Felsöka prestandaproblem med Intelligent Insights – Azure SQL Database och Azure SQL Managed Instance
Gäller för:![]() Azure SQL Database
Azure SQL Database![]() Azure SQL Managed Instance
Azure SQL Managed Instance
Den här sidan innehåller information om prestandaproblem med Azure SQL Database och Azure SQL Managed Instance som identifierats via Resursloggen för Intelligent Insights . Mått och resursloggar kan strömmas till Azure Monitor-loggar, Azure Event Hubs, Azure Storage eller en lösning från tredje part för anpassade DevOps-aviserings- och rapporteringsfunktioner.
Kommentar
En snabb felsökningsguide för prestanda med hjälp av Intelligent Insights finns i Det rekommenderade felsökningsflödets flödesschema i det här dokumentet.
Intelligenta insikter är en förhandsversionsfunktion som inte är tillgänglig i följande regioner: Europa, västra, Europa, norra, USA, västra 1 och USA, östra 1.
Prestandamönster för identifieringsbara databaser
Intelligent Insights identifierar automatiskt prestandaproblem baserat på frågekörningens väntetider, fel eller tidsgränser. Intelligent Insights-utdata identifierade prestandamönster i resursloggen. Detekterbara prestandamönster sammanfattas i tabellen nedan.
| Identifierbara prestandamönster | Azure SQL Database | Hanterad Azure SQL-instans |
|---|---|---|
| Nå resursgränser | Förbrukningen av tillgängliga resurser (DTU:er), databasarbetstrådar eller databasinloggningssessioner som är tillgängliga i den övervakade prenumerationen har nått sina resursgränser. Detta påverkar prestanda. | Förbrukningen av CPU-resurser når sina resursgränser. Detta påverkar databasens prestanda. |
| Arbetsbelastningsökning | Arbetsbelastningsökning eller kontinuerlig ackumulering av arbetsbelastningen i databasen har identifierats. Detta påverkar prestanda. | Arbetsbelastningsökning har identifierats. Detta påverkar databasens prestanda. |
| Minnestryck | Arbetare som begärde minnesbidrag måste vänta på minnestilldelningar under statistiskt betydande mängder tid, eller en ökad ackumulering av arbetare som begärde minnesbidrag finns. Detta påverkar prestanda. | Arbetare som har begärt minnesbidrag väntar på minnesallokeringar under en statistiskt betydande tid. Detta påverkar databasens prestanda. |
| Låsning | Överdriven databaslåsning identifierades som påverkar prestanda. | Överdriven databaslåsning upptäcktes som påverkade databasens prestanda. |
| Ökad MAXDOP | Maximal grad av parallellitetsalternativ (MAXDOP) har ändrats som påverkar frågekörningens effektivitet. Detta påverkar prestanda. | Maximal grad av parallellitetsalternativ (MAXDOP) har ändrats som påverkar frågekörningens effektivitet. Detta påverkar prestanda. |
| Pagelatch-konkurrens | Flera trådar försöker samtidigt komma åt samma minnesinterna databuffertsidor, vilket resulterar i ökade väntetider och orsakar pagelatch-konkurrens. Detta påverkar prestanda. | Flera trådar försöker samtidigt komma åt samma minnesinterna databuffertsidor, vilket resulterar i ökade väntetider och orsakar pagelatch-konkurrens. Detta påverkar databasens prestanda. |
| Index saknas | Det saknade indexet upptäcktes som påverkar prestanda. | Det saknade indexet upptäcktes som påverkar databasens prestanda. |
| Ny fråga | En ny fråga har identifierats som påverkar den övergripande prestandan. | En ny fråga har identifierats som påverkar den övergripande databasprestandan. |
| Ökad väntestatistik | Ökade väntetider för databasen har identifierats som påverkar prestanda. | Ökade väntetider för databasen har identifierats som påverkar databasens prestanda. |
| TempDB-konkurrens | Flera trådar försöker komma åt samma tempdb resurs som orsakar en flaskhals. Detta påverkar prestanda. |
Flera trådar försöker komma åt samma tempdb resurs som orsakar en flaskhals. Detta påverkar databasens prestanda. |
| DTU-brist för elastisk pool | Bristen på tillgängliga eDTU:er i den elastiska poolen påverkar prestandan. | Inte tillgängligt för Azure SQL Managed Instance eftersom den använder modellen med virtuella kärnor. |
| Planera regression | En ny plan eller en ändring i arbetsbelastningen för en befintlig plan har identifierats. Detta påverkar prestanda. | En ny plan eller en ändring i arbetsbelastningen för en befintlig plan har identifierats. Detta påverkar databasens prestanda. |
| Ändring av databasomfattningskonfigurationsvärde | Konfigurationsändring på databasen har identifierats som påverkar databasens prestanda. | Konfigurationsändring på databasen har identifierats som påverkar databasens prestanda. |
| Långsam klient | Den långsamma programklienten kan inte använda utdata från databasen tillräckligt snabbt. Detta påverkar prestanda. | Den långsamma programklienten kan inte använda utdata från databasen tillräckligt snabbt. Detta påverkar databasens prestanda. |
| Nedgradering av prisnivå | Prisnivåns nedgraderingsåtgärd minskade tillgängliga resurser. Detta påverkar prestanda. | Prisnivåns nedgraderingsåtgärd minskade tillgängliga resurser. Detta påverkar databasens prestanda. |
Dricks
Aktivera automatisk justering för kontinuerlig prestandaoptimering av databaser. Den här inbyggda intelligensfunktionen övervakar kontinuerligt din databas, justerar automatiskt index och tillämpar korrigeringar av frågekörningsplan.
