Azure Machine Learning som en dataprodukt för analys i molnskala
Azure Machine Learning är en integrerad plattform för att hantera livscykeln för maskininlärning från början till slut, inklusive hjälp med att skapa, använda och använda maskininlärningsmodeller och arbetsflöden. Några fördelar med tjänsten är:
Funktioner stöder skapare för att öka produktiviteten genom att hjälpa dem att hantera experiment, komma åt data, spåra jobb, finjustera hyperparametrar och automatisera arbetsflöden.
Modellens kapacitet att förklaras, reproduceras, granskas och integreras med DevOps, plus en omfattande säkerhetskontrollmodell, kan stödja operatörer för att uppfylla styrnings- och efterlevnadskrav.
Hanterade slutsatsdragningsfunktioner och robust integrering med Azure-beräknings- och datatjänster kan hjälpa till att förenkla hur tjänsten används.
Azure Machine Learning omfattar alla aspekter av datavetenskapens livscykel. Det omfattar registrering av datalager och datamängder för modellimplementering. Det kan användas för alla typer av maskininlärning, från klassisk maskininlärning till djupinlärning. Den innehåller övervakad och oövervakad inlärning. Oavsett om du föredrar att skriva Python, R-kod eller använda alternativ med noll kod eller låg kod, till exempel designern, kan du skapa, träna och spåra korrekta maskininlärnings- och djupinlärningsmodeller på en Azure Machine Learning-arbetsyta.
Azure Machine Learning, Azure-plattformen och Azure AI-tjänsterna kan arbeta tillsammans för att hantera livscykeln för maskininlärning. En maskininlärningsutövare kan använda Azure Synapse Analytics, Azure SQL Database eller Microsoft Power BI för att börja analysera data och övergå till Azure Machine Learning för prototyper, hantering av experimentering och operationalisering. I Azure-landningszoner kan Azure Machine Learning betraktas som en dataprodukt.
Azure Machine Learning i analys i molnskala
En stödfunktion för Molnimplementeringsramverket (CAF), datalandningszoner för molnskaliga analyser och konfigurationen av Azure Machine Learning utrustar maskininlärningsspecialister med en förkonfigurerad miljö där de upprepade gånger kan distribuera nya maskininlärningsarbetsbelastningar eller migrera befintliga arbetsbelastningar. Dessa funktioner kan hjälpa maskininlärningspersonal att få mer flexibilitet och värde för sin tid.
Följande designprinciper kan vägleda implementeringen av Azure Machine Learning Azure-landningszoner:
Accelererad dataåtkomst: Förkonfigurera lagringskomponenter för landningszoner som datalager på Azure Machine Learning-arbetsytan.
Aktiverat samarbete: Organisera arbetsytor efter projekt och centralisera åtkomsthantering för landningszonresurser för att stödja datateknik, datavetenskap och maskininlärningspersonal att arbeta tillsammans.
Säker implementering: Som standard för varje distribution följer du metodtips och använder nätverksisolering, identitets- och åtkomsthantering för att skydda datatillgångar.
självbetjäning: Maskininlärningspersonal kan få mer flexibilitet och organisation genom att utforska alternativ för att distribuera nya projektresurser.
Uppdelning av problem mellan datahantering och dataförbrukning: identitetsgenomströmning är standardautentiseringstypen för Azure Machine Learning och lagring.
Snabbare användning av data (källjusterat): Landningszoner för Azure Data Factory, Azure Synapse Analytics och Databricks kan förkonfigureras för att länka till Azure Machine Learning.
Observability: Centralloggning och referenskonfigurationer kan hjälpa till att övervaka systemmiljön.
Översikt över implementering
Notis
I det här avsnittet rekommenderas konfigurationer som är specifika för analys i molnskala. Den kompletterar Azure Machine Learning-dokumentationen och bästa praxis för Cloud Adoption Framework.
Organisation och konfiguration av arbetsyta
Du kan distribuera antalet maskininlärningsarbetsytor som dina arbetsbelastningar kräver och för varje landningszon som du distribuerar. Följande rekommendationer kan hjälpa dig att konfigurera:
Distribuera minst en arbetsyta för maskininlärning per projekt.
Beroende på maskininlärningsprojektets livscykel distribuerar du en utvecklingsarbetsyta (dev) för att skapa prototyper av användningsfall och utforska data tidigt. Distribuera en mellanlagrings- och produktionsarbetsyta för arbete som kräver kontinuerlig experimentering, testning och distribution.
När flera miljöer behövs för arbetsytor för utveckling, mellanlagring och produktion i en datalandningszon rekommenderar vi att du undviker dataduplicering genom att varje miljö hamnar i samma landningszon för produktionsdata.
Mer information om hur du organiserar och konfigurerar Azure Machine Learning-resurser finns i Organisera och konfigurera Azure Machine Learning-miljöer.
