Så här genererar du chattavslut med Azure AI-modellinferens
Viktigt!
Objekt markerade (förhandsversion) i den här artikeln är för närvarande i offentlig förhandsversion. Den här förhandsversionen tillhandahålls utan ett serviceavtal och vi rekommenderar det inte för produktionsarbetsbelastningar. Vissa funktioner kanske inte stöds eller kan vara begränsade. Mer information finns i Kompletterande villkor för användning av Microsoft Azure-förhandsversioner.
Den här artikeln beskriver hur du använder API:et för chattslutsättningar med modeller som distribuerats till Azure AI-modellinferens i Azure AI-tjänster.
Förutsättningar
Om du vill använda modeller för chattkomplettering i ditt program behöver du:
En Azure-prenumeration Om du använder GitHub-modeller kan du uppgradera din upplevelse och skapa en Azure-prenumeration i processen. Läs Uppgradera från GitHub-modeller till Azure AI-modellinferens om så är fallet.
En Azure AI-tjänstresurs. Mer information finns i Skapa en Azure AI Services-resurs.
Slutpunkts-URL:en och nyckeln.

En modelldistribution för chattavslut. Om du inte har någon läser du Lägg till och konfigurera modeller i Azure AI-tjänster för att lägga till en modell för chattavslut i resursen.
Installera Azure AI-slutsatsdragningspaketet med följande kommando:
pip install -U azure-ai-inferenceDricks
Läs mer om Azure AI-slutsatsdragningspaketet och referensen.
Använda chattens slutföranden
Skapa först klienten för att använda modellen. I följande kod används en slutpunkts-URL och nyckel som lagras i miljövariabler.
import os
from azure.ai.inference import ChatCompletionsClient
from azure.core.credentials import AzureKeyCredential
client = ChatCompletionsClient(
endpoint=os.environ["AZURE_INFERENCE_ENDPOINT"],
credential=AzureKeyCredential(os.environ["AZURE_INFERENCE_CREDENTIAL"]),
model="mistral-large-2407"
)
Om du har konfigurerat resursen till med Stöd för Microsoft Entra-ID kan du använda följande kodfragment för att skapa en klient.
import os
from azure.ai.inference import ChatCompletionsClient
from azure.identity import DefaultAzureCredential
client = ChatCompletionsClient(
endpoint=os.environ["AZURE_INFERENCE_ENDPOINT"],
credential=DefaultAzureCredential(),
model="mistral-large-2407"
)
Skapa en begäran om att chatten ska slutföras
I följande exempel visas hur du kan skapa en grundläggande begäran om att slutföra chatten till modellen.
from azure.ai.inference.models import SystemMessage, UserMessage
response = client.complete(
messages=[
SystemMessage(content="You are a helpful assistant."),
UserMessage(content="How many languages are in the world?"),
],
)
Kommentar
Vissa modeller stöder inte systemmeddelanden (role="system"). När du använder AZURE AI-modellinferens-API:et översätts systemmeddelanden till användarmeddelanden, vilket är den närmaste tillgängliga funktionen. Den här översättningen erbjuds för enkelhetens skull, men det är viktigt att du kontrollerar att modellen följer anvisningarna i systemmeddelandet med rätt konfidensnivå.
Svaret är följande, där du kan se modellens användningsstatistik:
print("Response:", response.choices[0].message.content)
print("Model:", response.model)
print("Usage:")
print("\tPrompt tokens:", response.usage.prompt_tokens)
print("\tTotal tokens:", response.usage.total_tokens)
print("\tCompletion tokens:", response.usage.completion_tokens)
Response: As of now, it's estimated that there are about 7,000 languages spoken around the world. However, this number can vary as some languages become extinct and new ones develop. It's also important to note that the number of speakers can greatly vary between languages, with some having millions of speakers and others only a few hundred.
Model: mistral-large-2407
Usage:
Prompt tokens: 19
Total tokens: 91
Completion tokens: 72
usage Granska avsnittet i svaret för att se antalet token som används för prompten, det totala antalet token som genererats och antalet token som används för slutförandet.
Strömma innehåll
Som standard returnerar API:et för slutförande hela det genererade innehållet i ett enda svar. Om du genererar långa slutföranden kan det ta många sekunder att vänta på svaret.
Du kan strömma innehållet för att hämta det när det genereras. Med strömmande innehåll kan du börja bearbeta slutförandet när innehållet blir tillgängligt. Det här läget returnerar ett objekt som strömmar tillbaka svaret som databaserade serverutskickade händelser. Extrahera segment från deltafältet i stället för meddelandefältet.
Om du vill strömma slutföranden anger stream=True du när du anropar modellen.
result = client.complete(
messages=[
SystemMessage(content="You are a helpful assistant."),
UserMessage(content="How many languages are in the world?"),
],
temperature=0,
top_p=1,
max_tokens=2048,
stream=True,
)
Om du vill visualisera utdata definierar du en hjälpfunktion för att skriva ut strömmen.
def print_stream(result):
"""
Prints the chat completion with streaming.
"""
import time
for update in result:
if update.choices:
print(update.choices[0].delta.content, end="")
Du kan visualisera hur strömning genererar innehåll:
print_stream(result)
Utforska fler parametrar som stöds av slutsatsdragningsklienten
Utforska andra parametrar som du kan ange i slutsatsdragningsklienten. En fullständig lista över alla parametrar som stöds och deras motsvarande dokumentation finns i API-referensen för Azure AI-modellinferens.
from azure.ai.inference.models import ChatCompletionsResponseFormatText
response = client.complete(
messages=[
SystemMessage(content="You are a helpful assistant."),
UserMessage(content="How many languages are in the world?"),
],
presence_penalty=0.1,
frequency_penalty=0.8,
max_tokens=2048,
stop=["<|endoftext|>"],
temperature=0,
top_p=1,
response_format={ "type": ChatCompletionsResponseFormatText() },
)
Vissa modeller stöder inte JSON-utdataformatering. Du kan alltid uppmana modellen att generera JSON-utdata. Sådana utdata är dock inte garanterade att vara giltiga JSON.
Om du vill skicka en parameter som inte finns med i listan över parametrar som stöds kan du skicka den till den underliggande modellen med hjälp av extra parametrar. Se Skicka extra parametrar till modellen.
Skapa JSON-utdata
Vissa modeller kan skapa JSON-utdata. Ange response_format till json_object för att aktivera JSON-läge och garantera att meddelandet som modellen genererar är giltigt JSON. Du måste också instruera modellen att skapa JSON själv via ett system- eller användarmeddelande. Dessutom kan meddelandeinnehållet vara delvis avskuret om finish_reason="length", vilket indikerar att genereringen överskred max_tokens eller att konversationen överskred den maximala kontextlängden.
from azure.ai.inference.models import ChatCompletionsResponseFormatJSON
response = client.complete(
messages=[
SystemMessage(content="You are a helpful assistant that always generate responses in JSON format, using."
" the following format: { ""answer"": ""response"" }."),
UserMessage(content="How many languages are in the world?"),
],
response_format={ "type": ChatCompletionsResponseFormatJSON() }
)
Skicka extra parametrar till modellen
Med AZURE AI Model Inference API kan du skicka extra parametrar till modellen. Följande kodexempel visar hur du skickar den extra parametern logprobs till modellen.
response = client.complete(
messages=[
SystemMessage(content="You are a helpful assistant."),
UserMessage(content="How many languages are in the world?"),
],
model_extras={
"logprobs": True
}
)
Innan du skickar extra parametrar till Azure AI-modellinferens-API:et kontrollerar du att din modell stöder dessa extra parametrar. När begäran görs till den underliggande modellen skickas rubriken extra-parameters till modellen med värdet pass-through. Det här värdet anger att slutpunkten ska skicka de extra parametrarna till modellen. Användning av extra parametrar med modellen garanterar inte att modellen faktiskt kan hantera dem. Läs modellens dokumentation för att förstå vilka extra parametrar som stöds.
Använda verktyg
Vissa modeller stöder användning av verktyg, vilket kan vara en extraordinär resurs när du behöver avlasta specifika uppgifter från språkmodellen och i stället förlitar dig på ett mer deterministiskt system eller till och med en annan språkmodell. Med AZURE AI Model Inference API kan du definiera verktyg på följande sätt.
I följande kodexempel skapas en verktygsdefinition som kan titta från flyginformation från två olika städer.
from azure.ai.inference.models import FunctionDefinition, ChatCompletionsFunctionToolDefinition
flight_info = ChatCompletionsFunctionToolDefinition(
function=FunctionDefinition(
name="get_flight_info",
description="Returns information about the next flight between two cities. This includes the name of the airline, flight number and the date and time of the next flight",
parameters={
"type": "object",
"properties": {
"origin_city": {
"type": "string",
"description": "The name of the city where the flight originates",
},
"destination_city": {
"type": "string",
"description": "The flight destination city",
},
},
"required": ["origin_city", "destination_city"],
},
)
)
tools = [flight_info]
I det här exemplet är funktionens utdata att det inte finns några tillgängliga flyg för den valda rutten, men användaren bör överväga att ta ett tåg.
def get_flight_info(loc_origin: str, loc_destination: str):
return {
"info": f"There are no flights available from {loc_origin} to {loc_destination}. You should take a train, specially if it helps to reduce CO2 emissions."
}
Kommentar
Cohere-modeller kräver att ett verktygs svar är ett giltigt JSON-innehåll formaterat som en sträng. När du skapar meddelanden av typen Verktyg kontrollerar du att svaret är en giltig JSON-sträng.
