Övervaka köad inmatning med metrik
I den köade inmatningsprocessen optimerar Azure Data Explorer datainmatning för högt dataflöde genom att gruppera inkommande små datasegment i batchar baserat på en konfigurerbar inmatningsbatchprincip. Med batchbearbetningsprincipen kan du ange utlösarvillkoren för att försegla en batch (datastorlek, antal blobar eller tid som passerat). Dessa batchar matas sedan in optimalt för snabba frågeresultat.
I den här artikeln får du lära dig hur du använder mått för att övervaka köad inmatning till Azure Data Explorer i Azure-portalen.
Batchbearbetningssteg
Stegen som beskrivs i det här avsnittet gäller för alla inmatningar av batchbearbetning. För Azure Event Grid, Azure Event Hubs, Azure IoT Hub och Cosmos DB-datahämtningar, är det så att innan data placeras i kö för bearbetning, hämtar en -dataanslutning data från externa källor och utför en inledande omorganisering av den.
Inmatning genom kö sker i steg:
- Batching Manager lyssnar på kön efter inmatningsmeddelanden och bearbetar begäranden.
- Batching Manager- optimerar dataflödet för inmatning genom att ta de små inkommande datasegmenten som den tar emot och batchhantera URL:erna baserat på inmatningsbatchprincipen.
- Ingestion Manager- skickar inmatningskommandona till Azure Data Explorer Storage Engine.
- Azure Data Explorer Storage Engine lagrar inmatade data, vilket gör dem tillgängliga för frågor.
Azure Data Explorer innehåller en uppsättning Azure Monitor-ingestationsmått så att du kan övervaka dataöverföringen i alla faser och komponenter i köprocessen.
Azure Data Explorer-inmatningsmåtten ger detaljerad information om:
- Resultatet av inmatning i kö.
- Mängden intagna data.
- Fördröjningen för den köade inmatningen och var den sker.
- Själva batch-processen.
- För inmatningar av Event Hubs, Event Grid och IoT Hub: Antalet mottagna händelser.
I den här artikeln får du lära dig hur du använder inmatningsmått i Azure-portalen för att övervaka köad inmatning till Azure Data Explorer.
Förutsättningar
- En Azure-prenumeration. Skapa ett kostnadsfritt Azure-konto.
- Ett Azure Data Explorer-kluster och en databas. Skapa ett kluster och en databas.
- En aktiv köinmatning, till exempel Event Hubs, IoT Hubeller Event Grid.
Skapa måttdiagram med Azure Monitor Metrics Explorer
Följande är en allmän förklaring av hur du använder Azure Monitor-måtten som sedan implementeras i efterföljande avsnitt. Använd följande steg för att skapa måttdiagram med Azure Monitor-måttutforskaren i Azure-portalen:
Logga in på Azure-portalen och gå till översiktssidan för ditt Azure Data Explorer-kluster.
Välj Mått från det vänstra navigeringsfältet för att öppna måttpanelen.
Öppna tidsväljaren längst upp till höger i panelen i måttfönstret och justera tidsintervallet till den tid du vill analysera. I den här artikeln analyserar vi datainmatning till Azure Data Explorer under de senaste 48 timmarna.
Välj ett omfång och ett måttnamnområde:
- Scope är namnet på ditt Azure Data Explorer-kluster. I följande exempel använder vi ett kluster med namnet demo11.
- Måttnamnområde ska anges till Standardmått för Kusto-kluster. Det här är namnområdet som innehåller Azure Data Explorer-måtten.

Välj mått namn och det relevanta värde för aggregering.

För några exempel i den här artikeln väljer vi Lägg till filter och Tillämpa delning för mått som har dimensioner. Vi använder också Lägg till mått för att rita andra mått i samma diagram och + Nytt diagram för att se flera diagram i en vy.
Varje gång du lägger till ett nytt mått upprepar du steg fyra och fem.
Anteckning
Mer information om hur du använder mått för att övervaka Azure Data Explorer i allmänhet och hur du arbetar med måttfönstret finns i Övervaka prestanda, hälsa och användning i Azure Data Explorer med mått.
I den här artikeln får du lära dig vilka metriker som kan användas för att spåra köad inmatning och hur du använder dessa metriker.
Visa inmatningsresultatet
Metriken inmatningsresultatet ger information om det totala antalet källor som har matats in framgångsrikt och de som misslyckades med inmatningen.
I det här exemplet använder vi det här måttet för att visa resultatet av våra inmatningsförsök och använda statusinformationen för att felsöka misslyckade försök.
- I panelen Mått i Azure Monitor väljer du Lägg till mått.
- Välj Inmatningsresultat som Metric-värde och Summa som Aggregation-värde. Det här valet visar resultatet av inmatningen över tid på en rad i diagrammet.
- Klicka på knappen Använd delning ovanför diagrammet och välj Status för att segmentera diagrammet efter status för inmatningsresultaten. När du har valt delningsvärdena klickar du bort från delningsväljaren för att stänga den.
Nu är måttinformationen uppdelad efter status och vi kan se information om statusen för inmatningsresultatet uppdelat på tre rader:
- Blå för lyckade inmatningsoperationer.
- Orange för inmatningsåtgärder som misslyckades på grund av entiteten hittades inte.
- Lila för inmatningsåtgärder som misslyckades på grund av Felaktig begäran.

