Anslutningsapp för dedikerad SQL-pool i Azure Synapse för Apache Spark
Introduktion
Azure Synapse Dedicated SQL Pool Connector för Apache Spark i Azure Synapse Analytics möjliggör effektiv överföring av stora datamängder mellan Apache Spark-körningen och den dedikerade SQL-poolen. Anslutningsappen levereras som ett standardbibliotek med Azure Synapse-arbetsytan. Anslutningsappen implementeras med hjälp av Scala språket. Anslutningsappen stöder Scala och Python. Om du vill använda anslutningsappen med andra språkval för notebook-filer använder du spark magic-kommandot - %%spark.
På hög nivå tillhandahåller anslutningsappen följande funktioner:
- Läs från Azure Synapse Dedicated SQL-pool:
- Läs stora datamängder från Synapse Dedicated SQL-pooltabeller (interna och externa) och vyer.
- Omfattande stöd för push-nedtryckning av predikat, där filter på DataFrame mappas till motsvarande SQL-predikat-push-nedtryckning.
- Stöd för kolumnrensning.
- Stöd för att skicka frågor nedåt.
- Skriv till Azure Synapse Dedicated SQL-pool:
- Mata in stora volymdata till interna och externa tabelltyper.
- Stöder följande inställningar för dataramsparläge:
AppendErrorIfExistsIgnoreOverwrite
- Skriv till extern tabelltyp stöder parquet- och avgränsat textfilformat (exempel – CSV).
- För att skriva data till interna tabeller använder anslutningsappen nu COPY-instruktionen i stället för CETAS/CTAS-metoden.
- Förbättringar för att optimera prestanda för skrivdataflöde från slutpunkt till slutpunkt.
- Introducerar ett valfritt anropshandtag (ett Scala-funktionsargument) som klienter kan använda för att ta emot mått efter skrivning.
- Några exempel är – antal poster, varaktighet för att slutföra en viss åtgärd och felorsak.
Orkestreringsmetod
Lästa
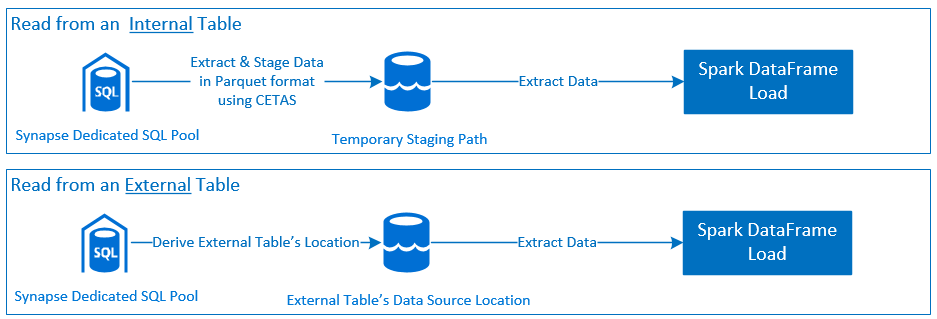
Skriva
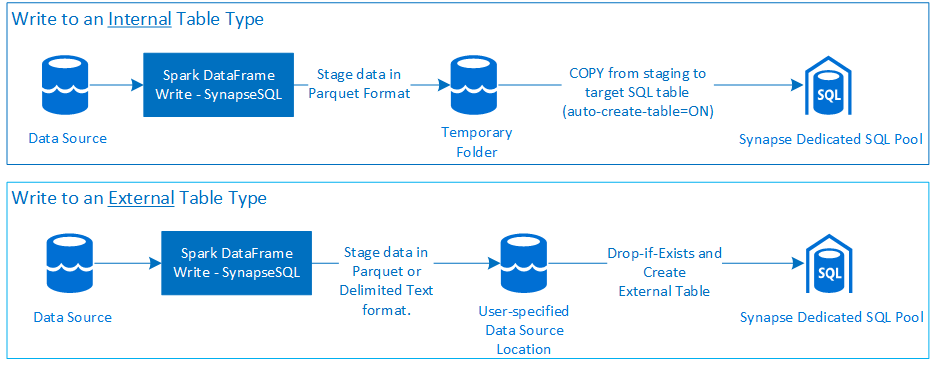
Förutsättningar
Krav som att konfigurera nödvändiga Azure-resurser och steg för att konfigurera dem beskrivs i det här avsnittet.
Azure-resurser
Granska och konfigurera följande beroende Azure-resurser:
- Azure Data Lake Storage – används som primärt lagringskonto för Azure Synapse-arbetsytan.
- Azure Synapse Workspace – skapa notebook-filer, skapa och distribuera DataFrame-baserade arbetsflöden för inkommande utgående.
- Dedikerad SQL-pool (tidigare SQL DW) – tillhandahåller företagsfunktioner Datalagring.
