MLOps (Machine Learning Operations)
Maskininlärningsåtgärder (kallas även MLOps) är tillämpningen av DevOps-principer för AI-infunderade program. För att implementera maskininlärningsåtgärder i en organisation måste specifika färdigheter, processer och teknik finnas på plats. Målet är att leverera maskininlärningslösningar som är robusta, skalbara, tillförlitliga och automatiserade.
I den här artikeln får du lära dig hur du planerar resurser för maskininlärningsåtgärder på organisationsnivå. Granska metodtips och rekommendationer som baseras på användning av Azure Mašinsko učenje för att implementera maskininlärningsåtgärder i företaget.
Vad är maskininlärningsåtgärder?
Moderna maskininlärningsalgoritmer och ramverk gör det allt enklare att utveckla modeller som kan göra korrekta förutsägelser. Maskininlärningsåtgärder är ett strukturerat sätt att införliva maskininlärning i programutveckling i företaget.
I ett exempelscenario har du skapat en maskininlärningsmodell som överskrider alla dina förväntningar på noggrannhet och imponerar på dina företagssponsorer. Nu är det dags att distribuera modellen till produktion, men det kanske inte är så enkelt som du hade förväntat dig. Organisationen kommer sannolikt att behöva ha personer, processer och teknik på plats innan den kan använda din maskininlärningsmodell i produktion.
Med tiden kan du eller en kollega utveckla en ny modell som fungerar bättre än den ursprungliga modellen. Att ersätta en maskininlärningsmodell som används i produktion medför vissa problem som är viktiga för organisationen:
- Du vill implementera den nya modellen utan att störa de affärsverksamheter som förlitar sig på den distribuerade modellen.
- I regelsyfte kan du behöva förklara modellens förutsägelser eller återskapa modellen om ovanliga eller partiska förutsägelser uppstår från data i den nya modellen.
- De data som du använder i maskininlärningsträningen och modellen kan ändras med tiden. Med ändringar i data kan du behöva träna om modellen regelbundet för att bibehålla förutsägelsenoggrannheten. En person eller roll måste tilldelas ansvar för att mata in data, övervaka modellens prestanda, träna om modellen och åtgärda modellen om den misslyckas.
Anta att du har ett program som hanterar en modells förutsägelser via REST API. Även ett enkelt användningsfall som det här kan orsaka problem i produktionen. Genom att implementera en strategi för maskininlärningsåtgärder kan du hantera distributionsproblem och stödja affärsåtgärder som är beroende av AI-infunderade program.
Vissa maskininlärningsåtgärder passar bra i det allmänna DevOps-ramverket. Exempel är att konfigurera enhetstester och integreringstester och spåra ändringar med hjälp av versionskontroll. Andra uppgifter är mer unika för maskininlärningsåtgärder och kan vara:
- Aktivera kontinuerlig experimentering och jämförelse med en baslinjemodell.
- Övervaka inkommande data för att identifiera dataavvikelser.
- Omträning av utlösarmodell och konfiguration av en återställning för haveriberedskap.
- Skapa återanvändbara datapipelines för träning och bedömning.
Målet med maskininlärningsåtgärder är att minska klyftan mellan utveckling och produktion och att leverera värde till kunderna snabbare. För att uppnå det här målet måste du tänka om traditionella utveckling- och produktionsprocesser.
Alla organisationers krav på maskininlärningsåtgärder är inte desamma. Arkitekturen för maskininlärningsåtgärder i ett stort multinationellt företag kommer förmodligen inte att vara samma infrastruktur som en liten startup etablerar. Organisationer börjar vanligtvis små och byggs upp när deras mognad, modellkatalog och erfarenhet växer.
Mognadsmodellen för maskininlärningsåtgärder kan hjälpa dig att se var din organisation befinner sig på mognadsskalan för maskininlärningsåtgärder och hjälpa dig att planera för framtida tillväxt.
