Spela in röstexempel för anpassad neural röst
Den här artikeln innehåller instruktioner om hur du förbereder röstexempel av hög kvalitet för att skapa en professionell röstmodell med hjälp av pro-projektet för anpassad neural röst.
Att skapa en anpassad neural röst av hög kvalitet från grunden är inte ett tillfälligt åtagande. Den centrala komponenten i en anpassad neural röst är en stor samling ljudexempel av mänskligt tal. Det är viktigt att dessa ljudinspelningar är av hög kvalitet. Välj en rösttalang som har erfarenhet av att göra den här typen av inspelningar och få dem inspelade av en inspelningstekniker som använder professionell utrustning.
Innan du kan göra dessa inspelningar behöver du dock ett skript: orden talas av din rösttalang för att skapa ljudexemplen.
Många små men viktiga detaljer går till att skapa en professionell röstinspelning. Den här guiden är en översikt över en process som hjälper dig att få bra, konsekventa resultat.
Tips för att förbereda data för en röst av hög kvalitet
En mycket naturlig anpassad neural röst beror på flera faktorer, till exempel kvaliteten och storleken på dina träningsdata.
Kvaliteten på dina träningsdata är en primär faktor. I samma träningsuppsättning är till exempel konsekvent volym, talfrekvens, talhöjd och talstil avgörande för att skapa en anpassad neural röst av hög kvalitet. Du bör också undvika bakgrundsbrus i inspelningen och se till att skriptet och inspelningen matchar. För att säkerställa kvaliteten på dina data måste du följa kriterierna för val av skript och inspelningskraven.
När det gäller storleken på träningsdata kan du i de flesta fall skapa en rimlig anpassad neural röst med 500 yttranden. Enligt våra tester förbättrar tillägg av mer träningsdata på de flesta språk inte nödvändigtvis själva röstens naturlighet (testas med MOS-poängen), men med mer träningsdata som täcker fler ordinstanser har du högre möjlighet att minska förhållandet mellan missnöjda delar av tal för rösten, till exempel problem. Information om hur missnöjda delar av tal låter finns i GitHub-exemplen.
I vissa fall kanske du vill ha en röstpersona med unika egenskaper. Till exempel behöver en tecknad persona en röst med en speciell talarstil, eller en röst som är dynamisk i intonation. I sådana fall rekommenderar vi att du förbereder minst 1 000 (helst 2 000) yttranden och registrerar dem i en professionell inspelningsstudio. Mer information om hur du förbättrar kvaliteten på din röstmodell finns i egenskaper och begränsningar för att använda anpassad neural röst.
Röstinspelningsroller
Det finns fyra grundläggande roller i ett anpassat neuralt röstinspelningsprojekt:
| Roll | Syfte |
|---|---|
| Rösttalang | Den här personens röst utgör grunden för den anpassade neurala rösten. |
| Inspelningstekniker | Övervakar de tekniska aspekterna av inspelningen och driver inspelningsutrustningen. |
| Regissör | Förbereder manus och coachar rösttalangens prestation. |
| Editor | Slutför ljudfilerna och förbereder dem för uppladdning till Speech Studio |
En individ kan fylla mer än en roll. Den här guiden förutsätter att du fyller rollen som regissör och anställer både en rösttalang och en inspelningstekniker. Om du vill göra inspelningarna själv innehåller den här artikeln information om inspelningsteknikerrollen. Redigeringsrollen behövs inte förrän efter inspelningssessionen. Under tiden kan regissören eller inspelningsteknikern fylla den här rollen.
Välj din rösttalang
Skådespelare med erfarenhet av voiceover, röstkaraktärsarbete, tillkännagivande eller nyhetsläsning gör bra rösttalanger. Välj rösttalang vars naturliga röst du gillar. Det är möjligt att skapa unika "karaktärsröster", men det är svårare för de flesta talanger att utföra dem konsekvent, och ansträngningen kan orsaka röstbelastning. Den enskilt viktigaste faktorn för att välja rösttalang är konsekvens. Dina inspelningar för samma röststil bör alla låta som om de gjordes samma dag i samma rum. Du kan närma dig det här idealet med hjälp av bra inspelningsmetoder och teknik.