- Azure Synapse Serverless Spark-pool – Spark-körning där jobben körs som Spark-program.
Förbereda databasen
Anslut till Synapse Dedicated SQL Pool-databasen och kör följande installationsinstruktioner:
Skapa en databasanvändare som är mappad till Microsoft Entra-användaridentiteten som används för att logga in på Azure Synapse-arbetsytan.
CREATE USER [username@domain.com] FROM EXTERNAL PROVIDER;Skapa ett schema där tabeller ska definieras, så att anslutningsappen kan skriva till och läsa från respektive tabeller.
CREATE SCHEMA [<schema_name>];
Autentisering
Microsoft Entra ID-baserad autentisering
Microsoft Entra ID-baserad autentisering är en integrerad autentiseringsmetod. Användaren måste logga in på Azure Synapse Analytics-arbetsytan.
Grundläggande autentisering
En grundläggande autentiseringsmetod kräver att användaren konfigurerar username och password alternativ. Läs avsnittet – Konfigurationsalternativ för att lära dig mer om relevanta konfigurationsparametrar för att läsa från och skriva till tabeller i Azure Synapse Dedicated SQL Pool.
Auktorisering
Azure Data Lake Storage Gen2
Det finns två sätt att bevilja åtkomstbehörigheter till Azure Data Lake Storage Gen2 – Lagringskonto:
- Rollbaserad åtkomstkontrollroll – Rollen Storage Blob Data-deltagare
- Tilldela
Storage Blob Data Contributor Roleger användaren behörighet att läsa, skriva och ta bort från Azure Storage Blob Containers. - RBAC erbjuder en grov kontrollmetod på containernivå.
- Tilldela
- Åtkomstkontrollistor (ACL)
- ACL-metoden möjliggör detaljerade kontroller över specifika sökvägar och/eller filer under en viss mapp.
- ACL-kontroller tillämpas inte om användaren redan har beviljats behörigheter med RBAC-metoden.
- Det finns två breda typer av ACL-behörigheter:
- Åtkomstbehörigheter (tillämpas på en viss nivå eller ett objekt).
- Standardbehörigheter (tillämpas automatiskt för alla underordnade objekt när de skapas).
- Typ av behörigheter är:
Executegör det möjligt att bläddra i eller navigera i mapphierarkierna.Readgör det möjligt att läsa.Writegör det möjligt att skriva.
- Det är viktigt att konfigurera ACL:er så att anslutningsappen kan skriva och läsa från lagringsplatserna.
Kommentar
Om du vill köra notebook-filer med synapse-arbetsytepipelines måste du även bevilja ovanstående åtkomstbehörigheter till Standardhanterad identitet för Synapse Workspace. Arbetsytans standardnamn för hanterad identitet är samma som namnet på arbetsytan.
Om du vill använda Synapse-arbetsytan med skyddade lagringskonton måste en hanterad privat slutpunkt konfigureras från notebook-filen. Den hanterade privata slutpunkten måste godkännas från ADLS Gen2-lagringskontots
Private endpoint connectionsavsnitt i fönstretNetworking.
Dedikerad SQL-pool i Azure Synapse
För att möjliggöra lyckad interaktion med Azure Synapse Dedicated SQL-pool krävs följande auktorisering om du inte är en användare som också har konfigurerats som en Active Directory Admin på den dedikerade SQL-slutpunkten:
Lässcenario
Bevilja användaren
db_exporterden system lagrade procedurensp_addrolemember.EXEC sp_addrolemember 'db_exporter', [<your_domain_user>@<your_domain_name>.com];
Skrivscenario
- Connector använder kommandot COPY för att skriva data från mellanlagring till den interna tabellens hanterade plats.
Konfigurera nödvändiga behörigheter som beskrivs här.
Följande är ett snabbåtkomstfragment av samma:
--Make sure your user has the permissions to CREATE tables in the [dbo] schema GRANT CREATE TABLE TO [<your_domain_user>@<your_domain_name>.com]; GRANT ALTER ON SCHEMA::<target_database_schema_name> TO [<your_domain_user>@<your_domain_name>.com]; --Make sure your user has ADMINISTER DATABASE BULK OPERATIONS permissions GRANT ADMINISTER DATABASE BULK OPERATIONS TO [<your_domain_user>@<your_domain_name>.com]; --Make sure your user has INSERT permissions on the target table GRANT INSERT ON <your_table> TO [<your_domain_user>@<your_domain_name>.com]
- Connector använder kommandot COPY för att skriva data från mellanlagring till den interna tabellens hanterade plats.
API-dokumentation
Dokumentation om Azure Synapse Dedicated SQL Pool Connector för Apache Spark – API.