I följande avsnitt beskrivs mer detaljerat möjliga prestandamönster.
Nå resursgränser
Vad händer
Det här detekterbara prestandamönstret kombinerar prestandaproblem som är relaterade till att nå tillgängliga resursgränser, arbetsgränser och sessionsgränser. När det här prestandaproblemet har identifierats anger ett beskrivningsfält i diagnostikloggen om prestandaproblemet är relaterat till resurs-, arbets- eller sessionsgränser.
Resurser i Azure SQL Database refereras vanligtvis till DTU - eller vCore-resurser , och resurser på Azure SQL Managed Instance kallas virtuella kärnresurser. Mönstret för att nå resursgränser identifieras när den identifierade frågeprestandaförsämringen orsakas av att någon av de uppmätta resursgränserna har nåtts.
Sessionsbegränsningsresursen anger antalet tillgängliga samtidiga inloggningar till databasen. Det här prestandamönstret identifieras när program som är anslutna till databaserna har nått antalet tillgängliga samtidiga inloggningar till databasen. Om program försöker använda fler sessioner än vad som är tillgängligt i en databas påverkas frågeprestandan.
Att nå arbetsgränser är ett specifikt fall av att nå resursgränser eftersom tillgängliga arbetare inte räknas i DTU- eller vCore-användningen. Om du når arbetsgränserna för en databas kan det leda till att resursspecifika väntetider ökar, vilket leder till försämrad frågeprestanda.
Felsökning
Diagnostikloggen matar ut fråge-hashvärden för frågor som påverkade prestanda- och resursförbrukningsprocenten. Du kan använda den här informationen som utgångspunkt för att optimera databasarbetsbelastningen. I synnerhet kan du optimera de frågor som påverkar prestandaförsämringen genom att lägga till index. Eller så kan du optimera program med en jämnare arbetsbelastningsdistribution. Om du inte kan minska arbetsbelastningar eller göra optimeringar kan du överväga att öka prisnivån för din databasprenumeration för att öka mängden tillgängliga resurser.
Om du har nått de tillgängliga sessionsgränserna kan du optimera dina program genom att minska antalet inloggningar som görs i databasen. Om du inte kan minska antalet inloggningar från dina program till databasen kan du överväga att öka prisnivån för din databasprenumeration. Eller så kan du dela upp och flytta databasen till flera databaser för en mer balanserad arbetsbelastningsdistribution.
Fler förslag på hur du löser sessionsgränser finns i Så här hanterar du gränserna för maximala inloggningar. Se Översikt över resursbegränsningar på en server för information om gränser på server- och prenumerationsnivå.
Ökad arbetsbelastning
Vad händer
Det här prestandamönstret identifierar problem som orsakas av en ökning av arbetsbelastningen eller, i dess allvarligare form, en arbetsbelastningspåsning.
Den här identifieringen görs genom en kombination av flera mått. Det mätbara basmåttet identifierar en ökning av arbetsbelastningen jämfört med den tidigare arbetsbelastningsbaslinjen. Den andra identifieringsformen baseras på mätning av en stor ökning av aktiva arbetstrådar som är tillräckligt stora för att påverka frågeprestandan.
I sin allvarligare form kan arbetsbelastningen kontinuerligt staplas på grund av att en databas inte kan hantera arbetsbelastningen. Resultatet är en ständigt växande arbetsbelastningsstorlek, vilket är arbetsbelastningens pålningsvillkor. På grund av det här villkoret växer den tid som arbetsbelastningen väntar på körning. Det här villkoret representerar ett av de allvarligaste databasprestandaproblemen. Det här problemet identifieras genom övervakning av ökningen av antalet avbrutna arbetstrådar.
