Samla in loggar och mått för Apache Spark-program med hjälp av Azure Storage-konto
Synapse Apache Spark-tillägget för diagnostikemitterare är ett bibliotek som gör det möjligt för Apache Spark-programmet att generera loggar, händelseloggar och mått till ett eller flera mål, inklusive Azure Log Analytics, Azure Storage och Azure Event Hubs.
I den här självstudien får du lära dig hur du använder Synapse Apache Spark-tillägget för diagnostikemitterare för att generera Apache Spark-programloggar, händelseloggar och mått till ditt Azure-lagringskonto.
Samla in loggar och mått till lagringskontot
Steg 1: Skapa ett lagringskonto
Om du vill samla in diagnostikloggar och mått till lagringskontot kan du använda befintliga Azure Storage-konton. Eller om du inte har något kan du skapa ett Azure Blob Storage-konto eller skapa ett lagringskonto som ska användas med Azure Data Lake Storage Gen2.
Steg 2: Skapa en Apache Spark-konfigurationsfil
Skapa och diagnostic-emitter-azure-storage-conf.txt kopiera följande innehåll till filen. Eller ladda ned en exempelmallfil för Konfiguration av Apache Spark-pooler.
spark.synapse.diagnostic.emitters MyDestination1
spark.synapse.diagnostic.emitter.MyDestination1.type AzureStorage
spark.synapse.diagnostic.emitter.MyDestination1.categories Log,EventLog,Metrics
spark.synapse.diagnostic.emitter.MyDestination1.uri https://<my-blob-storage>.blob.core.windows.net/<container-name>/<folder-name>
spark.synapse.diagnostic.emitter.MyDestination1.auth AccessKey
spark.synapse.diagnostic.emitter.MyDestination1.secret <storage-access-key>
Fyll i följande parametrar i konfigurationsfilen: <my-blob-storage>, <container-name>, <folder-name>, . <storage-access-key>
Mer beskrivning av parametrarna finns i Azure Storage-konfigurationer
Steg 3: Ladda upp Apache Spark-konfigurationsfilen till Synapse Studio och använd den i Spark-poolen
- Öppna sidan Apache Spark-konfigurationer (Hantera –> Apache Spark-konfigurationer).
- Klicka på knappen Importera för att ladda upp Apache Spark-konfigurationsfilen till Synapse Studio.
- Navigera till din Apache Spark-pool i Synapse Studio (Hantera –> Apache Spark-pooler).
- Klicka på knappen "..." till höger om Apache Spark-poolen och välj Apache Spark-konfiguration.
- Du kan välja den konfigurationsfil som du precis laddade upp i den nedrullningsbara menyn.
- Klicka på Använd när du har valt konfigurationsfil.
Steg 4: Visa loggfilerna i Azure Storage-kontot
När du har skickat ett jobb till den konfigurerade Apache Spark-poolen bör du kunna se loggarna och måttfilerna i mållagringskontot.
Loggarna placeras i motsvarande sökvägar enligt olika program av <workspaceName>.<sparkPoolName>.<livySessionId>.
Alla loggfiler kommer att vara i JSON-linjeformat (kallas även newline-avgränsad JSON, ndjson), vilket är praktiskt för databearbetning.