Konfigurationsalternativ
Om du vill starta och samordna läs- eller skrivåtgärden förväntar sig anslutningsappen vissa konfigurationsparametrar. Objektdefinitionen – com.microsoft.spark.sqlanalytics.utils.Constants innehåller en lista över standardiserade konstanter för varje parameternyckel.
Följande är listan över konfigurationsalternativ baserat på användningsscenario:
- Läsa med Microsoft Entra ID-baserad autentisering
- Autentiseringsuppgifterna mappas automatiskt och användaren behöver inte ange specifika konfigurationsalternativ.
- Argumentet tabellnamn i tre delar för
synapsesqlmetoden krävs för att läsa från respektive tabell i Azure Synapse Dedicated SQL Pool.
- Läsa med grundläggande autentisering
- Azure Synapse Dedikerad SQL-slutpunkt
Constants.SERVER– Synapse Dedikerad SQL-poolslutpunkt (server-FQDN)Constants.USER– SQL-användarnamn.Constants.PASSWORD– SQL-användarlösenord.
- Slutpunkt för Azure Data Lake Storage (Gen 2) – Mellanlagringsmappar
Constants.DATA_SOURCE– Lagringssökvägen som angetts för datakällans platsparameter används för mellanlagring av data.
- Azure Synapse Dedikerad SQL-slutpunkt
- Skriva med Microsoft Entra ID-baserad autentisering
- Azure Synapse Dedikerad SQL-slutpunkt
- Som standard härleder Anslutningsappen slutpunkten för Synapse Dedicated SQL med hjälp av databasnamnet som anges i
synapsesqlmetodens tabellnamnparameter i tre delar. - Alternativt kan användarna använda alternativet
Constants.SERVERför att ange sql-slutpunkten. Se till att slutpunkten är värd för motsvarande databas med respektive schema.
- Som standard härleder Anslutningsappen slutpunkten för Synapse Dedicated SQL med hjälp av databasnamnet som anges i
- Slutpunkt för Azure Data Lake Storage (Gen 2) – Mellanlagringsmappar
- För intern tabelltyp:
- Konfigurera antingen
Constants.TEMP_FOLDERellerConstants.DATA_SOURCEalternativ. - Om användaren väljer att ange
Constants.DATA_SOURCEalternativet härleds mellanlagringsmappenlocationmed hjälp av värdet från DataSource. - Om båda anges
Constants.TEMP_FOLDERanvänds alternativvärdet. - Om det inte finns något mellanlagringsmappsalternativ härleder anslutningsappen ett baserat på körningskonfigurationen –
spark.sqlanalyticsconnector.stagingdir.prefix.
- Konfigurera antingen
- För extern tabelltyp:
Constants.DATA_SOURCEär ett obligatoriskt konfigurationsalternativ.- Anslutningsappen använder lagringssökvägen som angetts för datakällans platsparameter i kombination med
locationargumentet tillsynapsesqlmetoden och härleder den absoluta sökvägen för att bevara externa tabelldata. locationOm argumentet tillsynapsesqlmetoden inte har angetts härleds platsvärdet som<base_path>/dbName/schemaName/tableName.
- För intern tabelltyp:
- Azure Synapse Dedikerad SQL-slutpunkt
- Skriva med grundläggande autentisering
- Azure Synapse Dedikerad SQL-slutpunkt
Constants.SERVER– Synapse Dedikerad SQL-poolslutpunkt (server-FQDN).Constants.USER– SQL-användarnamn.Constants.PASSWORD– SQL-användarlösenord.Constants.STAGING_STORAGE_ACCOUNT_KEYär associerad med lagringskonto som är värdarConstants.TEMP_FOLDERS(endast interna tabelltyper) ellerConstants.DATA_SOURCE.
- Slutpunkt för Azure Data Lake Storage (Gen 2) – Mellanlagringsmappar
- Grundläggande autentiseringsuppgifter för SQL gäller inte för åtkomst till lagringsslutpunkter.
- Se därför till att tilldela relevanta behörigheter för lagringsåtkomst enligt beskrivningen i avsnittet Azure Data Lake Storage Gen2.
- Azure Synapse Dedikerad SQL-slutpunkt
Kodmallar
I det här avsnittet beskrivs referenskodmallar som beskriver hur du använder och anropar Azure Synapse Dedicated SQL Pool Connector för Apache Spark.
Kommentar
Använda anslutningsappen i Python-
- Anslutningsappen stöds endast i Python för Spark 3. För Spark 2.4 (stöds inte) kan vi använda Scala-anslutnings-API:et för att interagera med innehåll från en DataFrame i PySpark med hjälp av DataFrame.createOrReplaceTempView eller DataFrame.createOrReplaceGlobalTempView. Se Avsnitt – Använda materialiserade data mellan celler.
- Referensen för återanrop är inte tillgänglig i Python.