Uppmana modellen att boka flyg med hjälp av den här funktionen:
messages = [
SystemMessage(
content="You are a helpful assistant that help users to find information about traveling, how to get"
" to places and the different transportations options. You care about the environment and you"
" always have that in mind when answering inqueries.",
),
UserMessage(
content="When is the next flight from Miami to Seattle?",
),
]
response = client.complete(
messages=messages, tools=tools, tool_choice="auto"
)
Du kan kontrollera svaret för att ta reda på om ett verktyg behöver anropas. Kontrollera avslutsorsaken för att avgöra om verktyget ska anropas. Kom ihåg att flera verktygstyper kan anges. Det här exemplet visar ett verktyg av typen function.
response_message = response.choices[0].message
tool_calls = response_message.tool_calls
print("Finish reason:", response.choices[0].finish_reason)
print("Tool call:", tool_calls)
Om du vill fortsätta lägger du till det här meddelandet i chatthistoriken:
messages.append(
response_message
)
Nu är det dags att anropa rätt funktion för att hantera verktygsanropet. Följande kodfragment itererar över alla verktygsanrop som anges i svaret och anropar motsvarande funktion med lämpliga parametrar. Svaret läggs också till i chatthistoriken.
import json
from azure.ai.inference.models import ToolMessage
for tool_call in tool_calls:
# Get the tool details:
function_name = tool_call.function.name
function_args = json.loads(tool_call.function.arguments.replace("\'", "\""))
tool_call_id = tool_call.id
print(f"Calling function `{function_name}` with arguments {function_args}")
# Call the function defined above using `locals()`, which returns the list of all functions
# available in the scope as a dictionary. Notice that this is just done as a simple way to get
# the function callable from its string name. Then we can call it with the corresponding
# arguments.
callable_func = locals()[function_name]
function_response = callable_func(**function_args)
print("->", function_response)
# Once we have a response from the function and its arguments, we can append a new message to the chat
# history. Notice how we are telling to the model that this chat message came from a tool:
messages.append(
ToolMessage(
tool_call_id=tool_call_id,
content=json.dumps(function_response)
)
)
Visa svaret från modellen:
response = client.complete(
messages=messages,
tools=tools,
)
Tillämpa innehållssäkerhet
Azure AI-modellinferens-API:et stöder Azure AI-innehållssäkerhet. När du använder distributioner med Azure AI-innehållssäkerhet aktiverad passerar indata och utdata genom en uppsättning klassificeringsmodeller som syftar till att identifiera och förhindra utdata från skadligt innehåll. Systemet för innehållsfiltrering identifierar och vidtar åtgärder för specifika kategorier av potentiellt skadligt innehåll i både inkommande prompter och slutföranden av utdata.
I följande exempel visas hur du hanterar händelser när modellen identifierar skadligt innehåll i indataprompten och innehållssäkerhet är aktiverat.
from azure.ai.inference.models import AssistantMessage, UserMessage, SystemMessage
try:
response = client.complete(
messages=[
SystemMessage(content="You are an AI assistant that helps people find information."),
UserMessage(content="Chopping tomatoes and cutting them into cubes or wedges are great ways to practice your knife skills."),
]
)
print(response.choices[0].message.content)
except HttpResponseError as ex:
if ex.status_code == 400:
response = ex.response.json()
if isinstance(response, dict) and "error" in response:
print(f"Your request triggered an {response['error']['code']} error:\n\t {response['error']['message']}")
else:
raise
raise
Dricks
Mer information om hur du kan konfigurera och kontrollera säkerhetsinställningar för Azure AI-innehåll finns i säkerhetsdokumentationen för Azure AI-innehåll.
Använda chattavslutningar med bilder
Vissa modeller kan resonera mellan text och bilder och generera textavslut baserat på båda typerna av indata. I det här avsnittet utforskar du funktionerna i Vissa modeller för vision på ett chattsätt:
Viktigt!
Vissa modeller stöder bara en bild för varje tur i chattkonversationen och endast den sista bilden behålls i kontext. Om du lägger till flera bilder resulterar det i ett fel.
Om du vill se den här funktionen laddar du ned en bild och kodar informationen som base64 sträng. Resulterande data bör finnas i en data-URL:
from urllib.request import urlopen, Request
import base64
image_url = "https://news.microsoft.com/source/wp-content/uploads/2024/04/The-Phi-3-small-language-models-with-big-potential-1-1900x1069.jpg"
image_format = "jpeg"
request = Request(image_url, headers={"User-Agent": "Mozilla/5.0"})
image_data = base64.b64encode(urlopen(request).read()).decode("utf-8")
data_url = f"data:image/{image_format};base64,{image_data}"
Visualisera bilden:
import requests
import IPython.display as Disp
Disp.Image(requests.get(image_url).content)

Skapa nu en begäran om att slutföra chatten med avbildningen:
from azure.ai.inference.models import TextContentItem, ImageContentItem, ImageUrl
response = client.complete(
messages=[
SystemMessage("You are a helpful assistant that can generate responses based on images."),
UserMessage(content=[
TextContentItem(text="Which conclusion can be extracted from the following chart?"),
ImageContentItem(image=ImageUrl(url=data_url))
]),
],
temperature=0,
top_p=1,
max_tokens=2048,
)
Svaret är följande, där du kan se modellens användningsstatistik:
print(f"{response.choices[0].message.role}:\n\t{response.choices[0].message.content}\n")
print("Model:", response.model)
print("Usage:")
print("\tPrompt tokens:", response.usage.prompt_tokens)
print("\tCompletion tokens:", response.usage.completion_tokens)
print("\tTotal tokens:", response.usage.total_tokens)
ASSISTANT: The chart illustrates that larger models tend to perform better in quality, as indicated by their size in billions of parameters. However, there are exceptions to this trend, such as Phi-3-medium and Phi-3-small, which outperform smaller models in quality. This suggests that while larger models generally have an advantage, there might be other factors at play that influence a model's performance.
Model: mistral-large-2407
Usage:
Prompt tokens: 2380
Completion tokens: 126
Total tokens: 2506
Viktigt!
Objekt markerade (förhandsversion) i den här artikeln är för närvarande i offentlig förhandsversion. Den här förhandsversionen tillhandahålls utan ett serviceavtal och vi rekommenderar det inte för produktionsarbetsbelastningar. Vissa funktioner kanske inte stöds eller kan vara begränsade. Mer information finns i Kompletterande villkor för användning av Microsoft Azure-förhandsversioner.
Den här artikeln beskriver hur du använder API:et för chattslutsättningar med modeller som distribuerats till Azure AI-modellinferens i Azure AI-tjänster.
Förutsättningar
Om du vill använda modeller för chattkomplettering i ditt program behöver du:
En Azure-prenumeration Om du använder GitHub-modeller kan du uppgradera din upplevelse och skapa en Azure-prenumeration i processen. Läs Uppgradera från GitHub-modeller till Azure AI-modellinferens om så är fallet.
En Azure AI-tjänstresurs. Mer information finns i Skapa en Azure AI Services-resurs.
Slutpunkts-URL:en och nyckeln.
En modelldistribution för chattavslut. Om du inte har någon läser du Lägg till och konfigurera modeller i Azure AI-tjänster för att lägga till en modell för chattavslut i resursen.
Installera Azure Inference-biblioteket för JavaScript med följande kommando:
npm install @azure-rest/ai-inferenceDricks
Läs mer om Azure AI-slutsatsdragningspaketet och referensen.
Använda chattens slutföranden
Skapa först klienten för att använda modellen. I följande kod används en slutpunkts-URL och nyckel som lagras i miljövariabler.
import ModelClient from "@azure-rest/ai-inference";
import { isUnexpected } from "@azure-rest/ai-inference";
import { AzureKeyCredential } from "@azure/core-auth";
const client = new ModelClient(
process.env.AZURE_INFERENCE_ENDPOINT,
new AzureKeyCredential(process.env.AZURE_INFERENCE_CREDENTIAL)
);
Om du har konfigurerat resursen till med Stöd för Microsoft Entra-ID kan du använda följande kodfragment för att skapa en klient.
import ModelClient from "@azure-rest/ai-inference";
import { isUnexpected } from "@azure-rest/ai-inference";
import { DefaultAzureCredential } from "@azure/identity";
const client = new ModelClient(
process.env.AZURE_INFERENCE_ENDPOINT,
new DefaultAzureCredential()
);
Skapa en begäran om att chatten ska slutföras
I följande exempel visas hur du kan skapa en grundläggande begäran om att slutföra chatten till modellen.
var messages = [
{ role: "system", content: "You are a helpful assistant" },
{ role: "user", content: "How many languages are in the world?" },
];
var response = await client.path("/chat/completions").post({
body: {
messages: messages,
}
});
Kommentar
Vissa modeller stöder inte systemmeddelanden (role="system"). När du använder AZURE AI-modellinferens-API:et översätts systemmeddelanden till användarmeddelanden, vilket är den närmaste tillgängliga funktionen. Den här översättningen erbjuds för enkelhetens skull, men det är viktigt att du kontrollerar att modellen följer anvisningarna i systemmeddelandet med rätt konfidensnivå.
Svaret är följande, där du kan se modellens användningsstatistik:
if (isUnexpected(response)) {
throw response.body.error;
}
console.log("Response: ", response.body.choices[0].message.content);
console.log("Model: ", response.body.model);
console.log("Usage:");
console.log("\tPrompt tokens:", response.body.usage.prompt_tokens);
console.log("\tTotal tokens:", response.body.usage.total_tokens);
console.log("\tCompletion tokens:", response.body.usage.completion_tokens);
Response: As of now, it's estimated that there are about 7,000 languages spoken around the world. However, this number can vary as some languages become extinct and new ones develop. It's also important to note that the number of speakers can greatly vary between languages, with some having millions of speakers and others only a few hundred.
Model: mistral-large-2407
Usage:
Prompt tokens: 19
Total tokens: 91
Completion tokens: 72
usage Granska avsnittet i svaret för att se antalet token som används för prompten, det totala antalet token som genererats och antalet token som används för slutförandet.
Strömma innehåll
Som standard returnerar API:et för slutförande hela det genererade innehållet i ett enda svar. Om du genererar långa slutföranden kan det ta många sekunder att vänta på svaret.
Du kan strömma innehållet för att hämta det när det genereras. Med strömmande innehåll kan du börja bearbeta slutförandet när innehållet blir tillgängligt. Det här läget returnerar ett objekt som strömmar tillbaka svaret som databaserade serverutskickade händelser. Extrahera segment från deltafältet i stället för meddelandefältet.