Tillgängliga konfigurationer
| Konfiguration | beskrivning |
|---|---|
spark.synapse.diagnostic.emitters |
Obligatoriskt. Kommaavgränsade målnamn för diagnostikemittare. Till exempel: MyDest1,MyDest2 |
spark.synapse.diagnostic.emitter.<destination>.type |
Obligatoriskt. Inbyggd måltyp. Om du vill aktivera Azure Storage-mål AzureStorage måste du inkluderas i det här fältet. |
spark.synapse.diagnostic.emitter.<destination>.categories |
Valfritt. De kommaavgränsade valda loggkategorierna. Tillgängliga värden är DriverLog, ExecutorLog, EventLog, Metrics. Om det inte anges är standardvärdet alla kategorier. |
spark.synapse.diagnostic.emitter.<destination>.auth |
Obligatoriskt. AccessKeyför att använda åtkomstnyckelauktorisering för lagringskonto. SASför auktorisering av signaturer för delad åtkomst. |
spark.synapse.diagnostic.emitter.<destination>.uri |
Obligatoriskt. Målblobcontainerns mapp-URI. Ska matcha mönstret https://<my-blob-storage>.blob.core.windows.net/<container-name>/<folder-name>. |
spark.synapse.diagnostic.emitter.<destination>.secret |
Valfritt. Det hemliga innehållet (AccessKey eller SAS). |
spark.synapse.diagnostic.emitter.<destination>.secret.keyVault |
Krävs om .secret inte har angetts. Azure Key Vault-namnet där hemligheten (AccessKey eller SAS) lagras. |
spark.synapse.diagnostic.emitter.<destination>.secret.keyVault.secretName |
Krävs om .secret.keyVault anges. Det hemliga namnet på Azure Key Vault där hemligheten (AccessKey eller SAS) lagras. |
spark.synapse.diagnostic.emitter.<destination>.secret.keyVault.linkedService |
Valfritt. Det länkade tjänstnamnet för Azure Key Vault. När det är aktiverat i Synapse-pipelinen är detta nödvändigt för att hämta hemligheten från AKV. (Kontrollera att MSI har läsbehörighet för AKV). |
spark.synapse.diagnostic.emitter.<destination>.filter.eventName.match |
Valfritt. De kommaavgränsade spark-händelsenamnen kan du ange vilka händelser som ska samlas in. Till exempel: SparkListenerApplicationStart,SparkListenerApplicationEnd |
spark.synapse.diagnostic.emitter.<destination>.filter.loggerName.match |
Valfritt. De kommaavgränsade log4j-loggningsnamnen kan du ange vilka loggar som ska samlas in. Till exempel: org.apache.spark.SparkContext,org.example.Logger |
spark.synapse.diagnostic.emitter.<destination>.filter.metricName.match |
Valfritt. Med kommaavgränsade spark-måttnamnssuffix kan du ange vilka mått som ska samlas in. Till exempel: jvm.heap.used |
Exempel på loggdata
Här är en exempelloggpost i JSON-format:
{
"timestamp": "2021-01-02T12:34:56.789Z",
"category": "Log|EventLog|Metrics",
"workspaceName": "<my-workspace-name>",
"sparkPool": "<spark-pool-name>",
"livyId": "<livy-session-id>",
"applicationId": "<application-id>",
"applicationName": "<application-name>",
"executorId": "<driver-or-executor-id>",
"properties": {
// The message properties of logs, events and metrics.
"timestamp": "2021-01-02T12:34:56.789Z",
"message": "Registering signal handler for TERM",
"logger_name": "org.apache.spark.util.SignalUtils",
"level": "INFO",
"thread_name": "main"
// ...
}
}
Synapse-arbetsyta med dataexfiltreringsskydd aktiverat
Azure Synapse Analytics-arbetsytor stöder aktivering av dataexfiltreringsskydd för arbetsytor. Med exfiltreringsskydd kan loggarna och måtten inte skickas direkt till målslutpunkterna. Du kan skapa motsvarande hanterade privata slutpunkter för olika målslutpunkter eller skapa IP-brandväggsregler i det här scenariot.
Gå till Synapse Studio > Hantera > hanterade privata slutpunkter, klicka på knappen Ny , välj Azure Blob Storage eller Azure Data Lake Storage Gen2 och fortsätt.