Felsökning
Diagnostikloggen matar ut antalet frågor vars körning har ökat och frågans hash för frågan med det största bidraget till arbetsbelastningen ökar. Du kan använda den här informationen som utgångspunkt för att optimera arbetsbelastningen. Frågan som identifieras som den största deltagaren i arbetsbelastningsökningen är särskilt användbar som startpunkt.
Du kan överväga att distribuera arbetsbelastningarna jämnare till databasen. Överväg att optimera frågan som påverkar prestanda genom att lägga till index. Du kan också distribuera din arbetsbelastning mellan flera databaser. Om dessa lösningar inte är möjliga kan du överväga att öka prisnivån för din databasprenumeration för att öka mängden tillgängliga resurser.
Minnesbelastning
Vad händer
Det här prestandamönstret indikerar försämring av den aktuella databasprestandan som orsakas av minnestryck, eller i dess allvarligare form ett minneshögtillstånd, jämfört med den senaste sjudagars prestandabaslinjen.
Minnestryck anger ett prestandatillstånd där det finns ett stort antal arbetstrådar som begär minnesbidrag. Den höga volymen orsakar ett villkor för hög minnesanvändning där databasen inte effektivt kan allokera minne till alla arbetare som begär det. En av de vanligaste orsakerna till det här problemet är relaterad till mängden minne som är tillgängligt för databasen å ena sidan. Å andra sidan leder en ökning av arbetsbelastningen till att arbetstrådarna och minnesbelastningen ökar.
Den allvarligare formen av minnestryck är minneshögen. Det här villkoret anger att ett högre antal arbetstrådar begär minnesbidrag än det finns frågor som frigör minnet. Det här antalet arbetstrådar som begär minnesbidrag kan också öka kontinuerligt (hopa sig) eftersom databasmotorn inte kan allokera minne tillräckligt effektivt för att möta efterfrågan. Minneshögen representerar ett av de allvarligaste databasprestandaproblemen.
Felsökning
Diagnostikloggen matar ut information om minnesobjektarkivet med kontoristen (det vill säga arbetstråden) markerad som den högsta orsaken till hög minnesanvändning och relevanta tidsstämplar. Du kan använda den här informationen som grund för felsökning.
Du kan optimera eller ta bort frågor som rör kontoristerna med den högsta minnesanvändningen. Du kan också se till att du inte kör frågor mot data som du inte planerar att använda. Bra praxis är att alltid använda en WHERE-sats i dina frågor. Dessutom rekommenderar vi att du skapar icke-illustrerade index för att söka efter data i stället för att genomsöka dem.
Du kan också minska arbetsbelastningen genom att optimera eller distribuera den över flera databaser. Eller så kan du distribuera din arbetsbelastning mellan flera databaser. Om dessa lösningar inte är möjliga kan du överväga att öka prisnivån för databasen för att öka mängden minnesresurser som är tillgängliga för databasen.
Ytterligare felsökningsförslag finns i Minnesbiståndsmeditation: Den mystiska SQL Server-minneskonsumenten med många namn. Mer information om minnesfel i Azure SQL Database finns i Felsöka minnesfel med Azure SQL Database.
Låsning
Vad händer
Det här prestandamönstret indikerar försämring av den aktuella databasprestandan där överdriven databaslåsning identifieras jämfört med den senaste sjudagars prestandabaslinjen.
I moderna RDBMS är låsning viktigt för att implementera flertrådade system där prestanda maximeras genom att köra flera samtidiga arbetare och parallella databastransaktioner där det är möjligt. Låsning i den här kontexten refererar till den inbyggda åtkomstmekanismen där endast en enda transaktion exklusivt kan komma åt de rader, sidor, tabeller och filer som krävs och inte konkurrerar med en annan transaktion för resurser. När transaktionen som låste resurserna för användning görs med dem frigörs låset på dessa resurser, vilket gör att andra transaktioner kan komma åt nödvändiga resurser. Mer information om låsning finns i Lås i databasmotorn.
Om transaktioner som körs av SQL-motorn väntar under längre tidsperioder för att få åtkomst till resurser som är låsta för användning, orsakar den här väntetiden en långsammare prestanda för arbetsbelastningskörningen.