Om du vill strömma slutföranden använder .asNodeStream() du när du anropar modellen.
var messages = [
{ role: "system", content: "You are a helpful assistant" },
{ role: "user", content: "How many languages are in the world?" },
];
var response = await client.path("/chat/completions").post({
body: {
messages: messages,
}
}).asNodeStream();
Du kan visualisera hur strömning genererar innehåll:
var stream = response.body;
if (!stream) {
stream.destroy();
throw new Error(`Failed to get chat completions with status: ${response.status}`);
}
if (response.status !== "200") {
throw new Error(`Failed to get chat completions: ${response.body.error}`);
}
var sses = createSseStream(stream);
for await (const event of sses) {
if (event.data === "[DONE]") {
return;
}
for (const choice of (JSON.parse(event.data)).choices) {
console.log(choice.delta?.content ?? "");
}
}
Utforska fler parametrar som stöds av slutsatsdragningsklienten
Utforska andra parametrar som du kan ange i slutsatsdragningsklienten. En fullständig lista över alla parametrar som stöds och deras motsvarande dokumentation finns i API-referensen för Azure AI-modellinferens.
var messages = [
{ role: "system", content: "You are a helpful assistant" },
{ role: "user", content: "How many languages are in the world?" },
];
var response = await client.path("/chat/completions").post({
body: {
messages: messages,
presence_penalty: "0.1",
frequency_penalty: "0.8",
max_tokens: 2048,
stop: ["<|endoftext|>"],
temperature: 0,
top_p: 1,
response_format: { type: "text" },
}
});
Vissa modeller stöder inte JSON-utdataformatering. Du kan alltid uppmana modellen att generera JSON-utdata. Sådana utdata är dock inte garanterade att vara giltiga JSON.
Om du vill skicka en parameter som inte finns med i listan över parametrar som stöds kan du skicka den till den underliggande modellen med hjälp av extra parametrar. Se Skicka extra parametrar till modellen.
Skapa JSON-utdata
Vissa modeller kan skapa JSON-utdata. Ange response_format till json_object för att aktivera JSON-läge och garantera att meddelandet som modellen genererar är giltigt JSON. Du måste också instruera modellen att skapa JSON själv via ett system- eller användarmeddelande. Dessutom kan meddelandeinnehållet vara delvis avskuret om finish_reason="length", vilket indikerar att genereringen överskred max_tokens eller att konversationen överskred den maximala kontextlängden.
var messages = [
{ role: "system", content: "You are a helpful assistant that always generate responses in JSON format, using."
+ " the following format: { \"answer\": \"response\" }." },
{ role: "user", content: "How many languages are in the world?" },
];
var response = await client.path("/chat/completions").post({
body: {
messages: messages,
response_format: { type: "json_object" }
}
});
Skicka extra parametrar till modellen
Med AZURE AI Model Inference API kan du skicka extra parametrar till modellen. Följande kodexempel visar hur du skickar den extra parametern logprobs till modellen.
var messages = [
{ role: "system", content: "You are a helpful assistant" },
{ role: "user", content: "How many languages are in the world?" },
];
var response = await client.path("/chat/completions").post({
headers: {
"extra-params": "pass-through"
},
body: {
messages: messages,
logprobs: true
}
});
Innan du skickar extra parametrar till Azure AI-modellinferens-API:et kontrollerar du att din modell stöder dessa extra parametrar. När begäran görs till den underliggande modellen skickas rubriken extra-parameters till modellen med värdet pass-through. Det här värdet anger att slutpunkten ska skicka de extra parametrarna till modellen. Användning av extra parametrar med modellen garanterar inte att modellen faktiskt kan hantera dem. Läs modellens dokumentation för att förstå vilka extra parametrar som stöds.
Använda verktyg
Vissa modeller stöder användning av verktyg, vilket kan vara en extraordinär resurs när du behöver avlasta specifika uppgifter från språkmodellen och i stället förlitar dig på ett mer deterministiskt system eller till och med en annan språkmodell. Med AZURE AI Model Inference API kan du definiera verktyg på följande sätt.
I följande kodexempel skapas en verktygsdefinition som kan titta från flyginformation från två olika städer.
const flight_info = {
name: "get_flight_info",
description: "Returns information about the next flight between two cities. This includes the name of the airline, flight number and the date and time of the next flight",
parameters: {
type: "object",
properties: {
origin_city: {
type: "string",
description: "The name of the city where the flight originates",
},
destination_city: {
type: "string",
description: "The flight destination city",
},
},
required: ["origin_city", "destination_city"],
},
}
const tools = [
{
type: "function",
function: flight_info,
},
];
I det här exemplet är funktionens utdata att det inte finns några tillgängliga flyg för den valda rutten, men användaren bör överväga att ta ett tåg.
function get_flight_info(loc_origin, loc_destination) {
return {
info: "There are no flights available from " + loc_origin + " to " + loc_destination + ". You should take a train, specially if it helps to reduce CO2 emissions."
}
}
Kommentar
Cohere-modeller kräver att ett verktygs svar är ett giltigt JSON-innehåll formaterat som en sträng. När du skapar meddelanden av typen Verktyg kontrollerar du att svaret är en giltig JSON-sträng.
Uppmana modellen att boka flyg med hjälp av den här funktionen:
var result = await client.path("/chat/completions").post({
body: {
messages: messages,
tools: tools,
tool_choice: "auto"
}
});
Du kan kontrollera svaret för att ta reda på om ett verktyg behöver anropas. Kontrollera avslutsorsaken för att avgöra om verktyget ska anropas. Kom ihåg att flera verktygstyper kan anges. Det här exemplet visar ett verktyg av typen function.
const response_message = response.body.choices[0].message;
const tool_calls = response_message.tool_calls;
console.log("Finish reason: " + response.body.choices[0].finish_reason);
console.log("Tool call: " + tool_calls);
Om du vill fortsätta lägger du till det här meddelandet i chatthistoriken:
messages.push(response_message);
Nu är det dags att anropa rätt funktion för att hantera verktygsanropet. Följande kodfragment itererar över alla verktygsanrop som anges i svaret och anropar motsvarande funktion med lämpliga parametrar. Svaret läggs också till i chatthistoriken.
function applyToolCall({ function: call, id }) {
// Get the tool details:
const tool_params = JSON.parse(call.arguments);
console.log("Calling function " + call.name + " with arguments " + tool_params);
// Call the function defined above using `window`, which returns the list of all functions
// available in the scope as a dictionary. Notice that this is just done as a simple way to get
// the function callable from its string name. Then we can call it with the corresponding
// arguments.
const function_response = tool_params.map(window[call.name]);
console.log("-> " + function_response);
return function_response
}
for (const tool_call of tool_calls) {
var tool_response = tool_call.apply(applyToolCall);
messages.push(
{
role: "tool",
tool_call_id: tool_call.id,
content: tool_response
}
);
}
Visa svaret från modellen:
var result = await client.path("/chat/completions").post({
body: {
messages: messages,
tools: tools,
}
});
Tillämpa innehållssäkerhet
Azure AI-modellinferens-API:et stöder Azure AI-innehållssäkerhet. När du använder distributioner med Azure AI-innehållssäkerhet aktiverad passerar indata och utdata genom en uppsättning klassificeringsmodeller som syftar till att identifiera och förhindra utdata från skadligt innehåll. Systemet för innehållsfiltrering identifierar och vidtar åtgärder för specifika kategorier av potentiellt skadligt innehåll i både inkommande prompter och slutföranden av utdata.
I följande exempel visas hur du hanterar händelser när modellen identifierar skadligt innehåll i indataprompten och innehållssäkerhet är aktiverat.
try {
var messages = [
{ role: "system", content: "You are an AI assistant that helps people find information." },
{ role: "user", content: "Chopping tomatoes and cutting them into cubes or wedges are great ways to practice your knife skills." },
];
var response = await client.path("/chat/completions").post({
body: {
messages: messages,
}
});
console.log(response.body.choices[0].message.content);
}
catch (error) {
if (error.status_code == 400) {
var response = JSON.parse(error.response._content);
if (response.error) {
console.log(`Your request triggered an ${response.error.code} error:\n\t ${response.error.message}`);
}
else
{
throw error;
}
}
}
Dricks
Mer information om hur du kan konfigurera och kontrollera säkerhetsinställningar för Azure AI-innehåll finns i säkerhetsdokumentationen för Azure AI-innehåll.
Använda chattavslutningar med bilder
Vissa modeller kan resonera mellan text och bilder och generera textavslut baserat på båda typerna av indata. I det här avsnittet utforskar du funktionerna i Vissa modeller för vision på ett chattsätt:
Viktigt!
Vissa modeller stöder bara en bild för varje tur i chattkonversationen och endast den sista bilden behålls i kontext. Om du lägger till flera bilder resulterar det i ett fel.
Om du vill se den här funktionen laddar du ned en bild och kodar informationen som base64 sträng. Resulterande data bör finnas i en data-URL:
const image_url = "https://news.microsoft.com/source/wp-content/uploads/2024/04/The-Phi-3-small-language-models-with-big-potential-1-1900x1069.jpg";
const image_format = "jpeg";
const response = await fetch(image_url, { headers: { "User-Agent": "Mozilla/5.0" } });
const image_data = await response.arrayBuffer();
const image_data_base64 = Buffer.from(image_data).toString("base64");
const data_url = `data:image/${image_format};base64,${image_data_base64}`;
Visualisera bilden:
const img = document.createElement("img");
img.src = data_url;
document.body.appendChild(img);
Skapa nu en begäran om att slutföra chatten med avbildningen:
var messages = [
{ role: "system", content: "You are a helpful assistant that can generate responses based on images." },
{ role: "user", content:
[
{ type: "text", text: "Which conclusion can be extracted from the following chart?" },
{ type: "image_url", image:
{
url: data_url
}
}
]
}
];
var response = await client.path("/chat/completions").post({
body: {
messages: messages,
temperature: 0,
top_p: 1,
max_tokens: 2048,
}
});
Svaret är följande, där du kan se modellens användningsstatistik:
console.log(response.body.choices[0].message.role + ": " + response.body.choices[0].message.content);
console.log("Model:", response.body.model);
console.log("Usage:");
console.log("\tPrompt tokens:", response.body.usage.prompt_tokens);
console.log("\tCompletion tokens:", response.body.usage.completion_tokens);
console.log("\tTotal tokens:", response.body.usage.total_tokens);
ASSISTANT: The chart illustrates that larger models tend to perform better in quality, as indicated by their size in billions of parameters. However, there are exceptions to this trend, such as Phi-3-medium and Phi-3-small, which outperform smaller models in quality. This suggests that while larger models generally have an advantage, there might be other factors at play that influence a model's performance.