Läsa från Azure Synapse Dedicated SQL-pool
Läsbegäran – synapsesql metodsignatur
Läsa från en tabell med Microsoft Entra ID-baserad autentisering
//Use case is to read data from an internal table in Synapse Dedicated SQL Pool DB
//Azure Active Directory based authentication approach is preferred here.
import org.apache.spark.sql.DataFrame
import com.microsoft.spark.sqlanalytics.utils.Constants
import org.apache.spark.sql.SqlAnalyticsConnector._
//Read from existing internal table
val dfToReadFromTable:DataFrame = spark.read.
//If `Constants.SERVER` is not provided, the `<database_name>` from the three-part table name argument
//to `synapsesql` method is used to infer the Synapse Dedicated SQL End Point.
option(Constants.SERVER, "<sql-server-name>.sql.azuresynapse.net").
//Defaults to storage path defined in the runtime configurations
option(Constants.TEMP_FOLDER, "abfss://<container_name>@<storage_account_name>.dfs.core.windows.net/<some_base_path_for_temporary_staging_folders>").
//Three-part table name from where data will be read.
synapsesql("<database_name>.<schema_name>.<table_name>").
//Column-pruning i.e., query select column values.
select("<some_column_1>", "<some_column_5>", "<some_column_n>").
//Push-down filter criteria that gets translated to SQL Push-down Predicates.
filter(col("Title").startsWith("E")).
//Fetch a sample of 10 records
limit(10)
//Show contents of the dataframe
dfToReadFromTable.show()
Läsa från en fråga med hjälp av Microsoft Entra ID-baserad autentisering
Kommentar
Begränsningar vid läsning från fråga:
- Tabellnamn och fråga kan inte anges samtidigt.
- Endast utvalda frågor tillåts. DDL- och DML-SQL:er tillåts inte.
- Alternativen välj och filtrera på dataramen skickas inte ned till den dedikerade SQL-poolen när en fråga har angetts.
- Läsning från en fråga är endast tillgängligt i Spark 3.
//Use case is to read data from an internal table in Synapse Dedicated SQL Pool DB
//Azure Active Directory based authentication approach is preferred here.
import org.apache.spark.sql.DataFrame
import com.microsoft.spark.sqlanalytics.utils.Constants
import org.apache.spark.sql.SqlAnalyticsConnector._
// Read from a query
// Query can be provided either as an argument to synapsesql or as a Constant - Constants.QUERY
val dfToReadFromQueryAsOption:DataFrame = spark.read.
// Name of the SQL Dedicated Pool or database where to run the query
// Database can be specified as a Spark Config - spark.sqlanalyticsconnector.dw.database or as a Constant - Constants.DATABASE
option(Constants.DATABASE, "<database_name>").
//If `Constants.SERVER` is not provided, the `<database_name>` from the three-part table name argument
//to `synapsesql` method is used to infer the Synapse Dedicated SQL End Point.
option(Constants.SERVER, "<sql-server-name>.sql.azuresynapse.net").
//Defaults to storage path defined in the runtime configurations
option(Constants.TEMP_FOLDER, "abfss://<container_name>@<storage_account_name>.dfs.core.windows.net/<some_base_path_for_temporary_staging_folders>")
//query from which data will be read
.option(Constants.QUERY, "select <column_name>, count(*) as cnt from <schema_name>.<table_name> group by <column_name>")
synapsesql()
val dfToReadFromQueryAsArgument:DataFrame = spark.read.
// Name of the SQL Dedicated Pool or database where to run the query
// Database can be specified as a Spark Config - spark.sqlanalyticsconnector.dw.database or as a Constant - Constants.DATABASE
option(Constants.DATABASE, "<database_name>")
//If `Constants.SERVER` is not provided, the `<database_name>` from the three-part table name argument
//to `synapsesql` method is used to infer the Synapse Dedicated SQL End Point.
option(Constants.SERVER, "<sql-server-name>.sql.azuresynapse.net").
//Defaults to storage path defined in the runtime configurations
option(Constants.TEMP_FOLDER, "abfss://<container_name>@<storage_account_name>.dfs.core.windows.net/<some_base_path_for_temporary_staging_folders>")
//query from which data will be read
.synapsesql("select <column_name>, count(*) as counts from <schema_name>.<table_name> group by <column_name>")
//Show contents of the dataframe
dfToReadFromQueryAsOption.show()
dfToReadFromQueryAsArgument.show()
Läsa från en tabell med grundläggande autentisering
//Use case is to read data from an internal table in Synapse Dedicated SQL Pool DB
//Azure Active Directory based authentication approach is preferred here.
import org.apache.spark.sql.DataFrame
import com.microsoft.spark.sqlanalytics.utils.Constants
import org.apache.spark.sql.SqlAnalyticsConnector._
//Read from existing internal table
val dfToReadFromTable:DataFrame = spark.read.