Tänk på följande när du tittar på diagrammet med inmatningsresultat:
- När du använder händelse- eller IoT-hubbens inmatning, sker en föraggregering av händelser i komponenten för dataanslutning . Under det här inmatningssteget behandlas händelser som en enda källa som ska matas in. Därför visas några händelser som ett enda inmatningsresultat efter föraggregering.
- Tillfälliga fel görs om internt i ett begränsat antal försök. Varje tillfälligt fel rapporteras som ett tillfälligt inmatningsresultat. Därför kan ett enskilt intag leda till mer än ett intagsresultat.
- Inmatningsfel i diagrammet visas efter felkodens kategori. Om du vill se den fullständiga listan över inmatningsfelkoder efter kategorier och försöka bättre förstå möjliga felorsaker kan du läsa Felkoder för inmatning i Azure Data Explorer.
- Om du vill ha mer information om ett inmatningsfel kan du ange diagnostikloggar för misslyckad inmatning. Det är dock viktigt att tänka på att generera loggar resulterar i skapandet av extra resurser, och därmed en ökning av COGS (kostnaden för sålda varor).
Visa mängden insamlade data
Metrikerna Blobs Processed, Blobs Receivedoch Blobs Dropped ger information om antalet blobar som bearbetas, tas emot och släppts av inkommande komponenter under stegen av köad inmatning.
I det här exemplet använder vi dessa mått för att se hur mycket data som skickas via inmatningspipelinen, hur mycket data som togs emot av inmatningskomponenterna och hur mycket data som togs bort.
Bearbetade blobar
- I fönstret Metrics i Azure Monitor väljer du Lägg till Metric.
- Välj blobar som bearbetas som måttvärde och summa som aggregeringsvärde.
- Välj knappen Använd delning och välj komponenttyp för att segmentera diagrammet efter de olika inmatningskomponenterna.
- Om du vill fokusera på en specifik databas i klustret väljer du knappen Lägg till filter ovanför diagrammet och väljer sedan vilka databasvärden som ska inkluderas när diagrammet ritas. I det här exemplet filtrerar vi på de blobar som skickas till GitHub-databasen genom att välja Database som Property, = som Operatoroch GitHub i listrutan Values. När du har valt filtervärdena klickar du bort från filterväljaren för att stänga den.
Nu visar diagrammet hur många blobar som skickades till GitHub- databas bearbetades vid var och en av inmatningskomponenterna över tid.

- Observera att antalet blobar som matades in till GitHub- databas över tid minskade den 13 februari. Observera också att antalet blobar som bearbetades av varje komponent är liknande, vilket innebär att nästan all data som bearbetades i Dataanslutning-komponenten också bearbetades framgångsrikt av Batching Manager, Ingestion Manager, och Azure Data Explorer Storage Engine-komponenterna. Dessa data är klara för frågor.
Mottagna blobbar
För att bättre förstå relationen mellan antalet blobar som togs emot vid varje komponent och antalet blobar som bearbetades korrekt vid varje komponent lägger vi till ett nytt diagram:
- Välj + Nytt diagram.
- Välj samma värden som ovan för Scope, Metric Namespaceoch Aggregation, och välj måttet Blobs Received.
- Välj knappen Använd delning och välj komponenttyp, vilket gör det möjligt att dela upp det metriska värdet mottagna blobbar enligt komponenttyp.
- Välj knappen Lägg till filter och ange samma värden som tidigare för att filtrera endast de blobar som skickas till GitHub-databasen.