Model: mistral-large-2407
Usage:
Prompt tokens: 2380
Completion tokens: 126
Total tokens: 2506
Viktigt!
Objekt markerade (förhandsversion) i den här artikeln är för närvarande i offentlig förhandsversion. Den här förhandsversionen tillhandahålls utan ett serviceavtal och vi rekommenderar det inte för produktionsarbetsbelastningar. Vissa funktioner kanske inte stöds eller kan vara begränsade. Mer information finns i Kompletterande villkor för användning av Microsoft Azure-förhandsversioner.
Den här artikeln beskriver hur du använder API:et för chattslutsättningar med modeller som distribuerats till Azure AI-modellinferens i Azure AI-tjänster.
Förutsättningar
Om du vill använda modeller för chattkomplettering i ditt program behöver du:
En Azure-prenumeration Om du använder GitHub-modeller kan du uppgradera din upplevelse och skapa en Azure-prenumeration i processen. Läs Uppgradera från GitHub-modeller till Azure AI-modellinferens om så är fallet.
En Azure AI-tjänstresurs. Mer information finns i Skapa en Azure AI Services-resurs.
Slutpunkts-URL:en och nyckeln.
En modelldistribution för chattavslut. Om du inte har någon läser du Lägg till och konfigurera modeller i Azure AI-tjänster för att lägga till en modell för chattavslut i resursen.
Lägg till Azure AI-slutsatsdragningspaketet i projektet:
<dependency> <groupId>com.azure</groupId> <artifactId>azure-ai-inference</artifactId> <version>1.0.0-beta.1</version> </dependency>Dricks
Läs mer om Azure AI-slutsatsdragningspaketet och referensen.
Om du använder Entra-ID behöver du också följande paket:
<dependency> <groupId>com.azure</groupId> <artifactId>azure-identity</artifactId> <version>1.13.3</version> </dependency>Importera följande namnområde:
package com.azure.ai.inference.usage; import com.azure.ai.inference.EmbeddingsClient; import com.azure.ai.inference.EmbeddingsClientBuilder; import com.azure.ai.inference.models.EmbeddingsResult; import com.azure.ai.inference.models.EmbeddingItem; import com.azure.core.credential.AzureKeyCredential; import com.azure.core.util.Configuration; import java.util.ArrayList; import java.util.List;
Använda chattens slutföranden
Skapa först klienten för att använda modellen. I följande kod används en slutpunkts-URL och nyckel som lagras i miljövariabler.
Om du har konfigurerat resursen till med Stöd för Microsoft Entra-ID kan du använda följande kodfragment för att skapa en klient.
Skapa en begäran om att chatten ska slutföras
I följande exempel visas hur du kan skapa en grundläggande begäran om att slutföra chatten till modellen.
Kommentar
Vissa modeller stöder inte systemmeddelanden (role="system"). När du använder AZURE AI-modellinferens-API:et översätts systemmeddelanden till användarmeddelanden, vilket är den närmaste tillgängliga funktionen. Den här översättningen erbjuds för enkelhetens skull, men det är viktigt att du kontrollerar att modellen följer anvisningarna i systemmeddelandet med rätt konfidensnivå.
Svaret är följande, där du kan se modellens användningsstatistik:
Response: As of now, it's estimated that there are about 7,000 languages spoken around the world. However, this number can vary as some languages become extinct and new ones develop. It's also important to note that the number of speakers can greatly vary between languages, with some having millions of speakers and others only a few hundred.
Model: mistral-large-2407
Usage:
Prompt tokens: 19
Total tokens: 91
Completion tokens: 72
usage Granska avsnittet i svaret för att se antalet token som används för prompten, det totala antalet token som genererats och antalet token som används för slutförandet.
Strömma innehåll
Som standard returnerar API:et för slutförande hela det genererade innehållet i ett enda svar. Om du genererar långa slutföranden kan det ta många sekunder att vänta på svaret.
Du kan strömma innehållet för att hämta det när det genereras. Med strömmande innehåll kan du börja bearbeta slutförandet när innehållet blir tillgängligt. Det här läget returnerar ett objekt som strömmar tillbaka svaret som databaserade serverutskickade händelser. Extrahera segment från deltafältet i stället för meddelandefältet.
Du kan visualisera hur strömning genererar innehåll:
Utforska fler parametrar som stöds av slutsatsdragningsklienten
Utforska andra parametrar som du kan ange i slutsatsdragningsklienten. En fullständig lista över alla parametrar som stöds och deras motsvarande dokumentation finns i API-referensen för Azure AI-modellinferens. Vissa modeller stöder inte JSON-utdataformatering. Du kan alltid uppmana modellen att generera JSON-utdata. Sådana utdata är dock inte garanterade att vara giltiga JSON.
Om du vill skicka en parameter som inte finns med i listan över parametrar som stöds kan du skicka den till den underliggande modellen med hjälp av extra parametrar. Se Skicka extra parametrar till modellen.
Skapa JSON-utdata
Vissa modeller kan skapa JSON-utdata. Ange response_format till json_object för att aktivera JSON-läge och garantera att meddelandet som modellen genererar är giltigt JSON. Du måste också instruera modellen att skapa JSON själv via ett system- eller användarmeddelande. Dessutom kan meddelandeinnehållet vara delvis avskuret om finish_reason="length", vilket indikerar att genereringen överskred max_tokens eller att konversationen överskred den maximala kontextlängden.
Skicka extra parametrar till modellen
Med AZURE AI Model Inference API kan du skicka extra parametrar till modellen. Följande kodexempel visar hur du skickar den extra parametern logprobs till modellen.
Innan du skickar extra parametrar till Azure AI-modellinferens-API:et kontrollerar du att din modell stöder dessa extra parametrar. När begäran görs till den underliggande modellen skickas rubriken extra-parameters till modellen med värdet pass-through. Det här värdet anger att slutpunkten ska skicka de extra parametrarna till modellen. Användning av extra parametrar med modellen garanterar inte att modellen faktiskt kan hantera dem. Läs modellens dokumentation för att förstå vilka extra parametrar som stöds.
Använda verktyg
Vissa modeller stöder användning av verktyg, vilket kan vara en extraordinär resurs när du behöver avlasta specifika uppgifter från språkmodellen och i stället förlitar dig på ett mer deterministiskt system eller till och med en annan språkmodell. Med AZURE AI Model Inference API kan du definiera verktyg på följande sätt.
I följande kodexempel skapas en verktygsdefinition som kan titta från flyginformation från två olika städer.
I det här exemplet är funktionens utdata att det inte finns några tillgängliga flyg för den valda rutten, men användaren bör överväga att ta ett tåg.
Kommentar
Cohere-modeller kräver att ett verktygs svar är ett giltigt JSON-innehåll formaterat som en sträng. När du skapar meddelanden av typen Verktyg kontrollerar du att svaret är en giltig JSON-sträng.
Uppmana modellen att boka flyg med hjälp av den här funktionen:
Du kan kontrollera svaret för att ta reda på om ett verktyg behöver anropas. Kontrollera avslutsorsaken för att avgöra om verktyget ska anropas. Kom ihåg att flera verktygstyper kan anges. Det här exemplet visar ett verktyg av typen function.
Om du vill fortsätta lägger du till det här meddelandet i chatthistoriken:
Nu är det dags att anropa rätt funktion för att hantera verktygsanropet. Följande kodfragment itererar över alla verktygsanrop som anges i svaret och anropar motsvarande funktion med lämpliga parametrar. Svaret läggs också till i chatthistoriken.
Visa svaret från modellen:
Tillämpa innehållssäkerhet
Azure AI-modellinferens-API:et stöder Azure AI-innehållssäkerhet. När du använder distributioner med Azure AI-innehållssäkerhet aktiverad passerar indata och utdata genom en uppsättning klassificeringsmodeller som syftar till att identifiera och förhindra utdata från skadligt innehåll. Systemet för innehållsfiltrering identifierar och vidtar åtgärder för specifika kategorier av potentiellt skadligt innehåll i både inkommande prompter och slutföranden av utdata.
I följande exempel visas hur du hanterar händelser när modellen identifierar skadligt innehåll i indataprompten och innehållssäkerhet är aktiverat.
Dricks
Mer information om hur du kan konfigurera och kontrollera säkerhetsinställningar för Azure AI-innehåll finns i säkerhetsdokumentationen för Azure AI-innehåll.
Använda chattavslutningar med bilder
Vissa modeller kan resonera mellan text och bilder och generera textavslut baserat på båda typerna av indata. I det här avsnittet utforskar du funktionerna i Vissa modeller för vision på ett chattsätt:
Viktigt!
Vissa modeller stöder bara en bild för varje tur i chattkonversationen och endast den sista bilden behålls i kontext. Om du lägger till flera bilder resulterar det i ett fel.
Om du vill se den här funktionen laddar du ned en bild och kodar informationen som base64 sträng. Resulterande data bör finnas i en data-URL:
Visualisera bilden:
Skapa nu en begäran om att slutföra chatten med avbildningen:
Svaret är följande, där du kan se modellens användningsstatistik:
ASSISTANT: The chart illustrates that larger models tend to perform better in quality, as indicated by their size in billions of parameters. However, there are exceptions to this trend, such as Phi-3-medium and Phi-3-small, which outperform smaller models in quality. This suggests that while larger models generally have an advantage, there might be other factors at play that influence a model's performance.
