Bearbetning av naturligt språk (NLP) har många program, till exempel attitydanalys, ämnesidentifiering, språkidentifiering, extrahering av nyckelfraser och kategorisering av dokument.
Mer specifikt kan du använda NLP för att:
- Klassificera dokument, till exempel genom att märka dem som känsliga eller skräppost.
- Utför efterföljande bearbetning eller sökningar med NLP-utdata.
- Sammanfatta text genom att identifiera entiteter i dokumentet.
- Tagga dokument med nyckelord och använd identifierade entiteter.
- Utföra innehållsbaserad sökning och hämtning via taggning.
- Sammanfatta ett dokuments viktigaste ämnen med hjälp av identifierade entiteter.
- Kategorisera dokument för navigering med hjälp av identifierade ämnen.
- Räkna upp relaterade dokument baserat på ett valt ämne.
- Utvärdera textsentiment för att förstå dess positiva eller negativa ton.
Med tekniska framsteg kan NLP inte bara användas för att kategorisera och analysera textdata, utan även för att förbättra tolkningsbara AI-funktioner i olika domäner. Integreringen av stora språkmodeller (LLM) förbättrar NLP:s funktioner avsevärt. LLM:er som GPT och BERT kan generera mänsklig, kontextmedveten text, vilket gör dem mycket effektiva för komplexa språkbearbetningsuppgifter. De kompletterar befintliga NLP-tekniker genom att hantera bredare kognitiva uppgifter, vilket förbättrar konversationssystem och kundengagemang, särskilt med modeller som Databricks Dolly 2.0.
Relation och skillnader mellan språkmodeller och NLP
NLP är ett omfattande område som omfattar olika tekniker för bearbetning av mänskligt språk. Språkmodeller är däremot en specifik delmängd inom NLP, med fokus på djupinlärning för att utföra språkuppgifter på hög nivå. Språkmodeller förbättrar NLP genom att tillhandahålla avancerade funktioner för textgenerering och förståelse, men de är inte synonyma med NLP. I stället fungerar de som kraftfulla verktyg inom den bredare NLP-domänen, vilket möjliggör mer avancerad språkbearbetning.
Not
Den här artikeln fokuserar på NLP. Relationen mellan NLP och språkmodeller visar att språkmodeller förbättrar NLP-processer genom överlägsen språktolkning och genereringsfunktioner.
Apache®, Apache Spark och flamlogotypen är antingen registrerade varumärken eller varumärken som tillhör Apache Software Foundation i USA och/eller andra länder. Inget godkännande från Apache Software Foundation underförstås av användningen av dessa märken.
Potentiella användningsfall
Affärsscenarier som kan dra nytta av anpassad NLP är:
- Dokumentinformation för handskrivna eller maskinskapade dokument inom ekonomi, sjukvård, detaljhandel, myndigheter och andra sektorer.
- Branschoberoende NLP-uppgifter för textbearbetning, till exempel namnentitetsigenkänning (NER), klassificering, sammanfattning och relationsextrahering. Dessa uppgifter automatiserar processen för att hämta, identifiera och analysera dokumentinformation som text och ostrukturerade data. Exempel på dessa uppgifter är riskstratifieringsmodeller, ontologiklassificering och detaljhandelssammanfattningar.
- Informationshämtning och skapande av kunskapsdiagram för semantisk sökning. Den här funktionen gör det möjligt att skapa medicinska kunskapsdiagram som stöder läkemedelsidentifiering och kliniska prövningar.
- Textöversättning för konversations-AI-system i kundinriktade program inom detaljhandel, ekonomi, resor och andra branscher.
- Sentiment och förbättrad känslomässig intelligens i analys, särskilt för övervakning av varumärkesuppfattning och kundfeedbackanalys.
- Automatiserad rapportgenerering. Syntetisera och generera omfattande textrapporter från strukturerade dataindata, med hjälp av sektorer som ekonomi och efterlevnad där noggrann dokumentation krävs.
- Röstaktiverade gränssnitt för att förbättra användarinteraktioner i IoT- och smarta enhetsprogram genom att integrera NLP för röstigenkänning och naturliga konversationsfunktioner.