//If `Constants.SERVER` is not provided, the `<database_name>` from the three-part table name argument
//to `synapsesql` method is used to infer the Synapse Dedicated SQL End Point.
option(Constants.SERVER, "<sql-server-name>.sql.azuresynapse.net").
//Set database user name
option(Constants.USER, "<user_name>").
//Set user's password to the database
option(Constants.PASSWORD, "<user_password>").
//Set name of the data source definition that is defined with database scoped credentials.
//Data extracted from the table will be staged to the storage path defined on the data source's location setting.
option(Constants.DATA_SOURCE, "<data_source_name>").
//Three-part table name from where data will be read.
synapsesql("<database_name>.<schema_name>.<table_name>").
//Column-pruning i.e., query select column values.
select("<some_column_1>", "<some_column_5>", "<some_column_n>").
//Push-down filter criteria that gets translated to SQL Push-down Predicates.
filter(col("Title").startsWith("E")).
//Fetch a sample of 10 records
limit(10)
//Show contents of the dataframe
dfToReadFromTable.show()
Läsa från en fråga med grundläggande autentisering
//Use case is to read data from an internal table in Synapse Dedicated SQL Pool DB
//Azure Active Directory based authentication approach is preferred here.
import org.apache.spark.sql.DataFrame
import com.microsoft.spark.sqlanalytics.utils.Constants
import org.apache.spark.sql.SqlAnalyticsConnector._
// Name of the SQL Dedicated Pool or database where to run the query
// Database can be specified as a Spark Config or as a Constant - Constants.DATABASE
spark.conf.set("spark.sqlanalyticsconnector.dw.database", "<database_name>")
// Read from a query
// Query can be provided either as an argument to synapsesql or as a Constant - Constants.QUERY
val dfToReadFromQueryAsOption:DataFrame = spark.read.
//Name of the SQL Dedicated Pool or database where to run the query
//Database can be specified as a Spark Config - spark.sqlanalyticsconnector.dw.database or as a Constant - Constants.DATABASE
option(Constants.DATABASE, "<database_name>").
//If `Constants.SERVER` is not provided, the `<database_name>` from the three-part table name argument
//to `synapsesql` method is used to infer the Synapse Dedicated SQL End Point.
option(Constants.SERVER, "<sql-server-name>.sql.azuresynapse.net").
//Set database user name
option(Constants.USER, "<user_name>").
//Set user's password to the database
option(Constants.PASSWORD, "<user_password>").
//Set name of the data source definition that is defined with database scoped credentials.
//Data extracted from the SQL query will be staged to the storage path defined on the data source's location setting.
option(Constants.DATA_SOURCE, "<data_source_name>").
//Query where data will be read.
option(Constants.QUERY, "select <column_name>, count(*) as counts from <schema_name>.<table_name> group by <column_name>" ).
synapsesql()
val dfToReadFromQueryAsArgument:DataFrame = spark.read.
//Name of the SQL Dedicated Pool or database where to run the query
//Database can be specified as a Spark Config - spark.sqlanalyticsconnector.dw.database or as a Constant - Constants.DATABASE
option(Constants.DATABASE, "<database_name>").
//If `Constants.SERVER` is not provided, the `<database_name>` from the three-part table name argument
//to `synapsesql` method is used to infer the Synapse Dedicated SQL End Point.
option(Constants.SERVER, "<sql-server-name>.sql.azuresynapse.net").
//Set database user name
option(Constants.USER, "<user_name>").
//Set user's password to the database
option(Constants.PASSWORD, "<user_password>").
//Set name of the data source definition that is defined with database scoped credentials.
//Data extracted from the SQL query will be staged to the storage path defined on the data source's location setting.
option(Constants.DATA_SOURCE, "<data_source_name>").
//Query where data will be read.
synapsesql("select <column_name>, count(*) as counts from <schema_name>.<table_name> group by <column_name>")
//Show contents of the dataframe
dfToReadFromQueryAsOption.show()
dfToReadFromQueryAsArgument.show()
Skriva till Azure Synapse Dedicated SQL-pool
Skrivbegäran – synapsesql metodsignatur
synapsesql(tableName:String,
tableType:String = Constants.INTERNAL,
location:Option[String] = None,
callBackHandle=Option[(Map[String, Any], Option[Throwable])=>Unit]):Unit
Skriva med Microsoft Entra ID-baserad autentisering
Följande är en omfattande kodmall som beskriver hur du använder anslutningsappen för skrivscenarier:
//Add required imports
import org.apache.spark.sql.DataFrame
import org.apache.spark.sql.SaveMode
import com.microsoft.spark.sqlanalytics.utils.Constants
import org.apache.spark.sql.SqlAnalyticsConnector._
//Define read options for example, if reading from CSV source, configure header and delimiter options.
val pathToInputSource="abfss://<storage_container_name>@<storage_account_name>.dfs.core.windows.net/<some_folder>/<some_dataset>.csv"
//Define read configuration for the input CSV
val dfReadOptions:Map[String, String] = Map("header" -> "true", "delimiter" -> ",")
//Initialize DataFrame that reads CSV data from a given source
val readDF:DataFrame=spark.
read.
options(dfReadOptions).
csv(pathToInputSource).
limit(1000) //Reads first 1000 rows from the source CSV input.