Felsökning
Diagnostikloggen matar ut låsinformation som du kan använda som grund för felsökning. Du kan analysera de rapporterade blockeringsfrågorna, d.v.s. de frågor som introducerar försämrad låsningsprestanda och ta bort dem. I vissa fall kan du lyckas optimera blockeringsfrågorna.
Det enklaste och säkraste sättet att åtgärda problemet är att hålla transaktionerna korta och minska låsfotavtrycket för de dyraste frågorna. Du kan dela upp en stor mängd åtgärder i mindre åtgärder. Det är bra att minska fotavtrycket för frågelåset genom att göra frågan så effektiv som möjligt. Minska stora genomsökningar eftersom de ökar risken för dödlägen och påverkar databasens övergripande prestanda negativt. För identifierade frågor som orsakar låsning kan du skapa nya index eller lägga till kolumner i det befintliga indexet för att undvika tabellgenomsökningarna.
Fler förslag finns i:
- Förstå och lösa problem med Azure SQL-blockering
- Så här löser du blockeringsproblem som orsakas av låseskalering i SQL Server
Ökad MAXDOP
Vad händer
Det här detekterbara prestandamönstret anger ett villkor där en vald frågekörningsplan parallelliserades mer än den borde ha varit. Frågeoptimeraren kan förbättra arbetsbelastningens prestanda genom att köra frågor parallellt för att påskynda saker där det är möjligt. I vissa fall lägger parallella arbetare som bearbetar en fråga mer tid på att synkronisera och sammanfoga resultat jämfört med att köra samma fråga med färre parallella arbetare, eller till och med i vissa fall jämfört med en enda arbetstråd.
Expertsystemet analyserar den aktuella databasprestandan jämfört med baslinjeperioden. Den avgör om en fråga som körs tidigare körs långsammare än tidigare eftersom frågekörningsplanen är mer parallelliserad än den borde vara.
Konfigurationsalternativet FÖR MAXDOP-servern används för att styra hur många CPU-kärnor som kan användas för att köra samma fråga parallellt.
Felsökning
Diagnostikloggen matar ut fråge-hashvärden relaterade till frågor för vilka körningstiden ökade eftersom de parallelliserades mer än de borde ha varit. Loggen matar också ut CXP-väntetider. Den här gången representerar den tid då en enskild organisatörs-/koordinatortråd (tråd 0) väntar på att alla andra trådar ska slutföras innan resultatet slås samman och går vidare. Dessutom matar diagnostikloggen ut de väntetider som de dåliga frågorna väntade i körningen totalt sett. Du kan använda den här informationen som grund för felsökning.
Börja med att optimera eller förenkla komplexa frågor. Bra praxis är att dela upp långa batchjobb i mindre. Se dessutom till att du har skapat index för att stödja dina frågor. Du kan också manuellt framtvinga maximal grad av parallellitet (MAXDOP) för en fråga som har flaggats som dålig. Information om hur du konfigurerar den här åtgärden med hjälp av T-SQL finns i Konfigurera konfigurationsalternativet MAXDOP-server.
Om du anger konfigurationsalternativet för MAXDOP-servern till noll (0) som standardvärde anges att databasen kan använda alla tillgängliga CPU-kärnor för att parallellisera trådar för att köra en enda fråga. Om du anger MAXDOP till en (1) anges att endast en kärna kan användas för en enda frågekörning. I praktiken innebär detta att parallelliteten är avstängd. Beroende på fall-per-fall-basis, tillgängliga kärnor till databasen och diagnostiklogginformation kan du justera MAXDOP-alternativet till antalet kärnor som används för parallell frågekörning som kan lösa problemet i ditt fall.
Pagelatch-konkurrens
Vad händer
Det här prestandamönstret anger den aktuella prestandaförsämringen för databasarbetsbelastningen på grund av pagelatch-konkurrens jämfört med den senaste sjudagars arbetsbelastningsbaslinjen.
Svarstider är enkla synkroniseringsmekanismer som används för att aktivera multitrådning. De garanterar konsekvens av minnesinterna strukturer som innehåller index, datasidor och andra interna strukturer.
Det finns många typer av lås tillgängliga. För enkelhetens skull används buffertlås för att skydda minnesinterna sidor i buffertpoolen. I/O-svarstider används för att skydda sidor som ännu inte har lästs in i buffertpoolen. När data skrivs till eller läss från en sida i buffertpoolen måste en arbetstråd hämta en buffertspärr för sidan först. När en arbetstråd försöker komma åt en sida som inte redan är tillgänglig i minnesintern buffertpool görs en I/O-begäran för att läsa in nödvändig information från lagringen. Den här händelsesekvensen indikerar en allvarligare form av prestandaförsämring.