Model: mistral-large-2407
Usage:
Prompt tokens: 2380
Completion tokens: 126
Total tokens: 2506
Viktigt!
Objekt markerade (förhandsversion) i den här artikeln är för närvarande i offentlig förhandsversion. Den här förhandsversionen tillhandahålls utan ett serviceavtal och vi rekommenderar det inte för produktionsarbetsbelastningar. Vissa funktioner kanske inte stöds eller kan vara begränsade. Mer information finns i Kompletterande villkor för användning av Microsoft Azure-förhandsversioner.
Den här artikeln beskriver hur du använder API:et för chattslutsättningar med modeller som distribuerats till Azure AI-modellinferens i Azure AI-tjänster.
Förutsättningar
Om du vill använda modeller för chattkomplettering i ditt program behöver du:
En Azure-prenumeration Om du använder GitHub-modeller kan du uppgradera din upplevelse och skapa en Azure-prenumeration i processen. Läs Uppgradera från GitHub-modeller till Azure AI-modellinferens om så är fallet.
En Azure AI-tjänstresurs. Mer information finns i Skapa en Azure AI Services-resurs.
Slutpunkts-URL:en och nyckeln.
En modelldistribution för chattavslut. Om du inte har någon läser du Lägg till och konfigurera modeller i Azure AI-tjänster för att lägga till en modell för chattavslut i resursen.
Installera Azure AI-slutsatsdragningspaketet med följande kommando:
dotnet add package Azure.AI.Inference --prereleaseDricks
Läs mer om Azure AI-slutsatsdragningspaketet och referensen.
Om du använder Entra-ID behöver du också följande paket:
dotnet add package Azure.Identity
Använda chattens slutföranden
Skapa först klienten för att använda modellen. I följande kod används en slutpunkts-URL och nyckel som lagras i miljövariabler.
ChatCompletionsClient client = new ChatCompletionsClient(
new Uri(Environment.GetEnvironmentVariable("AZURE_INFERENCE_ENDPOINT")),
new AzureKeyCredential(Environment.GetEnvironmentVariable("AZURE_INFERENCE_CREDENTIAL")),
"mistral-large-2407"
);
Om du har konfigurerat resursen till med Stöd för Microsoft Entra-ID kan du använda följande kodfragment för att skapa en klient.
client = new ChatCompletionsClient(
new Uri(Environment.GetEnvironmentVariable("AZURE_INFERENCE_ENDPOINT")),
new DefaultAzureCredential(includeInteractiveCredentials: true),
"mistral-large-2407"
);
Skapa en begäran om att chatten ska slutföras
I följande exempel visas hur du kan skapa en grundläggande begäran om att slutföra chatten till modellen.
ChatCompletionsOptions requestOptions = new ChatCompletionsOptions()
{
Messages = {
new ChatRequestSystemMessage("You are a helpful assistant."),
new ChatRequestUserMessage("How many languages are in the world?")
},
};
Response<ChatCompletions> response = client.Complete(requestOptions);
Kommentar
Vissa modeller stöder inte systemmeddelanden (role="system"). När du använder AZURE AI-modellinferens-API:et översätts systemmeddelanden till användarmeddelanden, vilket är den närmaste tillgängliga funktionen. Den här översättningen erbjuds för enkelhetens skull, men det är viktigt att du kontrollerar att modellen följer anvisningarna i systemmeddelandet med rätt konfidensnivå.
Svaret är följande, där du kan se modellens användningsstatistik:
Console.WriteLine($"Response: {response.Value.Content}");
Console.WriteLine($"Model: {response.Value.Model}");
Console.WriteLine("Usage:");
Console.WriteLine($"\tPrompt tokens: {response.Value.Usage.PromptTokens}");
Console.WriteLine($"\tTotal tokens: {response.Value.Usage.TotalTokens}");
Console.WriteLine($"\tCompletion tokens: {response.Value.Usage.CompletionTokens}");
Response: As of now, it's estimated that there are about 7,000 languages spoken around the world. However, this number can vary as some languages become extinct and new ones develop. It's also important to note that the number of speakers can greatly vary between languages, with some having millions of speakers and others only a few hundred.
Model: mistral-large-2407
Usage:
Prompt tokens: 19
Total tokens: 91
Completion tokens: 72
usage Granska avsnittet i svaret för att se antalet token som används för prompten, det totala antalet token som genererats och antalet token som används för slutförandet.
Strömma innehåll
Som standard returnerar API:et för slutförande hela det genererade innehållet i ett enda svar. Om du genererar långa slutföranden kan det ta många sekunder att vänta på svaret.
Du kan strömma innehållet för att hämta det när det genereras. Med strömmande innehåll kan du börja bearbeta slutförandet när innehållet blir tillgängligt. Det här läget returnerar ett objekt som strömmar tillbaka svaret som databaserade serverutskickade händelser. Extrahera segment från deltafältet i stället för meddelandefältet.
Om du vill strömma slutföranden använder CompleteStreamingAsync du metoden när du anropar modellen. Observera att i det här exemplet omsluts anropet i en asynkron metod.
static async Task StreamMessageAsync(ChatCompletionsClient client)
{
ChatCompletionsOptions requestOptions = new ChatCompletionsOptions()
{
Messages = {
new ChatRequestSystemMessage("You are a helpful assistant."),
new ChatRequestUserMessage("How many languages are in the world? Write an essay about it.")
},
MaxTokens=4096
};
StreamingResponse<StreamingChatCompletionsUpdate> streamResponse = await client.CompleteStreamingAsync(requestOptions);
await PrintStream(streamResponse);
}
Om du vill visualisera utdata definierar du en asynkron metod för att skriva ut strömmen i konsolen.
static async Task PrintStream(StreamingResponse<StreamingChatCompletionsUpdate> response)
{
await foreach (StreamingChatCompletionsUpdate chatUpdate in response)
{
if (chatUpdate.Role.HasValue)
{
Console.Write($"{chatUpdate.Role.Value.ToString().ToUpperInvariant()}: ");
}
if (!string.IsNullOrEmpty(chatUpdate.ContentUpdate))
{
Console.Write(chatUpdate.ContentUpdate);
}
}
}
Du kan visualisera hur strömning genererar innehåll:
StreamMessageAsync(client).GetAwaiter().GetResult();
Utforska fler parametrar som stöds av slutsatsdragningsklienten
Utforska andra parametrar som du kan ange i slutsatsdragningsklienten. En fullständig lista över alla parametrar som stöds och deras motsvarande dokumentation finns i API-referensen för Azure AI-modellinferens.
requestOptions = new ChatCompletionsOptions()
{
Messages = {
new ChatRequestSystemMessage("You are a helpful assistant."),
new ChatRequestUserMessage("How many languages are in the world?")
},
PresencePenalty = 0.1f,
FrequencyPenalty = 0.8f,
MaxTokens = 2048,
StopSequences = { "<|endoftext|>" },
Temperature = 0,
NucleusSamplingFactor = 1,
ResponseFormat = new ChatCompletionsResponseFormatText()
};
response = client.Complete(requestOptions);
Console.WriteLine($"Response: {response.Value.Content}");
Vissa modeller stöder inte JSON-utdataformatering. Du kan alltid uppmana modellen att generera JSON-utdata. Sådana utdata är dock inte garanterade att vara giltiga JSON.
Om du vill skicka en parameter som inte finns med i listan över parametrar som stöds kan du skicka den till den underliggande modellen med hjälp av extra parametrar. Se Skicka extra parametrar till modellen.
Skapa JSON-utdata
Vissa modeller kan skapa JSON-utdata. Ange response_format till json_object för att aktivera JSON-läge och garantera att meddelandet som modellen genererar är giltigt JSON. Du måste också instruera modellen att skapa JSON själv via ett system- eller användarmeddelande. Dessutom kan meddelandeinnehållet vara delvis avskuret om finish_reason="length", vilket indikerar att genereringen överskred max_tokens eller att konversationen överskred den maximala kontextlängden.
requestOptions = new ChatCompletionsOptions()
{
Messages = {
new ChatRequestSystemMessage(
"You are a helpful assistant that always generate responses in JSON format, " +
"using. the following format: { \"answer\": \"response\" }."
),
new ChatRequestUserMessage(
"How many languages are in the world?"
)
},
ResponseFormat = new ChatCompletionsResponseFormatJSON()
};
response = client.Complete(requestOptions);
Console.WriteLine($"Response: {response.Value.Content}");
Skicka extra parametrar till modellen
Med AZURE AI Model Inference API kan du skicka extra parametrar till modellen. Följande kodexempel visar hur du skickar den extra parametern logprobs till modellen.
requestOptions = new ChatCompletionsOptions()
{
Messages = {
new ChatRequestSystemMessage("You are a helpful assistant."),
new ChatRequestUserMessage("How many languages are in the world?")
},
AdditionalProperties = { { "logprobs", BinaryData.FromString("true") } },
};
response = client.Complete(requestOptions, extraParams: ExtraParameters.PassThrough);
Console.WriteLine($"Response: {response.Value.Content}");
Innan du skickar extra parametrar till Azure AI-modellinferens-API:et kontrollerar du att din modell stöder dessa extra parametrar. När begäran görs till den underliggande modellen skickas rubriken extra-parameters till modellen med värdet pass-through. Det här värdet anger att slutpunkten ska skicka de extra parametrarna till modellen. Användning av extra parametrar med modellen garanterar inte att modellen faktiskt kan hantera dem. Läs modellens dokumentation för att förstå vilka extra parametrar som stöds.
Använda verktyg
Vissa modeller stöder användning av verktyg, vilket kan vara en extraordinär resurs när du behöver avlasta specifika uppgifter från språkmodellen och i stället förlitar dig på ett mer deterministiskt system eller till och med en annan språkmodell. Med AZURE AI Model Inference API kan du definiera verktyg på följande sätt.
I följande kodexempel skapas en verktygsdefinition som kan titta från flyginformation från två olika städer.
FunctionDefinition flightInfoFunction = new FunctionDefinition("getFlightInfo")
{
Description = "Returns information about the next flight between two cities. This includes the name of the airline, flight number and the date and time of the next flight",
Parameters = BinaryData.FromObjectAsJson(new
{
Type = "object",
Properties = new
{
origin_city = new
{
Type = "string",
Description = "The name of the city where the flight originates"
},
destination_city = new
{
Type = "string",
Description = "The flight destination city"
}
}
},
new JsonSerializerOptions() { PropertyNamingPolicy = JsonNamingPolicy.CamelCase }
)
};
ChatCompletionsFunctionToolDefinition getFlightTool = new ChatCompletionsFunctionToolDefinition(flightInfoFunction);
I det här exemplet är funktionens utdata att det inte finns några tillgängliga flyg för den valda rutten, men användaren bör överväga att ta ett tåg.
static string getFlightInfo(string loc_origin, string loc_destination)
{
return JsonSerializer.Serialize(new
{
info = $"There are no flights available from {loc_origin} to {loc_destination}. You " +
"should take a train, specially if it helps to reduce CO2 emissions."
});
}
Kommentar
Cohere-modeller kräver att ett verktygs svar är ett giltigt JSON-innehåll formaterat som en sträng. När du skapar meddelanden av typen Verktyg kontrollerar du att svaret är en giltig JSON-sträng.
Uppmana modellen att boka flyg med hjälp av den här funktionen:
var chatHistory = new List<ChatRequestMessage>(){
new ChatRequestSystemMessage(
"You are a helpful assistant that help users to find information about traveling, " +
"how to get to places and the different transportations options. You care about the" +
"environment and you always have that in mind when answering inqueries."
),
new ChatRequestUserMessage("When is the next flight from Miami to Seattle?")
};
requestOptions = new ChatCompletionsOptions(chatHistory);
requestOptions.Tools.Add(getFlightTool);
requestOptions.ToolChoice = ChatCompletionsToolChoice.Auto;
response = client.Complete(requestOptions);
Du kan kontrollera svaret för att ta reda på om ett verktyg behöver anropas. Kontrollera avslutsorsaken för att avgöra om verktyget ska anropas. Kom ihåg att flera verktygstyper kan anges. Det här exemplet visar ett verktyg av typen function.
var responseMessage = response.Value;
var toolsCall = responseMessage.ToolCalls;
Console.WriteLine($"Finish reason: {response.Value.Choices[0].FinishReason}");
Console.WriteLine($"Tool call: {toolsCall[0].Id}");
Om du vill fortsätta lägger du till det här meddelandet i chatthistoriken:
requestOptions.Messages.Add(new ChatRequestAssistantMessage(response.Value));
Nu är det dags att anropa rätt funktion för att hantera verktygsanropet. Följande kodfragment itererar över alla verktygsanrop som anges i svaret och anropar motsvarande funktion med lämpliga parametrar. Svaret läggs också till i chatthistoriken.
foreach (ChatCompletionsToolCall tool in toolsCall)
{
if (tool is ChatCompletionsFunctionToolCall functionTool)
{
// Get the tool details:
string callId = functionTool.Id;
string toolName = functionTool.Name;
string toolArgumentsString = functionTool.Arguments;
Dictionary<string, object> toolArguments = JsonSerializer.Deserialize<Dictionary<string, object>>(toolArgumentsString);
// Here you have to call the function defined. In this particular example we use
// reflection to find the method we definied before in an static class called
// `ChatCompletionsExamples`. Using reflection allows us to call a function
// by string name. Notice that this is just done for demonstration purposes as a
// simple way to get the function callable from its string name. Then we can call
// it with the corresponding arguments.
var flags = BindingFlags.Instance | BindingFlags.Public | BindingFlags.NonPublic | BindingFlags.Static;
string toolResponse = (string)typeof(ChatCompletionsExamples).GetMethod(toolName, flags).Invoke(null, toolArguments.Values.Cast<object>().ToArray());
Console.WriteLine("->", toolResponse);
requestOptions.Messages.Add(new ChatRequestToolMessage(toolResponse, callId));
}
else
throw new Exception("Unsupported tool type");
}
Visa svaret från modellen:
response = client.Complete(requestOptions);
Tillämpa innehållssäkerhet
Azure AI-modellinferens-API:et stöder Azure AI-innehållssäkerhet. När du använder distributioner med Azure AI-innehållssäkerhet aktiverad passerar indata och utdata genom en uppsättning klassificeringsmodeller som syftar till att identifiera och förhindra utdata från skadligt innehåll. Systemet för innehållsfiltrering identifierar och vidtar åtgärder för specifika kategorier av potentiellt skadligt innehåll i både inkommande prompter och slutföranden av utdata.
I följande exempel visas hur du hanterar händelser när modellen identifierar skadligt innehåll i indataprompten och innehållssäkerhet är aktiverat.
try
{
requestOptions = new ChatCompletionsOptions()
{
Messages = {
new ChatRequestSystemMessage("You are an AI assistant that helps people find information."),
new ChatRequestUserMessage(
"Chopping tomatoes and cutting them into cubes or wedges are great ways to practice your knife skills."
),
},
};
response = client.Complete(requestOptions);
Console.WriteLine(response.Value.Content);
}
catch (RequestFailedException ex)
{
if (ex.ErrorCode == "content_filter")
{
Console.WriteLine($"Your query has trigger Azure Content Safety: {ex.Message}");
}
else
{
throw;
}
}
Dricks
Mer information om hur du kan konfigurera och kontrollera säkerhetsinställningar för Azure AI-innehåll finns i säkerhetsdokumentationen för Azure AI-innehåll.
Använda chattavslutningar med bilder
Vissa modeller kan resonera mellan text och bilder och generera textavslut baserat på båda typerna av indata. I det här avsnittet utforskar du funktionerna i Vissa modeller för vision på ett chattsätt:
Viktigt!
Vissa modeller stöder bara en bild för varje tur i chattkonversationen och endast den sista bilden behålls i kontext. Om du lägger till flera bilder resulterar det i ett fel.
Om du vill se den här funktionen laddar du ned en bild och kodar informationen som base64 sträng. Resulterande data bör finnas i en data-URL:
string imageUrl = "https://news.microsoft.com/source/wp-content/uploads/2024/04/The-Phi-3-small-language-models-with-big-potential-1-1900x1069.jpg";
string imageFormat = "jpeg";
HttpClient httpClient = new HttpClient();
httpClient.DefaultRequestHeaders.Add("User-Agent", "Mozilla/5.0");
byte[] imageBytes = httpClient.GetByteArrayAsync(imageUrl).Result;
string imageBase64 = Convert.ToBase64String(imageBytes);
string dataUrl = $"data:image/{imageFormat};base64,{imageBase64}";
Visualisera bilden:
Skapa nu en begäran om att slutföra chatten med avbildningen:
ChatCompletionsOptions requestOptions = new ChatCompletionsOptions()
{
Messages = {
new ChatRequestSystemMessage("You are an AI assistant that helps people find information."),
new ChatRequestUserMessage([
new ChatMessageTextContentItem("Which conclusion can be extracted from the following chart?"),
new ChatMessageImageContentItem(new Uri(dataUrl))
]),
},
MaxTokens=2048,
};
var response = client.Complete(requestOptions);
Console.WriteLine(response.Value.Content);
Svaret är följande, där du kan se modellens användningsstatistik:
Console.WriteLine($"{response.Value.Role}: {response.Value.Content}");
Console.WriteLine($"Model: {response.Value.Model}");
Console.WriteLine("Usage:");
Console.WriteLine($"\tPrompt tokens: {response.Value.Usage.PromptTokens}");
Console.WriteLine($"\tTotal tokens: {response.Value.Usage.TotalTokens}");
Console.WriteLine($"\tCompletion tokens: {response.Value.Usage.CompletionTokens}");
ASSISTANT: The chart illustrates that larger models tend to perform better in quality, as indicated by their size in billions of parameters. However, there are exceptions to this trend, such as Phi-3-medium and Phi-3-small, which outperform smaller models in quality. This suggests that while larger models generally have an advantage, there might be other factors at play that influence a model's performance.
Model: mistral-large-2407
Usage:
Prompt tokens: 2380
Completion tokens: 126
Total tokens: 2506
Viktigt!
Objekt markerade (förhandsversion) i den här artikeln är för närvarande i offentlig förhandsversion. Den här förhandsversionen tillhandahålls utan ett serviceavtal och vi rekommenderar det inte för produktionsarbetsbelastningar. Vissa funktioner kanske inte stöds eller kan vara begränsade. Mer information finns i Kompletterande villkor för användning av Microsoft Azure-förhandsversioner.
Den här artikeln beskriver hur du använder API:et för chattslutsättningar med modeller som distribuerats till Azure AI-modellinferens i Azure AI-tjänster.
Förutsättningar
Om du vill använda modeller för chattkomplettering i ditt program behöver du:
En Azure-prenumeration Om du använder GitHub-modeller kan du uppgradera din upplevelse och skapa en Azure-prenumeration i processen. Läs Uppgradera från GitHub-modeller till Azure AI-modellinferens om så är fallet.
En Azure AI-tjänstresurs. Mer information finns i Skapa en Azure AI Services-resurs.
Slutpunkts-URL:en och nyckeln.
- En modelldistribution för chattavslut. Om du inte har någon läser du Lägg till och konfigurera modeller i Azure AI-tjänster för att lägga till en modell för chattavslut i resursen.
Använda chattens slutföranden
Om du vill använda textbäddningarna använder du den väg /chat/completions som läggs till i bas-URL:en tillsammans med dina autentiseringsuppgifter som anges i api-key.
Authorization -huvudet stöds också med formatet Bearer <key>.