//Setup and trigger the read DataFrame for write to Synapse Dedicated SQL Pool.
//Fully qualified SQL Server DNS name can be obtained using one of the following methods:
// 1. Synapse Workspace - Manage Pane - SQL Pools - <Properties view of the corresponding Dedicated SQL Pool>
// 2. From Azure Portal, follow the bread-crumbs for <Portal_Home> -> <Resource_Group> -> <Dedicated SQL Pool> and then go to Connection Strings/JDBC tab.
//If `Constants.SERVER` is not provided, the value will be inferred by using the `database_name` in the three-part table name argument to the `synapsesql` method.
//Like-wise, if `Constants.TEMP_FOLDER` is not provided, the connector will use the runtime staging directory config (see section on Configuration Options for details).
val writeOptionsWithAADAuth:Map[String, String] = Map(Constants.SERVER -> "<dedicated-pool-sql-server-name>.sql.azuresynapse.net",
Constants.TEMP_FOLDER -> "abfss://<storage_container_name>@<storage_account_name>.dfs.core.windows.net/<some_temp_folder>")
//Setup optional callback/feedback function that can receive post write metrics of the job performed.
var errorDuringWrite:Option[Throwable] = None
val callBackFunctionToReceivePostWriteMetrics: (Map[String, Any], Option[Throwable]) => Unit =
(feedback: Map[String, Any], errorState: Option[Throwable]) => {
println(s"Feedback map - ${feedback.map{case(key, value) => s"$key -> $value"}.mkString("{",",\n","}")}")
errorDuringWrite = errorState
}
//Configure and submit the request to write to Synapse Dedicated SQL Pool (note - default SaveMode is set to ErrorIfExists)
//Sample below is using AAD-based authentication approach; See further examples to leverage SQL Basic auth.
readDF.
write.
//Configure required configurations.
options(writeOptionsWithAADAuth).
//Choose a save mode that is apt for your use case.
mode(SaveMode.Overwrite).
synapsesql(tableName = "<database_name>.<schema_name>.<table_name>",
//For external table type value is Constants.EXTERNAL
tableType = Constants.INTERNAL,
//Optional parameter that is used to specify external table's base folder; defaults to `database_name/schema_name/table_name`
location = None,
//Optional parameter to receive a callback.
callBackHandle = Some(callBackFunctionToReceivePostWriteMetrics))
//If write request has failed, raise an error and fail the Cell's execution.
if(errorDuringWrite.isDefined) throw errorDuringWrite.get
Skriva med grundläggande autentisering
Följande kodfragment ersätter skrivdefinitionen som beskrivs i avsnittet Skriv med Microsoft Entra ID-baserad autentisering för att skicka skrivbegäran med sql basic authentication approach:
//Define write options to use SQL basic authentication
val writeOptionsWithBasicAuth:Map[String, String] = Map(Constants.SERVER -> "<dedicated-pool-sql-server-name>.sql.azuresynapse.net",
//Set database user name
Constants.USER -> "<user_name>",
//Set database user's password
Constants.PASSWORD -> "<user_password>",
//Required only when writing to an external table. For write to internal table, this can be used instead of TEMP_FOLDER option.
Constants.DATA_SOURCE -> "<Name of the datasource as defined in the target database>"
//To be used only when writing to internal tables. Storage path will be used for data staging.
Constants.TEMP_FOLDER -> "abfss://<storage_container_name>@<storage_account_name>.dfs.core.windows.net/<some_temp_folder>")
//Configure and submit the request to write to Synapse Dedicated SQL Pool.
readDF.
write.
options(writeOptionsWithBasicAuth).
