Vad är SQL Data Sync för Azure?
gäller för:![]() Azure SQL Database
Azure SQL Database
Viktig
SQL Data Sync dras tillbaka den 30 september 2027. Överväg att migrera till alternativa lösningar för datareplikering/synkronisering.
SQL Data Sync är en tjänst som bygger på Azure SQL Database som gör att du kan synkronisera de data som du väljer dubbelriktad över flera databaser, både lokalt och i molnet.
Azure SQL Data Sync stöder inte Azure SQL Managed Instance eller Azure Synapse Analytics.
Överblick
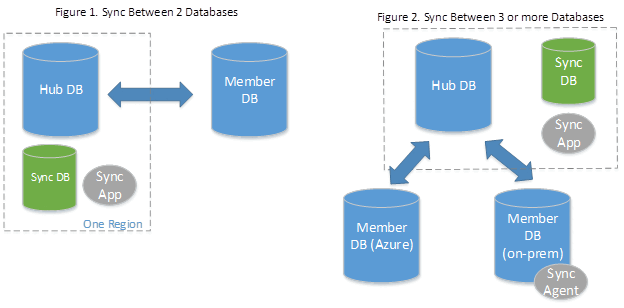
Datasynkronisering baseras på begreppet synkroniseringsgrupp. En synkroniseringsgrupp är en grupp databaser som du vill synkronisera.
Data Sync använder en hubb- och ekertopologi för att synkronisera data. Du definierar en av databaserna i synkroniseringsgruppen som hubbdatabas. Resten av databaserna är medlemsdatabaser. Synkronisering sker endast mellan hubben och enskilda medlemmar.
- Hub Database måste vara en Azure SQL Database.
- medlemsdatabaser kan vara antingen Azure SQL-databaser eller instanser av SQL Server.
- Sync Metadata Database innehåller metadata och loggen för datasynkronisering. Databasen för synkroniseringsmetadata måste vara en Azure SQL Database som finns i samma region som hubbdatabasen. Databasen för synkroniseringsmetadata är skapad av kunder och ägd av kunder. Du kan bara ha en databas för synkroniseringsmetadata per region och prenumeration. Det går inte att ta bort eller byta namn på synkroniseringsmetadatadatabasen när synkroniseringsgrupper eller synkroniseringsagenter finns. Microsoft rekommenderar att du skapar en ny, tom databas som ska användas som databas för synkroniseringsmetadata. Data Sync skapar tabeller i den här databasen och kör en frekvent arbetsbelastning.
Not
Om du använder en lokal databas som en medlemsdatabas måste du installera och konfigurera en lokal synkroniseringsagent.
En synkroniseringsgrupp har följande egenskaper:
- I Synkroniseringsschema beskrivs vilka data som synkroniseras.
- Synkroniseringsriktning kan vara dubbelriktad eller kan endast flöda i en riktning. Det vill säga: Synkroniseringsriktningen kan vara antingen hubb till medlem, eller medlem till hubb, eller båda.
- Synkroniseringsintervall beskriver hur ofta synkronisering sker.
- Konfliktlösningspolicy är en gruppolicy som kan vara Hubbvinst eller Medlemsvinst.
När du ska använda
Datasynkronisering är användbart i de fall där data måste uppdateras i flera databaser i Azure SQL Database eller SQL Server. Här är de viktigaste användningsfallen för datasynkronisering:
- Hybrid Data Synchronization: Med Data Sync kan du hålla data synkroniserade mellan dina databaser i SQL Server och Azure SQL Database för att aktivera hybridprogram. Den här funktionen kan tilltala kunder som funderar på att flytta till molnet och som vill placera en del av sitt program i Azure.
- Distribuerade program: I många fall är det fördelaktigt att separera olika arbetsbelastningar mellan olika databaser. Om du till exempel har en stor produktionsdatabas, men du också behöver köra en rapporterings- eller analysarbetsbelastning på dessa data, är det bra att ha en andra databas för den här extra arbetsbelastningen. Den här metoden minimerar prestandapåverkan på din produktionsarbetsbelastning. Du kan använda Data Sync för att synkronisera dessa två databaser.
- Globalt distribuerade program: Många företag omfattar flera regioner och till och med flera länder/regioner. För att minimera nätverksfördröjningen är det bäst att ha dina data i en region nära dig. Med Data Sync kan du enkelt synkronisera databaser i regioner runt om i världen.
Datasynkronisering är inte den bästa lösningen för följande scenarier:
| Scenario | Vissa rekommenderade lösningar |
|---|---|
| Katastrofåterställning | Automatiserade säkerhetskopieringar i Azure SQL Database |
| Lässkala | Använd skrivskyddade repliker för att avlasta frågebelastningar |
| ETL (OLTP till OLAP) | Azure Data Factory eller SQL Server Integration Services |
| Migrering från SQL Server till Azure SQL Database. SQL Data Sync kan dock användas när migreringen har slutförts för att säkerställa att källan och målet hålls synkroniserade. | Azure Database Migration Service |
Så här fungerar det
- Spåra dataändringar: Data Sync spårar ändringar med utlösare för infoga, uppdatera och ta bort. Ändringarna registreras i en sidotabell i användardatabasen. BULK INSERT utlöser inte utlösare som standard. Om FIRE_TRIGGERS inte har angetts körs inga infogningsutlösare. Lägg till alternativet FIRE_TRIGGERS så att Data Sync kan spåra dessa infogningar.
- Synkronisering av data: Data Sync har utformats i en hubb- och ekermodell. Hubben synkroniseras med varje medlem individuellt. Ändringar från hubben laddas ned till medlemmen och sedan laddas ändringar från medlemmen upp till hubben.
-
Att lösa konflikter: Data Sync innehåller två alternativ för konfliktlösning, Hub vinner eller Medlem vinner.
- Om du väljer Hub vinnerskriver ändringarna i hubben alltid över ändringar i medlemmen.
- Om du väljer Medlem vinner, överskriver ändringarna i medlemmen ändringarna i hubben. Om det finns fler än en medlem beror det slutliga värdet på vilken medlem som synkroniseras först.
Jämför med transaktionsreplikering
| Datasynkronisering | Transaktionsreplikering | |
|---|---|---|
| Fördelar | – Aktivt stöd – Dubbelriktad mellan lokal SQL-databas och Azure SQL Database |
- Kortare svarstid – Transaktionskonsekvens – Återanvänd befintlig topologi efter migrering -Stöd för Azure SQL Managed Instance |
| Nackdelar | – Ingen transaktionskonsekvens – Högre prestandapåverkan |
– Det går inte att publicera från Azure SQL Database – Höga underhållskostnader |
Privat länk för datasynkronisering
Anteckning
Den privata länken för SQL Data Sync skiljer sig från Azure Private Link-.
Med den nya funktionen privat länk kan du välja en tjänsthanterad privat slutpunkt för att upprätta en säker anslutning mellan synkroniseringstjänsten och dina medlems-/hubbdatabaser under datasynkroniseringsprocessen. En tjänsthanterad privat slutpunkt är en privat IP-adress i ett specifikt virtuellt nätverk och undernät. I Data Sync skapas den tjänsthanterade privata slutpunkten av Microsoft och används exklusivt av datasynkroniseringstjänsten för en viss synkroniseringsåtgärd.
Innan du konfigurerar den privata länken läser du allmänna krav för funktionen.

Note
Du måste godkänna den tjänsthanterade privata slutpunkten manuellt på sidan privata slutpunktsanslutningar i Azure-portalen under distributionen av synkroniseringsgruppen eller med hjälp av PowerShell.
Sätta igång
Konfigurera datasynkronisering i Azure-portalen
- Självstudie: Konfigurera SQL Data Sync mellan databaser i Azure SQL Database och SQL Server
- Data Sync-agent – Data Sync-agent för SQL-datasynkronisering
Konfigurera datasynkronisering med PowerShell
- Använda PowerShell för att synkronisera data mellan flera databaser i Azure SQL Database
- Använda PowerShell för att synkronisera data mellan SQL Database och SQL Server
Konfigurera datasynkronisering med REST API
Granska metodtipsen för datasynkronisering
Gick något fel
Konsekvens och prestanda
Eventuell konsistens
Eftersom Data Sync är utlösarbaserat garanteras inte transaktionskonsekvens. Microsoft garanterar att alla ändringar görs så småningom och att Data Sync inte orsakar dataförlust.
Prestandapåverkan
Data Sync använder utlösare för att infoga, uppdatera och ta bort för att spåra ändringar. Den skapar sidotabeller i användardatabasen för ändringsspårning. Dessa ändringsspårningsaktiviteter påverkar databasarbetsbelastningen. Utvärdera tjänstnivån och uppgradera om det behövs.
Provisionering och avprovisionering när synkroniseringsgruppen skapas, uppdateras och raderas kan också påverka databasens prestanda.
Krav och begränsningar
Allmänna krav
- Varje tabell måste ha en primärnyckel. Ändra inte värdet för primärnyckeln på någon rad. Om du måste ändra ett primärnyckelvärde tar du bort raden och återskapar den med det nya primärnyckelvärdet.
Viktig
Om du ändrar värdet för en befintlig primärnyckel resulterar det i följande felaktiga beteende:
- Data mellan hubben och medlemmen kan gå förlorade även om synkroniseringen inte rapporterar något problem.
- Synkroniseringen kan misslyckas eftersom spårningstabellen har en icke-befintlig rad från källan på grund av den primära nyckeländringen.
Isolering av ögonblicksbilder måste vara aktiverat för både Sync-medlemmar och hubb. För mer information, se Ögonblicksbildisolering i SQL Server.
För att kunna använda en privat datasynkron länk måste både medlems- och hubbdatabaserna finnas i Azure (samma eller olika regioner) i samma molntyp (till exempel både i det offentliga molnet eller i båda i myndighetsmolnet). Om du vill använda en privat länk måste
Microsoft.Networkresursprovidrar dessutom vara registrerade för de prenumerationer som är värdar för hubb- och medlemsservrarna. Slutligen måste du godkänna den privata länken för Data Sync manuellt under synkroniseringskonfigurationen, i avsnittet "Privata slutpunktsanslutningar" i Azure-portalen eller via PowerShell. Mer information om hur du godkänner den privata länken finns i Självstudie: Konfigurera SQL Data Sync mellan databaser i Azure SQL Database och SQL Server. När du har godkänt den tjänsthanterade privata slutpunkten sker all kommunikation mellan synkroniseringstjänsten och medlems-/hubbdatabaserna via den privata länken. Befintliga synkroniseringsgrupper kan uppdateras så att den här funktionen är aktiverad.
Allmänna begränsningar
- En tabell kan inte ha en identitetskolumn som inte är primärnyckeln.
- En primärnyckel kan inte ha följande datatyper: sql_variant, binära, varbinary, image, xml.
- Var försiktig när du använder följande datatyper som primärnyckel eftersom de endast stöder precision till sekunden: tid, datetime, datetime2, datetimeoffset.
- Namnen på objekt (databaser, tabeller och kolumner) får inte innehålla den utskrivbara teckenperioden (
.), vänster hakparentes ([) eller höger hakparentes (]). - Ett tabellnamn får inte innehålla utskrivbara tecken:
! " # $ % ' ( ) * + -eller blanksteg. - Microsoft Entra -autentisering (tidigare Azure Active Directory) stöds inte.
- Om det finns tabeller med samma namn men ett annat schema (till exempel
dbo.customersochsales.customers) kan bara en av tabellerna läggas till i synkronisering. - Kolumner med användardefinierade datatyper stöds inte.
- Det går inte att flytta servrar mellan olika prenumerationer.
- Om två primära nycklar bara skiljer sig åt om (till exempel
Fooochfoo) stöder Data Sync inte det här scenariot. - Trunkering av tabeller är inte en åtgärd som stöds av Data Sync (ändringar spåras inte).
- Det går inte att använda en Azure SQL Hyperscale-databas som en hubb- eller synkroniseringsmetadatadatabas. En Hyperskala-databas kan dock vara en medlemsdatabas i en datasynkroniseringstopologi.
- Minnesoptimerade tabeller stöds inte.
- Schemaändringar replikeras inte automatiskt.
- Data Sync stöder endast följande två indexegenskaper: Unik, Klustrad/Icke-klustrad. Andra egenskaper för ett index, till exempel
IGNORE_DUP_KEYellerWHEREfilterpredikat, stöds inte och målindexet etableras utan dessa egenskaper även om källindexet har dessa egenskaper angivna. - En Azure Elastic Jobs-databas kan inte användas som SQL Data Sync-metadatadatabas och vice versa.
- SQL Data Sync stöds inte för transaktionsregisterdatabaser.