- Anpassningsbara språkmodeller för att dynamiskt justera språkutdata så att de passar olika målgruppsförståelsenivåer, vilket är avgörande för utbildningsinnehåll och tillgänglighetsförbättringar.
- Textanalys för cybersäkerhet för att analysera kommunikationsmönster och språkanvändning i realtid för att identifiera potentiella säkerhetshot i digital kommunikation, förbättra identifieringen av nätfiskeförsök eller felaktig information.
Apache Spark som ett anpassat NLP-ramverk
Apache Spark är ett kraftfullt ramverk för parallell bearbetning som förbättrar prestandan för analysprogram med stordata via minnesintern bearbetning. Azure Synapse Analytics, Azure HDInsightoch Azure Databricks fortsätta att ge robust åtkomst till Sparks bearbetningsfunktioner, vilket säkerställer sömlös körning av storskaliga dataåtgärder.
För anpassade NLP-arbetsbelastningar är Spark NLP fortfarande ett effektivt ramverk som kan bearbeta stora mängder text. Det här biblioteket med öppen källkod innehåller omfattande funktioner via Python-, Java- och Scala-bibliotek, som levererar den sofistikering som finns i framstående NLP-bibliotek som spaCy och NLTK. Spark NLP innehåller avancerade funktioner som stavningskontroll, attitydanalys och dokumentklassificering, vilket konsekvent säkerställer den senaste precisionen och skalbarheten.
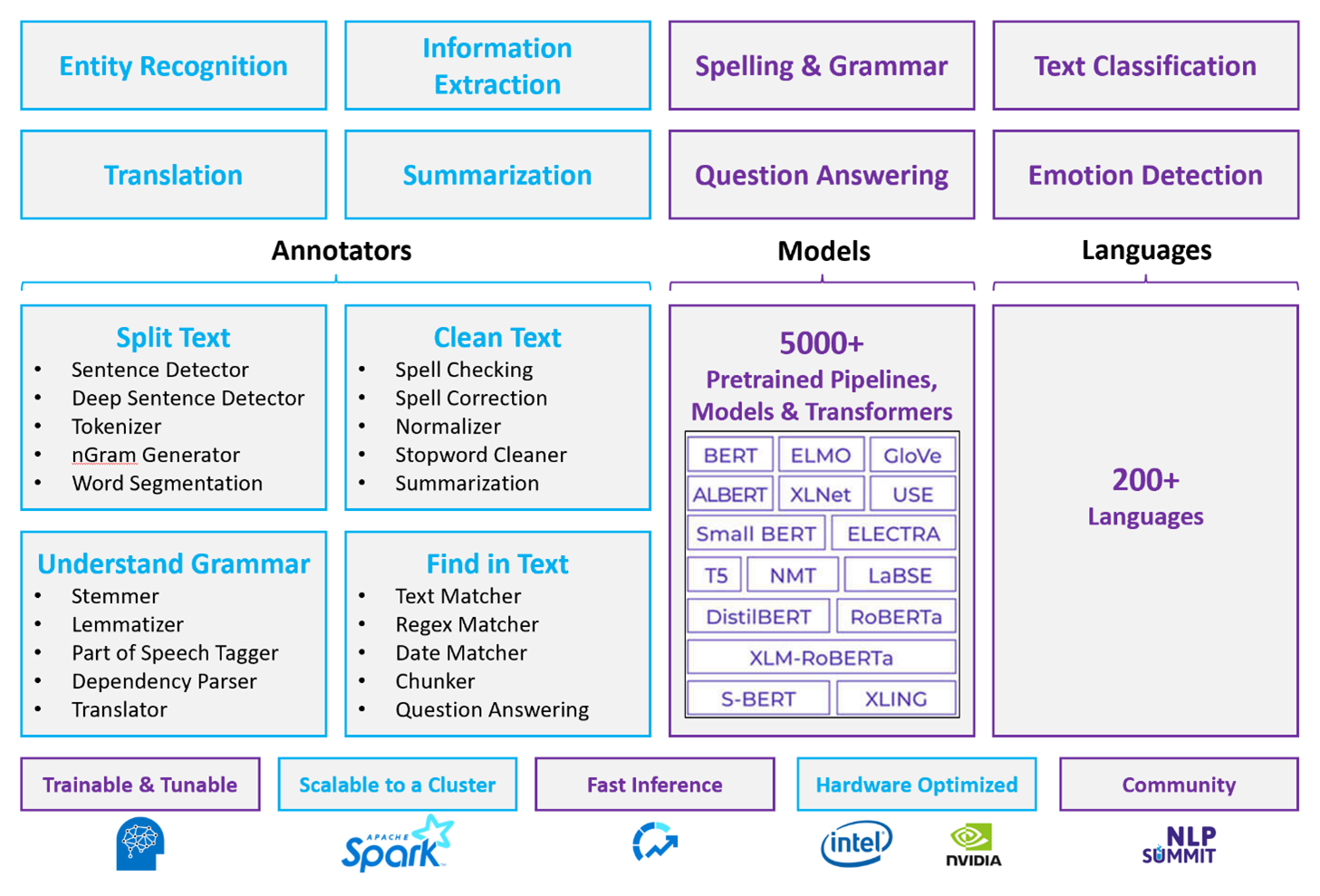
De senaste offentliga riktmärkena belyser Spark NLP:s prestanda och visar betydande hastighetsförbättringar jämfört med andra bibliotek samtidigt som jämförbar noggrannhet bibehålls för att träna anpassade modeller. I synnerhet förbättrar integreringen av Llama-2-modellerna och OpenAI Whisper konversationsgränssnitt och flerspråkig taligenkänning, vilket markerar betydande framsteg i optimerade bearbetningsfunktioner.
Unikt använder Spark NLP effektivt ett distribuerat Spark-kluster som fungerar som ett inbyggt tillägg för Spark ML som fungerar direkt på dataramar. Den här integreringen stöder förbättrade prestandavinster för kluster, vilket underlättar skapandet av enhetliga NLP- och maskininlärningspipelines för uppgifter som dokumentklassificering och riskförutsägelse. Introduktionen av MPNet-inbäddningar och omfattande ONNX-stöd utökar ytterligare dessa funktioner, vilket möjliggör exakt och kontextmedveten bearbetning.