//Choose a save mode that is apt for your use case.
mode(SaveMode.Overwrite).
synapsesql(tableName = "<database_name>.<schema_name>.<table_name>",
//For external table type value is Constants.EXTERNAL
tableType = Constants.INTERNAL,
//Not required for writing to an internal table
location = None,
//Optional parameter.
callBackHandle = Some(callBackFunctionToReceivePostWriteMetrics))
I en grundläggande autentiseringsmetod krävs andra konfigurationsalternativ för att kunna läsa data från en källlagringssökväg. Följande kodfragment innehåller ett exempel för att läsa från en Azure Data Lake Storage Gen2-datakälla med autentiseringsuppgifter för tjänstens huvudnamn:
//Specify options that Spark runtime must support when interfacing and consuming source data
val storageAccountName="<storageAccountName>"
val storageContainerName="<storageContainerName>"
val subscriptionId="<AzureSubscriptionID>"
val spnClientId="<ServicePrincipalClientID>"
val spnSecretKeyUsedAsAuthCred="<spn_secret_key_value>"
val dfReadOptions:Map[String, String]=Map("header"->"true",
"delimiter"->",",
"fs.defaultFS" -> s"abfss://$storageContainerName@$storageAccountName.dfs.core.windows.net",
s"fs.azure.account.auth.type.$storageAccountName.dfs.core.windows.net" -> "OAuth",
s"fs.azure.account.oauth.provider.type.$storageAccountName.dfs.core.windows.net" ->
"org.apache.hadoop.fs.azurebfs.oauth2.ClientCredsTokenProvider",
"fs.azure.account.oauth2.client.id" -> s"$spnClientId",
"fs.azure.account.oauth2.client.secret" -> s"$spnSecretKeyUsedAsAuthCred",
"fs.azure.account.oauth2.client.endpoint" -> s"https://login.microsoftonline.com/$subscriptionId/oauth2/token",
"fs.AbstractFileSystem.abfss.impl" -> "org.apache.hadoop.fs.azurebfs.Abfs",
"fs.abfss.impl" -> "org.apache.hadoop.fs.azurebfs.SecureAzureBlobFileSystem")
//Initialize the Storage Path string, where source data is maintained/kept.
val pathToInputSource=s"abfss://$storageContainerName@$storageAccountName.dfs.core.windows.net/<base_path_for_source_data>/<specific_file (or) collection_of_files>"
//Define data frame to interface with the data source
val df:DataFrame = spark.
read.
options(dfReadOptions).
csv(pathToInputSource).
limit(100)
DataFrame-lagringslägen som stöds
Följande sparlägen stöds när du skriver källdata till en måltabell i Azure Synapse Dedicated SQL Pool:
- ErrorIfExists (standardläge för sparande)
- Om måltabellen finns avbryts skrivning med ett undantag som returneras till anropare. Annars skapas en ny tabell med data från mellanlagringsmapparna.
- Bortse från
- Om måltabellen finns ignorerar skrivningen skrivbegäran utan att returnera ett fel. Annars skapas en ny tabell med data från mellanlagringsmapparna.
- Skriv över
- Om måltabellen finns ersätts befintliga data i målet med data från mellanlagringsmapparna. Annars skapas en ny tabell med data från mellanlagringsmapparna.
- Bifoga
- Om måltabellen finns läggs de nya data till. Annars skapas en ny tabell med data från mellanlagringsmapparna.
Återanropshandtag för skrivbegäran
De nya api-ändringarna för skrivsökväg introducerade en experimentell funktion för att ge klienten en nyckel/värde-karta> över mått efter skrivning. Nycklar för måtten definieras i den nya objektdefinitionen - Constants.FeedbackConstants. Mått kan hämtas som en JSON-sträng genom att skicka in motringningshandtaget (en Scala Function). Följande är funktionssignaturen:
//Function signature is expected to have two arguments - a `scala.collection.immutable.Map[String, Any]` and an Option[Throwable]
//Post-write if there's a reference of this handle passed to the `synapsesql` signature, it will be invoked by the closing process.
//These arguments will have valid objects in either Success or Failure case. In case of Failure the second argument will be a `Some(Throwable)`.