Datatyper som inte stöds
- FileStream
- SQL/CLR UDT
- XMLSchemaCollection (XML stöds)
- Cursor, RowVersion, Timestamp, Hierarchyid
Kolumntyper som inte stöds
Data Sync kan inte synkronisera skrivskyddade eller systemgenererade kolumner. Till exempel:
- Beräknade kolumner.
- Systemgenererade kolumner för temporala tabeller.
Begränsningar för tjänst- och databasdimensioner
| Dimensioner | Gräns | Tillfällig lösning |
|---|---|---|
| Maximalt antal synkroniseringsgrupper som en databas kan tillhöra. | 5 | |
| Maximalt antal slutpunkter i en enskild synkroniseringsgrupp | 30 | |
| Maximalt antal lokala slutpunkter i en enda synkroniseringsgrupp. | 5 | Skapa flera synkroniseringsgrupper |
| Databas-, tabell-, schema- och kolumnnamn | 50 tecken per namn | |
| Tabeller i en synkroniseringsgrupp | 500 | Skapa flera synkroniseringsgrupper |
| Kolumner i en tabell i en synkroniseringsgrupp | 1000 | |
| Dataradsstorlek i en tabell | 24 Mb |
Notera
Det kan finnas upp till 30 slutpunkter i en enda synkroniseringsgrupp om det bara finns en synkroniseringsgrupp. Om det finns fler än en synkroniseringsgrupp får det totala antalet slutpunkter i alla synkroniseringsgrupper inte överstiga 30. Om en databas tillhör flera synkroniseringsgrupper räknas den som flera slutpunkter, inte en.
Nätverkskrav
Not
Om du använder Synkronisera privat länk gäller inte dessa nätverkskrav.
När synkroniseringsgruppen har upprättats måste datasynkroniseringstjänsten ansluta till hubbdatabasen. När du upprättar synkroniseringsgruppen måste Azure SQL-servern ha följande konfiguration i sina Firewalls and virtual networks inställningar:
- Neka åtkomst till offentligt nätverk måste anges till Av.
- Tillåt att Azure-tjänster och resurser får åtkomst till den här servern måste anges till Ja, eller så måste du skapa IP-regler för IP-adresser som används av Data Sync-tjänsten.
När synkroniseringsgruppen har skapats och etablerats kan du sedan inaktivera de här inställningarna. Synkroniseringsagenten ansluter direkt till hubbdatabasen och du kan använda serverns brandväggs-IP-regler eller privata slutpunkter för att tillåta agenten att komma åt hubbservern.
Not
Om du ändrar synkroniseringsgruppens schemainställningar måste du tillåta att datasynkroniseringstjänsten får åtkomst till servern igen så att hubbdatabasen kan etableras på nytt.
Regiondatahemvist
Om du synkroniserar data inom samma region lagrar/bearbetar INTE SQL Data Sync kunddata utanför den region där tjänstinstansen distribueras. Om du synkroniserar data mellan olika regioner replikerar SQL Data Sync kunddata till de kopplade regionerna.
Vanliga frågor och svar om SQL Data Sync
Hur mycket kostar SQL Data Sync-tjänsten?
Det kostar ingenting för själva SQL Data Sync-tjänsten. Du kan dock fortfarande samla in dataöverföringsavgifter för dataflytt in och ut från din SQL Database-instans. Mer information finns i dataöverföringsavgifter.
Vilka regioner har stöd för datasynkronisering?
SQL Data Sync är tillgängligt i alla regioner.
Krävs ett SQL Database-konto?
Ja. Du måste ha ett SQL Database-konto som värd för hubbdatabasen.
Kan jag bara använda Data Sync för att synkronisera mellan SQL Server-databaser?
Inte direkt. Du kan dock synkronisera mellan SQL Server-databaser indirekt genom att skapa en hubbdatabas i Azure och sedan lägga till de lokala databaserna i synkroniseringsgruppen.
Kan jag konfigurera Data Sync för synkronisering mellan databaser i Azure SQL Database som tillhör olika prenumerationer?
Ja. Du kan konfigurera synkronisering mellan databaser som tillhör resursgrupper som ägs av olika prenumerationer, även om prenumerationerna tillhör olika klientorganisationer.
- Om prenumerationerna tillhör samma klientorganisation och du har behörighet till alla prenumerationer kan du konfigurera synkroniseringsgruppen i Azure-portalen.
- Annars måste du använda PowerShell för att lägga till synkroniseringsmedlemmar.