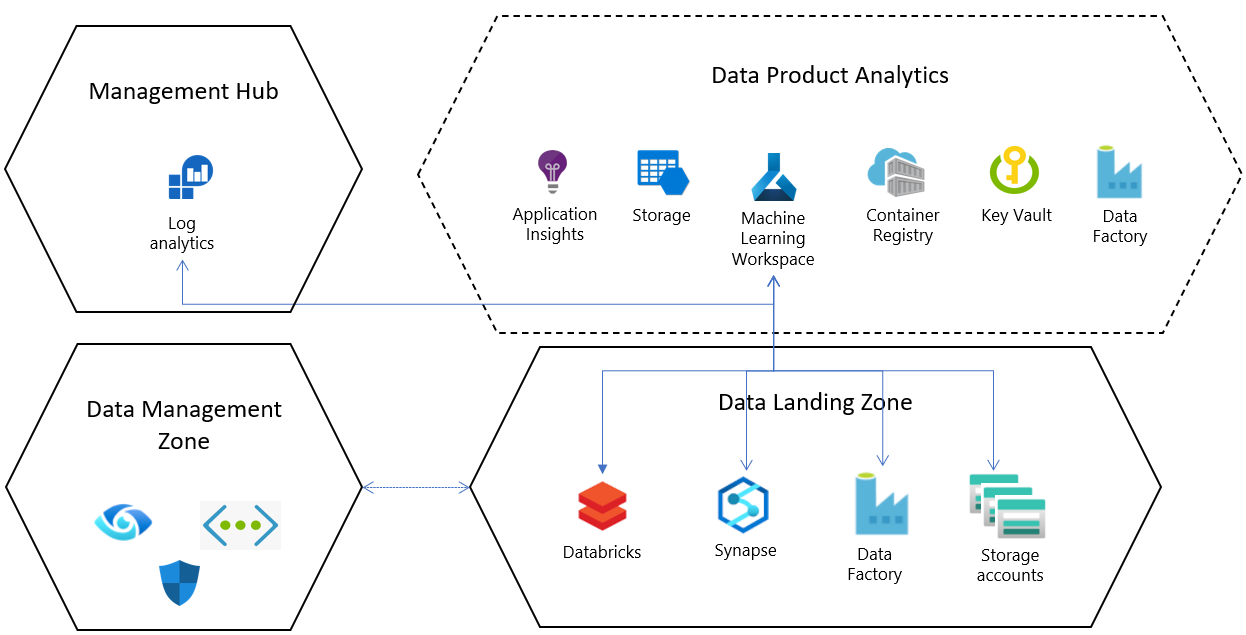
För varje standardresurskonfiguration i en datalandningszon distribueras en Azure Machine Learning-tjänst i en dedikerad resursgrupp med följande konfigurationer och beroende resurser:
- Azure Key Vault
- Application Insights
- Azure Container Registry
- Använd Azure Machine Learning för att ansluta till ett Azure Storage-konto och Microsoft Entra-identitetsbaserad autentisering för att hjälpa användare att ansluta till kontot.
- Diagnostikloggning sätts upp för varje arbetsyta och kopplas till en central Log Analytics-resurs för företagsskalor. Detta kan möjliggöra en central analys av tillstånd och resursstatus för Azure Machine Learning-jobb både inom och mellan landningszoner.
- Se Vad är en Azure Machine Learning-arbetsyta? för att lära dig mer om Azure Machine Learning-resurser och beroenden.
Integrering med kärntjänster för datalandningszoner
Datalandningszonen levereras med en standarduppsättning tjänster som distribueras i plattformstjänstlagret. Dessa kärntjänster kan konfigureras när Azure Machine Learning distribueras i datalandningszonen.
Anslut Azure Synapse Analytics- eller Databricks-arbetsytor som länkade tjänster för att integrera data och bearbeta stordata.
Som standard etableras Data Lake-tjänster i datalandningszonen och Azure Machine Learning-produktdistributioner levereras med anslutningar (datalager) som är förkonfigurerade för dessa lagringskonton.
Nätverksanslutning
Nätverk för implementering av Azure Machine Learning i Azure-landningszoner är konfigurerade enligt säkerhetsbästa praxis för Azure Machine Learning samt CAFs nätverksrekommendationer. Dessa metodtips omfattar följande konfigurationer:
- Azure Machine Learning och beroende resurser har konfigurerats för att använda Private Link-slutpunkter.
- Hanterade beräkningsresurser distribueras endast med privata IP-adresser.
- Nätverksanslutning till den offentliga lagringsplatsen för Azure Machine Learning-basavbildningar och partnertjänster som Azure Artifacts kan konfigureras på nätverksnivå.
Identitets- och åtkomsthantering
Överväg följande rekommendationer för att hantera användaridentiteter och åtkomst med Azure Azure Machine Learning:
Datalager i Azure Machine Learning kan konfigureras för att använda autentiseringsuppgifter eller identitetsbaserad autentisering. När du använder åtkomstkontroll och datasjökonfigurationer i Azure Data Lake Storage Gen2konfigurerar du datalager för att använda identitetsbaserad autentisering. Detta gör att Azure Machine Learning kan optimera användaråtkomstbehörigheter för lagring.
Använd Microsoft Entra-grupper för att hantera användarbehörigheter för lagrings- och maskininlärningsresurser.
Azure Machine Learning kan använda användartilldelade hanterade identiteter för åtkomstkontroll och begränsa åtkomstintervallet till Azure Container Registry, Key Vault, Azure Storage och Application Insights.
Skapa användartilldelade hanterade identiteter till hanterade beräkningskluster som skapats i Azure Machine Learning.
Etablera infrastruktur via självbetjäning
Självbetjäning kan aktiveras och styras med principer för Azure Machine Learning. I följande tabell visas en uppsättning standardprinciper när du distribuerar Azure Machine Learning. Mer information finns i inbyggda principdefinitioner i Azure Policy för Azure Machine Learning.
| Politik | Typ | Hänvisning |
|---|---|---|
| Azure Machine Learning-arbetsytor bör använda Azure Private Link. | Inbyggd | Visning i Azure-portalen |
| Azure Machine Learning-arbetsytor bör använda användartilldelade hanterade identiteter. | Inbyggd | Vy i Azure-portalen |
| [Förhandsversion]: Konfigurera tillåtna register för angivna Azure Machine Learning-beräkningar. | Inbyggd | Visa i Azure-portalen |
| Konfigurera Azure Machine Learning-arbetsytor med privata slutpunkter. | Inbyggd | Visa i Azure-portalen |
| Konfigurera maskininlärningsberäkning för att inaktivera lokala autentiseringsmetoder. | Inbyggd | Visa i Azure-portalen |
| Lägg till maskininlärningsberäknings-inställningsskript-skapandeskript | Anpassad (CAF-landningszoner) | Visa på GitHub |
| Avvisa-maskininlärning-hbiworkspace | Anpassad (CAF-landningszoner) | Visa på GitHub |
| Neka offentlig åtkomst för maskininlärning bakom VNET | Specialanpassad (CAF-landningszoner) | View på GitHub |
| Neka-maskininlärning-AKS | Anpassad (CAF-landningszoner) | Visa på GitHub |
| Nekad åtkomst till machinelearningcompute-subnetid | Anpassad (CAF-landningszoner) | visa på GitHub |
| Avvisa-machinelearningcompute-vmsize | Anpassad (CAF-landningszoner) | Visa på GitHub |
| Neka-maskininlärningsberäkningskluster-fjärrinloggningsport-offentlig åtkomst | Anpassad (CAF-landningszoner) | View på GitHub |
| Neka-maskininlärningsdatorkluster-skala | Anpassad (CAF-landningszoner) | View på GitHub |
Rekommendationer för att hantera din miljö
Datalandningszoner i molnskala beskriver referensimplementering för repeterbara distributioner, vilket kan hjälpa dig att konfigurera hanterbara och styrbara miljöer. Överväg följande rekommendationer för att använda Azure Machine Learning för att hantera din miljö:
Använd Microsoft Entra-grupper för att hantera åtkomst till maskininlärningsresurser.
Publicera en central instrumentpanel för övervakning för att övervaka pipelinens hälsa, beräkningsanvändning och kvothantering för maskininlärning.
Om du traditionellt använder inbyggda Azure-principer och behöver uppfylla ytterligare efterlevnadskrav skapar du anpassade Azure-principer för att förbättra styrning och självbetjäning.
Om du vill spåra kostnader för forskning och utveckling distribuerar du en maskininlärningsarbetsyta i landningszonen som en delad resurs under de tidiga stadierna av att utforska ditt användningsfall.
Viktig
Använd Azure Machine Learning-kluster för modellträning i produktionsklass och Azure Kubernetes Service (AKS) för distributioner i produktionsklass.
Tips
Använd Azure Machine Learning för datavetenskapsprojekt. Det omfattar arbetsflödet från slutpunkt till slutpunkt med undertjänster och funktioner och gör att processen kan automatiseras helt.
Nästa steg
Använd mallen Data Product Analytics och vägledning för att distribuera Azure Machine Learning och referera till Dokumentation och självstudier för Azure Machine Learning för att komma igång med att skapa dina lösningar.
Fortsätt till följande fyra Cloud Adoption Framework-artiklar om du vill veta mer om metodtips för distribution och hantering av Azure Machine Learning för företag:
Organisera och konfigurera Azure Machine Learning-miljöer: När du planerar en Azure Machine Learning-distribution, hur påverkar teamstrukturer, miljöer eller resursområdet hur arbetsytor konfigureras?
metodtips för Azure Machine Learning för företagssäkerhet: Lär dig hur du skyddar din miljö och dina resurser med Azure Machine Learning.
Hantera budgetar, kostnader och kvoter för Azure Machine Learning i organisationsskala: Organisationer står inför många hanterings- och optimeringsutmaningar när de hanterar arbetsbelastnings-, team- och användarberäkningskostnader som uppstår från Azure Machine Learning.
DevOps-guide för maskininlärning: Machine Learning DevOps är en organisationsförändring som bygger på en kombination av människor, processer och teknik för att leverera maskininlärningslösningar på ett robust, skalbart, tillförlitligt och automatiserat sätt. Den här guiden sammanfattar metodtips och information för företag som använder Azure Machine Learning för att använda DevOps för maskininlärning.