Reparera en nod på Azure Local
Gäller för: Azure Local 2311.2 och senare
Den här artikeln beskriver hur du reparerar en nod på din lokala Azure-instans. I den här artikeln kallas varje server för en nod.
Om reparationsnoder
Azure Local är ett hyperkonvergerat system som gör att du kan reparera noder från befintliga system. Du kan behöva reparera en nod i ett system om det uppstår ett maskinvarufel.
Innan du reparerar en nod kontrollerar du med din lösningsleverantör vilka komponenter på noden som är fältersättningsenheter (FRUs) som du kan ersätta själv och vilka komponenter som kräver att en tekniker ersätter.
Delar som stöder hot swap kräver vanligtvis inte att du återskapar noden till skillnad från de icke-hot-swappable komponenterna som moderkortet. Kontakta maskinvarutillverkaren för att avgöra vilka komponentbyten som skulle kräva att du återskapar noden. Mer information finns i Komponentersättning.
Reparera nodarbetsflöde
Följande flödesdiagram visar den övergripande processen för att reparera en nod.

*Noden kanske inte är i ett tillstånd där avstängning är möjlig eller nödvändig*
Följ dessa övergripande steg för att reparera en befintlig nod:
Stäng om möjligt den nod som du vill reparera. Beroende på nodens tillstånd kanske en avstängning inte är möjlig eller nödvändig.
Återskapa den nod som behöver repareras.
Kör reparationsnodåtgärden. Azure Stack HCI-operativsystemet, drivrutinerna och den inbyggda programvaran uppdateras som en del av reparationen.
Lagringen ombalanseras automatiskt på den omkonfigurerade noden. Ombalansering av lagring är en uppgift med låg prioritet som kan köras i flera dagar beroende på antalet noder och den lagring som används.
Stödda scenarier
När du reparerar en nod återskapas en nod och den återgår till systemet med det tidigare namnet och konfigurationen.
Reparation av en enskild nod resulterar i en omdistribution med alternativet att spara datavolymerna. Endast systemvolymen tas bort och konfigureras på nytt under utplaceringen.
Viktigt!
Kontrollera att du alltid har säkerhetskopior för dina arbetsbelastningar och inte bara förlitar dig på systemets återhämtning. Detta är särskilt viktigt i scenarier med en nod.
Återhämtningsinställningar
I den här versionen utförs inga specifika uppgifter vid en reparationsnodoperation på de arbetsbelastningsvolymer som du skapade efter distributionen. För en reparationsnodåtgärd återställs endast de nödvändiga infrastrukturvolymerna och arbetsbelastningsvolymerna och visas som klusterdelade volymer (CSV:er).
De andra arbetsbelastningsvolymerna som du skapade efter distributionen behålls fortfarande och du kan identifiera dessa volymer genom att köra cmdleten Get-VirtualDisk . Du måste låsa upp volymen manuellt (om volymen har BitLocker aktiverat) och skapa en CSV (om det behövs).
Maskinvarukrav
När du reparerar en nod verifierar systemet maskinvaran för den nya inkommande noden och ser till att noden uppfyller maskinvarukraven innan den läggs till i systemet.
| Komponent | Efterlevnadskontroll |
|---|---|
| Processor | Verifiera att den nya noden har samma antal eller fler CPU-kärnor. Om CPU-kärnorna på den inkommande noden inte uppfyller detta krav visas en varning. Åtgärden är dock tillåten. |
| Minne | Kontrollera att den nya noden har samma mängd eller mer minne installerat. Om minnet på den inkommande noden inte uppfyller det här kravet visas en varning. Åtgärden är dock tillåten. |
| Drivrutiner | Kontrollera att den nya noden har samma antal tillgängliga dataenheter för Storage Spaces Direct. Om antalet enheter på den inkommande noden inte uppfyller detta krav rapporteras ett fel och åtgärden blockeras. |
Nodersättning
Du kan ersätta hela noden:
- Med en ny nod som har ett annat serienummer jämfört med den gamla noden.
- Med den aktuella noden när du har återskapat den.
Följande scenarier stöds vid nodbyte:
| Node | Disk | Stöds |
|---|---|---|
| Ny nod | Nya diskar | Ja |
| Ny nod | Aktuella diskar | Ja |
| Aktuell nod (omskapad) | Aktuella diskar omformaterade ** | Nej |
| Aktuell nod (omskapad) | Nya diskar | Ja |
| Aktuell nod (omskapad) | Aktuella diskar | Ja |
**Diskar som har använts av Lagringsutrymmen Direct kräver korrekt rengöring. Omformatering räcker inte. Se hur du rensar enheter.
Viktigt!
Om du ersätter en komponent under nodreparationen behöver du inte ersätta eller återställa dataenheter. Om du ersätter en enhet eller återställer den identifieras inte enheten när noden ansluter till systemet.
Komponentersättning
I din lokala Azure-instans inkluderar komponenter som inte är hot-swappable följande saker:
- Moderkort/baseboard management controller (BMC)/grafikkort
- Diskkontrollant/värdbusskort (HBA)/bakplan
- Nätverkskort
- Grafikbearbetningsenhet
- Dataenheter (enheter som inte stöder hot swap, till exempel PCI-e-tilläggskort)
De faktiska stegen för att ersätta icke-varmbyteskompatibla komponenter varierar beroende på OEM-maskinvaruleverantören (ursprungsutrustningstillverkaren). Se din OEM-leverantörs dokumentation om en nodreparation krävs för komponenter som inte kan bytas ut utan att stänga av systemet.
Förutsättningar
Innan du reparerar en nod måste du se till att:
-
AzureStackLCMUserär aktiv i Active Directory. Mer information finns i Förbereda Active Directory. - Inloggad som
AzureStackLCMUsereller en annan användare med motsvarande behörigheter. - Autentiseringsuppgifterna
AzureStackLCMUserför har inte ändrats.
Om det behövs, ta den nod som du har identifierat för reparation offline. Följ stegen här:
Reparera en nod
I det här avsnittet beskrivs hur du reparerar en nod med PowerShell, övervakar åtgärdens Repair-Server status och felsöker om det finns några problem.
Kontrollera att du har granskat förutsättningarna.
Följ de här stegen på den nod som du försöker reparera.
Logga in på Azure-portalen med behörigheter för Azure Stack HCI-administratörsrollen.
Gå till den resursgrupp som används för att distribuera din lokala Azure-instans. I resursgruppen identifierar du Azure Arc-datorresursen för den felaktiga nod som du vill reparera.
I Azure Arc-datorresursen går du till Inställningar > Lås. I den högra rutan visas ett resurslås.
Välj låset och välj sedan papperskorgsikonen för att ta bort låset.
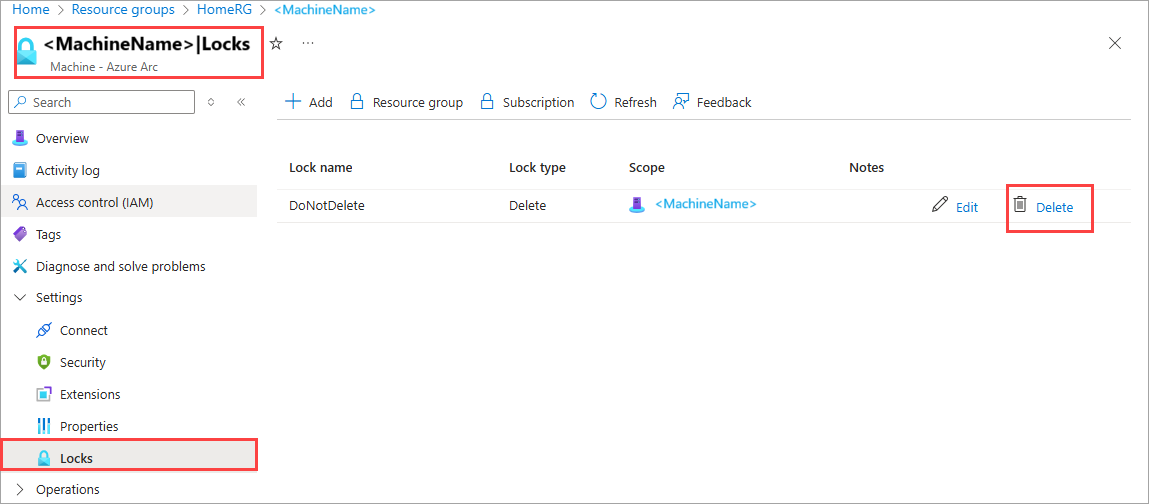
På sidan Översikt i Azure Arc-datorresursen, i det högra fönstret, väljer du Ta bort. Den här åtgärden bör ta bort den felaktiga datornoden.

Installera operativsystemet och nödvändiga drivrutiner på den nod som du vill reparera. Följ stegen i Installera Azure Stack HCI-operativsystemet version 23H2.
Anteckning
Om du har distribuerat din lokala Azure-instans med anpassade lagrings-IP-adresser måste du manuellt tilldela IP-adresser till lagringsnätverkskorten när noden har reparerats.
Registrera noden med Arc. Följ stegen i Registrera med Arc och konfigurera behörigheter.
Anteckning
Du måste använda samma parametrar som de befintliga noderna för att registrera dig med Arc. Till exempel: Resursgruppsnamn, Region, Prenumeration och Klientorganisation.
Tilldela följande behörigheter till den reparerade noden:
- Azure Local Enhetshanteringsroll
- Key Vault Secrets User Mer information finns i Tilldela behörigheter till noden.


Följ dessa steg på en annan nod som är medlem i samma lokala Azure-instans.
Om du kör en version före 2405.3 måste du köra följande kommando för att rensa filer som är i konflikt:
Get-ChildItem -Path "$env:SystemDrive\NugetStore" -Exclude Microsoft.AzureStack.Solution.LCMControllerWinService*,Microsoft.AzureStack.Role.Deployment.Service* | Remove-Item -Recurse -ForceLogga in på noden som redan är medlem i systemet med de autentiseringsuppgifter för domänanvändare som du angav under distributionen av systemet. Kör följande kommando för att reparera den inkommande noden:
$Cred = Get-Credential Repair-Server -Name "<Name of the new node>" -LocalAdminCredential $CredKommentar
Nodnamnet måste vara NetBIOS-namnet. Parametern
LocalAdminCredentialsom standard är det inbyggda administratörskontot som skapats av Windows OS-installationen.Anteckna operations-ID:t som utdata från
Repair-Serverkommandot. Du använder detta senare för att övervaka förloppet för åtgärdenRepair-Server.
Övervaka åtgärdens förlopp
Följ dessa steg för att övervaka förloppet av åtgärden att lägga till en nod:
Kör följande cmdlet och ange åtgärds-ID från föregående steg.
$ID = "<Operation ID>" Start-MonitoringActionplanInstanceToComplete -actionPlanInstanceID $IDNär åtgärden är klar fortsätter ombalanseringsjobbet för bakgrundslagring att köras. Vänta tills lagringsombalanseringsjobbet har slutförts. Använd följande cmdlet för att verifiera förloppet för det här lagringsombalanseringsjobbet:
Get-VirtualDisk|Get-StorageJobOm lagringsombalanseringsjobbet är klart returnerar cmdleten inte några utdata.
Återställningsscenarier
Följande återställningsscenarier och de rekommenderade åtgärdsstegen är tabulerade för att reparera en nod:
| Beskrivning av scenario | Mildering | Stöds? |
|---|---|---|
| Åtgärden för att reparera noden misslyckades. | För att slutföra åtgärden, undersök felet. Kör den misslyckade åtgärden igen med . Repair-Server -Rerun |
Ja |
| Reparationsåtgärden för noden lyckades delvis men måste påbörjas med en ny installation av operativsystemet. | I det här scenariot har orkestratorn (även kallat Livscykelhanteraren) redan uppdaterat sitt kunskapslager med den nya noden. Använd scenariot för reparationsnoden. | Ja |
Felsökning
Om det uppstår fel eller fel när du reparerar en nod kan du samla in utdata från felen i en loggfil.
Logga in med de autentiseringsuppgifter för domänanvändare som du angav under distributionen av systemet. Samla in problemet i loggfilerna.
Get-ActionPlanInstance -ActionPlanInstanceID $ID |out-file log.txtOm du vill köra den misslyckade åtgärden igen använder du följande cmdlet:
Repair-Server -Rerun
Nästa steg
Läs mer om hur du lägger till en nod.