Din rösttalang måste kunna tala med konsekvent hastighet, volymnivå, tonhöjd och ton med tydlig diktering. De måste också kunna kontrollera sin tonhöjdsvariation, känslomässiga effekt och talsätt. Att spela in röstexempel kan vara mer fatiguing än andra typer av röstarbete, så de flesta rösttalanger kan bara spela in två eller tre timmar om dagen. Begränsa sessioner till tre eller fyra dagar i veckan, med en ledig dag däremellan om möjligt.
Arbeta med din rösttalang för att utveckla en persona som definierar det övergripande ljudet och den känslomässiga tonen i den anpassade neurala rösten. Definiera talarstilarna för din persona och be din rösttalang att läsa skriptet på ett sätt som överensstämmer med dina önskade format. Se till att talstilen förblir konsekvent under inspelningarna för en uppsättning träningsdata.
Till exempel skulle en persona med en naturligt optimistisk personlighet bära en ton av optimism i sin röst. Den här personligheten bör dock uttryckas konsekvent i alla inspelningar för en uppsättning träningsdata. Lyssna på befintliga röster för att få en uppfattning om vad du siktar på.
Dricks
Vanligtvis vill du äga röstinspelningarna du gör. Din rösttalang bör vara berättigad till ett anställningskontrakt för projektet.
Skapa ett skript
Utgångspunkten för en anpassad neural röstinspelningssession är skriptet, som innehåller yttranden som ska talas av din rösttalang. Termen "yttranden" omfattar både fullständiga meningar och kortare fraser. Att skapa en anpassad neural röst kräver minst 300 inspelade yttranden som träningsdata.
Yttrandena i ditt skript kan komma var som helst: fiktion, facklitteratur, transkriptioner av tal, nyhetsrapporter och allt annat som är tillgängligt i tryckt form. En kort diskussion om potentiella juridiska problem finns i avsnittet "Legalities" . Du kan också skriva din egen text.
Dina yttranden behöver inte komma från samma källa, samma typ av källa eller ha något att göra med varandra. Men om du använder uppsättningsfraser (till exempel "Du har loggat in") i ditt talprogram måste du inkludera dem i skriptet. Det ger din anpassade neurala röst en bättre chans att uttala dessa fraser väl.
Vi rekommenderar att inspelningsskripten innehåller både allmänna meningar och domänspecifika meningar. Om du till exempel planerar att registrera 2 000 meningar kan 1 000 av dem vara allmänna meningar, ytterligare 1 000 av dem kan vara meningar från måldomänen eller användningsfallet för ditt program.
Vi tillhandahåller exempelskript i domänerna "Allmänt", "Chatt" och "Kundtjänst" för varje språk som hjälper dig att förbereda dina inspelningsskript. Du kan använda dessa delade Microsoft-skript för dina inspelningar direkt eller använda dem som referens för att skapa egna.
Villkor för val av skript
Nedan följer några allmänna riktlinjer som du kan följa för att skapa en bra corpus (inspelade ljudexempel) för anpassad neural röstträning.
Balansera skriptet för att täcka olika meningstyper i din domän, inklusive instruktioner, frågor, utrop, långa meningar och korta meningar.
Varje mening ska innehålla fyra ord till 30 ord och inga duplicerade meningar ska ingå i skriptet.
Information om hur du balanserar de olika meningstyperna finns i följande tabell:Meningstyper Täckning Instruktions meningar Instruktions meningar ska vara 70–80 % av skriptet. Fråge meningar Fråge meningar bör vara cirka 10%-20% av domänskriptet, inklusive 5%-10% av stigande och 5%-10% av fallande toner. Utropstecken meningar Utropstecken meningar bör vara cirka 10%-20% av skriptet. Kort ord/fras Korta ord-/frasskript bör vara cirka 10 % av de totala yttrandena, med 5 till 7 ord per fall. Kommentar
Korta ord/fraser ska separeras med kommatecken. De hjälper till att påminna din rösttalang att pausa kort när du läser dem.
Metodtips är:
- Balanserad täckning för delar av tal, till exempel verb, substantiv, adjektiv och så vidare.
- Balanserad täckning för uttal. Inkludera alla bokstäver från A till Z så att text-till-tal-motorn lär sig att uttala varje bokstav i din stil.
- Läsbara, begripliga, förnuftiga skript som talaren kan läsa.
- Undvik för många liknande mönster för ord/fraser, till exempel "enkelt" och "enklare".
- Inkludera olika format för tal: adress, enhet, telefon, kvantitet, datum och så vidare, i alla meningstyper.