Konkurrens på sidlåsen uppstår när flera trådar samtidigt försöker hämta lås på samma minnesintern struktur, vilket ger en ökad väntetid för frågekörning. När det gäller pagelatch-I/O-konkurrens är väntetiden ännu större när data behöver nås från lagringen. Det kan påverka arbetsbelastningens prestanda avsevärt. Pagelatch-konkurrens är det vanligaste scenariot med trådar som väntar på varandra och konkurrerar om resurser på flera CPU-system.
Felsökning
Diagnostikloggen matar ut information om pagelatch-konkurrens. Du kan använda den här informationen som grund för felsökning.
Eftersom en pagelatch är en intern kontrollmekanism avgör den automatiskt när de ska användas. Programbeslut, inklusive schemadesign, kan påverka pagelatch-beteendet på grund av det deterministiska beteendet för lås.
En metod för att hantera spärrkonkurration är att ersätta en sekventiell indexnyckel med en icke-sekventiell nyckel för att fördela infogningar jämnt över ett indexintervall. Vanligtvis distribuerar en inledande kolumn i indexet arbetsbelastningen proportionellt. En annan metod att överväga är tabellpartitionering. Att skapa ett hashpartitioneringsschema med en beräknad kolumn i en partitionerad tabell är en vanlig metod för att minimera överdriven spärrkonkurring. När det gäller pagelatch-I/O-konkurrens hjälper införandet av index till att minska det här prestandaproblemet.
Mer information finns i Diagnostisera och lösa spärrkonkurration på SQL Server (PDF-nedladdning).
Index saknas
Vad händer
Det här prestandamönstret anger den aktuella prestandaförsämringen för databasarbetsbelastningen jämfört med den senaste sjudagarsbaslinjen på grund av ett index som saknas.
Ett index används för att påskynda prestanda för frågor. Den ger snabb åtkomst till tabelldata genom att minska antalet datamängdssidor som behöver besökas eller genomsökas.
Specifika frågor som orsakade prestandaförsämring identifieras genom den här identifieringen för vilka det skulle vara fördelaktigt för prestandan att skapa index.
Felsökning
Diagnostikloggen matar ut fråge-hashvärden för de frågor som identifierades för att påverka arbetsbelastningens prestanda. Du kan skapa index för dessa frågor. Du kan också optimera eller ta bort dessa frågor om de inte krävs. En bra prestandametod är att undvika att köra frågor mot data som du inte använder.
Dricks
Visste du att inbyggd intelligens automatiskt kan hantera de bäst presterande indexen för dina databaser?
För kontinuerlig prestandaoptimering rekommenderar vi att du aktiverar automatisk justering. Den här unika inbyggda intelligensfunktionen övervakar kontinuerligt din databas och justerar automatiskt och skapar index för dina databaser.
Ny fråga
Vad händer
Det här prestandamönstret anger att en ny fråga identifieras som presterar dåligt och påverkar arbetsbelastningens prestanda jämfört med den sju dagar långa prestandabaslinjen.
Att skriva en bra fråga kan ibland vara en utmanande uppgift. Mer information om hur du skriver frågor finns i Skriva SQL-frågor. Information om hur du optimerar befintliga frågeprestanda finns i Frågejustering.
Felsökning
Diagnostikloggen matar ut information upp till två nya mest PROCESSORkrävande frågor, inklusive deras fråge-hashvärden. Eftersom den identifierade frågan påverkar arbetsbelastningens prestanda kan du optimera frågan. Bra praxis är att endast hämta data som du behöver använda. Vi rekommenderar också att du använder frågor med en WHERE-sats. Vi rekommenderar också att du förenklar komplexa frågor och delar upp dem i mindre frågor. En annan bra metod är att dela upp stora batchfrågor i mindre batchfrågor. Att introducera index för nya frågor är vanligtvis en bra metod för att undvika det här prestandaproblemet.
Överväg att använda Query Performance Insight i Azure SQL Database.
Ökad väntestatistik
Vad händer
Det här detekterbara prestandamönstret anger en försämrad arbetsbelastningsprestanda där frågor med dåliga prestanda identifieras jämfört med den senaste sjudagars arbetsbelastningsbaslinjen.
I det här fallet kan systemet inte klassificera frågor med dåliga prestanda under andra prestandakategorier som kan identifieras av standard, men det identifierade väntestatistiken som är ansvarig för regressionen. Därför betraktas de som frågor med ökad väntestatistik, där väntestatistiken som ansvarar för regressionen också exponeras.
Felsökning
Diagnostikloggen matar ut information om ökad väntetidsinformation och frågehashvärden för de berörda frågorna.
Eftersom systemet inte kunde identifiera rotorsaken till frågor med dålig prestanda är diagnostikinformationen en bra startpunkt för manuell felsökning. Du kan optimera prestandan för dessa frågor. En bra idé är att endast hämta data som du behöver använda och att förenkla och dela upp komplexa frågor i mindre.
Mer information om hur du optimerar frågeprestanda finns i Frågejustering.
TempDB-konkurrens
Vad händer
Det här detekterbara prestandamönstret anger ett villkor för databasprestanda där det finns en flaskhals med trådar som försöker komma åt tempdb resurser. (Det här villkoret är inte I/O-relaterat.) Det typiska scenariot för det här prestandaproblemet är hundratals samtidiga frågor som alla skapar, använder och sedan släpper små tempdb tabeller. Systemet upptäckte att antalet samtidiga frågor med samma tempdb tabeller ökade med tillräcklig statistisk signifikans för att påverka databasprestanda jämfört med den senaste sjudagars prestandabaslinjen.
Felsökning
Diagnostikloggen matar ut tempdb konkurrensinformation. Du kan använda informationen som startpunkt för felsökning. Det finns två saker du kan göra för att minska den här typen av konkurrens och öka dataflödet för den totala arbetsbelastningen: Du kan sluta använda de tillfälliga tabellerna. Du kan också använda minnesoptimerade tabeller.
Mer information finns i Introduktion till minnesoptimerade tabeller.
DTU-brist för elastisk pool
Vad händer
Det här detekterbara prestandamönstret indikerar en försämring av den aktuella databasens arbetsbelastningsprestanda jämfört med den senaste sjudagarsbaslinjen. Det beror på bristen på tillgängliga DTU:er i den elastiska poolen i din prenumeration.
Azures elastiska poolresurser används som en pool med tillgängliga resurser som delas mellan flera databaser i skalningssyfte. När tillgängliga eDTU-resurser i din elastiska pool inte är tillräckligt stora för att stödja alla databaser i poolen identifieras ett problem med DTU-brist på elastisk pool av systemet.
Felsökning
Diagnostikloggen matar ut information om den elastiska poolen, listar de främsta DTU-förbrukande databaserna och tillhandahåller en procentandel av poolens DTU som används av den mest tidskrävande databasen.
Eftersom det här prestandavillkoret är relaterat till flera databaser med samma pool med eDTU:er i den elastiska poolen fokuserar felsökningsstegen på de främsta DTU-använda databaserna. Du kan minska arbetsbelastningen på de mest tidskrävande databaserna, vilket inkluderar optimering av de mest tidskrävande frågorna i dessa databaser. Du kan också se till att du inte kör frågor mot data som du inte använder. En annan metod är att optimera program med hjälp av de mest DTU-använda databaserna och distribuera om arbetsbelastningen mellan flera databaser.
Om det inte går att minska och optimera den aktuella arbetsbelastningen i de mest DTU-använda databaserna kan du överväga att öka prisnivån för elastiska pooler. En sådan ökning resulterar i en ökning av tillgängliga DTU:er i den elastiska poolen.
Planera regression
Vad händer
Det här detekterbara prestandamönstret anger ett villkor där databasen använder en suboptimal frågekörningsplan. Den suboptimala planen orsakar vanligtvis ökad frågekörning, vilket leder till längre väntetider för aktuella och andra frågor.
Databasmotorn avgör frågekörningsplanen med den lägsta kostnaden för en frågekörning. När typen av frågor och arbetsbelastningar ändras är de befintliga planerna ibland inte längre effektiva, eller så kanske databasmotorn inte gjorde någon bra utvärdering. Som en korrigering kan frågekörningsplaner tvingas manuellt.
Det här detekterbara prestandamönstret kombinerar tre olika fall av planregression: ny planregression, gammal planregression och befintliga planer har ändrat arbetsbelastningen. Den specifika typen av planregression som inträffade finns i informationsegenskapen i diagnostikloggen.
Det nya regressionsvillkoret för planen refererar till ett tillstånd där databasmotorn börjar köra en ny frågekörningsplan som inte är lika effektiv som den gamla planen. Det gamla regressionsvillkoret för planen refererar till tillståndet när databasmotorn växlar från att använda en ny, effektivare plan till den gamla planen, vilket inte är lika effektivt som den nya planen. De befintliga planerna ändrade regressionen för arbetsbelastningen refererar till det tillstånd där de gamla och de nya planerna kontinuerligt växlar, där balansen går mer mot den dåliga planen.
Mer information om planregressioner finns i Vad är planregression i SQL Server?.
Felsökning
Diagnostikloggen matar ut fråge-hashvärden, bra plan-ID, felaktigt plan-ID och fråge-ID. Du kan använda den här informationen som grund för felsökning.
Du kan analysera vilken plan som fungerar bättre för dina specifika frågor som du kan identifiera med de angivna fråge-hashvärdena. När du har fastställt vilken plan som fungerar bättre för dina frågor kan du framtvinga den manuellt.
Mer information finns i Lär dig hur SQL Server förhindrar planregressioner.
Dricks
Visste du att den inbyggda intelligensfunktionen automatiskt kan hantera de bäst presterande frågekörningsplanerna för dina databaser?
För kontinuerlig prestandaoptimering rekommenderar vi att du aktiverar automatisk justering. Den här inbyggda intelligensfunktionen övervakar kontinuerligt din databas och justerar automatiskt och skapar högpresterande frågekörningsplaner för dina databaser.
Ändring av databasomfattningskonfigurationsvärde
Vad händer
Det här detekterbara prestandamönstret anger ett villkor där en ändring i den databasomfattande konfigurationen orsakar prestandaregression som identifieras jämfört med det senaste sju dagar långa arbetsbelastningsbeteendet för databasen. Det här mönstret anger att en nyligen genomförd ändring av den databasomfattande konfigurationen inte verkar vara till nytta för databasens prestanda.
Konfigurationsändringar med databasomfattning kan anges för varje enskild databas. Den här konfigurationen används från fall till fall för att optimera databasens individuella prestanda. Följande alternativ kan konfigureras för varje enskild databas: MAXDOP, LEGACY_CARDINALITY_ESTIMATION, PARAMETER_SNIFFING, QUERY_OPTIMIZER_HOTFIXES och CLEAR PROCEDURE_CACHE.
Felsökning
Diagnostikloggen matar ut databasomfattande konfigurationsändringar som nyligen gjordes som orsakade prestandaförsämring jämfört med det tidigare sjudagars arbetsbelastningsbeteendet. Du kan återställa konfigurationsändringarna till tidigare värden. Du kan också justera värdet efter värde tills den önskade prestandanivån har nåtts. Du kan kopiera konfigurationsvärden för databasomfattning från en liknande databas med tillfredsställande prestanda. Om du inte kan felsöka prestandan återgår du till standardvärdena och försöker finjustera från och med den här baslinjen.
Mer information om hur du optimerar databasomfattande konfiguration och T-SQL-syntax vid ändring av konfigurationen finns i Ändra databasomfattande konfiguration (Transact-SQL).
Långsam klient
Vad händer
Det här detekterbara prestandamönstret anger ett villkor där klienten som använder databasen inte kan använda utdata från databasen lika snabbt som databasen skickar resultatet. Eftersom databasen inte lagrar resultatet av de körda frågorna i en buffert, saktar den ned och väntar på att klienten ska använda de överförda frågeutdata innan den fortsätter. Det här villkoret kan också vara relaterat till ett nätverk som inte är tillräckligt snabbt för att överföra utdata från databasen till den förbrukande klienten.
Det här villkoret genereras endast om en prestandaregression identifieras jämfört med det senaste sju dagar långa arbetsbelastningsbeteendet för databasen. Det här prestandaproblemet identifieras endast om en statistiskt signifikant prestandaförsämring inträffar jämfört med tidigare prestandabeteende.
Felsökning
Det här detekterbara prestandamönstret anger ett villkor på klientsidan. Felsökning krävs i programmet på klientsidan eller i nätverket på klientsidan. Diagnostikloggen matar ut fråge-hashvärden och väntetider som verkar vänta mest på att klienten ska använda dem under de senaste två timmarna. Du kan använda den här informationen som grund för felsökning.
Du kan optimera programmets prestanda för användning av dessa frågor. Du kan också överväga eventuella problem med nätverksfördröjning. Eftersom prestandaförsämringsproblemet baserades på ändringar i den senaste sjudagars prestandabaslinjen kan du undersöka om de senaste ändringarna av program- eller nätverksvillkor orsakade den här prestandaregressionshändelsen.
Nedgradering av prisnivå
Vad händer
Det här detekterbara prestandamönstret anger ett villkor där prisnivån för din databasprenumeration nedgraderades. På grund av minskade resurser (DTU:er) som är tillgängliga för databasen upptäckte systemet en minskning av den aktuella databasprestandan jämfört med den senaste sjudagarsbaslinjen.