Maskininlärningsåtgärder jämfört med DevOps
Maskininlärningsåtgärder skiljer sig från DevOps inom flera viktiga områden. Maskininlärningsåtgärder har följande egenskaper:
- Utforskning föregår utveckling och drift.
- Livscykeln för datavetenskap kräver ett anpassningsbart sätt att arbeta.
- Gränser för förlopp för datakvalitet och tillgänglighetsgräns.
- En större driftsinsats krävs än i DevOps.
- Arbetsteam kräver specialister och domänexperter.
En sammanfattning finns i de sju principerna för maskininlärningsåtgärder.
Prospektering föregår utveckling och drift
Datavetenskapsprojekt skiljer sig från programutveckling eller datateknikprojekt. Ett datavetenskapsprojekt kan ta sig till produktion, men ofta är fler steg inblandade än i en traditionell distribution. Efter en inledande analys kan det bli tydligt att affärsresultatet inte kan uppnås med tillgängliga datauppsättningar. En mer detaljerad utforskningsfas är vanligtvis det första steget i ett datavetenskapsprojekt.
Målet med utforskningsfasen är att definiera och förfina problemet. Under den här fasen kör dataforskare undersökande dataanalys. De använder statistik och visualiseringar för att bekräfta eller förfalska problemhypoteserna. Intressenterna bör förstå att projektet kanske inte sträcker sig längre än till den här fasen. Samtidigt är det viktigt att göra den här fasen så smidig som möjligt för en snabb vändning. Om inte problemet att lösa innehåller ett säkerhetselement bör du undvika att begränsa den undersökande fasen med processer och procedurer. Dataexperter bör få arbeta med de verktyg och data som de föredrar. Verkliga data behövs för det här undersökande arbetet.
Projektet kan övergå till experimenterings- och utvecklingsstegen när intressenterna är övertygade om att data science-projektet är genomförbart och kan ge verkligt affärsvärde. I det här skedet blir utvecklingsmetoderna allt viktigare. Det är en bra idé att samla in mått för alla experiment som görs i det här skedet. Det är också viktigt att använda källkontroll så att du kan jämföra modeller och växla mellan olika versioner av koden.
Utvecklingsaktiviteter omfattar refaktorisering, testning och automatisering av utforskningskod i repeterbara experimenteringspipelines. Organisationen måste skapa program och pipelines för att hantera modellerna. Genom att omstrukturera kod i modulära komponenter och bibliotek kan du öka återanvändning, testning och prestandaoptimering.
Slutligen distribueras de program- eller batchinferenspipelines som betjänar modellerna till mellanlagrings- eller produktionsmiljöer. Förutom att övervaka infrastrukturens tillförlitlighet och prestanda som för ett standardprogram, måste du i en distribution av maskininlärningsmodeller kontinuerligt övervaka kvaliteten på data, dataprofilen och modellen för försämring eller drift. Maskininlärningsmodeller kräver också omträning över tid för att förbli relevanta i en föränderlig miljö.
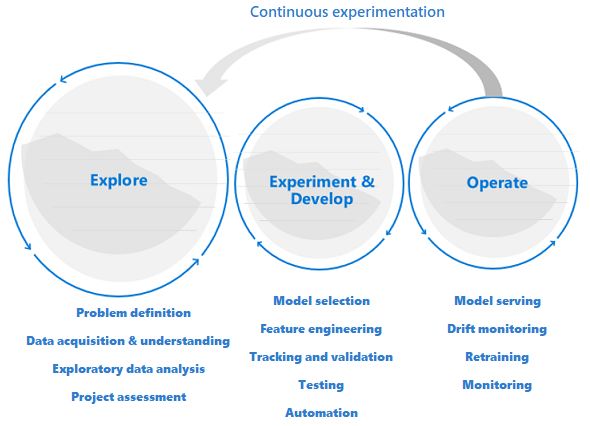
Data science lifecycle kräver ett anpassningsbart sätt att arbeta
Eftersom datas natur och kvalitet från början är osäkra kanske du inte uppnår dina affärsmål om du tillämpar en typisk DevOps-process på ett datavetenskapsprojekt. Utforskning och experimentering är återkommande aktiviteter och behov under hela maskininlärningsprocessen. Teams på Microsoft använder en projektlivscykel och en arbetsprocess som återspeglar typen av datavetenskapsspecifika aktiviteter. Team Data Science Process och Data Science Lifecycle Process är exempel på referensimplementeringar.