POST https://<resource>.services.ai.azure.com/models/chat/completions?api-version=2024-05-01-preview
Content-Type: application/json
api-key: <key>
Om du har konfigurerat resursen med Stöd för Microsoft Entra-ID skickar du token i Authorization rubriken:
POST https://<resource>.services.ai.azure.com/models/chat/completions?api-version=2024-05-01-preview
Content-Type: application/json
Authorization: Bearer <token>
Skapa en begäran om att chatten ska slutföras
I följande exempel visas hur du kan skapa en grundläggande begäran om att slutföra chatten till modellen.
{
"model": "mistral-large-2407",
"messages": [
{
"role": "system",
"content": "You are a helpful assistant."
},
{
"role": "user",
"content": "How many languages are in the world?"
}
]
}
Kommentar
Vissa modeller stöder inte systemmeddelanden (role="system"). När du använder AZURE AI-modellinferens-API:et översätts systemmeddelanden till användarmeddelanden, vilket är den närmaste tillgängliga funktionen. Den här översättningen erbjuds för enkelhetens skull, men det är viktigt att du kontrollerar att modellen följer anvisningarna i systemmeddelandet med rätt konfidensnivå.
Svaret är följande, där du kan se modellens användningsstatistik:
{
"id": "0a1234b5de6789f01gh2i345j6789klm",
"object": "chat.completion",
"created": 1718726686,
"model": "mistral-large-2407",
"choices": [
{
"index": 0,
"message": {
"role": "assistant",
"content": "As of now, it's estimated that there are about 7,000 languages spoken around the world. However, this number can vary as some languages become extinct and new ones develop. It's also important to note that the number of speakers can greatly vary between languages, with some having millions of speakers and others only a few hundred.",
"tool_calls": null
},
"finish_reason": "stop",
"logprobs": null
}
],
"usage": {
"prompt_tokens": 19,
"total_tokens": 91,
"completion_tokens": 72
}
}
usage Granska avsnittet i svaret för att se antalet token som används för prompten, det totala antalet token som genererats och antalet token som används för slutförandet.
Strömma innehåll
Som standard returnerar API:et för slutförande hela det genererade innehållet i ett enda svar. Om du genererar långa slutföranden kan det ta många sekunder att vänta på svaret.
Du kan strömma innehållet för att hämta det när det genereras. Med strömmande innehåll kan du börja bearbeta slutförandet när innehållet blir tillgängligt. Det här läget returnerar ett objekt som strömmar tillbaka svaret som databaserade serverutskickade händelser. Extrahera segment från deltafältet i stället för meddelandefältet.
{
"model": "mistral-large-2407",
"messages": [
{
"role": "system",
"content": "You are a helpful assistant."
},
{
"role": "user",
"content": "How many languages are in the world?"
}
],
"stream": true,
"temperature": 0,
"top_p": 1,
"max_tokens": 2048
}
Du kan visualisera hur strömning genererar innehåll:
{
"id": "23b54589eba14564ad8a2e6978775a39",
"object": "chat.completion.chunk",
"created": 1718726371,
"model": "mistral-large-2407",
"choices": [
{
"index": 0,
"delta": {
"role": "assistant",
"content": ""
},
"finish_reason": null,
"logprobs": null
}
]
}
Det sista meddelandet i strömmen har finish_reason angetts, vilket anger orsaken till att genereringsprocessen stoppas.
{
"id": "23b54589eba14564ad8a2e6978775a39",
"object": "chat.completion.chunk",
"created": 1718726371,
"model": "mistral-large-2407",
"choices": [
{
"index": 0,
"delta": {
"content": ""
},
"finish_reason": "stop",
"logprobs": null
}
],
"usage": {
"prompt_tokens": 19,
"total_tokens": 91,
"completion_tokens": 72
}
}
Utforska fler parametrar som stöds av slutsatsdragningsklienten
Utforska andra parametrar som du kan ange i slutsatsdragningsklienten. En fullständig lista över alla parametrar som stöds och deras motsvarande dokumentation finns i API-referensen för Azure AI-modellinferens.
{
"model": "mistral-large-2407",
"messages": [
{
"role": "system",
"content": "You are a helpful assistant."
},
{
"role": "user",
"content": "How many languages are in the world?"
}
],
"presence_penalty": 0.1,
"frequency_penalty": 0.8,
"max_tokens": 2048,
"stop": ["<|endoftext|>"],
"temperature" :0,
"top_p": 1,
"response_format": { "type": "text" }
}
{
"id": "0a1234b5de6789f01gh2i345j6789klm",
"object": "chat.completion",
"created": 1718726686,
"model": "mistral-large-2407",
"choices": [
{
"index": 0,
"message": {
"role": "assistant",
"content": "As of now, it's estimated that there are about 7,000 languages spoken around the world. However, this number can vary as some languages become extinct and new ones develop. It's also important to note that the number of speakers can greatly vary between languages, with some having millions of speakers and others only a few hundred.",
"tool_calls": null
},
"finish_reason": "stop",
"logprobs": null
}
],
"usage": {
"prompt_tokens": 19,
"total_tokens": 91,
"completion_tokens": 72
}
}
Vissa modeller stöder inte JSON-utdataformatering. Du kan alltid uppmana modellen att generera JSON-utdata. Sådana utdata är dock inte garanterade att vara giltiga JSON.
Om du vill skicka en parameter som inte finns med i listan över parametrar som stöds kan du skicka den till den underliggande modellen med hjälp av extra parametrar. Se Skicka extra parametrar till modellen.
Skapa JSON-utdata
Vissa modeller kan skapa JSON-utdata. Ange response_format till json_object för att aktivera JSON-läge och garantera att meddelandet som modellen genererar är giltigt JSON. Du måste också instruera modellen att skapa JSON själv via ett system- eller användarmeddelande. Dessutom kan meddelandeinnehållet vara delvis avskuret om finish_reason="length", vilket indikerar att genereringen överskred max_tokens eller att konversationen överskred den maximala kontextlängden.
{
"model": "mistral-large-2407",
"messages": [
{
"role": "system",
"content": "You are a helpful assistant that always generate responses in JSON format, using the following format: { \"answer\": \"response\" }"
},
{
"role": "user",
"content": "How many languages are in the world?"
}
],
"response_format": { "type": "json_object" }
}
{
"id": "0a1234b5de6789f01gh2i345j6789klm",
"object": "chat.completion",
"created": 1718727522,
"model": "mistral-large-2407",
"choices": [
{
"index": 0,
"message": {
"role": "assistant",
"content": "{\"answer\": \"There are approximately 7,117 living languages in the world today, according to the latest estimates. However, this number can vary as some languages become extinct and others are newly discovered or classified.\"}",
"tool_calls": null
},
"finish_reason": "stop",
"logprobs": null
}
],
"usage": {
"prompt_tokens": 39,
"total_tokens": 87,
"completion_tokens": 48
}
}
Skicka extra parametrar till modellen
Med AZURE AI Model Inference API kan du skicka extra parametrar till modellen. Följande kodexempel visar hur du skickar den extra parametern logprobs till modellen.
POST https://<resource>.services.ai.azure.com/models/chat/completions?api-version=2024-05-01-preview
Authorization: Bearer <TOKEN>
Content-Type: application/json
extra-parameters: pass-through
{
"model": "mistral-large-2407",
"messages": [
{
"role": "system",
"content": "You are a helpful assistant."
},
{
"role": "user",
"content": "How many languages are in the world?"
}
],
"logprobs": true
}
Innan du skickar extra parametrar till Azure AI-modellinferens-API:et kontrollerar du att din modell stöder dessa extra parametrar. När begäran görs till den underliggande modellen skickas rubriken extra-parameters till modellen med värdet pass-through. Det här värdet anger att slutpunkten ska skicka de extra parametrarna till modellen. Användning av extra parametrar med modellen garanterar inte att modellen faktiskt kan hantera dem. Läs modellens dokumentation för att förstå vilka extra parametrar som stöds.
Använda verktyg
Vissa modeller stöder användning av verktyg, vilket kan vara en extraordinär resurs när du behöver avlasta specifika uppgifter från språkmodellen och i stället förlitar dig på ett mer deterministiskt system eller till och med en annan språkmodell. Med AZURE AI Model Inference API kan du definiera verktyg på följande sätt.
I följande kodexempel skapas en verktygsdefinition som kan titta från flyginformation från två olika städer.
{
"type": "function",
"function": {
"name": "get_flight_info",
"description": "Returns information about the next flight between two cities. This includes the name of the airline, flight number and the date and time of the next flight",
"parameters": {
"type": "object",
"properties": {
"origin_city": {
"type": "string",
"description": "The name of the city where the flight originates"
},
"destination_city": {
"type": "string",
"description": "The flight destination city"
}
},
"required": [
"origin_city",
"destination_city"
]
}
}
}
I det här exemplet är funktionens utdata att det inte finns några tillgängliga flyg för den valda rutten, men användaren bör överväga att ta ett tåg.
Kommentar
Cohere-modeller kräver att ett verktygs svar är ett giltigt JSON-innehåll formaterat som en sträng. När du skapar meddelanden av typen Verktyg kontrollerar du att svaret är en giltig JSON-sträng.
Uppmana modellen att boka flyg med hjälp av den här funktionen:
{
"model": "mistral-large-2407",
"messages": [
{
"role": "system",
"content": "You are a helpful assistant that help users to find information about traveling, how to get to places and the different transportations options. You care about the environment and you always have that in mind when answering inqueries"
},
{
"role": "user",
"content": "When is the next flight from Miami to Seattle?"
}
],
"tool_choice": "auto",
"tools": [
{
"type": "function",
"function": {
"name": "get_flight_info",
"description": "Returns information about the next flight between two cities. This includes the name of the airline, flight number and the date and time of the next flight",
"parameters": {
"type": "object",
"properties": {
"origin_city": {
"type": "string",
"description": "The name of the city where the flight originates"
},
"destination_city": {
"type": "string",
"description": "The flight destination city"
}
},
"required": [
"origin_city",
"destination_city"
]
}
}
}
]
}
Du kan kontrollera svaret för att ta reda på om ett verktyg behöver anropas. Kontrollera avslutsorsaken för att avgöra om verktyget ska anropas. Kom ihåg att flera verktygstyper kan anges. Det här exemplet visar ett verktyg av typen function.