(Map[String, Any], Option[Throwable]) => Unit
Följande är några anmärkningsvärda mått (presenteras i kamelfall):
WriteFailureCauseDataStagingSparkJobDurationInMillisecondsNumberOfRecordsStagedForSQLCommitSQLStatementExecutionDurationInMillisecondsrows_processed
Följande är en JSON-exempelsträng med mått efter skrivning:
{
SparkApplicationId -> <spark_yarn_application_id>,
SQLStatementExecutionDurationInMilliseconds -> 10113,
WriteRequestReceivedAtEPOCH -> 1647523790633,
WriteRequestProcessedAtEPOCH -> 1647523808379,
StagingDataFileSystemCheckDurationInMilliseconds -> 60,
command -> "COPY INTO [schema_name].[table_name] ...",
NumberOfRecordsStagedForSQLCommit -> 100,
DataStagingSparkJobEndedAtEPOCH -> 1647523797245,
SchemaInferenceAssertionCompletedAtEPOCH -> 1647523790920,
DataStagingSparkJobDurationInMilliseconds -> 5252,
rows_processed -> 100,
SaveModeApplied -> TRUNCATE_COPY,
DurationInMillisecondsToValidateFileFormat -> 75,
status -> Completed,
SparkApplicationName -> <spark_application_name>,
ThreePartFullyQualifiedTargetTableName -> <database_name>.<schema_name>.<table_name>,
request_id -> <query_id_as_retrieved_from_synapse_dedicated_sql_db_query_reference>,
StagingFolderConfigurationCheckDurationInMilliseconds -> 2,
JDBCConfigurationsSetupAtEPOCH -> 193,
StagingFolderConfigurationCheckCompletedAtEPOCH -> 1647523791012,
FileFormatValidationsCompletedAtEPOCHTime -> 1647523790995,
SchemaInferenceCheckDurationInMilliseconds -> 91,
SaveModeRequested -> Overwrite,
DataStagingSparkJobStartedAtEPOCH -> 1647523791993,
DurationInMillisecondsTakenToGenerateWriteSQLStatements -> 4
}
Fler kodexempel
Använda materialiserade data mellan celler
Spark DataFrame kan createOrReplaceTempView användas för att komma åt data som hämtats i en annan cell genom att registrera en tillfällig vy.
- Cell där data hämtas (t.ex. med notebook-språkinställningar som
Scala)
//Necessary imports
import org.apache.spark.sql.DataFrame
import org.apache.spark.sql.SaveMode
import com.microsoft.spark.sqlanalytics.utils.Constants
import org.apache.spark.sql.SqlAnalyticsConnector._
//Configure options and read from Synapse Dedicated SQL Pool.
val readDF = spark.read.
//Set Synapse Dedicated SQL End Point name.
option(Constants.SERVER, "<synapse-dedicated-sql-end-point>.sql.azuresynapse.net").
//Set database user name.
option(Constants.USER, "<user_name>").
//Set database user's password.
option(Constants.PASSWORD, "<user_password>").
//Set name of the data source definition that is defined with database scoped credentials.
option(Constants.DATA_SOURCE,"<data_source_name>").
//Set the three-part table name from which the read must be performed.
synapsesql("<database_name>.<schema_name>.<table_name>").
//Optional - specify number of records the DataFrame would read.
limit(10)
//Register the temporary view (scope - current active Spark Session)
readDF.createOrReplaceTempView("<temporary_view_name>")
- Ändra nu språkinställningen för notebook-filen till
PySpark (Python)och hämta data från den registrerade vyn<temporary_view_name>
spark.sql("select * from <temporary_view_name>").show()
Svarshantering
Anropet synapsesql har två möjliga sluttillstånd – Lyckades eller ett misslyckat tillstånd. I det här avsnittet beskrivs hur du hanterar begärandesvaret för varje scenario.
Svar på läsbegäran
När det är klart visas det lästa svarsfragmentet i cellens utdata. Fel i den aktuella cellen kommer också att avbryta efterföljande cellkörningar. Detaljerad felinformation finns i Spark-programloggarna.
Svar på skrivbegäran
Som standard skrivs ett skrivsvar ut till cellutdata. Vid fel markeras den aktuella cellen som misslyckad och efterföljande cellkörningar avbryts. Den andra metoden är att skicka återanropshandtagsalternativet synapsesql till metoden. Motringningshandtaget ger programmatisk åtkomst till skrivsvaret.
Övriga beaktanden
- När du läser från Azure Synapse Dedicated SQL Pool-tabeller:
- Överväg att använda nödvändiga filter på DataFrame för att dra nytta av anslutningsappens kolumnrensningsfunktion.
- Lässcenariot stöder
TOP(n-rows)inte -satsen när du utformar frågeinstruktionernaSELECT. Valet att begränsa data är att använda DataFrame-satsen limit(.).- Se exemplet – Använda materialiserade data mellan celler .
- När du skriver till Azure Synapse Dedicated SQL Pool-tabellerna:
- För interna tabelltyper:
- Tabeller skapas med ROUND_ROBIN datadistribution.
- Kolumntyper härleds från dataramen som skulle läsa data från källan. Strängkolumner mappas till
NVARCHAR(4000).
- För externa tabelltyper:
- DataFrames inledande parallellitet driver dataorganisationen för den externa tabellen.
- Kolumntyper härleds från dataramen som skulle läsa data från källan.
- Bättre datadistribution mellan exekutorer kan uppnås genom att justera parametern
spark.sql.files.maxPartitionBytesoch DataFrame-parameternrepartition. - När du skriver stora datamängder är det viktigt att ta hänsyn till effekten av DWU-prestandanivåinställningen som begränsar transaktionsstorleken.
- För interna tabelltyper:
- Övervaka användningstrender för Azure Data Lake Storage Gen2 för att upptäcka begränsningar som kan påverka läs- och skrivprestanda.