Prestanda och svarstider
Den här artikeln innehåller bakgrundsinformation om hur svarstid och dataflöde fungerar med Azure OpenAI och hur du optimerar din miljö för att förbättra prestandan.
Förstå dataflöde kontra svarstid
Det finns två viktiga begrepp att tänka på när du ändrar storlek på ett program: (1) Dataflöde på systemnivå mätt i token per minut (TPM) och (2) svarstider per anrop (kallas även svarstid).
Dataflöde på systemnivå
Då tittar vi på distributionens totala kapacitet – hur många begäranden per minut och totalt antal token som kan bearbetas.
För en standarddistribution avgör den kvot som tilldelats distributionen delvis hur mycket dataflöde du kan uppnå. Kvoten avgör dock bara antagningslogik för anrop till distributionen och framtvingar inte direkt dataflöde. På grund av variationer i svarstid per anrop kanske du inte kan uppnå ett dataflöde så högt som din kvot. Läs mer om att hantera kvoter.
I en etablerad distribution allokeras en viss mängd modellbearbetningskapacitet till slutpunkten. Mängden dataflöde som du kan uppnå på slutpunkten är en faktor för arbetsbelastningens form, inklusive indatatokens belopp, utdatamängd, anropsfrekvens och cachematchningshastighet. Antalet samtidiga anrop och totalt antal bearbetade token kan variera beroende på dessa värden.
För alla distributionstyper är förståelse av dataflöde på systemnivå en viktig komponent för att optimera prestanda. Det är viktigt att överväga dataflöde på systemnivå för en viss modell, version och arbetsbelastningskombination eftersom dataflödet varierar mellan dessa faktorer.
Beräkna dataflöde på systemnivå
Beräkna TPM med Azure Monitor-mått
En metod för att beräkna dataflödet på systemnivå för en viss arbetsbelastning är att använda historiska tokenanvändningsdata. För Azure OpenAI-arbetsbelastningar kan alla historiska användningsdata nås och visualiseras med de inbyggda övervakningsfunktioner som erbjuds i Azure OpenAI. Två mått krävs för att beräkna dataflödet på systemnivå för Azure OpenAI-arbetsbelastningar: (1) Bearbetade prompttoken och (2) genererade slutförandetoken.
När de kombineras ger måtten för bearbetade prompttoken (indata-TPM) och genererade slutförandetoken (utdata-TPM) en uppskattad vy över dataflödet på systemnivå baserat på den faktiska arbetsbelastningstrafiken. Den här metoden tar inte hänsyn till fördelarna med snabb cachelagring, så det blir en konservativ beräkning av systemets dataflöde. Dessa mått kan analyseras med minsta, genomsnittliga och maximala aggregering över 1 minuts fönster över en tidshorisont för flera veckor. Vi rekommenderar att du analyserar dessa data under en tidshorisont på flera veckor för att säkerställa att det finns tillräckligt med datapunkter att utvärdera. Följande skärmbild visar ett exempel på måttet För bearbetade prompttoken som visualiserats i Azure Monitor, som är tillgängligt direkt via Azure Portal.
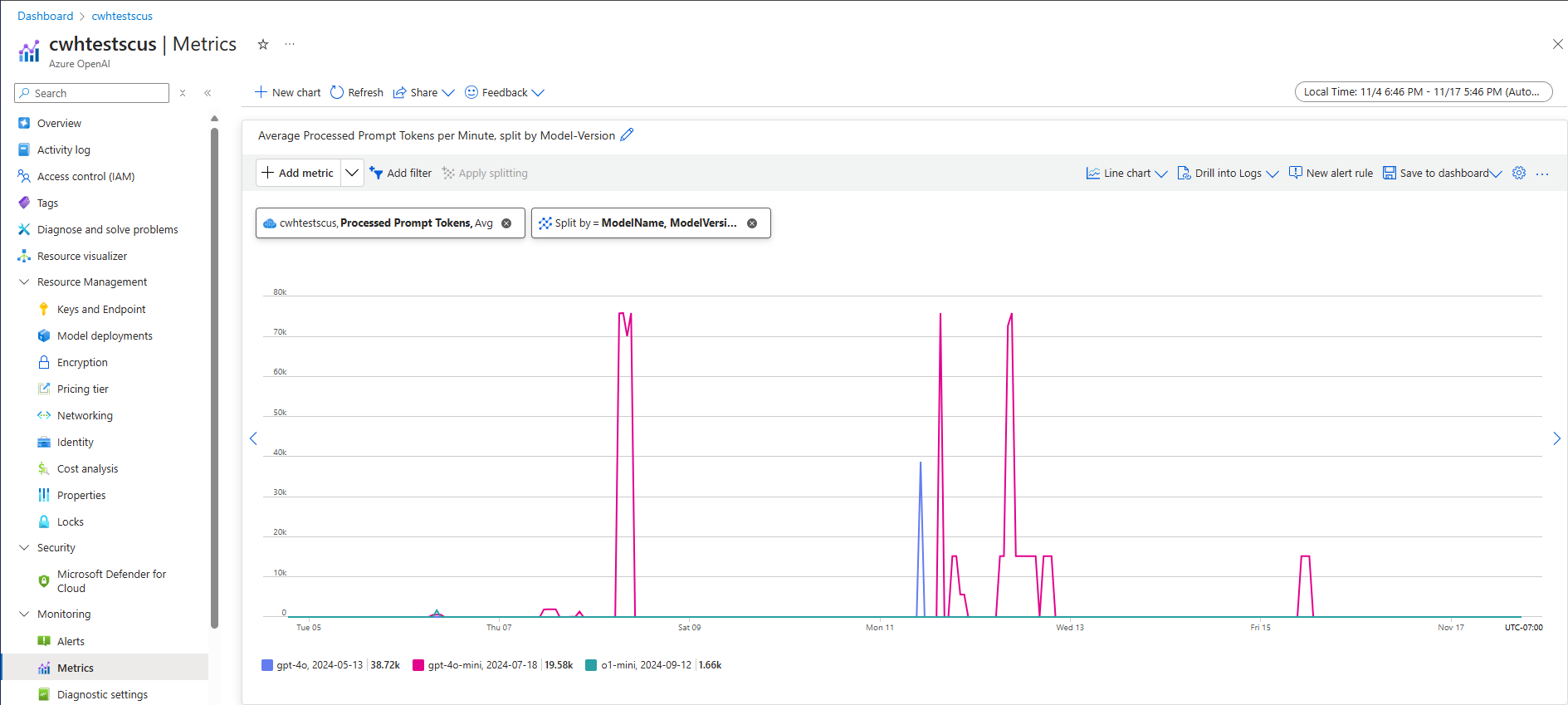
Beräkna TPM från begärandedata
En andra metod för uppskattat dataflöde på systemnivå är att samla in information om tokenanvändning från API-begärandedata. Den här metoden ger en mer detaljerad metod för att förstå arbetsbelastningsformen per begäran. Att kombinera användningsinformation för token per begäran med begärandevolym, mätt i begäranden per minut (RPM), ger en uppskattning av dataflödet på systemnivå. Det är viktigt att observera att alla antaganden som görs för konsekvens av tokenanvändningsinformation för begäranden och begärandevolym påverkar systemets dataflödesuppskattning. Utdata för tokenanvändning finns i API-svarsinformationen för en viss begäran om slutförande av Azure OpenAI-tjänstens chatt.
{
"body": {
"id": "chatcmpl-7R1nGnsXO8n4oi9UPz2f3UHdgAYMn",
"created": 1686676106,
"choices": [...],
"usage": {
"completion_tokens": 557,
"prompt_tokens": 33,
"total_tokens": 590
}
}
}
Förutsatt att alla begäranden för en viss arbetsbelastning är enhetliga kan prompttoken och slutförandetoken från API-svarsdata multipliceras med den uppskattade RPM:en för att identifiera in- och utdata-TPM för den angivna arbetsbelastningen.
Så här använder du dataflödesuppskattningar på systemnivå
När dataflödet på systemnivå har uppskattats för en viss arbetsbelastning kan dessa uppskattningar användas för att storleksanpassa standard- och etablerade distributioner. För Standard-distributioner kan TPM-värdena för indata och utdata kombineras för att uppskatta den totala TPM som ska tilldelas till en viss distribution. För etablerade distributioner kan användningsdata för begärandetoken eller TPM-värden för indata och utdata användas för att uppskatta antalet PTU:er som krävs för att stödja en viss arbetsbelastning med distributionskapacitetskalkylatorns upplevelse.
Här är några exempel på minimodellen GPT-4o:
| Fråga storlek (token) | Generationsstorlek (token) | Antal begäranden per minut | Indata-TPM | Utdata-TPM | Totalt antal TPM | PTUs krävs |
|---|---|---|---|---|---|---|
| 800 | 150 | 30 | 24,000 | 4 500 | 28,500 | 15 |
| 5 000 | 50 | 1 000 | 5,000,000 | 50,000 | 5,050,000 | 140 |
| 1 000 | 300 | 500 | 500,000 | 150 000 | 650,000 | 30 |
Antalet PTU:er skalas ungefär linjärt med anropshastighet när arbetsbelastningsfördelningen förblir konstant.
Svarstid: Svarstiderna per samtal
Den övergripande definitionen av svarstid i den här kontexten är hur lång tid det tar att få tillbaka ett svar från modellen. För slutförande- och chattbegäranden är svarstiden till stor del beroende av modelltyp, antalet token i prompten och antalet token som genereras. I allmänhet lägger varje prompttoken till lite tid jämfört med varje inkrementell token som genereras.
Det kan vara svårt att beräkna din förväntade svarstid per anrop med dessa modeller. Svarstiden för en slutförandebegäran kan variera beroende på fyra primära faktorer: (1) modellen, (2) antalet token i prompten, (3) antalet token som genereras och (4) den totala belastningen på distributionen och systemet. En och tre är ofta de viktigaste bidragsgivarna till den totala tiden. Nästa avsnitt går in på mer information om anatomin för ett inferensanrop för en stor språkmodell.
Bättre prestanda
Det finns flera faktorer som du kan styra för att förbättra svarstiden per anrop för ditt program.
Modellval
Svarstiden varierar beroende på vilken modell du använder. För en identisk begäran kan du förvänta dig att olika modeller har olika svarstider för samtalet om chattens slutförande. Om ditt användningsfall kräver de lägsta svarstidsmodellerna med de snabbaste svarstiderna rekommenderar vi den senaste MINI-modellen GPT-4o.
Generationsstorlek och Maxtoken
När du skickar en slutförandebegäran till Azure OpenAI-slutpunkten konverteras din indatatext till token som sedan skickas till din distribuerade modell. Modellen tar emot indatatoken och börjar sedan generera ett svar. Det är en iterativ sekventiell process, en token i taget. Ett annat sätt att tänka på det är som en for-loop med n tokens = n iterations. För de flesta modeller är det långsammaste steget i processen att generera svaret.
Vid tidpunkten för begäran används den begärda generationsstorleken (max_tokens parametern) som en första uppskattning av generationsstorleken. Beräkningstiden för att generera den fullständiga storleken reserveras av modellen när begäran bearbetas. När genereringen är klar frigörs den återstående kvoten. Sätt att minska antalet token:
- Ange parametern för
max_tokensvarje anrop så litet som möjligt. - Inkludera stoppsekvenser för att förhindra att extra innehåll genereras.
- Generera färre svar: Parametrarna best_of &n kan avsevärt öka svarstiden eftersom de genererar flera utdata. För det snabbaste svaret anger du antingen inte dessa värden eller anger dem till 1.
Sammanfattningsvis minskar en minskning av antalet token som genereras per begäran svarstiden för varje begäran.
Strömning
Inställningen stream: true i en begäran gör att tjänsten returnerar token så snart de är tillgängliga, i stället för att vänta på att hela sekvensen av token ska genereras. Det ändrar inte tiden för att hämta alla token, men det minskar tiden för första svaret. Den här metoden ger en bättre användarupplevelse eftersom slutanvändare kan läsa svaret när det genereras.
Strömning är också värdefullt med stora anrop som tar lång tid att bearbeta. Många klienter och mellanliggande lager har tidsgränser för enskilda anrop. Långa generationsanrop kan avbrytas på grund av tidsgränser på klientsidan. Genom att strömma tillbaka data kan du se till att inkrementella data tas emot.
Exempel på när du ska använda strömning:
Chattrobotar och konversationsgränssnitt.
Strömning påverkar upplevd svarstid. När strömning är aktiverat får du tillbaka token i segment så snart de är tillgängliga. För slutanvändare känns den här metoden ofta som att modellen svarar snabbare även om den totala tiden för att slutföra begäran förblir densamma.
Exempel på när strömning är mindre viktigt:
Attitydanalys, språköversättning, innehållsgenerering.
Det finns många användningsfall där du utför en massuppgift där du bara bryr dig om det färdiga resultatet, inte realtidssvaret. Om direktuppspelning är inaktiverat får du inga token förrän modellen har slutfört hela svaret.
Innehållsfiltrering
Azure OpenAI innehåller ett system för innehållsfiltrering som fungerar tillsammans med kärnmodellerna. Det här systemet fungerar genom att köra både prompten och slutförandet genom en uppsättning klassificeringsmodeller som syftar till att identifiera och förhindra utdata från skadligt innehåll.
Systemet för innehållsfiltrering identifierar och vidtar åtgärder för specifika kategorier av potentiellt skadligt innehåll i både inkommande prompter och slutföranden av utdata.
Tillägget av innehållsfiltrering medför en ökad säkerhet, men även svarstid. Det finns många program där den här kompromissen i prestanda är nödvändig, men det finns vissa användningsfall med lägre risk där det kan vara värt att inaktivera innehållsfiltren för att förbättra prestanda.
Läs mer om att begära ändringar av standardprinciperna för innehållsfiltrering.
Separation av arbetsbelastningar
Att blanda olika arbetsbelastningar på samma slutpunkt kan påverka svarstiden negativt. Detta beror på att (1) de batchas ihop under slutsatsdragningen och korta anrop kan vänta på längre slutföranden och (2) blandning av anropen kan minska din cacheträfffrekvens eftersom de båda konkurrerar om samma utrymme. När det är möjligt rekommenderar vi att du har separata distributioner för varje arbetsbelastning.
Fråga storlek
Även om promptens storlek har mindre inverkan på svarstiden än generationsstorleken påverkar det den totala tiden, särskilt när storleken växer sig stor.
Batchbearbetning
Om du skickar flera begäranden till samma slutpunkt kan du skicka begäranden till ett enda anrop. Detta minskar antalet begäranden som du behöver göra och beroende på scenariot kan det förbättra den totala svarstiden. Vi rekommenderar att du testar den här metoden för att se om den hjälper.
Så här mäter du dataflödet
Vi rekommenderar att du mäter ditt totala dataflöde för en distribution med två mått:
- Anrop per minut: Antalet API-slutsatsdragningsanrop som du gör per minut. Detta kan mätas i Azure-monitor med hjälp av måttet Azure OpenAI-begäranden och delas upp med ModelDeploymentName
- Totalt antal token per minut: Det totala antalet token som bearbetas per minut av distributionen. Detta inkluderar prompt- och genererade token. Detta delas ofta upp ytterligare i mätning av båda för en djupare förståelse av distributionsprestanda. Detta kan mätas i Azure-Monitor med hjälp av måttet För bearbetade slutsatsdragningstoken.
Du kan läsa mer om övervakning av Azure OpenAI-tjänsten.
Mäta svarstid per anrop
Hur lång tid det tar för varje anrop beror på hur lång tid det tar att läsa modellen, generera utdata och tillämpa innehållsfilter. Hur du mäter tiden varierar om du använder strömning eller inte. Vi föreslår en annan uppsättning mått för varje fall.
Du kan läsa mer om övervakning av Azure OpenAI-tjänsten.
Icke-direktuppspelning:
- Tid för begäran från slutpunkt till slutpunkt: Den totala tid det tar att generera hela svaret för icke-strömmande begäranden, mätt med API-gatewayen. Det här antalet ökar när prompten och generationsstorleken ökar.
Strömning:
- Tid till svar: Mått för rekommenderad svarstid (svarstid) för strömningsbegäranden. Gäller för PTU- och PTU-hanterade distributioner. Beräknas som den tid det tar för det första svaret att visas när en användare skickar en uppmaning, mätt med API-gatewayen. Det här antalet ökar när promptens storlek ökar och/eller träffstorleken minskar.
- Genomsnittlig tid för tokengenerering från den första token till den sista token, dividerat med antalet genererade token, mätt med API-gatewayen. Detta mäter svarsgenereringens hastighet och ökar när systembelastningen ökar. Rekommenderat svarstidsmått för strömningsbegäranden.
Sammanfattning
Modellfördröjning: Om modellsvarstiden är viktig för dig rekommenderar vi att du testar minimodellen GPT-4o.
Lägre maxtoken: OpenAI har upptäckt att även i fall där det totala antalet token som genereras liknar begäran med det högre värdet inställt för parametern max token får mer svarstid.
Lägre totalt antal token som genereras: Ju färre token som genereras desto snabbare blir det övergripande svaret. Kom ihåg att det här är som att ha en for-loop med
n tokens = n iterations. Minska antalet token som genereras och den totala svarstiden förbättras i enlighet med detta.Direktuppspelning: Aktivering av direktuppspelning kan vara användbart för att hantera användarnas förväntningar i vissa situationer genom att låta användaren se modellsvaret när det genereras i stället för att behöva vänta tills den sista token är klar.
Innehållsfiltrering förbättrar säkerheten, men det påverkar även svarstiden. Utvärdera om någon av dina arbetsbelastningar skulle ha nytta av ändrade principer för innehållsfiltrering.