Utöver prestandafördelar ger Spark NLP den senaste precisionen i en expanderande matris med NLP-uppgifter. Biblioteket levereras med fördefinierade djupinlärningsmodeller för namngiven entitetsigenkänning, dokumentklassificering, attitydidentifiering med mera. Dess funktionsrika design innehåller förtränade språkmodeller som stöder inbäddningar av ord, segment, mening och dokument.
Med optimerade versioner för processorer, GPU:er och de senaste Intel Xeon-chipsen är Spark NLP:s infrastruktur utformad för skalbarhet, vilket gör det möjligt för träning och slutsatsdragningsprocesser att fullt ut använda Spark-kluster. Detta säkerställer effektiv hantering av NLP-uppgifter i olika miljöer och program, och behåller sin position i spetsen för NLP-innovation.
Utmaningar
Bearbetningsresurser: Bearbetning av en samling textdokument i fritt format kräver en betydande mängd beräkningsresurser, och bearbetningen är också tidsintensiv. Den här typen av bearbetning omfattar ofta GPU-beräkningsdistribution. De senaste framstegen, till exempel optimeringar i Spark NLP-arkitekturer som Llama-2 som stöder kvantisering, hjälper till att effektivisera dessa intensiva uppgifter, vilket gör resursallokeringen mer effektiv.
Standardiseringsproblem: Utan ett standardiserat dokumentformat kan det vara svårt att uppnå konsekvent korrekta resultat när du använder textbearbetning i fritt format för att extrahera specifika fakta från ett dokument. Att till exempel extrahera fakturanumret och datumet från olika fakturor innebär utmaningar. Integreringen av anpassningsbara NLP-modeller som M2M100 förbättrade bearbetningsnoggrannheten mellan flera språk och format, vilket underlättar bättre konsekvens i resultaten.
Datavarialitet och komplexitet: Att hantera olika dokumentstrukturer och språkliga nyanser är fortfarande komplext. Innovationer som MPNet-inbäddningar ger bättre sammanhangsberoende förståelse, ger mer intuitiv hantering av olika textformat och förbättrar den övergripande databehandlingens tillförlitlighet.