{
"id": "0a1234b5de6789f01gh2i345j6789klm",
"object": "chat.completion",
"created": 1718726007,
"model": "mistral-large-2407",
"choices": [
{
"index": 0,
"message": {
"role": "assistant",
"content": "",
"tool_calls": [
{
"id": "abc0dF1gh",
"type": "function",
"function": {
"name": "get_flight_info",
"arguments": "{\"origin_city\": \"Miami\", \"destination_city\": \"Seattle\"}",
"call_id": null
}
}
]
},
"finish_reason": "tool_calls",
"logprobs": null
}
],
"usage": {
"prompt_tokens": 190,
"total_tokens": 226,
"completion_tokens": 36
}
}
Om du vill fortsätta lägger du till det här meddelandet i chatthistoriken:
Nu är det dags att anropa rätt funktion för att hantera verktygsanropet. Följande kodfragment itererar över alla verktygsanrop som anges i svaret och anropar motsvarande funktion med lämpliga parametrar. Svaret läggs också till i chatthistoriken.
Visa svaret från modellen:
{
"model": "mistral-large-2407",
"messages": [
{
"role": "system",
"content": "You are a helpful assistant that help users to find information about traveling, how to get to places and the different transportations options. You care about the environment and you always have that in mind when answering inqueries"
},
{
"role": "user",
"content": "When is the next flight from Miami to Seattle?"
},
{
"role": "assistant",
"content": "",
"tool_calls": [
{
"id": "abc0DeFgH",
"type": "function",
"function": {
"name": "get_flight_info",
"arguments": "{\"origin_city\": \"Miami\", \"destination_city\": \"Seattle\"}",
"call_id": null
}
}
]
},
{
"role": "tool",
"content": "{ \"info\": \"There are no flights available from Miami to Seattle. You should take a train, specially if it helps to reduce CO2 emissions.\" }",
"tool_call_id": "abc0DeFgH"
}
],
"tool_choice": "auto",
"tools": [
{
"type": "function",
"function": {
"name": "get_flight_info",
"description": "Returns information about the next flight between two cities. This includes the name of the airline, flight number and the date and time of the next flight",
"parameters":{
"type": "object",
"properties": {
"origin_city": {
"type": "string",
"description": "The name of the city where the flight originates"
},
"destination_city": {
"type": "string",
"description": "The flight destination city"
}
},
"required": ["origin_city", "destination_city"]
}
}
}
]
}
Tillämpa innehållssäkerhet
Azure AI-modellinferens-API:et stöder Azure AI-innehållssäkerhet. När du använder distributioner med Azure AI-innehållssäkerhet aktiverad passerar indata och utdata genom en uppsättning klassificeringsmodeller som syftar till att identifiera och förhindra utdata från skadligt innehåll. Systemet för innehållsfiltrering identifierar och vidtar åtgärder för specifika kategorier av potentiellt skadligt innehåll i både inkommande prompter och slutföranden av utdata.
I följande exempel visas hur du hanterar händelser när modellen identifierar skadligt innehåll i indataprompten och innehållssäkerhet är aktiverat.
{
"model": "mistral-large-2407",
"messages": [
{
"role": "system",
"content": "You are an AI assistant that helps people find information."
},
{
"role": "user",
"content": "Chopping tomatoes and cutting them into cubes or wedges are great ways to practice your knife skills."
}
]
}
{
"error": {
"message": "The response was filtered due to the prompt triggering Microsoft's content management policy. Please modify your prompt and retry.",
"type": null,
"param": "prompt",
"code": "content_filter",
"status": 400
}
}
Dricks
Mer information om hur du kan konfigurera och kontrollera säkerhetsinställningar för Azure AI-innehåll finns i säkerhetsdokumentationen för Azure AI-innehåll.
Använda chattavslutningar med bilder
Vissa modeller kan resonera mellan text och bilder och generera textavslut baserat på båda typerna av indata. I det här avsnittet utforskar du funktionerna i Vissa modeller för vision på ett chattsätt:
Viktigt!
Vissa modeller stöder bara en bild för varje tur i chattkonversationen och endast den sista bilden behålls i kontext. Om du lägger till flera bilder resulterar det i ett fel.
Om du vill se den här funktionen laddar du ned en bild och kodar informationen som base64 sträng. Resulterande data bör finnas i en data-URL:
Dricks
Du måste skapa data-URL:en med hjälp av ett skript- eller programmeringsspråk. I den här självstudien används den här exempelbilden i JPEG-format. En data-URL har följande format: data:image/jpg;base64,0xABCDFGHIJKLMNOPQRSTUVWXYZ....
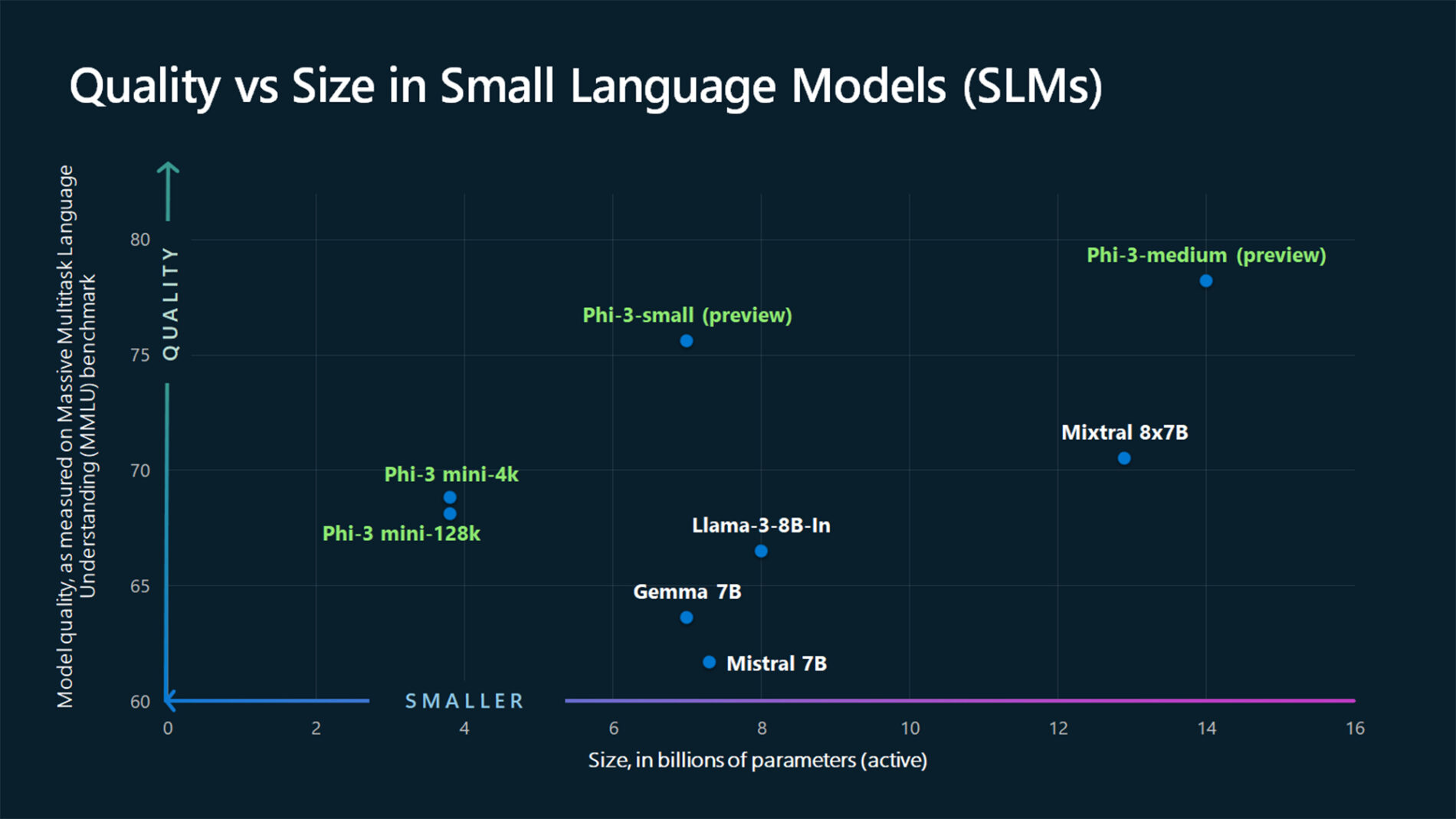{kind=link}
Visualisera bilden:
Skapa nu en begäran om att slutföra chatten med avbildningen:
{
"model": "phi-3.5-vision-instruct",
"messages": [
{
"role": "user",
"content": [
{
"type": "text",
"text": "Which peculiar conclusion about LLMs and SLMs can be extracted from the following chart?"
},
{
"type": "image_url",
"image_url": {
"url": "data:image/jpg;base64,0xABCDFGHIJKLMNOPQRSTUVWXYZ..."
}
}
]
}
],
"temperature": 0,
"top_p": 1,
"max_tokens": 2048
}
Svaret är följande, där du kan se modellens användningsstatistik:
{
"id": "0a1234b5de6789f01gh2i345j6789klm",
"object": "chat.completion",
"created": 1718726686,
"model": "phi-3.5-vision-instruct",
"choices": [
{
"index": 0,
"message": {
"role": "assistant",
"content": "The chart illustrates that larger models tend to perform better in quality, as indicated by their size in billions of parameters. However, there are exceptions to this trend, such as Phi-3-medium and Phi-3-small, which outperform smaller models in quality. This suggests that while larger models generally have an advantage, there might be other factors at play that influence a model's performance.",
"tool_calls": null
},
"finish_reason": "stop",
"logprobs": null
}
],
"usage": {
"prompt_tokens": 2380,
"completion_tokens": 126,
"total_tokens": 2506
}
}