Gränser för förlopp för datakvalitet och tillgänglighetsgräns
För ett maskininlärningsteam för att effektivt utveckla maskininlärningsinfunderade program är åtkomst till produktionsdata att föredra för alla relevanta arbetsmiljöer. Om åtkomst till produktionsdata inte är möjlig på grund av efterlevnadskrav eller tekniska begränsningar bör du överväga att implementera rollbaserad åtkomstkontroll i Azure (Azure RBAC) med Azure Mašinsko učenje, just-in-time-åtkomst eller pipelines för dataflytt för att skapa produktionsdatarepliker och förbättra användarproduktiviteten.
Maskininlärning kräver en större driftsinsats
Till skillnad från traditionell programvara är prestandan för en maskininlärningslösning ständigt i fara eftersom lösningen är beroende av datakvalitet. För att upprätthålla en kvalitativ lösning i produktion är det viktigt att du kontinuerligt övervakar och omvärderar både data- och modellkvaliteten. En produktionsmodell förväntas kräva omträning, omdistribution och justering i tid. De här uppgifterna gäller utöver den dagliga säkerheten, övervakningen av infrastrukturen och efterlevnadskraven, och de kräver särskild expertis.
Maskininlärningsteam kräver specialister och domänexperter
Även om datavetenskapsprojekt delar roller med vanliga IT-projekt, beror framgången för en maskininlärningsinsats starkt på att ha viktiga maskininlärningsteknikspecialister och domänämnesexperter. En teknikspecialist har rätt bakgrund för att utföra maskininlärningsexperiment från slutpunkt till slutpunkt. En domänexpert kan stödja specialisten genom att analysera och syntetisera data eller genom att kvalificera data för användning.
Vanliga tekniska roller som är unika för datavetenskapsprojekt är domänexpert, datatekniker, dataexpert, AI-tekniker, modellverifierare och maskininlärningstekniker. Mer information om roller och uppgifter i ett typiskt datavetenskapsteam finns i Team Data Science Process.
Sju principer för maskininlärningsåtgärder
När du planerar att införa maskininlärningsåtgärder i din organisation bör du överväga att tillämpa följande grundläggande principer som grund:
Använd versionskontroll för utdata för kod, data och experimentering. Till skillnad från traditionell programvaruutveckling har data en direkt inverkan på kvaliteten på maskininlärningsmodeller. Du bör version din experimenteringskodbas, men även version dina datauppsättningar för att säkerställa att du kan återskapa experiment eller slutsatsdragningsresultat. Versionsexperimentutdata som modeller kan spara arbete och beräkningskostnaden för att återskapa dem.
Använd flera miljöer. Om du vill separera utveckling och testning från produktionsarbete replikerar du infrastrukturen i minst två miljöer. Åtkomstkontroll för användare kan vara olika för varje miljö.
Hantera infrastrukturen och konfigurationerna som kod. När du skapar och uppdaterar infrastrukturkomponenter i dina arbetsmiljöer använder du infrastruktur som kod, så inkonsekvenser utvecklas inte i dina miljöer. Hantera jobbspecifikationer för maskininlärningsexperiment som kod så att du enkelt kan köra och återanvända en version av experimentet i flera miljöer.
Spåra och hantera maskininlärningsexperiment. Spåra viktiga prestandaindikatorer och andra artefakter för dina maskininlärningsexperiment. När du har en historik över jobbprestanda kan du göra en kvantitativ analys av lyckade experiment och förbättra teamsamarbetet och flexibiliteten.
Testa kod, verifiera dataintegritet och säkerställa modellkvalitet. Testa din experimenteringskodbas för korrekt dataförberedelse och extrahering av funktioner, dataintegritet och modellprestanda.