Kan jag konfigurera Data Sync för synkronisering mellan databaser i SQL Database som tillhör olika moln (till exempel Azure Public Cloud och Azure som drivs av 21Vianet)?
Ja. Du kan konfigurera synkronisering mellan databaser som tillhör olika moln. Du måste använda PowerShell för att lägga till de synkroniseringsmedlemmar som tillhör de olika prenumerationerna.
Kan jag använda Data Sync för att hämta data från min produktionsdatabas till en tom databas och sedan synkronisera dem?
Ja. Skapa schemat manuellt i den nya databasen genom att skripta det från originalet. När du har skapat schemat lägger du till tabellerna i en synkroniseringsgrupp för att kopiera data och hålla dem synkroniserade.
Ska jag använda SQL Data Sync för att säkerhetskopiera och återställa mina databaser?
Vi rekommenderar inte att du använder SQL Data Sync för att skapa en säkerhetskopia av dina data. Du kan inte säkerhetskopiera och återställa till en viss tidpunkt eftersom SQL Data Sync-synkroniseringar inte är versionshanterade. Dessutom säkerhetskopierar INTE SQL Data Sync andra SQL-objekt, till exempel lagrade procedurer, och gör inte motsvarande en återställningsåtgärd snabbt.
En rekommenderad säkerhetskopieringsteknik finns i Kopiera en transaktionsmässigt konsekvent kopia av en databas i Azure SQL Database.
Kan datasynkronisering synkronisera krypterade tabeller och kolumner?
- Om en databas använder Always Encrypted kan du bara synkronisera tabeller och kolumner som inte krypterade. Du kan inte synkronisera de krypterade kolumnerna eftersom Data Sync inte kan dekryptera data.
- Om en kolumn använder Column-Level Kryptering (CLE) kan du synkronisera kolumnen så länge radstorleken är mindre än den maximala storleken på 24 Mb. Data Sync behandlar kolumnen krypterad med nyckel (CLE) som normala binära data. Om du vill dekryptera data på andra synkroniseringsmedlemmar måste du ha samma certifikat.
Stöds sortering i SQL Data Sync?
Ja. SQL Data Sync stöder konfiguration av sorteringsinställningar i följande scenarier:
- Om de valda synkroniseringsschematabellerna inte redan finns i dina hubb- eller medlemsdatabaser skapar tjänsten automatiskt motsvarande tabeller och kolumner med de sorteringsinställningar som valts i de tomma måldatabaserna när du distribuerar synkroniseringsgruppen.
- Om tabellerna som ska synkroniseras redan finns i både dina hubb- och medlemsdatabaser kräver SQL Data Sync att de primära nyckelkolumnerna har samma sortering mellan hubb- och medlemsdatabaser för att kunna distribuera synkroniseringsgruppen. Det finns inga sorteringsbegränsningar för andra kolumner än primärnyckelkolumnerna.
Stöds federation i SQL Data Sync?
Federationsrotdatabas kan användas i SQL Data Sync-tjänsten utan några begränsningar. Du kan inte lägga till den federerade databasslutpunkten i den aktuella versionen av SQL Data Sync.
Kan jag använda Data Sync för att synkronisera data som exporteras från Dynamics 365 med hjälp av byOD-funktionen (Bring Your Own Database) ?
Med Dynamics 365 bring your own database-funktionen kan administratörer exportera dataentiteter från programmet till sin egen Microsoft Azure SQL-databas. DataSynkronisering kan användas för att synkronisera dessa data till andra databaser om data exporteras med inkrementell push- (fullständig push stöds inte) och aktivera utlösare i måldatabasen har angetts till ja.
Hur skapar jag datasynkronisering i en failover-grupp för att stödja katastrofåterställning?
- För att säkerställa att datasynkroniseringsåtgärderna i redundansregionen är i nivå med den primära regionen måste du efter redundansväxlingen manuellt återskapa synkroniseringsgruppen i redundansregionen med samma inställningar som den primära regionen.
Relaterat innehåll
Övervaka och felsöka
Fungerar SQL Data Sync som förväntat? Information om hur du övervakar aktivitet och felsöker problem finns i följande artiklar:
Läs mer om Azure SQL Database
Mer information om Azure SQL Database finns i följande artiklar:
- Översikt över SQL-databasen
- Livscykelhantering för databaser