egenskapen Kontrollpunktsnyckel visas inte om körningsläget i SAP CDC-källan har angetts till Full vid varje körning (se nästa avsnitt), eftersom det i det här fallet inte upprättas någon process för insamling av ändringsdata.
Parameteriserade kontrollpunktsnycklar
Kontrollpunktsnycklar krävs för att hantera statusen för ändringsdatainsamlingsprocesser. För effektiv hantering kan du parametrisera kontrollpunktsnyckeln för att tillåta anslutningar till olika källor. Så här kan du implementera en parametriserad kontrollpunktsnyckel:
Skapa en global parameter för att lagra kontrollpunktsnyckeln på pipelinenivå för att säkerställa konsekvens mellan körningar:
"parameters": { "checkpointKey": { "type": "string", "defaultValue": "YourStaticCheckpointKey" } }Ange kontrollpunktsnyckeln programmatiskt för att anropa pipelinen med önskat värde varje gång den körs. Här är ett exempel på ett REST-anrop med hjälp av den parametriserade kontrollpunktsnyckeln:
PUT https://management.azure.com/subscriptions/{subscriptionId}/resourceGroups/{resourceGroupName}/providers/Microsoft.DataFactory/factories/{factoryName}/pipelines/{pipelineName}?api-version=2018-06-01 Content-Type: application/json { "properties": { "activities": [ // Your activities here ], "parameters": { "checkpointKey": { "type": "String", "defaultValue": "YourStaticCheckpointKey" } } } }
Mer detaljerad information finns i Avancerade ämnen för SAP CDC-anslutningsappen.
Mappa dataflödesegenskaper
Utför följande steg för att skapa ett mappningsdataflöde med hjälp av SAP CDC-anslutningsappen som källa:
I ADF Studio går du till avsnittet Dataflöden i author-hubben , väljer knappen ... för att listrutan Dataflödesåtgärder och väljer objektet Nytt dataflöde . Aktivera felsökningsläge med hjälp av felsökningsknappen Dataflöde i det övre fältet på arbetsytan för dataflöden.
I redigeraren för dataflödesmappning väljer du Lägg till källa.
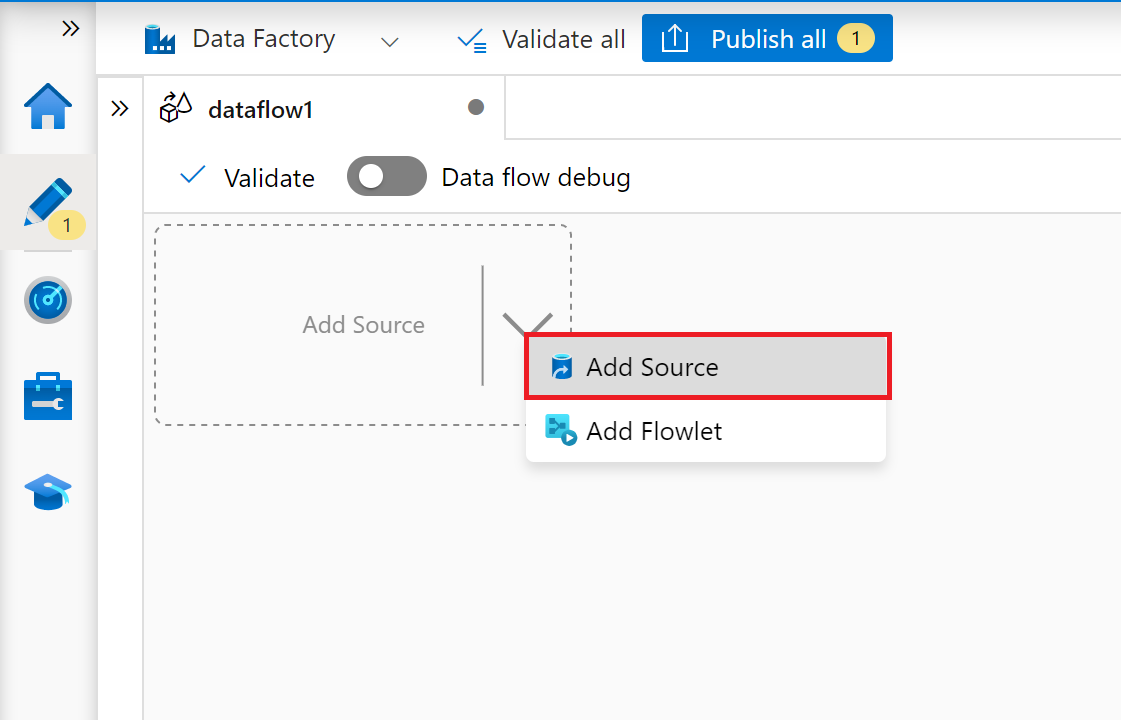
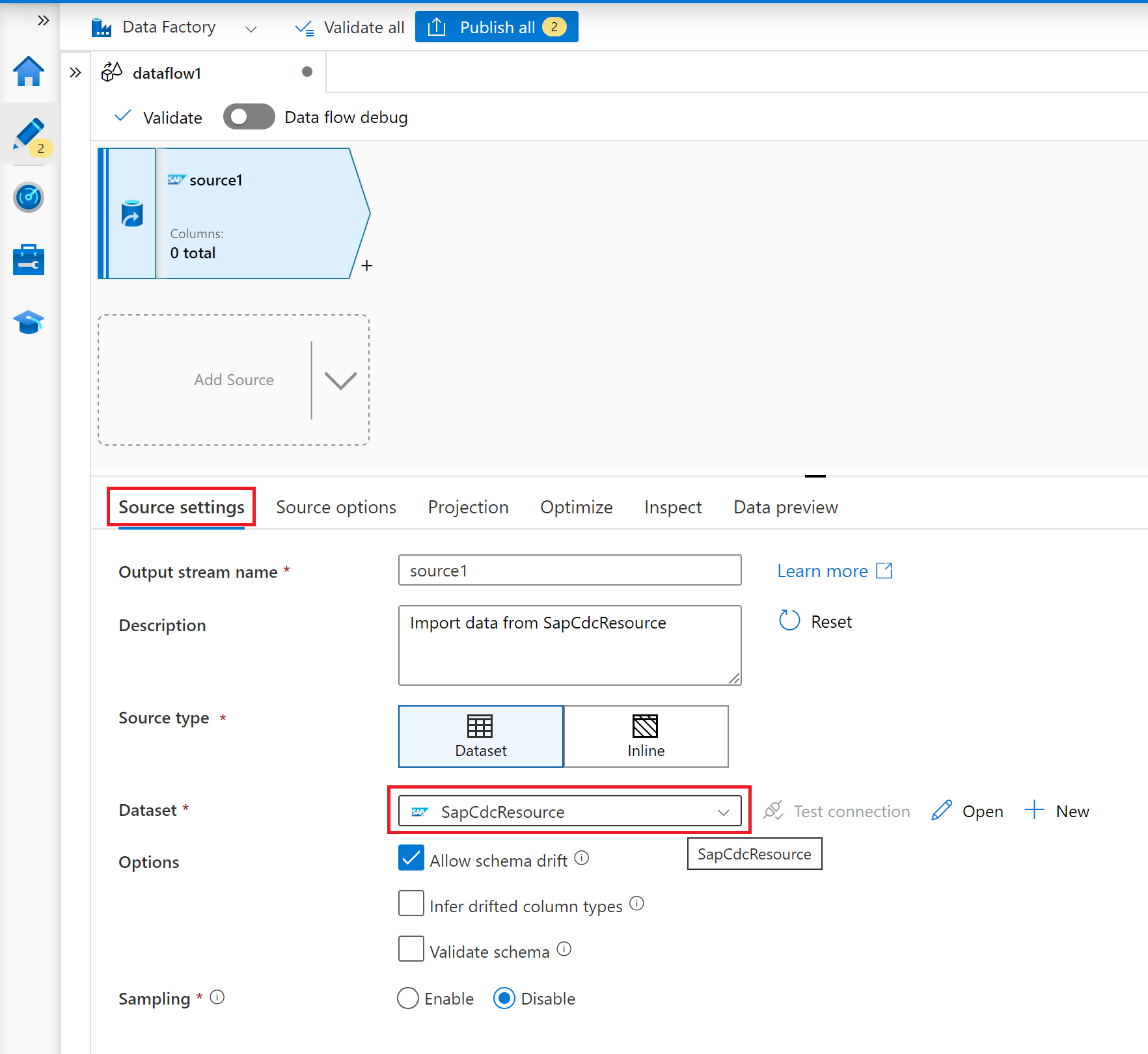
På fliken Källinställningar väljer du en förberedd SAP CDC-datauppsättning eller väljer knappen Ny för att skapa en ny. Du kan också välja Infoga i egenskapen Källtyp och fortsätta utan att definiera en explicit datauppsättning.
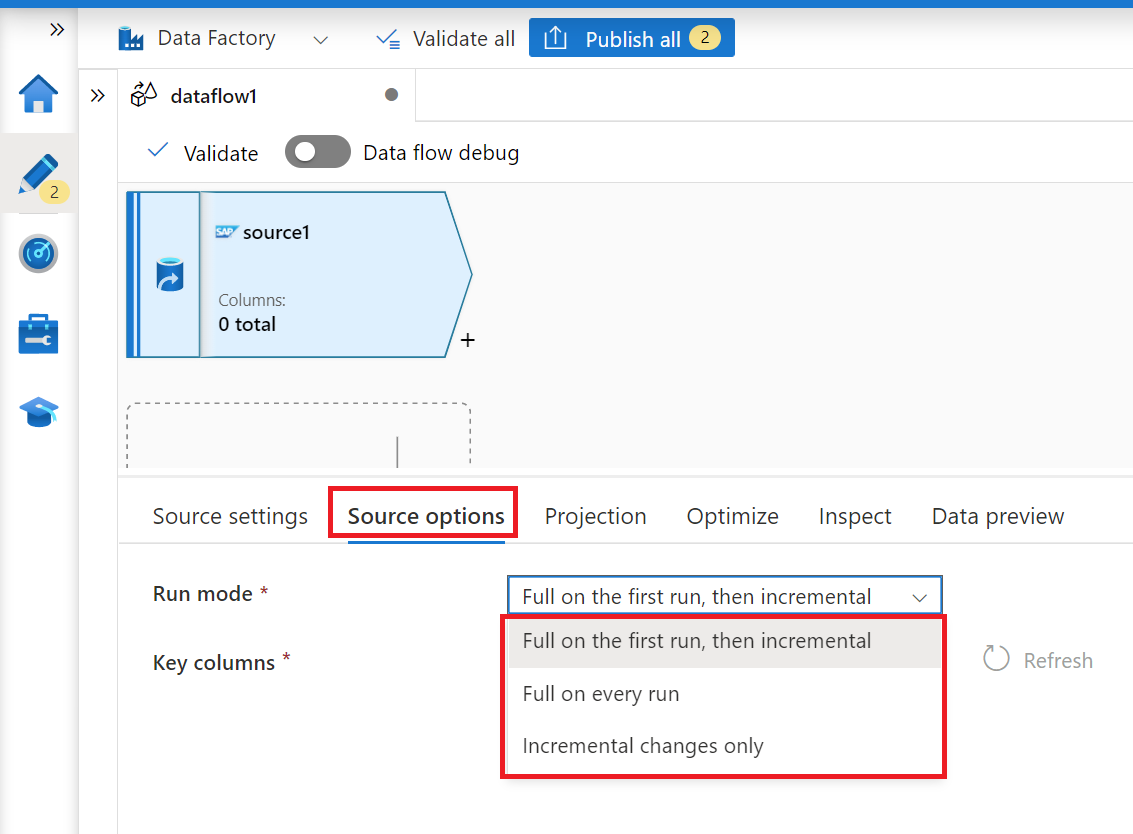
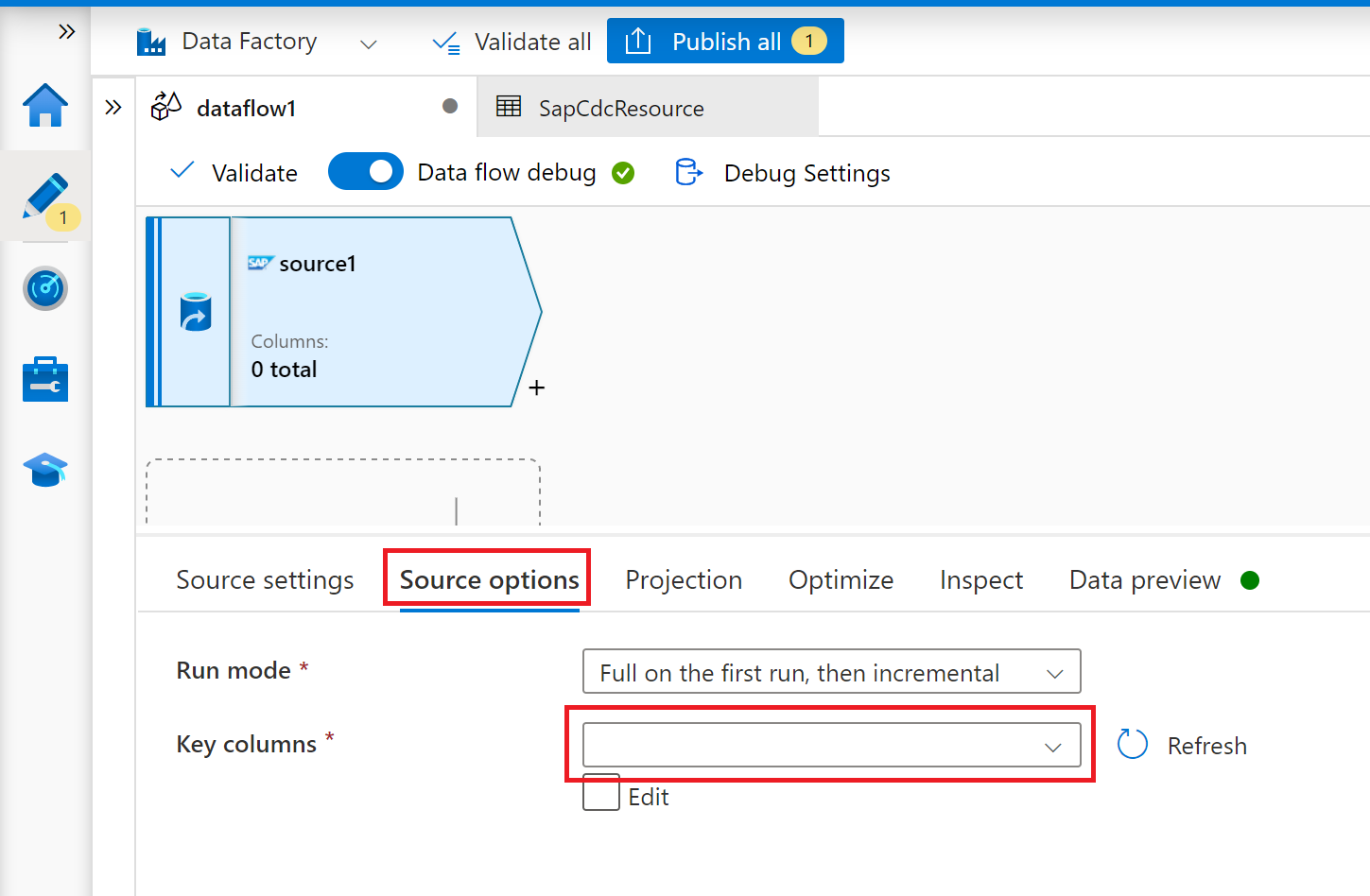
På fliken Källalternativ väljer du alternativet Full på varje körning om du vill läsa in fullständiga ögonblicksbilder vid varje körning av ditt mappningsdataflöde. Välj Fullständig vid den första körningen och sedan inkrementell om du vill prenumerera på en ändringsfeed från SAP-källsystemet, inklusive en första fullständig ögonblicksbild av data. I det här fallet utför den första körningen av pipelinen en deltainitiering, vilket innebär att den skapar en ODP-deltaprenumeration i källsystemet och returnerar en aktuell fullständig ögonblicksbild av data. Efterföljande pipelinekörningar returnerar endast inkrementella ändringar sedan föregående körning. Alternativet inkrementella ändringar skapar bara en ODP-deltaprenumeration utan att returnera en första fullständig ögonblicksbild av data i den första körningen. Återigen returnerar efterföljande körningar inkrementella ändringar eftersom endast föregående körning. Båda inkrementella inläsningsalternativen kräver att du anger nycklarna för ODP-källobjektet i egenskapen Nyckelkolumner .
Följ mappningsdataflödet för flikarna Projektion, Optimera och Inspektera.
Optimera prestanda för fullständiga eller inledande belastningar med källpartitionering
Om Körningsläge är inställt på Fullständig vid varje körning eller Fullständig vid den första körningen, erbjuder fliken Optimera en markerings- och partitioneringstyp som heter Källa. Med det här alternativet kan du ange villkor för flera partitioner (dvs. filter) för att segmentera en stor källdatauppsättning i flera mindre delar. För varje partition utlöser SAP CDC-anslutningsappen en separat extraheringsprocess i SAP-källsystemet.
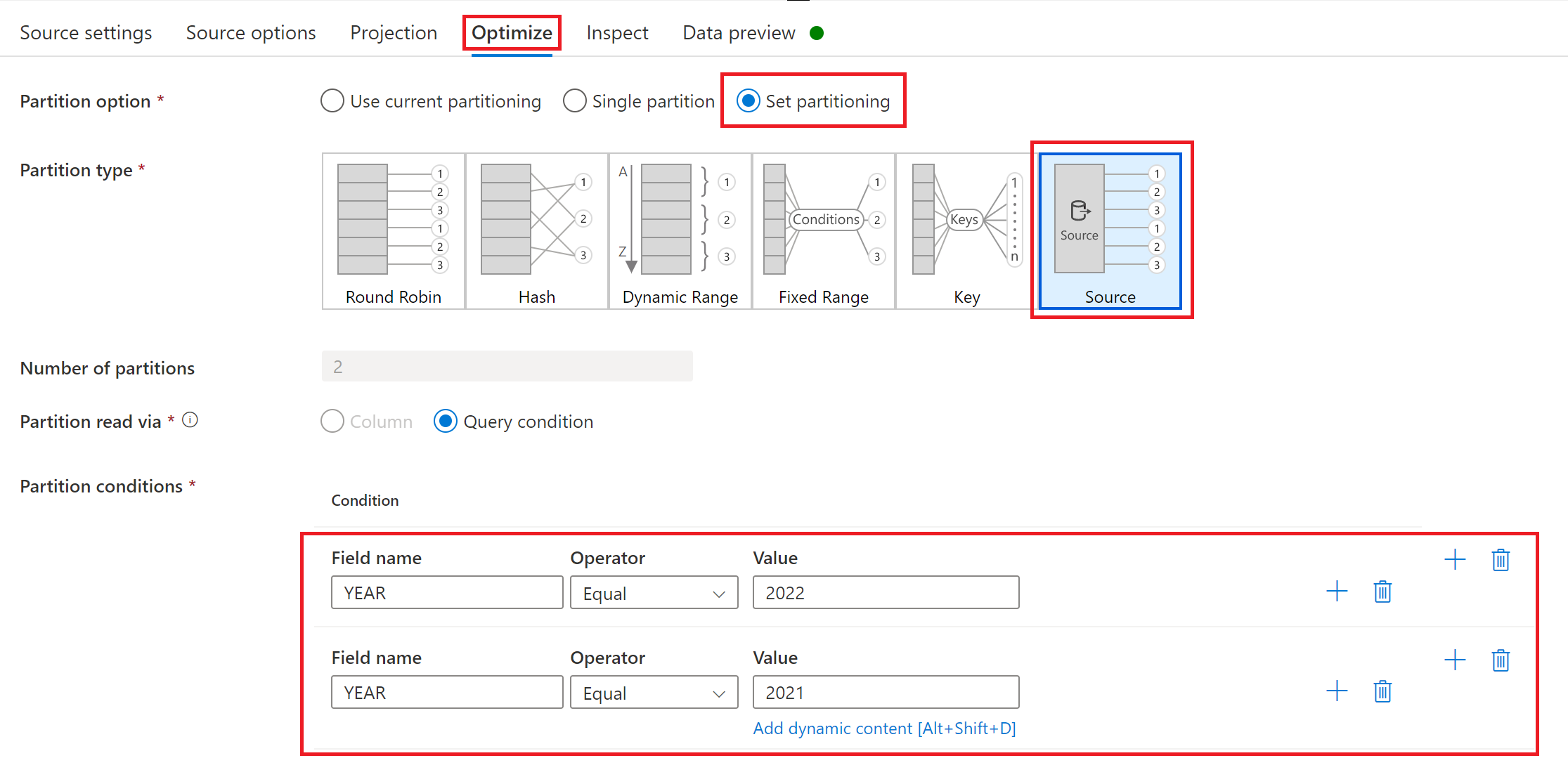
Om partitionerna är lika stora kan källpartitioneringen linjärt öka dataflödet för extrahering av data. För att uppnå sådana prestandaförbättringar krävs tillräckliga resurser i SAP-källsystemet, den virtuella datorn som är värd för den lokala integrationskörningen och Azure Integration Runtime.