Kontinuerlig integrering och leverans av maskininlärning. Använd kontinuerlig integrering (CI) för att automatisera testningen för ditt team. Inkludera modellträning som en del av pipelines för kontinuerlig träning. Inkludera A/B-testning som en del av din version för att säkerställa att endast en kvalitativ modell används i produktion.
Övervaka tjänster, modeller och data. När du hanterar modeller i en maskininlärningsmiljö är det viktigt att övervaka tjänsterna för infrastrukturens drifttid, efterlevnad och modellkvalitet. Konfigurera övervakning för att identifiera data och modellavvikelser och för att förstå om omträning krävs. Överväg att konfigurera utlösare för automatisk omträning.
Metodtips från Azure Mašinsko učenje
Azure Mašinsko učenje erbjuder tillgångshantering, orkestrering och automatiseringstjänster som hjälper dig att hantera livscykeln för tränings- och distributionsarbetsflöden för maskininlärningsmodeller. Granska metodtipsen och rekommendationerna för att tillämpa maskininlärningsåtgärder inom resursområdena personer, processer och teknik, som alla stöds av Azure Mašinsko učenje.
Personer
Arbeta i projektteam för att på bästa sätt använda specialist- och domänkunskaper i din organisation. Konfigurera Azure Mašinsko učenje-arbetsytor för varje projekt för att uppfylla kraven på uppdelning av användningsfall.
Definiera en uppsättning ansvarsområden och uppgifter som en roll så att alla teammedlemmar i ett projektteam för maskininlärningsåtgärder kan tilldelas till och uppfylla flera roller. Använd anpassade roller i Azure för att definiera en uppsättning detaljerade Azure RBAC-åtgärder för Azure Mašinsko učenje som varje roll kan utföra.
Standardisera på en projektlivscykel och agil metodik. Team Data Science Process tillhandahåller en referenslivscykelimplementering.
Balanserade team kan köra alla faser för maskininlärningsåtgärder, inklusive utforskning, utveckling och åtgärder.
Process
Standardisera på en kodmall för återanvändning av kod och för att påskynda upptakten i ett nytt projekt eller när en ny gruppmedlem ansluter till projektet. Använd Azure Mašinsko učenje pipelines, jobböverföringsskript och CI/CD-pipelines som grund för nya mallar.
Använd versionskontroll. Jobb som skickas från en Git-backad mapp spårar automatiskt lagringsplatsens metadata med jobbet i Azure Mašinsko učenje för reproducerbarhet.
Använd versionshantering för experimentindata och utdata för reproducerbarhet. Använd Azure Mašinsko učenje-datauppsättningar, modellhantering och miljöhanteringsfunktioner för att underlätta versionshantering.
Skapa en körningshistorik för experimentkörningar för jämförelse, planering och samarbete. Använd ett ramverk för experimentspårning som MLflow för att samla in mått.
Mät och kontrollera kontinuerligt kvaliteten på teamets arbete via CI på den fullständiga experimenteringskodbasen.
Avsluta träningen tidigt i processen när en modell inte konvergerar. Använd ett ramverk för experimentspårning och körningshistoriken i Azure Mašinsko učenje för att övervaka jobbkörningar.
Definiera en strategi för experiment- och modellhantering. Överväg att använda ett namn som champion för att referera till den aktuella baslinjemodellen. En utmanarmodell är en kandidatmodell som kan överträffa mästarmodellen i produktionen. Använd taggar i Azure Mašinsko učenje för att markera experiment och modeller. I ett scenario som försäljningsprognoser kan det ta månader att avgöra om modellens förutsägelser är korrekta.
Höja CI för kontinuerlig träning genom att inkludera modellträning i bygget. Börja till exempel modellträningen på den fullständiga datamängden med varje pull-begäran.
Förkorta den tid det tar att få feedback om kvaliteten på maskininlärningspipelinen genom att köra en automatiserad version av ett dataexempel. Använd Azure Mašinsko učenje pipelineparametrar för att parametrisera indatauppsättningar.