Dessutom kan det finnas ett villkor där prisnivån för din databasprenumeration nedgraderades och sedan uppgraderades till en högre nivå inom en kort tidsperiod. Identifiering av den här tillfälliga prestandaförsämringen visas i informationsavsnittet i diagnostikloggen som en nedgradering och uppgradering på prisnivå.
Felsökning
Om du har sänkt prisnivån och därför de DTU:er som är tillgängliga och du är nöjd med prestandan behöver du inte göra något. Om du har sänkt prisnivån och inte är nöjd med databasprestandan kan du minska dina databasarbetsbelastningar eller överväga att öka prisnivån till en högre nivå.
Rekommenderat felsökningsflöde
Följ flödesschemat för en rekommenderad metod för att felsöka prestandaproblem med hjälp av Intelligent Insights.
Få åtkomst till Intelligent Insights via Azure-portalen genom att gå till Azure SQL Analytics. Försök att hitta den inkommande prestandaaviseringen och välj den. Identifiera vad som händer på identifieringssidan. Observera den angivna rotorsaksanalysen av problemet, frågetexten, frågetidstrender och incidentutvecklingen. Försök att lösa problemet med hjälp av rekommendationen Intelligent Insights för att åtgärda prestandaproblemet.
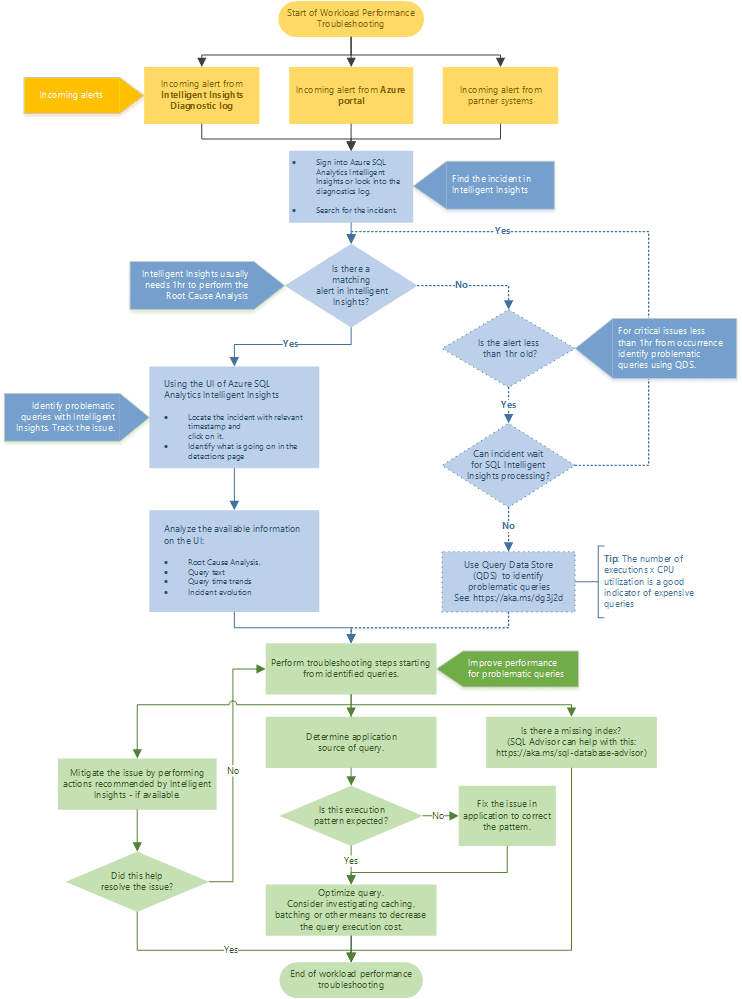
Dricks
Välj flödesschemat för att ladda ned en PDF-version.
Intelligent Insights behöver vanligtvis en timmes tid för att utföra rotorsaksanalysen av prestandaproblemet. Om du inte kan hitta problemet i Intelligent Insights och det är viktigt för dig använder du Query Store för att manuellt identifiera rotorsaken till prestandaproblemet. (Dessa problem är vanligtvis mindre än en timme gamla.) Mer information finns i Övervaka prestanda med hjälp av Query Store.
Nästa steg
- Lär dig begrepp om Intelligent Insights .
- Använd prestandadiagnostikloggen för Intelligent Insights.
- Övervaka med Azure SQL Analytics.
- Lär dig att samla in och använda loggdata från dina Azure-resurser.