- Inkludera stavnings meningar om det är något som din anpassade neurala röst läser. Till exempel "Stavningen av Apple är A P P L E".
Placera inte flera meningar i en rad/ett yttrande. Avgränsa varje rad efter yttrande.
Kontrollera att meningen är ren. Ta vanligtvis inte med för många icke-standardord som siffror eller förkortningar eftersom de är svåra att läsa. Vissa program kan kräva läsning av många tal eller förkortningar. I dessa fall kan du inkludera dessa ord, men normalisera dem i deras talade form.
Nedan följer några metodtips, till exempel:
- För rader med förkortningar, i stället för "BTW", skriver du "förresten".
- För rader med siffror, i stället för "911", skriver du "nio en".
- För rader med förkortningar, i stället för "ABC", skriver du "A B C".
Se till att din rösttalang uttalar dessa ord på ett förväntat sätt. Håll skriptet och inspelningarna matchade under träningsprocessen.
Skriptet bör innehålla många olika ord och meningar med olika typer av meningslängder, strukturer och stämningar.
Kontrollera skriptet noggrant efter fel. Om möjligt, låt någon annan kontrollera det också. När du kör igenom skriptet med din rösttalang kan du få fler misstag.
Skillnad mellan rösttalangskript och träningsskript
Träningsskriptet kan skilja sig från rösttalangskriptet, särskilt för skript som innehåller siffror, symboler, förkortningar, datum och tid. Skript som är förberedda för rösttalangen måste följa interna läskonventioner, till exempel 50% och $ 45. Skripten som används för träning måste normaliseras för att matcha ljudinspelningen, till exempel femtio procent och fyrtiofem dollar.
Kommentar
Vi tillhandahåller några exempelskript för rösttalangen på GitHub. Om du vill använda exempelskripten för träning måste du normalisera dem enligt inspelningarna av din rösttalang innan du laddar upp filen.
I följande tabell visas skillnaden mellan skript för rösttalanger och det normaliserade skriptet för träning.
| Kategori | Exempel på rösttalangskript | Exempel på träningsskript (normaliserad) |
|---|---|---|
| Siffror | 123 | 123 |
| Symboler | 50 % | femtio procent |
| Förkortning | ASAP | Så snart som möjligt |
| Datum och tid | 3 mars kl. 17:00 | Mars trea kl. 17.00 |
Vanliga fel i ett skript
Skriptets dåliga kvalitet kan påverka träningsresultaten negativt. För att uppnå högkvalitativa träningsresultat är det viktigt att undvika defekter.
Skriptfel hör vanligtvis till följande kategorier:
| Kategori | Exempel |
|---|---|
| Meningslöst innehåll. | "Färglösa gröna idéer sover ursinnigt." |
| Ofullständiga meningar. | - "Detta var min sista kväll" (inget ämne, ingen specifik betydelse) - "De är redan roliga (inget citattecken i slutändan, det är inte en fullständig mening) |
| Skriv in meningarna. | – Börja med ett gemener – Ingen avslutande skiljetecken om det behövs -Felstavning - Brist på skiljetecken: ingen period i slutet (förutom nyhetstitel) - Avsluta med symboler, utom kommatecken, fråga, utropstecken – Fel format, till exempel: - 45$ (bör vara $45) - Inget utrymme eller överflödigt utrymme mellan ord/skiljetecken |
| Duplicering i liknande format räcker med ett per mönster. | - "Nu är det 13:00 i New York" - "Nu är det 14:00 i New York" - "Nu är det 15:00 i New York" - "Nu är det 13:00 i Seattle" - "Nu är det 13:00 i Washington D.C." |
| Ovanliga främmande ord: endast vanliga främmande ord är acceptabla i skriptet. | På engelska kan man använda det franska ordet "faux" i vanligt tal, men ett franskt uttryck som "coincer la bulle" skulle vara ovanligt. |
| Emoji eller andra ovanliga symboler |
Skriptformat
Skriptet är till för användning under inspelningssessioner, så att du kan konfigurera det på alla sätt som du enkelt kan arbeta med. Skapa textfilen som krävs av Speech Studio separat.