Använd kontinuerlig distribution (CD) för maskininlärningsmodeller för att automatisera distribution och testning av realtidsbedömningstjänster i dina Azure-miljöer.
I vissa reglerade branscher kan du behöva slutföra modellverifieringssteg innan du kan använda en maskininlärningsmodell i en produktionsmiljö. Att automatisera valideringsstegen kan påskynda leveranstiden. När manuella gransknings- eller valideringssteg fortfarande är en flaskhals bör du överväga om du kan certifiera den automatiserade modellverifieringspipelinen. Använd resurstaggar i Azure Mašinsko učenje för att ange tillgångsefterlevnad och kandidater för granskning eller som utlösare för distribution.
Träna inte om i produktion och ersätt sedan produktionsmodellen direkt utan integreringstestning. Även om modellprestanda och funktionskrav kan verka bra, kan en omtränad modell bland annat ha ett större miljöavtryck och bryta servermiljön.
När åtkomst till produktionsdata endast är tillgänglig i produktion använder du Azure RBAC och anpassade roller för att ge ett visst antal maskininlärningsutövare läsåtkomst. Vissa roller kan behöva läsa data för relaterad datautforskning. Du kan också göra en datakopia tillgänglig i icke-produktionsmiljöer.
Kom överens om namngivningskonventioner och taggar för Azure Mašinsko učenje experiment för att skilja omträning av maskininlärningspipelines från experimentellt arbete.
Teknik
Om du för närvarande skickar jobb via Azure Mašinsko učenje Studio UI eller CLI använder du CLI- eller Azure DevOps-Mašinsko učenje uppgifter i stället för att skicka jobb via SDK:t för att konfigurera steg för automatiseringspipeline. Den här processen kan minska kodens fotavtryck genom att återanvända samma jobböverföringar direkt från automationspipelines.
Använd händelsebaserad programmering. Du kan till exempel utlösa en offlinemodelltestningspipeline med hjälp av Azure Functions när en ny modell har registrerats. Eller skicka ett meddelande till ett angivet e-postalias när en kritisk pipeline inte kan köras. Azure Mašinsko učenje skapar händelser i Azure Event Grid. Flera roller kan prenumerera för att meddelas om en händelse.
När du använder Azure DevOps för automatisering använder du Azure DevOps Tasks for Mašinsko učenje för att använda maskininlärningsmodeller som pipelineutlösare.
När du utvecklar Python-paket för ditt maskininlärningsprogram kan du vara värd för dem på en Azure DevOps-lagringsplats som artefakter och publicera dem som ett flöde. Med den här metoden kan du integrera DevOps-arbetsflödet för att skapa paket med din Azure Mašinsko učenje-arbetsyta.
Överväg att använda en mellanlagringsmiljö för att testa systemintegrering av maskininlärningspipelines med överordnade eller underordnade programkomponenter.
Skapa enhets- och integreringstester för dina slutpunkter för slutsatsdragning för förbättrad felsökning och för att påskynda tiden till distributionen.
Om du vill utlösa omträning använder du övervakare av datauppsättningar och händelsedrivna arbetsflöden. Prenumerera på dataavvikelsehändelser och automatisera utlösaren av maskininlärningspipelines för omträning.
AI-fabrik för organisationens maskininlärningsåtgärder
Ett datavetenskapsteam kan besluta att det kan hantera flera användningsfall för maskininlärning internt. Genom att införa maskininlärningsåtgärder kan en organisation konfigurera projektteam för bättre kvalitet, tillförlitlighet och underhåll av lösningar. Genom balanserade team, processer som stöds och teknikautomatisering kan ett team som implementerar maskininlärningsåtgärder skala och fokusera på att utveckla nya användningsfall.
