En arkitektur för stordata är utformad för att hantera inmatning, bearbetning och analys av data som är för stora eller komplexa för traditionella databassystem.

Stordatalösningar omfattar vanligtvis en eller flera av följande typer av arbetsbelastningar:
- Batchbearbetning av vilande stordatakällor.
- Realtidsbearbetning av stordata i rörelse.
- Interaktiv utforskning av stordata.
- Förutsägelseanalys och maskininlärning.
De flesta stordataarkitekturer innehåller några eller alla följande komponenter:
Datakällor: Alla stordatalösningar börjar med en eller flera datakällor. Exempel är:
- Programdatalager, till exempel relationsdatabaser.
- Statiska filer som skapas av program, till exempel webbserverloggfiler.
- Realtidsdatakällor, till exempel IoT-enheter.
Data storage: Data för batchbearbetningsåtgärder lagras vanligtvis i ett distribuerat fillager som kan innehålla stora mängder stora filer i olika format. Den här typen av lagring kallas ofta för en datasjö. Alternativen för att implementera den här lagringen är Azure Data Lake Store eller blobcontainrar i Azure Storage.
Batch-bearbetning: Eftersom datauppsättningarna är så stora måste ofta en stordatalösning bearbeta datafiler med långvariga batchjobb för att filtrera, aggregera och på annat sätt förbereda data för analys. Vanligtvis omfattar dessa jobb att läsa källfiler, bearbeta dem och skriva utdata till nya filer. Alternativen omfattar användning av dataflöden, datapipelines i Microsoft Fabric.
meddelandeinmatning i realtid: Om lösningen innehåller realtidskällor måste arkitekturen innehålla ett sätt att samla in och lagra realtidsmeddelanden för dataströmbearbetning. Det kan vara ett enkelt datalager där inkommande meddelanden släpps till en mapp för bearbetning. Många lösningar behöver dock ett meddelandeinmatningslager för att fungera som en buffert för meddelanden och för att stödja utskalningsbearbetning, tillförlitlig leverans och andra semantik för meddelandeköer. Alternativen är Azure Event Hubs, Azure IoT Hubs och Kafka.
Stream-bearbetning: När du har avbildat realtidsmeddelanden måste lösningen bearbeta dem genom att filtrera, aggregera och på annat sätt förbereda data för analys. De bearbetade dataströmmen skrivs sedan till en utdatamottagare. Azure Stream Analytics tillhandahåller en hanterad dataströmbearbetningstjänst som baseras på ständigt körande SQL-frågor som körs på obundna strömmar. Ett annat alternativ är att använda realtidsinformation i Microsoft Fabric som gör att du kan köra KQL-frågor när data matas in.
Analysdatalager: Många stordatalösningar förbereder data för analys och hanterar sedan bearbetade data i ett strukturerat format som kan efterfrågas med hjälp av analysverktyg. Det analytiska datalager som används för att hantera dessa frågor kan vara ett relationsdatalager i Kimball-stil, enligt de flesta traditionella BI-lösningar (Business Intelligence) eller ett sjöhus med medaljongarkitektur (brons, silver och guld). Azure Synapse Analytics tillhandahåller en hanterad tjänst för storskalig, molnbaserad datalagerhantering. Alternativt tillhandahåller Microsoft Fabric båda alternativen – lager och lakehouse – som kan efterfrågas med hjälp av SQL respektive Spark.
Analys och rapportering: Målet med de flesta stordatalösningar är att ge insikter om data via analys och rapportering. För att användarna ska kunna analysera data kan arkitekturen innehålla ett datamodelleringslager, till exempel en flerdimensionell OLAP-kub eller tabelldatamodell i Azure Analysis Services. Det kan också stödja självbetjänings-BI med hjälp av modellerings- och visualiseringstekniker i Microsoft Power BI eller Microsoft Excel. Analys och rapportering kan också ske i form av interaktiv datautforskning av dataforskare eller dataanalytiker. I dessa scenarier tillhandahåller Microsoft Fabric verktyg som notebook-filer där användaren antingen kan välja SQL eller ett programmeringsspråk som användaren väljer.
Orchestration: De flesta stordatalösningar består av upprepade databearbetningsåtgärder, inkapslade i arbetsflöden, som transformerar källdata, flyttar data mellan flera källor och mottagare, läser in bearbetade data i ett analysdatalager eller skickar resultaten direkt till en rapport eller instrumentpanel. Om du vill automatisera dessa arbetsflöden kan du använda en orkestreringsteknik som Azure Data Factory eller Microsoft Fabric-pipelines.
Azure innehåller många tjänster som kan användas i en stordataarkitektur. De delas in i ungefär två kategorier:
- Hanterade tjänster, inklusive Microsoft Fabric, Azure Data Lake Store, Azure Synapse Analytics, Azure Stream Analytics, Azure Event Hubs, Azure IoT Hub och Azure Data Factory.