- Jämför diagrammen genom att observera att antalet blobar som tas emot av varje komponent nära matchar antalet blobar som bearbetades av varje komponent. Den här jämförelsen anger att inga blobar togs bort under inmatningen.
Blobbar släppta
För att avgöra om det finns blobar som har släppts under inmatningen bör du analysera måttet blobar som släppts. Det här måttet visar hur många blobar som togs bort under inmatningen och hjälper dig att identifiera om det finns ett problem vid bearbetning vid en specifik inmatningskomponent. För varje borttagen blob får du också ett inmatningsresultat mått med mer information om orsaken till felet.
Visa svarstiden för inmatning
De mätvärden som Stegfördröjning och Upptäcktsfördröjning övervakar är latensen i inmatningsprocessen och meddelar om det sker några långa fördröjningar antingen i Azure Data Explorer eller innan data anländer till Azure Data Explorer för inmatning.
- anger tidsintervallet från när ett meddelande identifieras av Azure Data Explorer tills dess innehåll tas emot av en inmatningskomponent för bearbetning.
- Upptäcktslatens används för inmatningspipelines med dataanslutningar (till exempel händelsehubb, IoT-hubb och Event Grid). Det här måttet ger information om tidsintervallet från datakö till identifiering av Azure Data Explorer-dataanslutningar. Det här tidsintervallet är uppströms till Azure Data Explorer, så det ingår inte i måttet stage latency som endast mäter svarstiden i Azure Data Explorer.
Obs
Enligt standardprincipen batchbearbetningär standard batchbearbetningstiden fem minuter. Om batchen inte är förseglad av andra utlösare förseglas därför batchen efter fem minuter.
När du ser en lång svarstid tills data är redo för frågor, kan du analysera Stage Latency och Discovery Latency för att avgöra om den långa svarstiden beror på långa svarstider i Azure Data Explorer eller om den ligger uppströms mot Azure Data Explorer. När svarstiden är i Själva Azure Data Explorer kan du också identifiera den specifika komponent som är ansvarig för den långa svarstiden.
Svarstid för steg (förhandsversion)
Låt oss först titta på fördröjningen för vår köade inmatning. En förklaring av varje steg finns i Batchbearbetningssteg.
- I panelen Mätvärden i Azure Monitor väljer du Lägg till mätvärde.
- Välj stegfördröjning som värdet Mått och Genomsnittlig som aggregering värde.
- Välj knappen Använd delning och välj komponenttyp för att segmentera diagrammet efter de olika inmatningskomponenterna.
- Välj knappen Lägg till filter och filtrera på de data som skickas till GitHub-databasen. När du har valt filtervärdena klickar du bort från filterväljaren för att stänga den. Nu visar diagrammet svarstiden för inmatningsåtgärder som skickas till GitHub-databasen vid var och en av komponenterna via inmatning över tid:

Vi kan se följande information från det här diagrammet:
- Svarstiden för Event Hubs-dataanslutningen komponenten är cirka 0 sekunder. Det här är vettigt eftersom stegfördröjning endast mäter svarstiden från när ett meddelande identifieras av Azure Data Explorer.
- Den längsta tiden i inmatningsprocessen (cirka 5 minuter) passerar från när Batching Manager komponenten tog emot data till när Ingestion Manager komponenten tog emot data. I det här exemplet använder vi standardprincipen för batchbearbetning för GitHub- databas. Som nämnts är tidsgränsen för svarstiden för standardprincipen för batchbearbetning 5 minuter, så detta indikerar troligtvis att nästan alla data batchats efter tid, och den största delen av svarstiden för den köade inmatningen berodde på själva batchbearbetningen.
- Svarstiden för lagringsmotorn i diagrammet representerar svarstiden tills data lagras i Azure Data Explorer Storage Engine och är redo för frågor. Du kan se att den genomsnittliga totala svarstiden från tidpunkten för dataidentifiering av Azure Data Explorer tills den är klar för frågan är 5,2 minuter.
Upptäcktslatens
Om du använder inmatning med dataanslutningar kanske du vill beräkna svarstiden uppströms till Azure Data Explorer över tid, eftersom långa svarstider också kan uppstå innan Azure Data Explorer hämtar data för inmatning. I det syftet kan du använda måttet Identifieringssvarstid.
- Välj + Nytt diagram.
- Välj identifieringssvarstid som mått och genomsnittlig som värdet aggregering.
- Välj knappen Använd delning och välj komponenttyp för att segmentera diagrammet efter olika typer av dataanslutningskomponenter. När du har valt delningsvärdena klickar du bort från delningsväljaren för att stänga den.

- Du kan se att identifieringsfördröjningen under större delen av tiden är nära 0 sekunder, vilket indikerar att Azure Data Explorer fick data strax efter att data har lagts till. Den högsta toppen på cirka 300 millisekunder är runt den 13 februari klockan 14:00, vilket indikerar att Azure Data Explorer-klustret vid denna tidpunkt tog emot data ungefär 300 millisekunder efter att data köades.
Förstå batchbearbetningsprocessen
I den andra fasen av det köade inmatningsflödet optimerar Batching Manager--komponenten dataflödet för inmatning genom att batchhantera de data som den tar emot baserat på inmatningen batchprincipen.
Följande uppsättning mått hjälper dig att förstå hur dina data batchas under inmatningen:
- Batches Processed: Antalet batchar som har slutförts för inmatning.
- Batch Size: Den uppskattade storleken på okomprimerade data i en batch aggregerad för inmatning.
- batchens varaktighet: Varaktigheten för varje enskild batch från och med det ögonblick batchen öppnas till batchens försegling.
- Batch Blob Count: Antalet blobar i en slutförd batch för intag.
Bearbetade batchar
Låt oss börja med en övergripande vy över batchbearbetningsprocessen genom att titta på metriket för bearbetade batcher.
- I fönstret Mått i Azure Monitor ska du välja Lägg till mått.
- Välj Batches Processed som värdet Metric och Sum som aggregeringsvärde.
- Välj knappen Använd delning och välj Batching Type för att segmentera diagrammet utifrån skälet till att batchen förseglades. En fullständig lista över batchtyper finns i Batching-typer.
- Välj knappen Lägg till filter och filtrera på batcharna som skickas till GitHub-databasen. När du har valt filtervärdena klickar du bort från filterväljaren för att stänga den.
Diagrammet visar antalet förseglade batchar med data som skickas till GitHub databas över tid, uppdelat efter Batching Type.

- Observera att det finns 2–4 batchar per tidsenhet och att alla batchar är förseglade i tid enligt uppskattningen i avsnittet stegsvarstid där du kan se att det tar cirka 5 minuter att batcha data baserat på standardprincipen för batchning.
Batchvaraktighet, storlek och antal blobar
Nu ska vi ytterligare karakterisera de bearbetade batcharna.
- Välj knappen + Lägg till diagram för varje diagram för att skapa fler diagram för värdena MetricBatch Duration, Batch Sizeoch Batch Blob Count.
- Använd genomsnitt som aggregeringsvärde.
- Precis som i föregående exempel väljer du knappen Lägg till filter och filtrerar på data som skickas till GitHub-databasen.

Från Batch Duration, Batch Sizeoch Batch Blob Count diagrammen kan vi dra vissa insikter.
Den genomsnittliga batchvaraktigheten är fem minuter (enligt standardprincipen för batchbearbetning). Du bör ta hänsyn till detta när du tittar på den totala svarstiden för inmatning.
I diagrammet Batch Size kan du se att den genomsnittliga storleken på batchar är cirka 200–500 MB över tid. Den optimala storleken på data som ska matas in är 1 GB okomprimerade data, och den här storleken definieras också som ett tätningsvillkor som standardprincip för batchbearbetning. Eftersom det inte finns 1 GB data som ska samlas över tid ser vi inga batchar som förseglas på grund av storlek.
Det genomsnittliga antalet blobar i batcharna är cirka 160 blobar över tid, vilket sedan minskar till 60–120 blobar. Baserat på standardprincipen för batchbearbetning kan en batch förseglas när antalet blobar är 1 000 blobar. Eftersom vi inte anländer till det här numret ser vi inte batchar som är förseglade med antal.
Jämför händelser som tagits emot med händelser som skickats för inmatning
När du använder händelsehubb, IoT-hubb eller Event Grid-inmatning kan det vara användbart att jämföra antalet händelser som tas emot av Azure Data Explorer med antalet händelser som skickas från händelsekällan till Azure Data Explorer. Med mätvärdena mottagna händelser, bearbetade händelser, och förlorade händelser kan du göra den här jämförelsen.
Mottagna händelser
- I fönstret Mått i Azure Monitor väljer du alternativet Lägg till mått.
- Välj Mottagna händelser som Måttvärde och Summa som Aggregationsvärde.
- Välj knappen Lägg till filter ovanför diagrammet och välj värdet egenskapkomponentnamn för att filtrera de händelser som tas emot av en specifik dataanslutning som definierats i klustret. I det här exemplet filtrerar vi på GitHubStreamingEvents dataanslutning. När du har valt filtervärdena klickar du bort från filterväljaren för att stänga den.
Nu visar diagrammet antalet händelser som tagits emot av den valda dataanslutningen över tid:

- I det här diagrammet tar GitHubStreamingEvents dataanslutning emot cirka 200–500 händelser per tidsenhet över tid.
Händelser som bearbetas och händelser som tagits bort
Om du vill se om några händelser har tagits bort av Azure Data Explorer använder du måtten Händelser som bearbetas och borttagna händelser.
- I diagrammet som du redan har skapat väljer du Lägg till mått.
- Välj bearbetade händelser som måttets värde och summans värde som aggregeringens värde.
- Välj Lägg till mått igen och välj Borttagna händelser som måttvärde och summa som aggregeringsvärde.
Diagrammet visar nu antalet händelser som tagits emot, bearbetats och släppts av GitHubStreamingEvents dataanslutning över tid.

- Nästan alla mottagna händelser har framgångsrikt bearbetats av dataanslutningen. Det finns en borttagen händelse som är kompatibel med det misslyckade inmatningsresultatet på grund av en felaktig begäran som vi såg när att visa måttet för inmatningsresultatet.
Jämför händelser som tas emot i Azure Data Explorer med utgående meddelanden från händelsehubben
Du kanske också vill jämföra antalet händelser som tagits emot med antalet händelser som skickats från händelsehubben till Azure Data Explorer genom att titta på måtten mottagna händelser och utgående meddelanden.
I diagrammet som du redan har skapat för händelser som tagits emotväljer du Lägg till mått.
Välj Omfång och i dialogrutan Välj ett omfång, bläddra tills du hittar och väljer namnområdet för händelsehubben som skickar data till din dataanslutning.
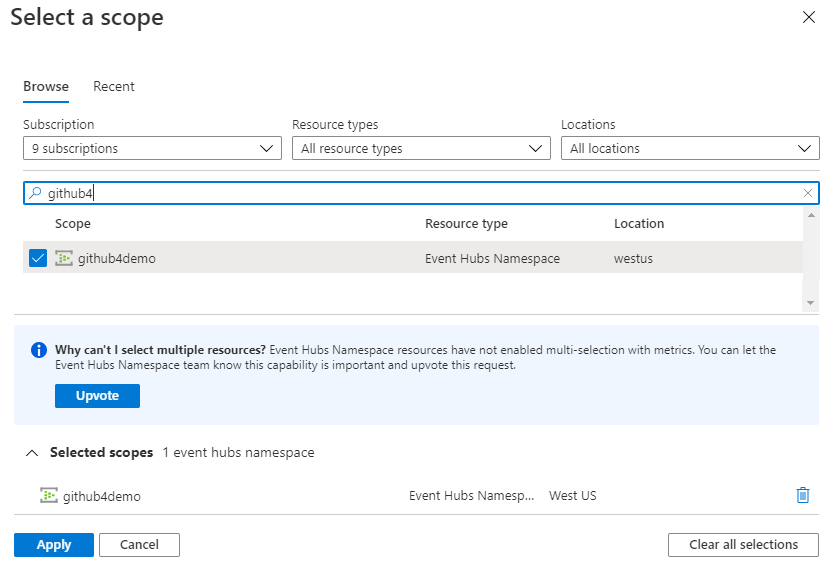
Välj Tillämpa
Välj utgående meddelanden som måttvärde och summa som aggregationsvärde.

Klicka bort från inställningarna för att hämta det fullständiga diagrammet som jämför antalet händelser som bearbetas av Azure Data Explorer-dataanslutningen med antalet händelser som skickas från händelsehubben.

- Observera att alla händelser som skickades från händelsehubben har bearbetats av Azure Data Explorer-dataanslutningen.
- Om du har mer än en händelsehubb i namnområdet för händelsehubbarna bör du filtrera metriken Utgående Meddelanden genom dimensionen Entitetsnamn för att endast hämta data från önskad händelsehubb i ditt namnområde för händelsehubbar.
Not
Det finns inget alternativ för att övervaka utgående meddelande per konsumentgrupp. Måttet Utgående Meddelanden räknar det totala antalet meddelanden som konsumerades av alla konsumentgrupper. Om du har några konsumentgrupper i händelsehubben kan du få ett större antal utgående meddelanden än händelser som tagits emot.