I takt med att antalet användningsfall växer i en organisation växer hanteringsbördan för att stödja användningsfall linjärt, eller ännu mer. Utmaningen för organisationen blir hur du kan påskynda tiden till marknaden, stödja snabbare utvärdering av genomförbarhet av användningsfall, implementera repeterbarhet och använda tillgängliga resurser och färdigheter på bästa sätt i en rad olika projekt. För många organisationer är det lösningen att utveckla en AI-fabrik.
En AI-fabrik är ett system med repeterbara affärsprocesser och standardiserade artefakter som underlättar utveckling och distribution av en stor uppsättning användningsfall för maskininlärning. En AI-fabrik optimerar teamkonfiguration, rekommenderade metoder, strategi för maskininlärningsåtgärder, arkitekturmönster och återanvändbara mallar som är skräddarsydda för affärskrav.
En lyckad AI-fabrik förlitar sig på repeterbara processer och återanvändbara tillgångar för att hjälpa organisationen att effektivt skala från tiotals användningsfall till tusentals användningsfall.
Följande bild sammanfattar viktiga element i en AI-fabrik:

Standardisera på repeterbara arkitekturmönster
Repeterbarhet är en viktig egenskap hos en AI-fabrik. Datavetenskapsteam kan påskynda projektutvecklingen och förbättra konsekvensen mellan projekt genom att utveckla några repeterbara arkitekturmönster som täcker de flesta maskininlärningsanvändningsfallen för organisationen. När dessa mönster finns på plats kan de flesta projekt använda mönstren för att få följande fördelar:
- Accelererad designfas
- Påskyndade godkännanden från IT- och säkerhetsteam när de återanvänder verktyg i olika projekt
- Accelererad utveckling på grund av återanvändbar infrastruktur som kodmallar och projektmallar
Arkitekturmönstren kan innehålla men är inte begränsade till följande ämnen:
- Föredragna tjänster för varje fas i projektet
- Dataanslutning och styrning
- En strategi för maskininlärningsåtgärder som är skräddarsydd för kraven i branschen, verksamheten eller dataklassificeringen
- Modeller för experimenthanteringsmästare och utmanare
Underlätta samarbete och delning mellan team
Lagringsplatser och verktyg för delad kod kan påskynda utvecklingen av maskininlärningslösningar. Kodlagringsplatser kan utvecklas på ett modulärt sätt under projektutvecklingen så att de är tillräckligt generiska för att kunna användas i andra projekt. De kan göras tillgängliga på en central lagringsplats som alla datavetenskapsteam kan komma åt.
Dela och återanvänd immateriella rättigheter
Om du vill maximera återanvändningen av kod granskar du följande immateriella rättigheter i början av ett projekt:
- Intern kod som har utformats för återanvändning i organisationen. Exempel är paket och moduler.
- Datauppsättningar som har skapats i andra maskininlärningsprojekt eller som är tillgängliga i Azure-ekosystemet.
- Befintliga datavetenskapsprojekt som har liknande arkitektur och affärsproblem.
- GitHub- eller lagringsplatser med öppen källkod som kan påskynda projektet.
Alla projekt i efterhand bör innehålla ett åtgärdsobjekt för att avgöra om element i projektet kan delas och generaliseras för bredare återanvändning. Listan över tillgångar som organisationen kan dela och återanvända utökas över tid.
För att hjälpa till med delning och identifiering har många organisationer introducerat delade lagringsplatser för att organisera kodfragment och maskininlärningsartefakter. Artefakter i Azure Mašinsko učenje, inklusive datauppsättningar, modeller, miljöer och pipelines, kan definieras som kod, så att du kan dela dem effektivt mellan projekt och arbetsytor.
Projektmallar
För att påskynda migreringen av befintliga lösningar och maximera återanvändningen av kod standardiserar många organisationer på en projektmall för att starta nya projekt. Exempel på projektmallar som rekommenderas för användning med Azure Mašinsko učenje är Azure Mašinsko učenje exempel, Data Science Lifecycle Process och Team Data Science Process.