- Tekniker med öppen källkod baserade på Apache Hadoop-plattformen, inklusive HDFS, HBase, Hive, Spark och Kafka. Dessa tekniker är tillgängliga i Azure i Azure HDInsight-tjänsten.
De här alternativen är inte ömsesidigt uteslutande och många lösningar kombinerar tekniker med öppen källkod med Azure-tjänster.
När du ska använda den här arkitekturen
Tänk på den här arkitekturstilen när du behöver:
- Lagra och bearbeta data i volymer som är för stora för en traditionell databas.
- Transformera ostrukturerade data för analys och rapportering.
- Samla in, bearbeta och analysera obundna dataströmmar i realtid eller med låg svarstid.
- Använd Azure Machine Learning eller Azure AI-tjänster.
Fördelar
- Teknikval. Du kan blanda och matcha Azure-hanterade tjänster och Apache-tekniker i HDInsight-kluster för att dra nytta av befintliga kunskaper eller teknikinvesteringar.
- Prestanda genom parallellitet. Stordatalösningar drar nytta av parallellitet och möjliggör högpresterande lösningar som skalas till stora mängder data.
- Elastisk skalning. Alla komponenter i stordataarkitekturen stöder utskalningsetablering, så att du kan justera din lösning till små eller stora arbetsbelastningar och endast betala för de resurser som du använder.
- samverkan med befintliga lösningar. Komponenterna i stordataarkitekturen används också för IoT-bearbetning och företags-BI-lösningar, så att du kan skapa en integrerad lösning för dataarbetsbelastningar.
Utmaningar
- Complexity. Stordatalösningar kan vara extremt komplexa, med många komponenter för att hantera datainmatning från flera datakällor. Det kan vara svårt att skapa, testa och felsöka stordataprocesser. Dessutom kan det finnas ett stort antal konfigurationsinställningar i flera system som måste användas för att optimera prestanda.
- Skillset. Många stordatatekniker är mycket specialiserade och använder ramverk och språk som inte är typiska för mer allmänna programarkitekturer. Å andra sidan utvecklar stordatatekniker nya API:er som bygger på mer etablerade språk.
- Technology maturity. Många av de tekniker som används i stordata utvecklas. Medan grundläggande Hadoop-tekniker som Hive och Spark har stabiliserats, introducerar framväxande tekniker som delta eller isberg omfattande förändringar och förbättringar. Hanterade tjänster som Microsoft Fabric är relativt unga jämfört med andra Azure-tjänster och kommer sannolikt att utvecklas över tid.
- Security. Stordatalösningar förlitar sig vanligtvis på att lagra alla statiska data i en centraliserad datasjö. Det kan vara svårt att skydda åtkomsten till dessa data, särskilt när data måste matas in och användas av flera program och plattformar.
Metodtips
Utnyttja parallellitet. De flesta stordatabearbetningstekniker distribuerar arbetsbelastningen över flera bearbetningsenheter. Detta kräver att statiska datafiler skapas och lagras i ett delat format. Distribuerade filsystem som HDFS kan optimera läs- och skrivprestanda och den faktiska bearbetningen utförs av flera klusternoder parallellt, vilket minskar de totala jobbtiderna. Användning av delningsbart dataformat rekommenderas starkt, till exempel Parquet.
Partitioneringsdata. Batchbearbetning sker vanligtvis enligt ett återkommande schema , till exempel varje vecka eller månad. Partitionering av datafiler och datastrukturer, till exempel tabeller, baserat på tidsperioder som matchar bearbetningsschemat. Det förenklar datainmatning och jobbschemaläggning och gör det enklare att felsöka fel. Dessutom kan partitionering av tabeller som används i Hive-, Spark- eller SQL-frågor avsevärt förbättra frågeprestandan.
Använd schema-on-read-semantik. Med hjälp av en datasjö kan du kombinera lagring för filer i flera format, oavsett om de är strukturerade, halvstrukturerade eller ostrukturerade. Använd schema-on-read-semantik, som projicerar ett schema på data när data bearbetas, inte när data lagras. Detta skapar flexibilitet i lösningen och förhindrar flaskhalsar vid datainmatning som orsakas av dataverifiering och typkontroll.
Bearbeta data på plats. Traditionella BI-lösningar använder ofta en ETL-process (extract, transform, and load) för att flytta data till ett informationslager. Med större volymdata och en större mängd olika format använder stordatalösningar vanligtvis varianter av ETL, till exempel transformering, extrahering och inläsning (TEL). Med den här metoden bearbetas data i det distribuerade datalagret och transformerar dem till den struktur som krävs innan de omvandlade data flyttas till ett analysdatalager.
Balansera användnings- och tidskostnader. För batchbearbetningsjobb är det viktigt att tänka på två faktorer: kostnaden per enhet för beräkningsnoderna och kostnaden per minut för att använda dessa noder för att slutföra jobbet. Ett batchjobb kan till exempel ta åtta timmar med fyra klusternoder. Det kan dock visa sig att jobbet endast använder alla fyra noderna under de första två timmarna, och därefter krävs bara två noder. I så fall skulle körning av hela jobbet på två noder öka den totala jobbtiden, men inte fördubbla det, så den totala kostnaden skulle bli mindre. I vissa affärsscenarier kan en längre bearbetningstid vara att föredra framför den högre kostnaden för att använda underutnyttade klusterresurser.
Separata resurser. När det är möjligt bör du sträva efter att separera resurser baserat på arbetsbelastningarna för att undvika scenarier som en arbetsbelastning som använder alla resurser medan andra väntar.
Dirigera datainmatning. I vissa fall kan befintliga företagsprogram skriva datafiler för batchbearbetning direkt till Azure Storage Blob-containrar, där de kan användas av underordnade tjänster som Microsoft Fabric. Du behöver dock ofta samordna inmatningen av data från lokala eller externa datakällor till datasjön. Använd ett orkestreringsarbetsflöde eller en pipeline, till exempel de som stöds av Azure Data Factory eller Microsoft Fabric, för att uppnå detta på ett förutsägbart och centralt hanterbart sätt.
Rensa känsliga data tidigt. Arbetsflödet för datainmatning bör rensa känsliga data tidigt i processen för att undvika att lagra dem i datasjön.
IoT-arkitektur
Sakernas Internet (IoT) är en specialiserad delmängd av stordatalösningar. Följande diagram visar en möjlig logisk arkitektur för IoT. Diagrammet betonar komponenterna för händelseströmning i arkitekturen.
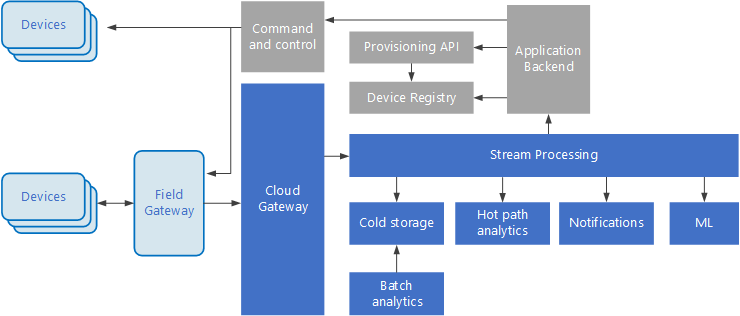
Den molngatewayen matar in enhetshändelser vid molngränsen med hjälp av ett tillförlitligt meddelandesystem med låg svarstid.
Enheter kan skicka händelser direkt till molngatewayen eller via en fältgateway. En fältgateway är en specialiserad enhet eller programvara, vanligtvis samlokaliserad med enheterna, som tar emot händelser och vidarebefordrar dem till molngatewayen. Fältgatewayen kan också förbearbeta de råa enhetshändelserna och utföra funktioner som filtrering, aggregering eller protokolltransformering.
Efter inmatningen går händelser igenom en eller flera dataströmprocessorer som kan dirigera data (till exempel till lagring) eller utföra analys och annan bearbetning.
Följande är några vanliga typer av bearbetning. (Denna lista är verkligen inte fullständig.)
Skriva händelsedata till kall lagring, för arkivering eller batchanalys.
Analys av frekvent sökväg, analys av händelseströmmen i (nära) realtid, för att identifiera avvikelser, identifiera mönster över rullande tidsfönster eller utlösa aviseringar när ett specifikt villkor inträffar i strömmen.
Hantera särskilda typer av icke-telemetrimeddelanden från enheter, till exempel meddelanden och larm.
Maskininlärning.
Rutorna som är skuggade grå visar komponenter i ett IoT-system som inte är direkt relaterade till händelseströmning, men som ingår här för fullständighet.
enhetsregister är en databas med etablerade enheter, inklusive enhets-ID:n och vanligtvis enhetsmetadata, till exempel plats.
etablerings-API:et är ett vanligt externt gränssnitt för etablering och registrering av nya enheter.
Vissa IoT-lösningar tillåter kommando- och kontrollmeddelanden skickas till enheter.
Det här avsnittet har presenterat en mycket övergripande vy över IoT, och det finns många subtiliteter och utmaningar att tänka på. Mer information finns i IoT-arkitekturer.
Nästa steg
- Läs mer om stordataarkitekturer.
- Läs mer om IoT-arkitekturer.