Kriterier för nyckelval
I Azure tillhandahåller Spark-tjänster som Azure Databricks, Microsoft Fabric och Azure HDInsight NLP-funktioner när de används med Spark NLP. Azure AI-tjänster är ett annat alternativ för NLP-funktioner. Tänk på följande frågor för att avgöra vilken tjänst som ska användas:
Vill du använda fördefinierade eller förträade modeller? Om ja kan du överväga att använda de API:er som Azure AI-tjänster erbjuder, eller ladda ned valfri modell via Spark NLP, som nu innehåller avancerade modeller som Llama-2 och MPNet för förbättrade funktioner.
Behöver du träna anpassade modeller mot en stor mängd textdata? Om ja kan du överväga att använda Azure Databricks, Microsoft Fabric eller Azure HDInsight med Spark NLP. Dessa plattformar ger den beräkningskraft och flexibilitet som krävs för omfattande modellträning.
Behöver du NLP-funktioner på låg nivå som tokenisering, härstamning, lemmatisering och termfrekvens/inverterad dokumentfrekvens (TF/IDF)? Om ja kan du överväga att använda Azure Databricks, Microsoft Fabric eller Azure HDInsight med Spark NLP. Du kan också använda ett programbibliotek med öppen källkod i ditt bearbetningsverktyg.
Behöver du enkla NLP-funktioner på hög nivå som entitets- och avsiktsidentifiering, ämnesidentifiering, stavningskontroll eller attitydanalys? Om ja kan du överväga att använda de API:er som Azure AI-tjänster erbjuder. Eller ladda ned valfri modell via Spark NLP för att utnyttja fördefinierade funktioner för dessa uppgifter.
Kapacitetsmatris
I följande tabeller sammanfattas de viktigaste skillnaderna i funktionerna i NLP-tjänster.
Allmänna funktioner
| Kapacitet | Spark-tjänsten (Azure Databricks, Microsoft Fabric, Azure HDInsight) med Spark NLP | Azure AI-tjänster |
|---|---|---|
| Tillhandahåller förtränad modeller som en tjänst | Ja | Ja |
| REST-API | Ja | Ja |
| Programmerbarhet | Python, Scala | Mer information om språk som stöds finns i Ytterligare resurser |
| Stöder bearbetning av stordatamängder och stora dokument | Ja | Nej |
NLP-funktioner på låg nivå
Funktion för anteckningar
| Kapacitet | Spark-tjänsten (Azure Databricks, Microsoft Fabric, Azure HDInsight) med Spark NLP | Azure AI-tjänster |
|---|---|---|
| Meningsdetektor | Ja | Nej |
| Djup meningsdetektor | Ja | Ja |
| Tokenizer | Ja | Ja |
| N-gramgenerator | Ja | Nej |
| Word-segmentering | Ja | Ja |
| Stemmer | Ja | Nej |
| Lemmatizer | Ja | Nej |
| Del av tal-märkning | Ja | Nej |
| Beroendeparser | Ja | Nej |
| Översättning | Ja | Nej |
| Stoppordsrengöringsmedel | Ja | Nej |
| Stavningskorrigering | Ja | Nej |
| Normalizer | Ja | Ja |
| Textmatchning | Ja | Nej |
| TF/IDF | Ja | Nej |
| Matchning av reguljära uttryck | Ja | Inbäddad i Conversational Language Understanding (CLU) |
| Datummatchning | Ja | Möjligt i CLU via DateTime-identifierare |
| Segment | Ja | Nej |
Not
Microsoft Language Understanding (LUIS) dras tillbaka den 1 oktober 2025. Befintliga LUIS-program uppmuntras att migrera till Conversational Language Understanding (CLU), en funktion i Azure AI Services for Language, som förbättrar funktionerna för språkförståelse och erbjuder nya funktioner.
NLP-funktioner på hög nivå
| Kapacitet | Spark-tjänsten (Azure Databricks, Microsoft Fabric, Azure HDInsight) med Spark NLP | Azure AI-tjänster |
|---|---|---|
| Stavningskontroll | Ja | Nej |
| Summering | Ja | Ja |
| Frågor och svar | Ja | Ja |
| Identifiering av attityder | Ja | Ja |
| Känsloidentifiering | Ja | Stöder åsiktsutvinning |
| Tokenklassificering | Ja | Ja, via anpassade modeller |
| Textklassificering | Ja | Ja, via anpassade modeller |
| Textrepresentation | Ja | Nej |
| NER | Ja | Ja – textanalys ger en uppsättning NER och anpassade modeller är i entitetsigenkänning |
| Igenkänning av enhet | Ja | Ja, via anpassade modeller |
| Språkidentifiering | Ja | Ja |
| Stöder språk förutom engelska | Ja, stöder över 200 språk | Ja, stöder över 97 språk |
Konfigurera Spark NLP i Azure
Om du vill installera Spark NLP använder du följande kod, men ersätter <version> med det senaste versionsnumret. Mer information finns i Spark NLP-dokumentationen.
# Install Spark NLP from PyPI.
pip install spark-nlp==<version>
# Install Spark NLP from Anacodna or Conda.
conda install -c johnsnowlabs spark-nlp
# Load Spark NLP with Spark Shell.
spark-shell --packages com.johnsnowlabs.nlp:spark-nlp_<version>
# Load Spark NLP with PySpark.
pyspark --packages com.johnsnowlabs.nlp:spark-nlp_<version>
# Load Spark NLP with Spark Submit.
spark-submit --packages com.johnsnowlabs.nlp:spark-nlp_<version>
# Load Spark NLP as an external JAR after compiling and building Spark NLP by using sbt assembly.
spark-shell --jars spark-nlp-assembly-3 <version>.jar
Utveckla NLP-pipelines
För körningsordningen för en NLP-pipeline följer Spark NLP samma utvecklingskoncept som traditionella Spark ML-maskininlärningsmodeller och tillämpar specialiserade NLP-tekniker.
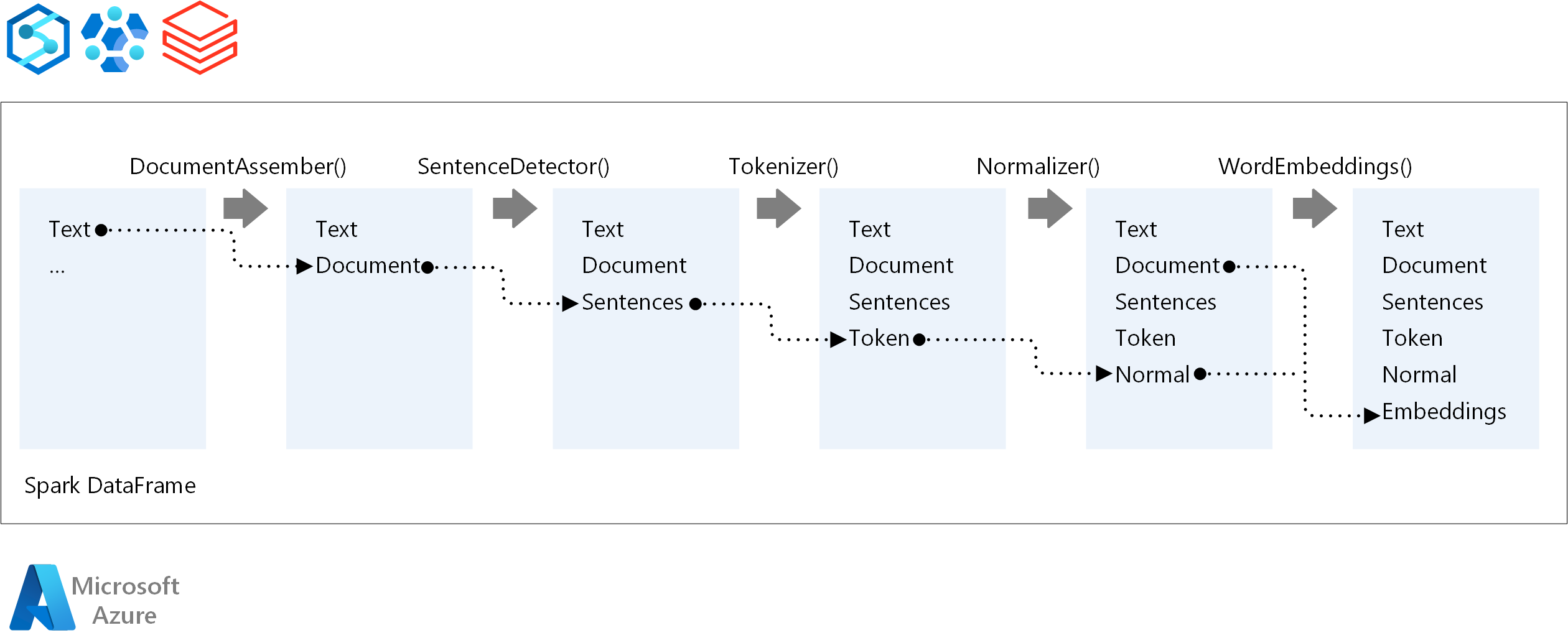
Huvudkomponenterna i en Spark NLP-pipeline är:
DocumentAssembler: En transformerare som förbereder data genom att konvertera dem till ett format som Spark NLP kan bearbeta. Det här steget är startpunkten för varje Spark NLP-pipeline. DocumentAssembler läser antingen en
Stringkolumn eller enArray[String], med alternativ för att förbearbeta texten med hjälp avsetCleanupMode, som är inaktiverad som standard.SentenceDetector: En anteckning som identifierar meningsgränser med hjälp av fördefinierade metoder. Den kan returnera varje identifierad mening i en
Array, eller i separata rader närexplodeSentenceshar angetts till true.Tokenizer: En kommenterare som delar upp råtext i diskreta token – ord, siffror och symboler – som matar ut dessa som en
TokenizedSentence. Tokenizern är inte anpassad och använder indatakonfiguration iRuleFactoryför att skapa tokeniseringsregler. Anpassade regler kan läggas till när standardvärdena är otillräckliga.Normalizer: En anteckning som har till uppgift att förfina token. Normalizer använder reguljära uttryck och ordlistetransformeringar för att rensa text och ta bort överflödiga tecken.
WordEmbeddings: Uppslagsanteckningar som mappar token till vektorer, vilket underlättar semantisk bearbetning. Du kan ange en anpassad inbäddningsordlista med hjälp av
setStoragePath, där varje rad innehåller en token och dess vektor, avgränsade med blanksteg. Olösta token är som standard nollvektorer.
Spark NLP utnyttjar Spark MLlib-pipelines med inbyggt stöd från MLflow, en plattform med öppen källkod som hanterar livscykeln för maskininlärning. MLflows nyckelkomponenter är:
MLflow Tracking: Registrerar experimentella körningar och ger robusta frågefunktioner för analys av resultat.
MLflow Projects: Möjliggör körning av datavetenskapskod på olika plattformar, vilket förbättrar portabiliteten och reproducerbarheten.
MLflow-modeller: Stöder mångsidig modelldistribution i olika miljöer via ett konsekvent ramverk.
Model Registry: Tillhandahåller omfattande modellhantering, lagring av versioner centralt för effektiv åtkomst och distribution, vilket underlättar produktionsberedskap.
MLflow är integrerat med plattformar som Azure Databricks men kan även installeras i andra Spark-baserade miljöer för att hantera och spåra dina experiment. Med den här integreringen kan du använda MLflow Model Registry för att göra modeller tillgängliga i produktionssyfte, vilket effektiviserar distributionsprocessen och underhåller modellstyrningen.
Genom att använda MLflow tillsammans med Spark NLP kan du säkerställa effektiv hantering och distribution av NLP-pipelines, hantera moderna krav för skalbarhet och integrering samtidigt som du stöder avancerade tekniker som ordinbäddningar och anpassningar av stora språkmodeller.
Deltagare
Den här artikeln underhålls av Microsoft. Det har ursprungligen skrivits av följande medarbetare.
Huvudsakliga författare:
- Freddy Ayala | Molnlösningsarkitekt
- Moritz Steller | Senior Cloud Solution Architect
Nästa steg
Spark NLP-dokumentation:
Azure-komponenter:
Lär dig resurser: