Så här genererar du inbäddningar med Azure AI-modellinferens
Viktigt!
Objekt markerade (förhandsversion) i den här artikeln är för närvarande i offentlig förhandsversion. Den här förhandsversionen tillhandahålls utan ett serviceavtal och vi rekommenderar det inte för produktionsarbetsbelastningar. Vissa funktioner kanske inte stöds eller kan vara begränsade. Mer information finns i Kompletterande villkor för användning av Microsoft Azure-förhandsversioner.
Den här artikeln beskriver hur du använder API för inbäddning med modeller som distribueras till Azure AI-modellinferens i Azure AI-tjänster.
Förutsättningar
Om du vill använda inbäddningsmodeller i ditt program behöver du:
En Azure-prenumeration Om du använder GitHub-modeller kan du uppgradera din upplevelse och skapa en Azure-prenumeration i processen. Läs Uppgradera från GitHub-modeller till Azure AI-modellinferens om så är fallet.
En Azure AI-tjänstresurs. Mer information finns i Skapa en Azure AI Services-resurs.
Slutpunkts-URL:en och nyckeln.
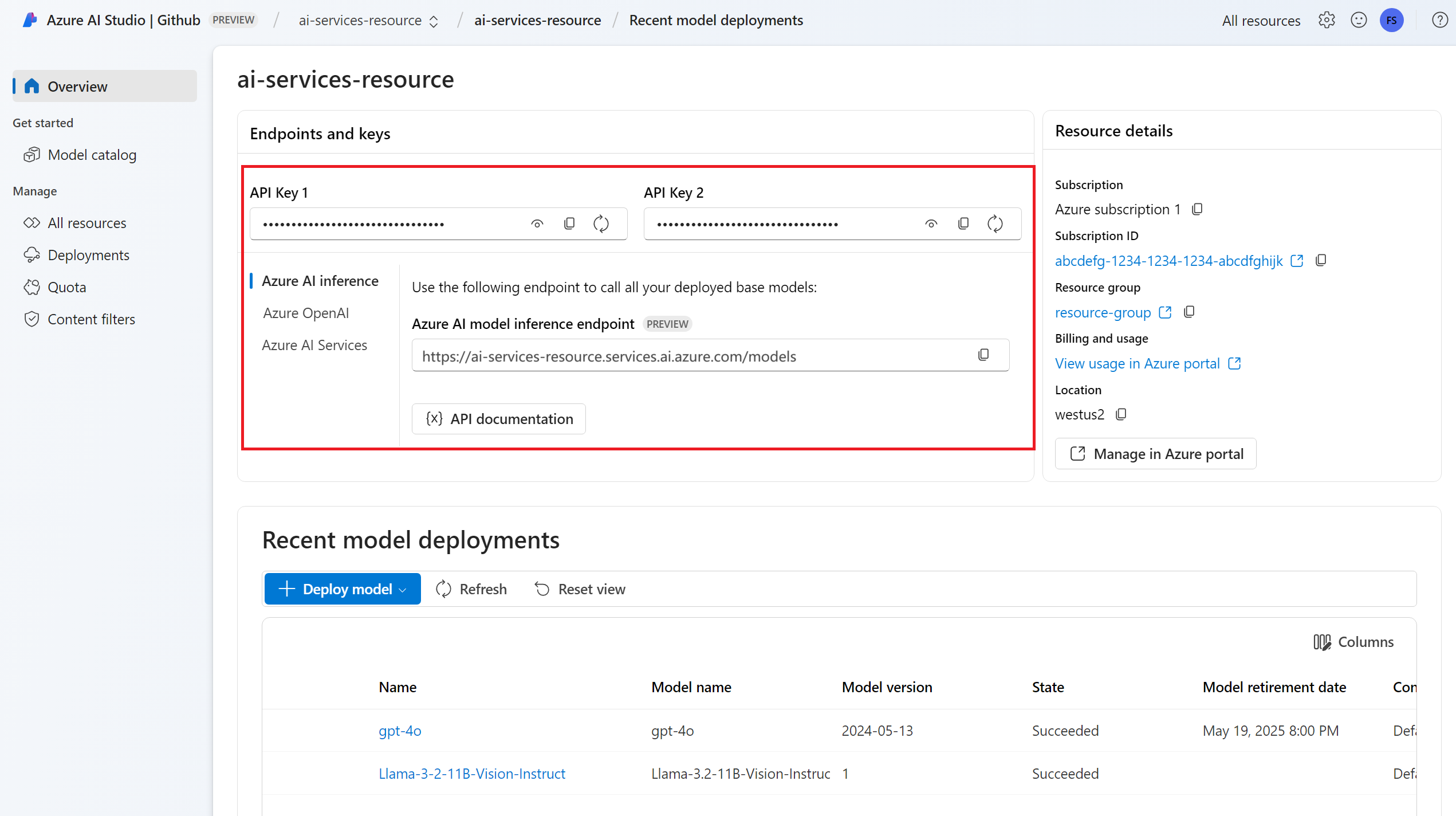

En inbäddningsmodelldistribution. Om du inte har någon läser du Lägg till och konfigurera modeller i Azure AI-tjänster för att lägga till en inbäddningsmodell i resursen.
Installera Azure AI-slutsatsdragningspaketet med följande kommando:
pip install -U azure-ai-inferenceDricks
Läs mer om Azure AI-slutsatsdragningspaketet och referensen.
Använda inbäddningar
Skapa först klienten för att använda modellen. I följande kod används en slutpunkts-URL och nyckel som lagras i miljövariabler.
import os
from azure.ai.inference import EmbeddingsClient
from azure.core.credentials import AzureKeyCredential
model = EmbeddingsClient(
endpoint=os.environ["AZURE_INFERENCE_ENDPOINT"],
credential=AzureKeyCredential(os.environ["AZURE_INFERENCE_CREDENTIAL"]),
model="text-embedding-3-small"
)
Om du har konfigurerat resursen till med Stöd för Microsoft Entra-ID kan du använda följande kodfragment för att skapa en klient.
import os
from azure.ai.inference import EmbeddingsClient
from azure.core.credentials import AzureKeyCredential
model = EmbeddingsClient(
endpoint=os.environ["AZURE_INFERENCE_ENDPOINT"],
credential=DefaultAzureCredential(),
model="text-embedding-3-small"
)
Skapa inbäddningar
Skapa en inbäddningsbegäran för att se modellens utdata.
response = model.embed(
input=["The ultimate answer to the question of life"],
)
Dricks
När du skapar en begäran tar du hänsyn till tokens indatagräns för modellen. Om du behöver bädda in större delar av text behöver du en segmenteringsstrategi.
Svaret är följande, där du kan se modellens användningsstatistik:
import numpy as np
for embed in response.data:
print("Embeding of size:", np.asarray(embed.embedding).shape)
print("Model:", response.model)
print("Usage:", response.usage)
Det kan vara användbart att beräkna inbäddningar i indatabatch. Parametern inputs kan vara en lista över strängar, där varje sträng är olika indata. Svaret är i sin tur en lista över inbäddningar, där varje inbäddning motsvarar indata i samma position.
response = model.embed(
input=[
"The ultimate answer to the question of life",
"The largest planet in our solar system is Jupiter",
],
)
Svaret är följande, där du kan se modellens användningsstatistik:
import numpy as np
for embed in response.data:
print("Embeding of size:", np.asarray(embed.embedding).shape)
print("Model:", response.model)
print("Usage:", response.usage)
Dricks
När du skapar batchar med begäran tar du hänsyn till batchgränsen för var och en av modellerna. De flesta modeller har en batchgräns på 1 024.
Ange inbäddningsdimensioner
Du kan ange antalet dimensioner för inbäddningarna. Följande exempelkod visar hur du skapar inbäddningar med 1 024 dimensioner. Observera att inte alla inbäddningsmodeller har stöd för att ange antalet dimensioner i begäran och i dessa fall returneras ett 422-fel.
response = model.embed(
input=["The ultimate answer to the question of life"],
dimensions=1024,
)
Skapa olika typer av inbäddningar
Vissa modeller kan generera flera inbäddningar för samma indata beroende på hur du planerar att använda dem. Med den här funktionen kan du hämta mer exakta inbäddningar för RAG-mönster.
I följande exempel visas hur du skapar inbäddningar som används för att skapa en inbäddning för ett dokument som ska lagras i en vektordatabas:
from azure.ai.inference.models import EmbeddingInputType
response = model.embed(
input=["The answer to the ultimate question of life, the universe, and everything is 42"],
input_type=EmbeddingInputType.DOCUMENT,
)
När du arbetar med en fråga för att hämta ett sådant dokument kan du använda följande kodfragment för att skapa inbäddningarna för frågan och maximera hämtningsprestandan.
from azure.ai.inference.models import EmbeddingInputType
response = model.embed(
input=["What's the ultimate meaning of life?"],
input_type=EmbeddingInputType.QUERY,
)
Observera att inte alla inbäddningsmodeller stöder indatatypen i begäran och i dessa fall returneras ett 422-fel. Som standard returneras inbäddningar av typen Text .
Viktigt!
Objekt markerade (förhandsversion) i den här artikeln är för närvarande i offentlig förhandsversion. Den här förhandsversionen tillhandahålls utan ett serviceavtal och vi rekommenderar det inte för produktionsarbetsbelastningar. Vissa funktioner kanske inte stöds eller kan vara begränsade. Mer information finns i Kompletterande villkor för användning av Microsoft Azure-förhandsversioner.
Den här artikeln beskriver hur du använder API för inbäddning med modeller som distribueras till Azure AI-modellinferens i Azure AI-tjänster.
Förutsättningar
Om du vill använda inbäddningsmodeller i ditt program behöver du:
En Azure-prenumeration Om du använder GitHub-modeller kan du uppgradera din upplevelse och skapa en Azure-prenumeration i processen. Läs Uppgradera från GitHub-modeller till Azure AI-modellinferens om så är fallet.
En Azure AI-tjänstresurs. Mer information finns i Skapa en Azure AI Services-resurs.
Slutpunkts-URL:en och nyckeln.
En inbäddningsmodelldistribution. Om du inte har någon läser du Lägg till och konfigurera modeller i Azure AI-tjänster för att lägga till en inbäddningsmodell i resursen.
Installera Azure Inference-biblioteket för JavaScript med följande kommando:
npm install @azure-rest/ai-inferenceDricks
Läs mer om Azure AI-slutsatsdragningspaketet och referensen.
Använda inbäddningar
Skapa först klienten för att använda modellen. I följande kod används en slutpunkts-URL och nyckel som lagras i miljövariabler.
import ModelClient from "@azure-rest/ai-inference";
import { isUnexpected } from "@azure-rest/ai-inference";
import { AzureKeyCredential } from "@azure/core-auth";
const client = new ModelClient(
process.env.AZURE_INFERENCE_ENDPOINT,
new AzureKeyCredential(process.env.AZURE_INFERENCE_CREDENTIAL),
"text-embedding-3-small"
);
Om du har konfigurerat resursen till med Stöd för Microsoft Entra-ID kan du använda följande kodfragment för att skapa en klient.
import ModelClient from "@azure-rest/ai-inference";
import { isUnexpected } from "@azure-rest/ai-inference";
import { DefaultAzureCredential } from "@azure/identity";
const client = new ModelClient(
process.env.AZURE_INFERENCE_ENDPOINT,
new DefaultAzureCredential(),
"text-embedding-3-small"
);
Skapa inbäddningar
Skapa en inbäddningsbegäran för att se modellens utdata.
var response = await client.path("/embeddings").post({
body: {
input: ["The ultimate answer to the question of life"],
}
});
Dricks
När du skapar en begäran tar du hänsyn till tokens indatagräns för modellen. Om du behöver bädda in större delar av text behöver du en segmenteringsstrategi.
Svaret är följande, där du kan se modellens användningsstatistik:
if (isUnexpected(response)) {
throw response.body.error;
}
console.log(response.embedding);
console.log(response.body.model);
console.log(response.body.usage);
Det kan vara användbart att beräkna inbäddningar i indatabatch. Parametern inputs kan vara en lista över strängar, där varje sträng är olika indata. Svaret är i sin tur en lista över inbäddningar, där varje inbäddning motsvarar indata i samma position.
var response = await client.path("/embeddings").post({
body: {
input: [
"The ultimate answer to the question of life",
"The largest planet in our solar system is Jupiter",
],
}
});
Svaret är följande, där du kan se modellens användningsstatistik:
if (isUnexpected(response)) {
throw response.body.error;
}
console.log(response.embedding);
console.log(response.body.model);
console.log(response.body.usage);
Dricks
När du skapar batchar med begäran tar du hänsyn till batchgränsen för var och en av modellerna. De flesta modeller har en batchgräns på 1 024.
Ange inbäddningsdimensioner
Du kan ange antalet dimensioner för inbäddningarna. Följande exempelkod visar hur du skapar inbäddningar med 1 024 dimensioner. Observera att inte alla inbäddningsmodeller har stöd för att ange antalet dimensioner i begäran och i dessa fall returneras ett 422-fel.
var response = await client.path("/embeddings").post({
body: {
input: ["The ultimate answer to the question of life"],
dimensions: 1024,
}
});
Skapa olika typer av inbäddningar
Vissa modeller kan generera flera inbäddningar för samma indata beroende på hur du planerar att använda dem. Med den här funktionen kan du hämta mer exakta inbäddningar för RAG-mönster.
I följande exempel visas hur du skapar inbäddningar som används för att skapa en inbäddning för ett dokument som ska lagras i en vektordatabas:
var response = await client.path("/embeddings").post({
body: {
input: ["The answer to the ultimate question of life, the universe, and everything is 42"],
input_type: "document",
}
});
När du arbetar med en fråga för att hämta ett sådant dokument kan du använda följande kodfragment för att skapa inbäddningarna för frågan och maximera hämtningsprestandan.
var response = await client.path("/embeddings").post({
body: {
input: ["What's the ultimate meaning of life?"],
input_type: "query",
}
});
Observera att inte alla inbäddningsmodeller stöder indatatypen i begäran och i dessa fall returneras ett 422-fel. Som standard returneras inbäddningar av typen Text .
Viktigt!
Objekt markerade (förhandsversion) i den här artikeln är för närvarande i offentlig förhandsversion. Den här förhandsversionen tillhandahålls utan ett serviceavtal och vi rekommenderar det inte för produktionsarbetsbelastningar. Vissa funktioner kanske inte stöds eller kan vara begränsade. Mer information finns i Kompletterande villkor för användning av Microsoft Azure-förhandsversioner.
Den här artikeln beskriver hur du använder API för inbäddning med modeller som distribueras till Azure AI-modellinferens i Azure AI-tjänster.
Förutsättningar
Om du vill använda inbäddningsmodeller i ditt program behöver du:
En Azure-prenumeration Om du använder GitHub-modeller kan du uppgradera din upplevelse och skapa en Azure-prenumeration i processen. Läs Uppgradera från GitHub-modeller till Azure AI-modellinferens om så är fallet.
En Azure AI-tjänstresurs. Mer information finns i Skapa en Azure AI Services-resurs.
Slutpunkts-URL:en och nyckeln.
En inbäddningsmodelldistribution. Om du inte har någon läser du Lägg till och konfigurera modeller i Azure AI-tjänster för att lägga till en inbäddningsmodell i resursen.
Lägg till Azure AI-slutsatsdragningspaketet i projektet:
<dependency> <groupId>com.azure</groupId> <artifactId>azure-ai-inference</artifactId> <version>1.0.0-beta.1</version> </dependency>Dricks
Läs mer om Azure AI-slutsatsdragningspaketet och referensen.
Om du använder Entra-ID behöver du också följande paket:
<dependency> <groupId>com.azure</groupId> <artifactId>azure-identity</artifactId> <version>1.13.3</version> </dependency>Importera följande namnområde:
package com.azure.ai.inference.usage; import com.azure.ai.inference.EmbeddingsClient; import com.azure.ai.inference.EmbeddingsClientBuilder; import com.azure.ai.inference.models.EmbeddingsResult; import com.azure.ai.inference.models.EmbeddingItem; import com.azure.core.credential.AzureKeyCredential; import com.azure.core.util.Configuration; import java.util.ArrayList; import java.util.List;
Använda inbäddningar
Skapa först klienten för att använda modellen. I följande kod används en slutpunkts-URL och nyckel som lagras i miljövariabler.
EmbeddingsClient client = new EmbeddingsClient(
URI.create(System.getProperty("AZURE_INFERENCE_ENDPOINT")),
new AzureKeyCredential(System.getProperty("AZURE_INFERENCE_CREDENTIAL")),
"text-embedding-3-small"
);
Om du har konfigurerat resursen till med Stöd för Microsoft Entra-ID kan du använda följande kodfragment för att skapa en klient.
client = new EmbeddingsClient(
URI.create(System.getProperty("AZURE_INFERENCE_ENDPOINT")),
new DefaultAzureCredential(),
"text-embedding-3-small"
);
Skapa inbäddningar
Skapa en inbäddningsbegäran för att se modellens utdata.
EmbeddingsOptions requestOptions = new EmbeddingsOptions()
.setInput(Arrays.asList("The ultimate answer to the question of life"));
Response<EmbeddingsResult> response = client.embed(requestOptions);
Dricks
När du skapar en begäran tar du hänsyn till tokens indatagräns för modellen. Om du behöver bädda in större delar av text behöver du en segmenteringsstrategi.
Svaret är följande, där du kan se modellens användningsstatistik:
System.out.println("Embedding: " + response.getValue().getData());
System.out.println("Model: " + response.getValue().getModel());
System.out.println("Usage:");
System.out.println("\tPrompt tokens: " + response.getValue().getUsage().getPromptTokens());
System.out.println("\tTotal tokens: " + response.getValue().getUsage().getTotalTokens());
Det kan vara användbart att beräkna inbäddningar i indatabatch. Parametern inputs kan vara en lista över strängar, där varje sträng är olika indata. Svaret är i sin tur en lista över inbäddningar, där varje inbäddning motsvarar indata i samma position.
requestOptions = new EmbeddingsOptions()
.setInput(Arrays.asList(
"The ultimate answer to the question of life",
"The largest planet in our solar system is Jupiter"
));
response = client.embed(requestOptions);
Svaret är följande, där du kan se modellens användningsstatistik:
Dricks
När du skapar batchar med begäran tar du hänsyn till batchgränsen för var och en av modellerna. De flesta modeller har en batchgräns på 1 024.
Ange inbäddningsdimensioner
Du kan ange antalet dimensioner för inbäddningarna. Följande exempelkod visar hur du skapar inbäddningar med 1 024 dimensioner. Observera att inte alla inbäddningsmodeller har stöd för att ange antalet dimensioner i begäran och i dessa fall returneras ett 422-fel.
Skapa olika typer av inbäddningar
Vissa modeller kan generera flera inbäddningar för samma indata beroende på hur du planerar att använda dem. Med den här funktionen kan du hämta mer exakta inbäddningar för RAG-mönster.
I följande exempel visas hur du skapar inbäddningar som används för att skapa en inbäddning för ett dokument som ska lagras i en vektordatabas:
List<String> input = Arrays.asList("The answer to the ultimate question of life, the universe, and everything is 42");
requestOptions = new EmbeddingsOptions(input, EmbeddingInputType.DOCUMENT);
response = client.embed(requestOptions);
När du arbetar med en fråga för att hämta ett sådant dokument kan du använda följande kodfragment för att skapa inbäddningarna för frågan och maximera hämtningsprestandan.
input = Arrays.asList("What's the ultimate meaning of life?");
requestOptions = new EmbeddingsOptions(input, EmbeddingInputType.QUERY);
response = client.embed(requestOptions);
Observera att inte alla inbäddningsmodeller stöder indatatypen i begäran och i dessa fall returneras ett 422-fel. Som standard returneras inbäddningar av typen Text .
Viktigt!
Objekt markerade (förhandsversion) i den här artikeln är för närvarande i offentlig förhandsversion. Den här förhandsversionen tillhandahålls utan ett serviceavtal och vi rekommenderar det inte för produktionsarbetsbelastningar. Vissa funktioner kanske inte stöds eller kan vara begränsade. Mer information finns i Kompletterande villkor för användning av Microsoft Azure-förhandsversioner.
Den här artikeln beskriver hur du använder API för inbäddning med modeller som distribueras till Azure AI-modellinferens i Azure AI-tjänster.
Förutsättningar
Om du vill använda inbäddningsmodeller i ditt program behöver du:
En Azure-prenumeration Om du använder GitHub-modeller kan du uppgradera din upplevelse och skapa en Azure-prenumeration i processen. Läs Uppgradera från GitHub-modeller till Azure AI-modellinferens om så är fallet.
En Azure AI-tjänstresurs. Mer information finns i Skapa en Azure AI Services-resurs.
Slutpunkts-URL:en och nyckeln.
En inbäddningsmodelldistribution. Om du inte har någon läser du Lägg till och konfigurera modeller i Azure AI-tjänster för att lägga till en inbäddningsmodell i resursen.
Installera Azure AI-slutsatsdragningspaketet med följande kommando:
dotnet add package Azure.AI.Inference --prereleaseDricks
Läs mer om Azure AI-slutsatsdragningspaketet och referensen.
Om du använder Entra-ID behöver du också följande paket:
dotnet add package Azure.Identity
Använda inbäddningar
Skapa först klienten för att använda modellen. I följande kod används en slutpunkts-URL och nyckel som lagras i miljövariabler.
EmbeddingsClient client = new EmbeddingsClient(
new Uri(Environment.GetEnvironmentVariable("AZURE_INFERENCE_ENDPOINT")),
new AzureKeyCredential(Environment.GetEnvironmentVariable("AZURE_INFERENCE_CREDENTIAL")),
"text-embedding-3-small"
);
Om du har konfigurerat resursen till med Stöd för Microsoft Entra-ID kan du använda följande kodfragment för att skapa en klient.
client = new EmbeddingsClient(
new Uri(Environment.GetEnvironmentVariable("AZURE_INFERENCE_ENDPOINT")),
new DefaultAzureCredential(includeInteractiveCredentials: true),
"text-embedding-3-small"
);
Skapa inbäddningar
Skapa en inbäddningsbegäran för att se modellens utdata.
EmbeddingsOptions requestOptions = new EmbeddingsOptions()
{
Input = {
"The ultimate answer to the question of life"
},
};
Response<EmbeddingsResult> response = client.Embed(requestOptions);
Dricks
När du skapar en begäran tar du hänsyn till tokens indatagräns för modellen. Om du behöver bädda in större delar av text behöver du en segmenteringsstrategi.
Svaret är följande, där du kan se modellens användningsstatistik:
Console.WriteLine($"Embedding: {response.Value.Data}");
Console.WriteLine($"Model: {response.Value.Model}");
Console.WriteLine("Usage:");
Console.WriteLine($"\tPrompt tokens: {response.Value.Usage.PromptTokens}");
Console.WriteLine($"\tTotal tokens: {response.Value.Usage.TotalTokens}");
Det kan vara användbart att beräkna inbäddningar i indatabatch. Parametern inputs kan vara en lista över strängar, där varje sträng är olika indata. Svaret är i sin tur en lista över inbäddningar, där varje inbäddning motsvarar indata i samma position.
EmbeddingsOptions requestOptions = new EmbeddingsOptions()
{
Input = {
"The ultimate answer to the question of life",
"The largest planet in our solar system is Jupiter"
},
};
Response<EmbeddingsResult> response = client.Embed(requestOptions);
Svaret är följande, där du kan se modellens användningsstatistik:
Dricks
När du skapar batchar med begäran tar du hänsyn till batchgränsen för var och en av modellerna. De flesta modeller har en batchgräns på 1 024.
Ange inbäddningsdimensioner
Du kan ange antalet dimensioner för inbäddningarna. Följande exempelkod visar hur du skapar inbäddningar med 1 024 dimensioner. Observera att inte alla inbäddningsmodeller har stöd för att ange antalet dimensioner i begäran och i dessa fall returneras ett 422-fel.
Skapa olika typer av inbäddningar
Vissa modeller kan generera flera inbäddningar för samma indata beroende på hur du planerar att använda dem. Med den här funktionen kan du hämta mer exakta inbäddningar för RAG-mönster.
I följande exempel visas hur du skapar inbäddningar som används för att skapa en inbäddning för ett dokument som ska lagras i en vektordatabas:
var input = new List<string> {
"The answer to the ultimate question of life, the universe, and everything is 42"
};
var requestOptions = new EmbeddingsOptions(input, EmbeddingInputType.DOCUMENT);
Response<EmbeddingsResult> response = client.Embed(requestOptions);
När du arbetar med en fråga för att hämta ett sådant dokument kan du använda följande kodfragment för att skapa inbäddningarna för frågan och maximera hämtningsprestandan.
var input = new List<string> {
"What's the ultimate meaning of life?"
};
var requestOptions = new EmbeddingsOptions(input, EmbeddingInputType.QUERY);
Response<EmbeddingsResult> response = client.Embed(requestOptions);
Observera att inte alla inbäddningsmodeller stöder indatatypen i begäran och i dessa fall returneras ett 422-fel. Som standard returneras inbäddningar av typen Text .
Viktigt!
Objekt markerade (förhandsversion) i den här artikeln är för närvarande i offentlig förhandsversion. Den här förhandsversionen tillhandahålls utan ett serviceavtal och vi rekommenderar det inte för produktionsarbetsbelastningar. Vissa funktioner kanske inte stöds eller kan vara begränsade. Mer information finns i Kompletterande villkor för användning av Microsoft Azure-förhandsversioner.
Den här artikeln beskriver hur du använder API för inbäddning med modeller som distribueras till Azure AI-modellinferens i Azure AI-tjänster.
Förutsättningar
Om du vill använda inbäddningsmodeller i ditt program behöver du:
En Azure-prenumeration Om du använder GitHub-modeller kan du uppgradera din upplevelse och skapa en Azure-prenumeration i processen. Läs Uppgradera från GitHub-modeller till Azure AI-modellinferens om så är fallet.
En Azure AI-tjänstresurs. Mer information finns i Skapa en Azure AI Services-resurs.
Slutpunkts-URL:en och nyckeln.
- En inbäddningsmodelldistribution. Om du inte har någon läser du Lägg till och konfigurera modeller i Azure AI-tjänster för att lägga till en inbäddningsmodell i resursen.
Använda inbäddningar
Om du vill använda textbäddningarna använder du den väg /embeddings som läggs till i bas-URL:en tillsammans med dina autentiseringsuppgifter som anges i api-key.
Authorization -huvudet stöds också med formatet Bearer <key>.
POST https://<resource>.services.ai.azure.com/models/embeddings?api-version=2024-05-01-preview
Content-Type: application/json
api-key: <key>
Om du har konfigurerat resursen med Stöd för Microsoft Entra-ID skickar du token i Authorization rubriken:
POST https://<resource>.services.ai.azure.com/models/embeddings?api-version=2024-05-01-preview
Content-Type: application/json
Authorization: Bearer <token>
Skapa inbäddningar
Skapa en inbäddningsbegäran för att se modellens utdata.
{
"input": [
"The ultimate answer to the question of life"
]
}
Dricks
När du skapar en begäran tar du hänsyn till tokens indatagräns för modellen. Om du behöver bädda in större delar av text behöver du en segmenteringsstrategi.
Svaret är följande, där du kan se modellens användningsstatistik:
{
"id": "0ab1234c-d5e6-7fgh-i890-j1234k123456",
"object": "list",
"data": [
{
"index": 0,
"object": "embedding",
"embedding": [
0.017196655,
// ...
-0.000687122,
-0.025054932,
-0.015777588
]
}
],
"model": "text-embedding-3-small",
"usage": {
"prompt_tokens": 9,
"completion_tokens": 0,
"total_tokens": 9
}
}
Det kan vara användbart att beräkna inbäddningar i indatabatch. Parametern inputs kan vara en lista över strängar, där varje sträng är olika indata. Svaret är i sin tur en lista över inbäddningar, där varje inbäddning motsvarar indata i samma position.
{
"input": [
"The ultimate answer to the question of life",
"The largest planet in our solar system is Jupiter"
]
}
Svaret är följande, där du kan se modellens användningsstatistik:
{
"id": "0ab1234c-d5e6-7fgh-i890-j1234k123456",
"object": "list",
"data": [
{
"index": 0,
"object": "embedding",
"embedding": [
0.017196655,
// ...
-0.000687122,
-0.025054932,
-0.015777588
]
},
{
"index": 1,
"object": "embedding",
"embedding": [
0.017196655,
// ...
-0.000687122,
-0.025054932,
-0.015777588
]
}
],
"model": "text-embedding-3-small",
"usage": {
"prompt_tokens": 19,
"completion_tokens": 0,
"total_tokens": 19
}
}
Dricks
När du skapar batchar med begäran tar du hänsyn till batchgränsen för var och en av modellerna. De flesta modeller har en batchgräns på 1 024.
Ange inbäddningsdimensioner
Du kan ange antalet dimensioner för inbäddningarna. Följande exempelkod visar hur du skapar inbäddningar med 1 024 dimensioner. Observera att inte alla inbäddningsmodeller har stöd för att ange antalet dimensioner i begäran och i dessa fall returneras ett 422-fel.
{
"input": [
"The ultimate answer to the question of life"
],
"dimensions": 1024
}
Skapa olika typer av inbäddningar
Vissa modeller kan generera flera inbäddningar för samma indata beroende på hur du planerar att använda dem. Med den här funktionen kan du hämta mer exakta inbäddningar för RAG-mönster.
I följande exempel visas hur du skapar inbäddningar som används för att skapa en inbäddning för ett dokument som ska lagras i en vektordatabas:
{
"input": [
"The answer to the ultimate question of life, the universe, and everything is 42"
],
"input_type": "document"
}
När du arbetar med en fråga för att hämta ett sådant dokument kan du använda följande kodfragment för att skapa inbäddningarna för frågan och maximera hämtningsprestandan.
{
"input": [
"What's the ultimate meaning of life?"
],
"input_type": "query"
}
Observera att inte alla inbäddningsmodeller stöder indatatypen i begäran och i dessa fall returneras ett 422-fel. Som standard returneras inbäddningar av typen Text .