Central datahantering
Det kan vara tidskrävande att få åtkomst till data för utforskning eller produktionsanvändning. Många organisationer centraliserar datahantering för att sammanföra dataproducenter och datakonsumenter för enklare åtkomst till data för maskininlärningsexperiment.
Delade verktyg
Din organisation kan använda centraliserade instrumentpaneler för hela företaget för att konsolidera loggnings- och övervakningsinformation. Instrumentpanelerna kan innehålla felloggning, tjänsttillgänglighet och telemetri samt övervakning av modellprestanda.
Använd Azure Monitor-mått för att skapa en instrumentpanel för Azure Mašinsko učenje och associerade tjänster som Azure Storage. En instrumentpanel hjälper dig att hålla reda på experimenteringsförloppet, hälsotillståndet för beräkningsinfrastrukturen och GPU-kvotanvändningen.
Specialistteam för maskininlärning
Många organisationer har implementerat rollen maskininlärningstekniker. En maskininlärningstekniker är specialiserad på att skapa och köra robusta maskininlärningspipelines, driftövervakning och omträning av arbetsflöden och övervakning av instrumentpaneler. Ingenjören har det övergripande ansvaret för att industrialisera maskininlärningslösningen, från utveckling till produktion. Teknikern arbetar nära datateknik, arkitekter, säkerhet och åtgärder för att säkerställa att alla nödvändiga kontroller finns på plats.
Även om datavetenskap kräver djup domänexpertis är maskininlärningsteknik mer tekniskt i fokus. Skillnaden gör maskininlärningsteknikern mer flexibel, så att de kan arbeta med olika projekt och med olika affärsavdelningar. Stora datavetenskapsmetoder kan dra nytta av ett specialiserat maskininlärningsteam som driver repeterbarhet och återanvändning av automatiseringsarbetsflöden i olika användningsfall och affärsområden.
Aktivering och dokumentation
Det är viktigt att ge tydlig vägledning om AI-fabriksprocessen för nya och befintliga team och användare. Vägledningen hjälper till att säkerställa konsekvens och minska det arbete som krävs från maskininlärningsteamet när det industrialiserar ett projekt. Överväg att utforma innehåll specifikt för de olika rollerna i din organisation.
Alla har ett unikt sätt att lära sig, så en blandning av följande typer av vägledning kan hjälpa till att påskynda implementeringen av AI-fabriksramverket:
- En central hubb som har länkar till alla artefakter. Den här hubben kan till exempel vara en kanal på Microsoft Teams eller en Microsoft SharePoint-webbplats.
- Utbildning och en aktiveringsplan som utformats för varje roll.
- En sammanfattningspresentation på hög nivå av metoden och en tillhörande video.
- Ett detaljerat dokument eller en spelbok.
- Instruktioner för videor.
- Beredskapsutvärderingar.
Maskininlärningsåtgärder i Azure-videoserie
En videoserie om maskininlärningsåtgärder i Azure visar hur du etablerar maskininlärningsåtgärder för din maskininlärningslösning, från inledande utveckling till produktion.
Etik
Etik spelar en avgörande roll i utformningen av en AI-lösning. Om etiska principer inte implementeras kan tränade modeller uppvisa samma bias som finns i de data som de har tränats på. Resultatet kan vara att projektet har upphört. Ännu viktigare är att organisationens rykte kan vara i fara.
För att säkerställa att de viktigaste etiska principerna som organisationen står för implementeras mellan projekt bör organisationen tillhandahålla en lista över dessa principer och sätt att validera dem från ett tekniskt perspektiv under testfasen. Använd maskininlärningsfunktionerna i Azure Mašinsko učenje för att förstå vad ansvarsfull maskininlärning är och hur du bygger in den i dina maskininlärningsåtgärder.
Nästa steg
Läs mer om hur du organiserar och konfigurerar Azure Mašinsko učenje miljöer eller tittar på en praktisk videoserie om maskininlärningsåtgärder i Azure.
Läs mer om hur du hanterar budgetar, kvoter och kostnader på organisationsnivå med hjälp av Azure Mašinsko učenje: