Konfigurera innehållsfilter med Azure AI Foundry
Innehållsfiltreringssystemet som är integrerat i Azure AI Foundry körs tillsammans med kärnmodellerna, inklusive DALL-E-bildgenereringsmodeller. Den använder en ensemble av klassificeringsmodeller med flera klasser för att identifiera fyra kategorier av skadligt innehåll (våld, hat, sexuellt och självskadebeteende) på fyra allvarlighetsnivåer (säkra, låga, medelstora och höga) och valfria binära klassificerare för att upptäcka risk för jailbreak, befintlig text och kod i offentliga lagringsplatser.
Standardkonfigurationen för innehållsfiltrering är inställd på att filtrera med tröskelvärdet för medelhög allvarlighetsgrad för alla fyra kategorier av innehållsskador för både prompter och slutföranden. Det innebär att innehåll som identifieras på allvarlighetsgrad medel eller hög filtreras, medan innehåll som identifieras på allvarlighetsnivå låg eller säker inte filtreras av innehållsfiltren. Läs mer om innehållskategorier, allvarlighetsnivåer och beteendet för innehållsfiltreringssystemet här.
Riskidentifiering av jailbreak och skyddade text- och kodmodeller är valfria och aktiverade som standard. För jailbreak och skyddade materialtext- och kodmodeller gör konfigurationsfunktionen att alla kunder kan aktivera och inaktivera modellerna. Modellerna är som standard aktiverade och kan inaktiveras enligt ditt scenario. Vissa modeller måste vara på för att vissa scenarier ska kunna behålla täckningen under kundens upphovsrättsåtagande.
Kommentar
Alla kunder har möjlighet att ändra innehållsfiltren och konfigurera tröskelvärdena för allvarlighetsgrad (låg, medel, hög). Godkännande krävs för att stänga av innehållsfiltren helt eller delvis. Endast hanterade kunder kan ansöka om full kontroll över innehållsfiltrering via detta formulär: Granskning av begränsad åtkomst till Azure OpenAI: Ändrade innehållsfilter. För närvarande är det inte möjligt att bli en hanterad kund.
Innehållsfilter kan konfigureras på resursnivå. När en ny konfiguration har skapats kan den associeras med en eller flera distributioner. Mer information om distributionsmodellerna finns i Förstå distributionsmodeller.
Förutsättningar
- Du måste ha en Azure OpenAI-resurs och en distribution av en stor språkmodell (LLM) för att konfigurera innehållsfilter. Följ en snabbstart för att komma igång.
Förstå konfigurerbarhet för innehållsfilter
Azure OpenAI Service innehåller standardsäkerhetsinställningar som tillämpas på alla modeller, exklusive Azure OpenAI Whisper. De här konfigurationerna ger dig en ansvarsfull upplevelse som standard, inklusive modeller för innehållsfiltrering, blocklistor, prompttransformering, autentiseringsuppgifter för innehåll och andra. Läs mer om det här.
Alla kunder kan också konfigurera innehållsfilter och skapa anpassade säkerhetsprinciper som är skräddarsydda för deras användningsfallskrav. Med konfigurationsfunktionen kan kunderna justera inställningarna separat för frågor och slutföranden för att filtrera innehåll för varje innehållskategori på olika allvarlighetsnivåer enligt beskrivningen i tabellen nedan. Innehåll som identifieras på allvarlighetsnivå "säker" är märkt i anteckningar men är inte föremål för filtrering och kan inte konfigureras.