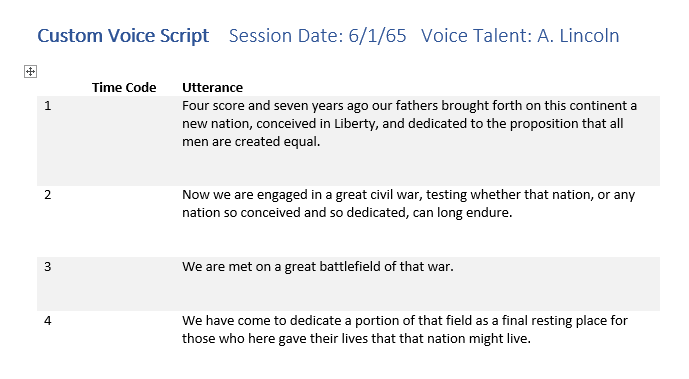
Ett grundläggande skriptformat innehåller tre kolumner:
- Antalet yttranden som börjar på 1. Numrering gör det enkelt för alla i studion att referera till ett visst yttrande ("låt oss försöka nummer 356 igen"). Du kan använda styckenumreringsfunktionen i Microsoft Word för att numrera raderna i tabellen automatiskt.
- En tom kolumn där du skriver koden ta nummer eller tid för varje yttrande som hjälper dig att hitta den i den färdiga inspelningen.
- Texten i själva yttrandet.
Kommentar
De flesta studior spelar in i korta segment som kallas "takes". Varje tagning innehåller vanligtvis 10 till 24 yttranden. Att bara notera tagningsnumret räcker för att hitta ett yttrande senare. Om du spelar in i en studio som föredrar att göra längre inspelningar bör du anteckna tidskoden i stället. Studion kommer att ha en framträdande tidsvisning.
Lämna tillräckligt med utrymme efter varje rad för att skriva anteckningar. Se till att inget yttrande delas upp mellan sidor. Numrera sidorna och skriv ut skriptet på ena sidan av papperet.
Skriv ut tre kopior av skriptet: en för rösttalangen, en för inspelningsteknikern och en för regissören (du). Använd ett gem i stället för häftklamrar: en erfaren röstkonstnär separerar sidorna för att undvika att göra ljud när sidorna vänds.
Rösttalang uttalande
För att träna en neural röst måste du skapa en rösttalangprofil med en ljudfil som spelas in av rösttalangen och samtycka till användningen av deras taldata för att träna en anpassad röstmodell. När du förbereder inspelningsskriptet måste du inkludera instruktionssatsen.
Lagligheten
Enligt upphovsrättslagen kan en aktörs läsning av upphovsrättsskyddad text vara en föreställning som verkets författare bör kompenseras för. Den här prestandan går inte att känna igen i slutprodukten, den anpassade neurala rösten. Trots detta är lagenligheten av att använda ett upphovsrättsskyddat verk för detta ändamål inte väletablerad. Microsoft kan inte ge juridisk rådgivning om det här problemet. kontakta din egen juridiska rådgivare.
Lyckligtvis är det möjligt att undvika dessa problem helt och hållet. Det finns många textkällor som du kan använda utan behörighet eller licens.
| Textkälla | beskrivning |
|---|---|
| CMU Arctic corpus | Cirka 1 100 meningar som valts ut från verk som inte är upphovsrättsskyddade fungerar specifikt för användning i talsyntesprojekt. En utmärkt utgångspunkt. |
| Fungerar inte längre under copyright |
Fungerar vanligtvis som publicerat före 1923. För engelska erbjuder Project Gutenberg tiotusentals sådana verk. Du kanske vill fokusera på nyare verk, eftersom språket är närmare modern engelska. |
| Myndighetsarbeten | Verk som skapats av USA myndigheter är inte upphovsrättsskyddade i USA, även om regeringen kan göra anspråk på upphovsrätt i andra länder/regioner. |
| Offentlig domän | Verk för vilka upphovsrätt uttryckligen frisägs eller tillägnas den offentliga domänen. Det kanske inte går att avstå från upphovsrätten helt och hållet i vissa jurisdiktioner. |
| Tillåtande licensierade verk | Verk som distribueras under en licens som Creative Commons eller GNU Free Documentation License (GFDL). Wikipedia använder GFDL. Vissa licenser kan dock införa begränsningar för prestanda för det licensierade innehållet som kan påverka skapandet av en anpassad neural röstmodell, så läs licensen noggrant. |
Spela in skriptet
Spela in ditt skript i en professionell inspelningsstudio som specialiserar sig på röstarbete. De har en inspelningsbås, rätt utrustning och rätt personer att använda den. Vi rekommenderar att du inte snålar med inspelningen.
Diskutera ditt projekt med studions inspelningstekniker och lyssna på deras råd. Inspelningen bör ha liten eller ingen komprimering av dynamiskt intervall (högst 4:1). Det är viktigt att ljudet har konsekvent volym och ett högt signal-till-brus-förhållande, samtidigt som det är fritt från oönskade ljud.
Inspelningskrav
För att uppnå högkvalitativa träningsresultat följer du följande krav under registreringen eller förberedelsen av data:
Tydlig och väl uttalad
Naturlig hastighet: inte för långsam eller för snabb mellan ljudfiler.
Lämplig volym, prosody och brytpunkt: stabil inom samma mening eller mellan meningar, rätt brytpunkt för skiljetecken.
Inget brus under inspelningen
Anpassa din personadesign
Ingen fel accent: anpassa till måldesignen
Inget felaktigt uttal
Du kan se nedanstående specifikation för att förbereda för ljudexemplen som bästa praxis.
| Property | Värde |
|---|---|
| File format | *.wav, Mono |
| Samplingsfrekvens | 24 KHz |
| Samplingsformat | 16 bitar, PCM |
| Högsta volymnivåer | -3 dB till -6 dB |
| SNR | > 35 dB |
| Tystnad | - Det bör finnas viss tystnad (rekommendera 100 ms) i början och slutet, men inte längre än 200 ms - Tystnad mellan ord eller fraser < -30 dB - Tystnad i vågen efter sista ordet talas <-60 dB |
| Miljöbrus eller eko | - Ljudnivån i början av vågen innan du talar < -70 dB |
Kommentar
Du kan registrera med högre samplingshastighet och bitdjup, till exempel i formatet 48 KHz 24-bitars PCM. Under den anpassade neurala röstträningen ska vi ta ett exempel på det till 24 KHz 16-bitars PCM automatiskt.
Ett högre signal-till-brus-förhållande (SNR) indikerar lägre brus i ljudet. Du kan vanligtvis nå en 35+ SNR genom att spela in på professionella studior. Ljud med en SNR under 20 kan resultera i uppenbart brus i din genererade röst.
Överväg att spela in eventuella yttranden med låga uttalspoäng eller dåliga signal-till-brus-förhållanden. Om du inte kan registrera igen kan du överväga att exkludera dessa yttranden från dina data.
Vanliga ljudfel
För högkvalitativa träningsresultat rekommenderar vi starkt att du undviker ljudfel. Ljudfel finns vanligtvis inom följande kategorier:
Namnet på ljudfilen matchar inte skript-ID:t.
WAR-filen har ett ogiltigt format och kan inte läsas.
Ljudsamplingshastigheten är lägre än 16 KHz. Vi rekommenderar att .wav filsamplingshastigheten är lika med eller högre än 24 KHz för neural röst av hög kvalitet.
Volymtoppen ligger inte inom intervallet -3 dB (70 % av maxvolymen) till -6 dB (50 %).
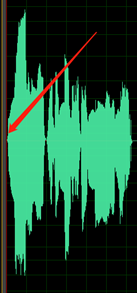
Vågformsspill: vågformen skärs vid dess högsta värde och är därför inte fullständig.
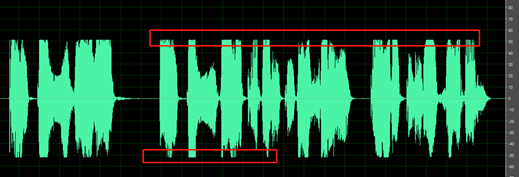
De tysta delarna av inspelningen är inte rena. du kan höra ljud som omgivningsbrus, munbrus och eko.
Till exempel innehåller ljudet nedan miljöbruset mellan tal.
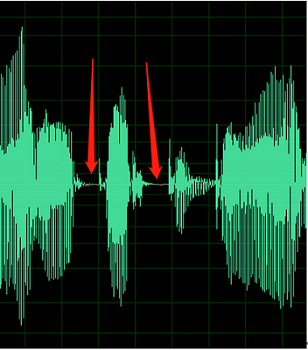
Exemplet nedan innehåller tecken på DC-förskjutning eller eko.
Den totala volymen är för låg. Dina data taggas som ett problem om volymen är lägre än -18 dB (10 % av maxvolymen). Kontrollera att alla ljudfiler ska vara konsekventa på samma volymnivå.
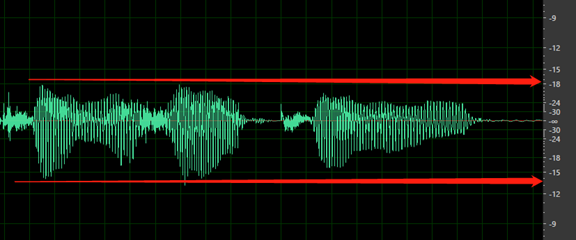
Ingen tystnad före det första ordet eller efter sista ordet. Dessutom bör tystnaden för start eller slut inte vara längre än 200 ms eller kortare än 100 ms.
Gör det själv
Om du vill göra inspelningen själv, istället för att gå in i en inspelningsstudio, här är en kort primer. Tack vare uppkomsten av heminspelning och podcasting är det lättare än någonsin att hitta bra inspelningsråd och resurser online.
Din "inspelningsbås" ska vara ett litet rum utan märkbar eko eller "rumston". Det ska vara så tyst och ljudisolerat som möjligt. Draperier på väggarna kan användas för att minska eko och neutralisera eller "döda" ljudet av rummet.
Använd en studiokondensatormikrofon av hög kvalitet ("mikrofon" för kort) avsedd för inspelning av röst. Sennheiser, AKG och ännu nyare Zoom-mikrofoner kan ge bra resultat. Du kan köpa en mikrofon eller hyra en från en lokal audiovisuell uthyrningsfirma. Leta efter en med ett USB-gränssnitt. Den här typen av mikrofon kombinerar bekvämt mikrofonelementet, preamp- och analog-till-digital-konverteraren till ett paket, vilket förenklar uppkopplingen.
Du kan också använda en analog mikrofon. Många hyreshus erbjuder "vintage" mikrofoner kända för sin röstkaraktär. Professionell analog växel använder balanserade XLR-anslutningar, snarare än den 1/4-tums plugg som används i konsumentutrustning. Om du går analogt behöver du också en preamp och ett datorljudgränssnitt med dessa anslutningsappar.
Installera mikrofonen på ett stativ eller en bom och installera ett popfilter framför mikrofonen för att eliminera brus från "plosive" konsonanter som "p" och "b". Vissa mikrofoner levereras med en fjädringsmontering som isolerar dem från vibrationer i stativet, vilket är användbart.
Rösttalangen måste hålla sig på ett konsekvent avstånd från mikrofonen. Använd tejp på golvet för att markera var de ska stå. Om talangen föredrar att sitta, var särskilt noga med att övervaka mikrofonavstånd och undvika stolsbrus.
Använd ett stativ för att lagra skriptet. Undvik att meta stativet så att det kan reflektera ljud mot mikrofonen.
Den person som använder inspelningsutrustningen - inspelningsteknikern - bör vara i ett separat rum från talangen, med något sätt att prata med talangen i inspelningsbåset (en talkback-krets).
Inspelningen ska innehålla så lite brus som möjligt, med målet -80 dB.
Lyssna noga på en inspelning av tystnad i din "monter", ta reda på var allt brus kommer ifrån och eliminera orsaken. Vanliga källor till buller är luftventiler, lysrör, trafik på närliggande vägar och utrustningsfans (även notebook-datorer kan ha fläktar). Mikrofoner och kablar kan fånga upp elektriskt brus från närliggande AC-ledningar, vanligtvis ett surr eller surr. Ett surr kan också orsakas av en jordslinga, som orsakas av att utrustning är ansluten till mer än en elektrisk krets.
Dricks
I vissa fall kanske du kan använda en equalizer eller ett plugin-program för brusreducering för att ta bort brus från dina inspelningar, även om det alltid är bäst att stoppa det vid källan.
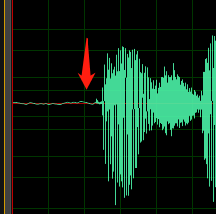
Ange nivåer så att det mesta av det tillgängliga dynamiska intervallet för digital inspelning används utan överkörning. Det innebär att ställa in ljudet högt, men inte så högt att det blir förvrängt. Ett exempel på vågformen för en bra inspelning visas i följande bild:
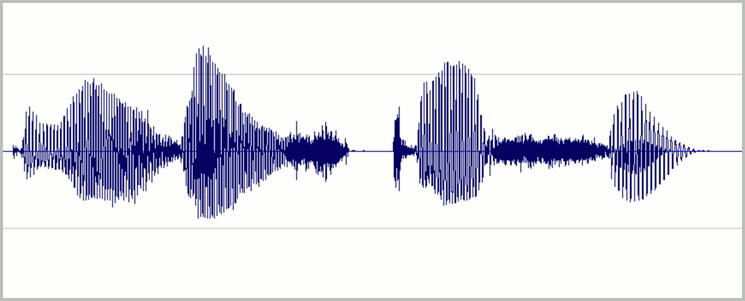
Här används det mesta av intervallet (höjd), men signalens högsta toppar når inte fönstrets övre eller nedre del. Du kan också se att tystnaden i inspelningen approximerar en tunn vågrät linje, vilket indikerar ett lågt brusgolv. Denna inspelning har acceptabelt dynamiskt omfång och signal-till-brus-förhållande.
Spela in direkt i datorn via ett högkvalitativt ljudgränssnitt eller en USB-port, beroende på vilken mikrofon du använder. För analog, håll ljudkedjan enkel: mikrofon, preamp, ljudgränssnitt, dator. Du kan licensiera både Avid Pro Tools och Adobe Audition varje månad till en rimlig kostnad. Om din budget är extremt stram kan du prova den kostnadsfria Audacity.
Spela in på 44,1 KHz 16 bitar monofonisk (CD-kvalitet) eller bättre. Den senaste tekniken är 48 KHz 24 bitar, om din utrustning stöder den. Du kommer att ta bort ljudet till 24 KHz 16-bitars innan du skickar det till Speech Studio. Ändå lönar det sig att ha en högkvalitativ originalinspelning i händelse av att redigeringar behövs.
Helst har olika människor tjänar i rollerna chef, ingenjör och talang. Försök inte göra allt själv. I en nypa kan en person vara både regissören och ingenjören.
Före sessionen
Undvik att slösa studiotid genom att köra igenom skriptet med din rösttalang före inspelningssessionen. Medan rösttalangen blir bekant med texten, kan de klargöra uttalet av alla obekanta ord.
Kommentar
De flesta inspelningsstudior erbjuder elektronisk visning av skript i inspelningsbåset. I det här fallet skriver du dina genomkörda anteckningar direkt i skriptets dokument. Du vill dock fortfarande att en papperskopia ska antecknas under sessionen. De flesta tekniker vill också ha en papperskopia. Och du vill fortfarande ha en tredje tryckt kopia som en säkerhetskopia för talangen om datorn är nere.
Din rösttalang kan fråga vilket ord du vill framhäva i ett yttrande (det "avgörande ordet"). Berätta för dem att du vill ha en naturlig läsning utan särskild betoning. Betoning kan läggas till när tal syntetiseras. det bör inte vara en del av den ursprungliga inspelningen.
Be talangen att uttala ord tydligt. Varje ord i skriptet ska uttalas som skrivet. Ljud bör inte utelämnas eller sluddras tillsammans, vilket är vanligt i tillfälligt tal, såvida de inte har skrivits på det sättet i skriptet.
| Skriftlig text | Oönskat tillfälligt uttal |
|---|---|
| aldrig kommer att ge upp dig | aldrig kommer att ge upp dig |
| det finns fyra lampor | det finns fyra lampor |
| hur är vädret idag | how's th' väder idag |
| säga hej till min lilla vän | säg hej till min lil vän |
Talangen bör inte* lägga till distinkta pauser mellan ord. Meningen bör fortfarande flöda naturligt, även om den låter lite formell. Denna fina distinktion kan ta praxis för att få rätt.
Inspelningssessionen
Skapa en referensinspelning, eller matchningsfil, av ett typiskt yttrande i början av sessionen. Be talangen att upprepa den här raden varje sida eller så. Jämför varje gång den nya inspelningen med referensen. Den här övningen hjälper talangen att förbli konsekvent i volym, tempo, tonhöjd och intonation. Under tiden kan teknikern använda matchningsfilen som referens för nivåer och övergripande konsekvens av ljud.
Matchningsfilen är särskilt viktig när du återupptar inspelningen efter en paus eller en annan dag. Spela det några gånger för talangen och låt dem upprepa det varje gång tills de matchar bra.
Om du vill spela in en corpus med ett visst format väljer du noggrant skript som visar önskad stil. Under inspelningen ser du till att rösttalangen bibehåller konsekvent i volym, tempo, tonhöjd och ton för att uppnå inspelningar som förkroppsligar den avsedda stilen.
Coacha din talang för att ta ett djupt andetag och pausa en stund före varje yttrande. Spela in ett par sekunders tystnad mellan yttranden. Ord bör uttalas på samma sätt varje gång de visas, med tanke på kontexten. Till exempel uttalas "post" som ett verb annorlunda än "post" som ett substantiv.
Spela in cirka fem sekunders tystnad före den första inspelningen för att fånga "rumstonen". Den här metoden hjälper Speech Studio att kompensera för brus i inspelningarna.
Dricks
Allt du behöver för att fånga är rösttalangen, så att du kan göra en monofonisk (enkanalig) inspelning av bara deras rader. Men om du spelar in i stereo kan du använda den andra kanalen för att spela in pratet i kontrollrummet för att fånga upp diskussioner om vissa rader eller tagningar. Ta bort det här spåret från den version som laddas upp till Speech Studio.
Lyssna noga, med hörlurar, på rösttalangens prestanda. Du letar efter bra men naturlig diction, rätt uttal och brist på oönskade ljud. Tveka inte att be din talang att spela in ett yttrande som inte uppfyller dessa standarder.
Dricks
Om du använder ett stort antal yttranden kanske ett enda yttrande inte har någon märkbar effekt på den resulterande anpassade neurala rösten. Det kan vara mer lämpligt att bara notera eventuella yttranden med problem, exkludera dem från din datauppsättning och se hur din anpassade neurala röst blir. Du kan alltid gå tillbaka till studion och spela in de missade exemplen senare.
Observera koden för att ta nummer eller tid på skriptet för varje yttrande. Be teknikern att markera varje yttrande i inspelningens metadata eller referensblad.
Ta regelbundna pauser och ge en dryck för att hjälpa din rösttalang att hålla sin röst i gott skick.
Efter sessionen
Moderna inspelningsstudior körs på datorer. I slutet av sessionen får du en eller flera ljudfiler, inte ett band. Dessa filer är förmodligen WAV- eller AIFF-format i CD-kvalitet (44,1 KHz 16-bitars) eller bättre. 24 KHz 16-bitars är vanligt och önskvärt. Standardsamplingsfrekvensen för en anpassad neural röst är 24 KHz. Vi rekommenderar att du använder en exempelfrekvens på 24 KHz och högre för dina träningsdata. Högre samplingshastigheter, till exempel 96 KHz, behövs vanligtvis inte.
Speech Studio kräver att varje angivet yttrande finns i sin egen fil. Varje ljudfil som levereras av studion innehåller flera yttranden. Därför är den primära uppgiften efter produktion att dela upp inspelningarna och förbereda dem för sändning. Inspelningsteknikern kan ha placerat markörer i filen (eller tillhandahållit ett separat referensblad) för att ange var varje yttrande startar.
Använd dina anteckningar för att hitta de exakta tagningarna du vill ha och använd sedan ett verktyg för ljudredigering, till exempel Avid Pro Tools, Adobe Audition eller den kostnadsfria Audacity, för att kopiera varje yttrande till en ny fil.
Lyssna noga på varje fil. I det här skedet kan du redigera ut små oönskade ljud som du missade under inspelningen, som en liten läppsmet före en rad, men var noga med att inte ta bort något faktiskt tal. Om du inte kan åtgärda en fil tar du bort den från datauppsättningen och noterar att du har gjort det.
Konvertera varje fil till 16 bitar och en exempelfrekvens på 24 KHz och högre innan du sparar och ta bort den andra kanalen om du spelade in studiochattet. Spara varje fil i WAV-format och namnge filerna med yttrandenumret från skriptet.
Skapa slutligen avskriften som associerar varje WAV-fil med en textversion av motsvarande yttrande. Träna din röstmodell innehåller information om det format som krävs. Du kan kopiera texten direkt från skriptet. Skapa sedan en Zip-fil med WAV-filerna och textavskriften.
Arkivera de ursprungliga inspelningarna på en säker plats om du behöver dem senare. Bevara skriptet och anteckningarna också.
Nästa steg
Du är redo att ladda upp dina inspelningar och skapa din anpassade neurala röst.