| Allvarlighetsgrad filtrerad | Kan konfigureras för frågor | Kan konfigureras för slutföranden | Beskrivningar |
|---|---|---|---|
| Låg, medelhög, hög | Ja | Ja | Striktast filtreringskonfiguration. Innehåll som identifieras på allvarlighetsgraderna låg, medelhög och hög filtreras. |
| Medelhög, hög | Ja | Ja | Innehåll som identifieras på allvarlighetsnivå låg filtreras inte, innehåll på medelhög och hög filtreras. |
| Högt | Ja | Ja | Innehåll som identifieras på allvarlighetsgraderna låg och medel filtreras inte. Endast innehåll på hög allvarlighetsgrad filtreras. |
| Inga filter | Om godkänd1 | Om godkänd1 | Inget innehåll filtreras oavsett allvarlighetsgrad som identifierats. Kräver godkännande1. |
| Kommentera endast | Om godkänd1 | Om godkänd1 | Inaktiverar filterfunktionen, så innehållet blockeras inte, men anteckningar returneras via API-svar. Kräver godkännande1. |
1 För Azure OpenAI-modeller har endast kunder som har godkänts för modifierad innehållsfiltrering fullständig innehållsfiltreringskontroll och kan inaktivera innehållsfilter. Ansök om ändrade innehållsfilter via det här formuläret: Azure OpenAI Limited Access Review: Modified Content Filters (Begränsad åtkomstgranskning i Azure OpenAI: Ändrade innehållsfilter). För Azure Government-kunder kan du ansöka om ändrade innehållsfilter via det här formuläret: Azure Government – Begära ändrad innehållsfiltrering för Azure OpenAI-tjänsten.
Konfigurerbara innehållsfilter för indata (prompter) och utdata (slutföranden) är tillgängliga för alla Azure OpenAI-modeller.
Konfigurationer för innehållsfiltrering skapas i en resurs i Azure AI Foundry-portalen och kan associeras med distributioner. Läs mer om konfigurerbarhet här.
Kunderna ansvarar för att säkerställa att program som integrerar Azure OpenAI följer uppförandekoden.
Förstå andra filter
Du kan konfigurera följande filterkategorier utöver standardfilter för skadekategorier.
| Filterkategori | Status | Standardinställning | Tillämpas på fråga eller slutförande? | beskrivning |
|---|---|---|---|---|
| Fråga sköldar för direkta attacker (jailbreak) | Allmän tillgänglighet | På | Användarprompt | Filtrerar/kommenterar användarfrågor som kan utgöra en jailbreak-risk. Mer information om anteckningar finns i Azure AI Foundry-innehållsfiltrering. |
| Fråga sköldar för indirekta attacker | Allmän tillgänglighet | Av | Användarprompt | Filtrera/kommentera indirekta attacker, även kallade indirekta promptattacker eller direktinmatningsattacker mellan domäner, en potentiell sårbarhet där tredje part placerar skadliga instruktioner i dokument som det generativa AI-systemet kan komma åt och bearbeta. Kräver: Inbäddning och formatering av dokument. |
| Skyddat material – kod | Allmän tillgänglighet | På | Fullbordande | Filtrerar skyddad kod eller hämtar exempelinformation om källhänvisning och licens i anteckningar för kodfragment som matchar offentliga kodkällor som drivs av GitHub Copilot. Mer information om att använda anteckningar finns i konceptguiden för innehållsfiltrering |
| Skyddat material – text | Allmän tillgänglighet | På | Fullbordande | Identifierar och blockerar känt textinnehåll från att visas i modellutdata (till exempel låttexter, recept och valt webbinnehåll). |
| Grundstötning* | Förhandsversion | Av | Fullbordande | Identifierar om textsvaren från stora språkmodeller (LLM) är baserade på källmaterialet som tillhandahålls av användarna. Ogrundadhet avser instanser där llm:erna producerar information som inte är faktisk eller felaktig från det som fanns i källmaterialet. Kräver: Inbäddning och formatering av dokument. |
Skapa ett innehållsfilter i Azure AI Foundry
För alla modelldistributioner i Azure AI Foundry kan du använda standardinnehållsfiltret direkt, men du kanske vill ha mer kontroll. Du kan till exempel göra ett filter striktare eller mer överseende, eller aktivera mer avancerade funktioner som promptsköldar och skyddad materialidentifiering.
Dricks
Mer information om innehållsfilter i ditt Azure AI Foundry-projekt finns i Innehållsfiltrering i Azure AI Foundry.
Följ dessa steg för att skapa ett innehållsfilter:
Gå till Azure AI Foundry och gå till projektet. Välj sedan sidan Säkerhet + säkerhet på den vänstra menyn och välj fliken Innehållsfilter .
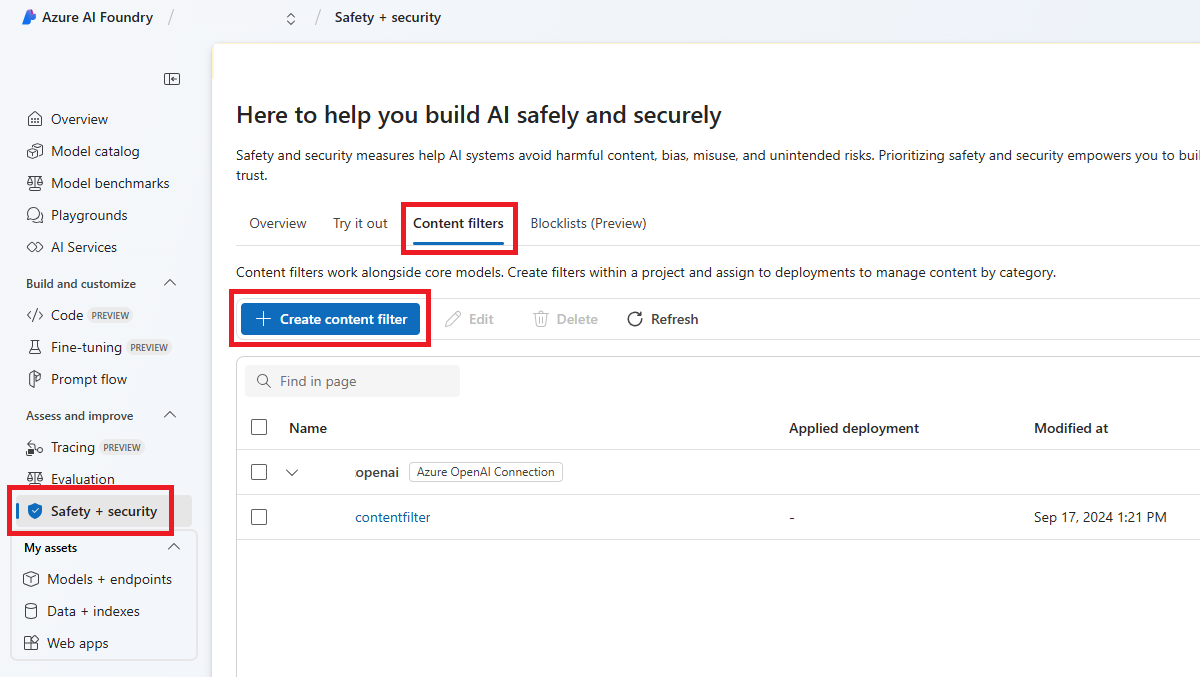
Välj + Skapa innehållsfilter.
På sidan Grundläggande information anger du ett namn för konfigurationen för innehållsfiltrering. Välj en anslutning som ska associeras med innehållsfiltret. Välj sedan Nästa.
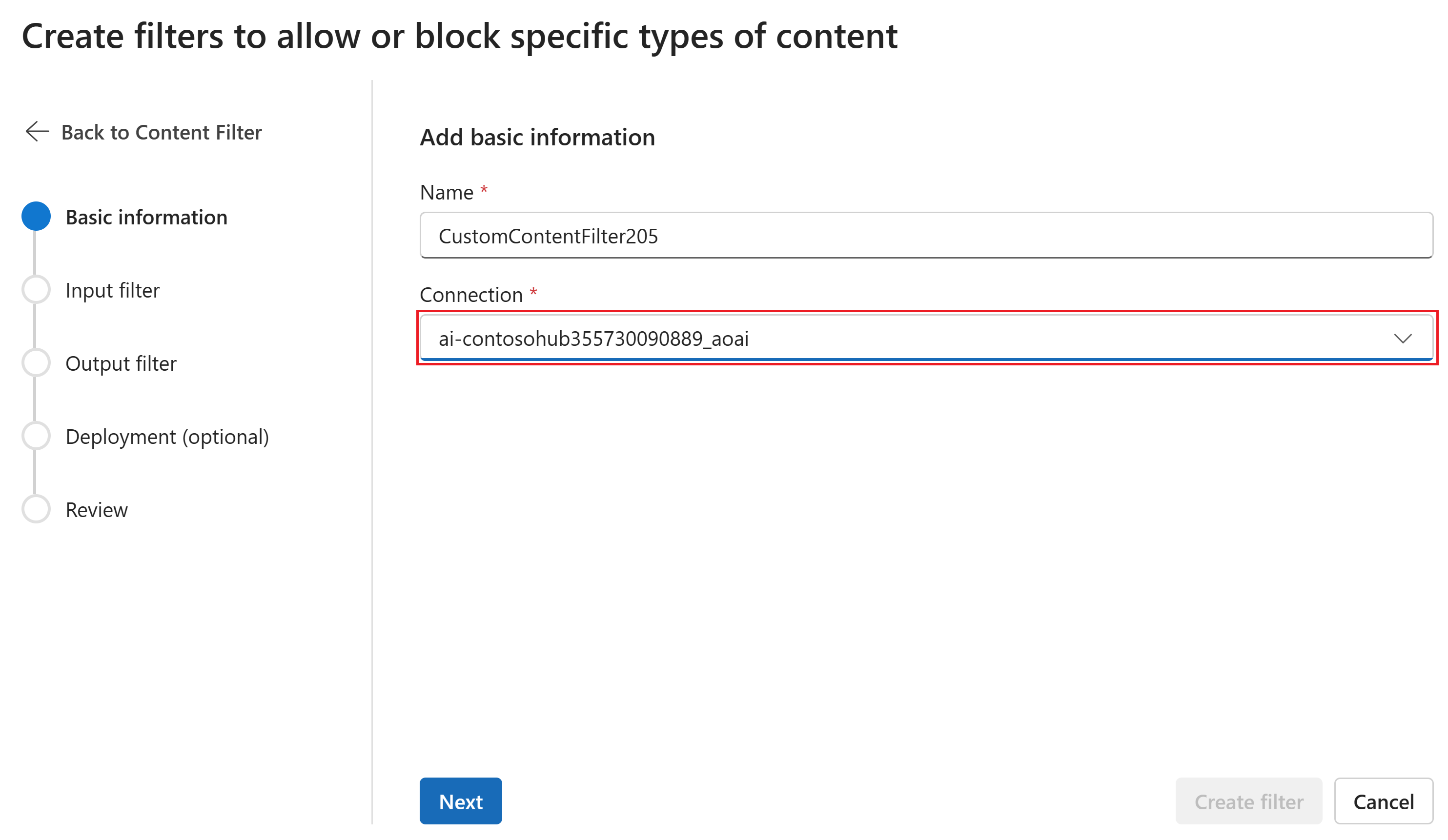
Nu kan du konfigurera indatafilter (för användarfrågor) och utdatafilter (för modellavslut).
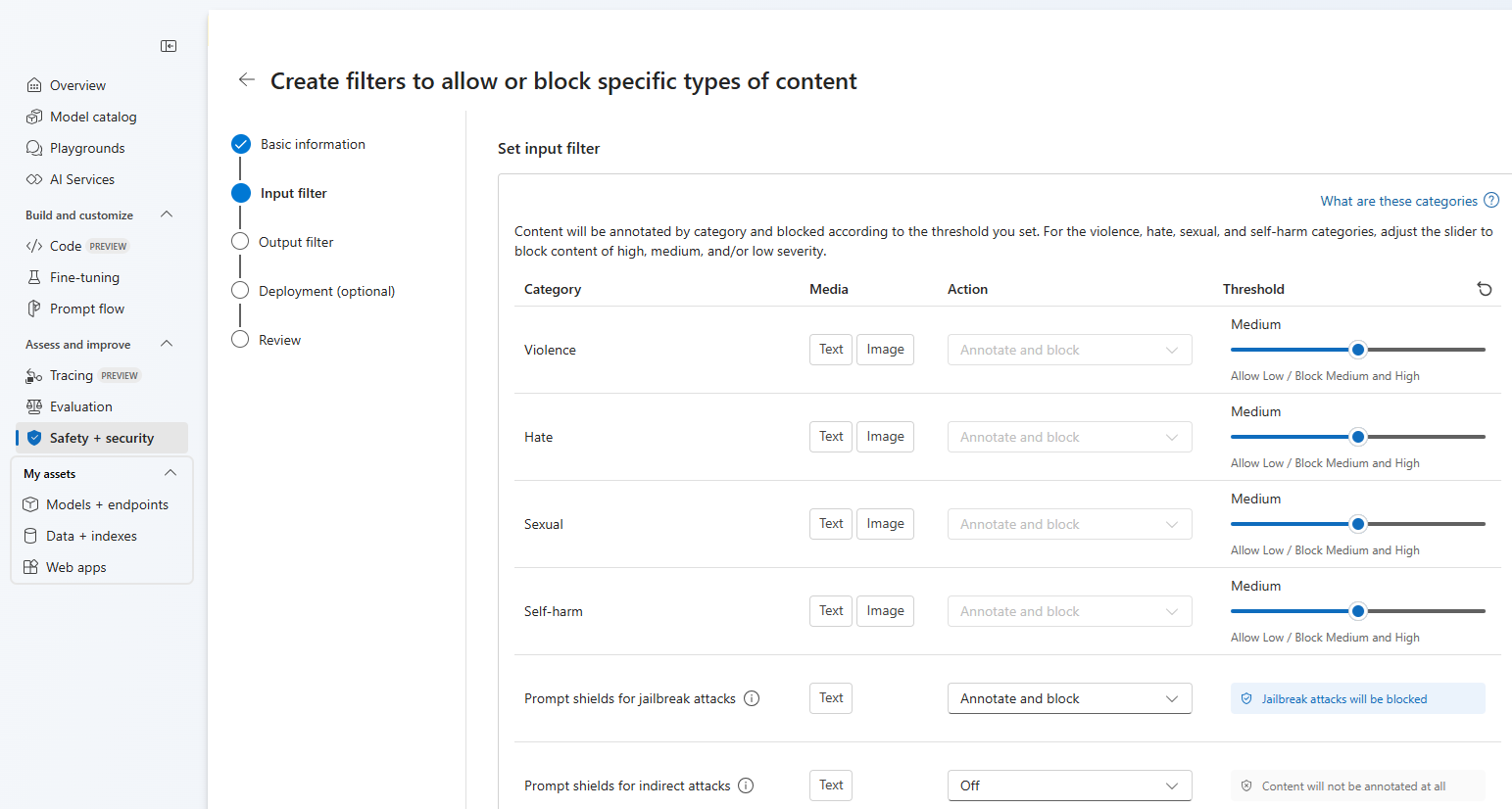
På sidan Indatafilter kan du ange filtret för indataprompten. För de första fyra innehållskategorierna finns det tre allvarlighetsnivåer som kan konfigureras: Låg, medel och hög. Du kan använda skjutreglagen för att ange tröskelvärdet för allvarlighetsgrad om du fastställer att ditt program eller användningsscenario kräver en annan filtrering än standardvärdena. Vissa filter, till exempel Prompt Shields och Skyddad materialidentifiering, gör att du kan avgöra om modellen ska kommentera och/eller blockera innehåll. Om du väljer Kommentera körs endast respektive modell och returnerar anteckningar via API-svar, men det filtrerar inte innehåll. Förutom att kommentera kan du också välja att blockera innehåll.
Om ditt användningsfall har godkänts för ändrade innehållsfilter får du fullständig kontroll över konfigurationer för innehållsfiltrering och kan välja att helt eller delvis inaktivera filtrering eller endast aktivera anteckningar för kategorierna för innehållsskador (våld, hat, sexuell och självskada).
Innehållet kommenteras efter kategori och blockeras enligt det tröskelvärde som du anger. För kategorierna våld, hat, sexuell och självskadebeteende justerar du skjutreglaget för att blockera innehåll av hög, medel eller låg allvarlighetsgrad.
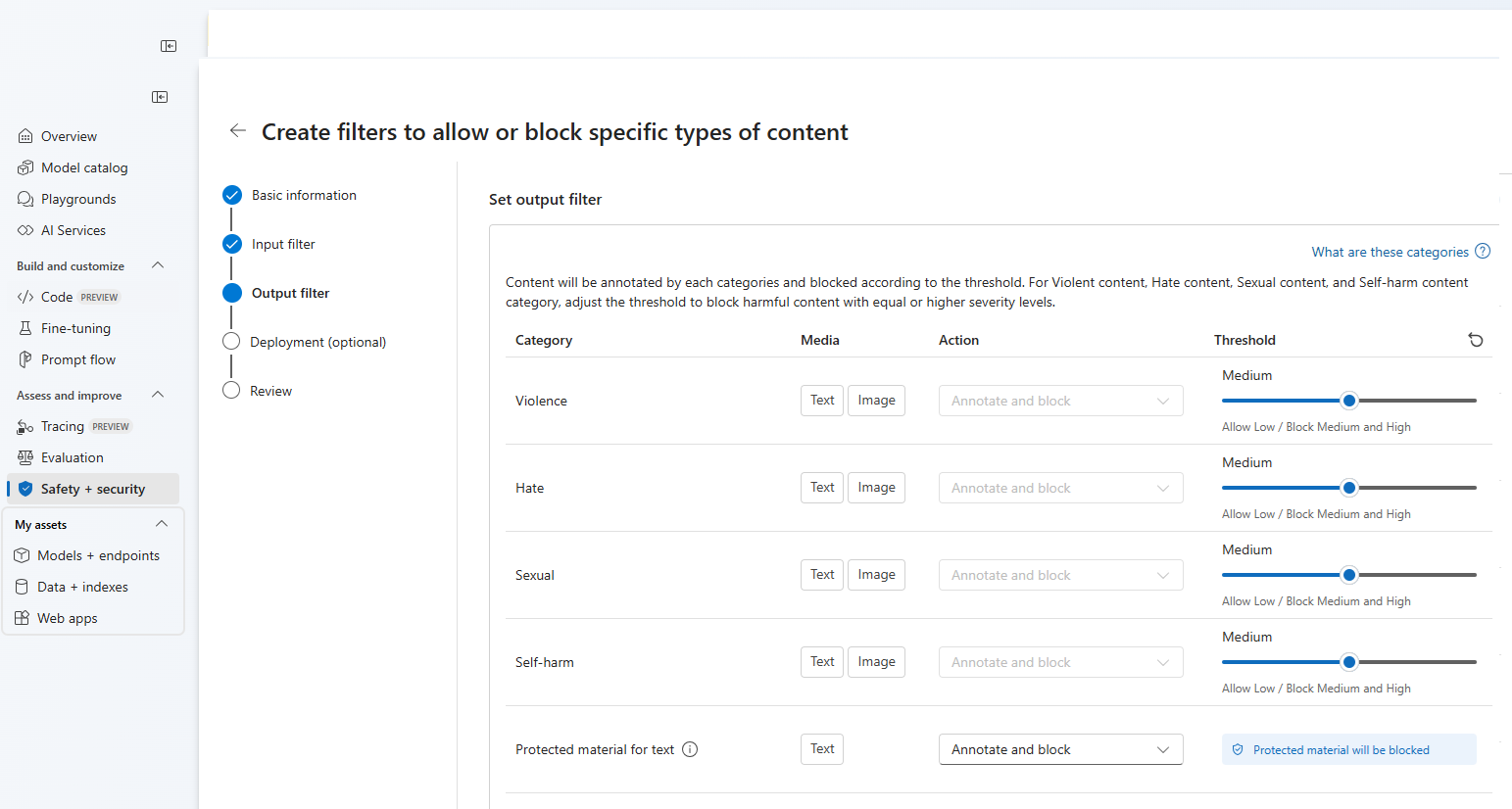
På sidan Utdatafilter kan du konfigurera utdatafiltret, som ska tillämpas på allt utdatainnehåll som genereras av din modell. Konfigurera de enskilda filtren som tidigare. Den här sidan innehåller också alternativet Strömningsläge, vilket gör att du kan filtrera innehåll nästan i realtid eftersom det genereras av modellen, vilket minskar svarstiden. När du är klar väljer du Nästa.
Innehållet kommenteras av varje kategori och blockeras enligt tröskelvärdet. För våldsamt innehåll, hatinnehåll, sexuellt innehåll och självskadebeteende, justerar du tröskelvärdet för att blockera skadligt innehåll med samma eller högre allvarlighetsgrad.
På sidan Distribution kan du också associera innehållsfiltret med en distribution. Om en vald distribution redan har ett filter kopplat måste du bekräfta att du vill ersätta den. Du kan också associera innehållsfiltret med en distribution senare. Välj Skapa.
Konfigurationer för innehållsfiltrering skapas på hubbnivå i Azure AI Foundry-portalen. Läs mer om konfigurerbarhet i Azure OpenAI Service-dokumentationen.
På sidan Granska granskar du inställningarna och väljer sedan Skapa filter.



Använda en blockeringslista som ett filter
Du kan använda en blocklista som antingen ett indata- eller utdatafilter eller båda. Aktivera alternativet Blocklist på sidan Indatafilter och/eller Utdatafilter. Välj en eller flera blocklistor i listrutan eller använd den inbyggda listan med olämpligt språk. Du kan kombinera flera blocklistor i samma filter.
Använda ett innehållsfilter
Processen för att skapa filter ger dig möjlighet att tillämpa filtret på de distributioner du vill använda. Du kan också ändra eller ta bort innehållsfilter från dina distributioner när som helst.
Följ dessa steg för att tillämpa ett innehållsfilter på en distribution:
Gå till Azure AI Foundry och välj ett projekt.
Välj Modeller + slutpunkter i det vänstra fönstret och välj en av dina distributioner och välj sedan Redigera.

I fönstret Uppdateringsdistribution väljer du det innehållsfilter som du vill använda för distributionen. Välj sedan Spara och stäng.

Du kan också redigera och ta bort en konfiguration av innehållsfilter om det behövs. Innan du tar bort en konfiguration för innehållsfiltrering måste du ta bort tilldelningen och ersätta den från alla distributioner på fliken Distributioner .


Nu kan du gå till lekplatsen för att testa om innehållsfiltret fungerar som förväntat.
Feedback om filtrering av rapportinnehåll
Om du stöter på ett problem med innehållsfiltrering väljer du knappen Filterfeedback överst på lekplatsen. Detta aktiveras i lekplatsen Bilder, Chatt och Slutföranden när du skickar en uppmaning.
När dialogrutan visas väljer du lämpligt problem med innehållsfiltrering. Ta med så mycket information som möjligt om ditt problem med innehållsfiltrering, till exempel det specifika prompt- och innehållsfiltreringsfel som du stötte på. Ta inte med någon privat eller känslig information.
Om du vill ha support skickar du ett supportärende.
Följ metodtipsen
Vi rekommenderar att du informerar dina beslut om innehållsfiltrering genom en iterativ identifiering (till exempel red team-testning, stresstestning och analys) och mätningsprocess för att åtgärda potentiella skador som är relevanta för en specifik modell, ett visst program och distributionsscenario. När du har implementerat åtgärder som innehållsfiltrering upprepar du mätningen för att testa effektiviteten. Rekommendationer och metodtips för ansvarsfull AI för Azure OpenAI, som finns i Microsoft Responsible AI Standard, finns i Översikt över ansvarsfull AI för Azure OpenAI.
Relaterat innehåll
- Läs mer om ansvarsfulla AI-metoder för Azure OpenAI: Översikt över ansvarsfulla AI-metoder för Azure OpenAI-modeller.
- Läs mer om innehållsfiltreringskategorier och allvarlighetsnivåer med Azure AI Foundry.
- Läs mer om röd teamindelning från vår artikel: Introduktion till red teaming large language models (LLMs).