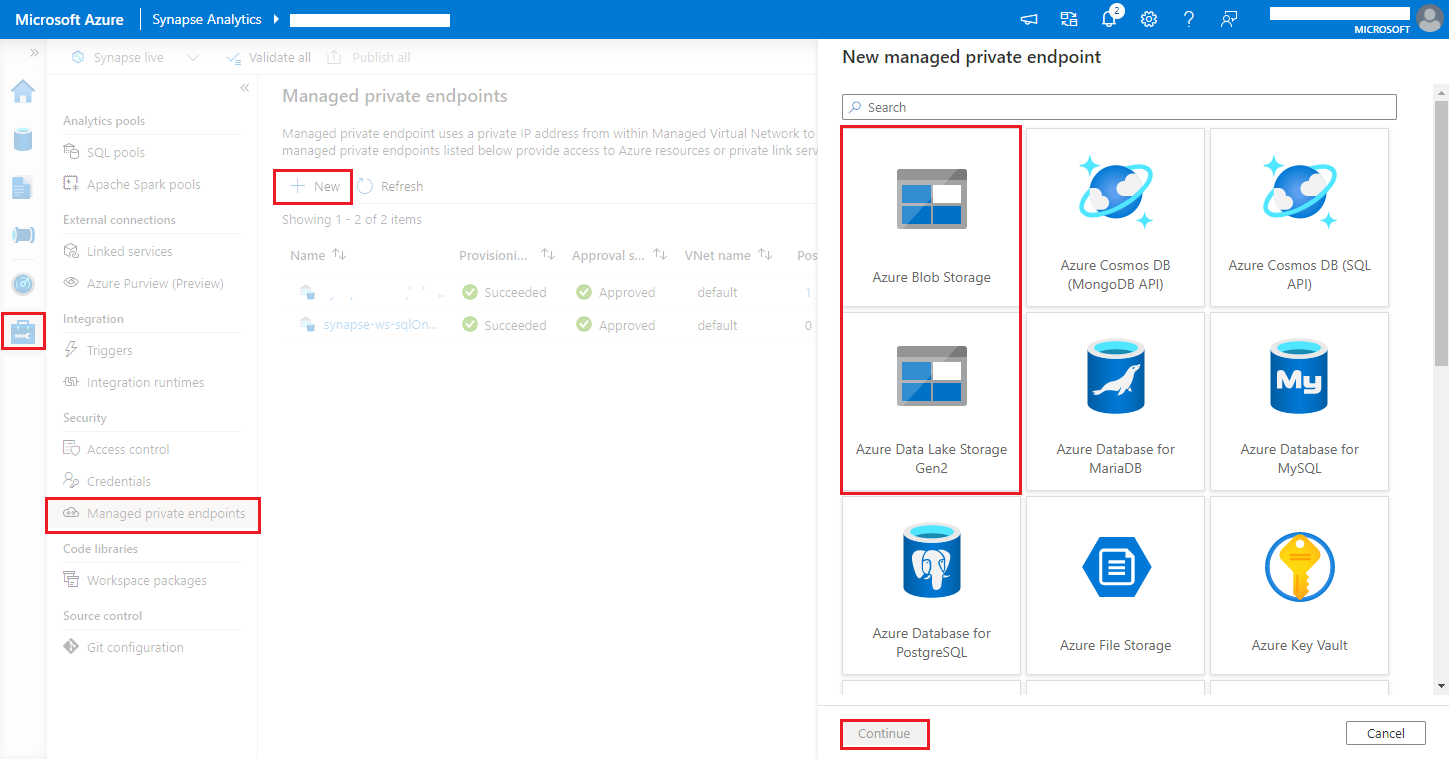
Kommentar
Vi kan stödja både Azure Blob Storage och Azure Data Lake Storage Gen2. Men vi kunde inte parsa abfss:// format. Azure Data Lake Storage Gen2-slutpunkter ska formateras som en blob-URL:
https://<my-blob-storage>.blob.core.windows.net/<container-name>/<folder-name>Välj ditt Azure Storage-konto i namnet på lagringskontot och klicka på knappen Skapa.
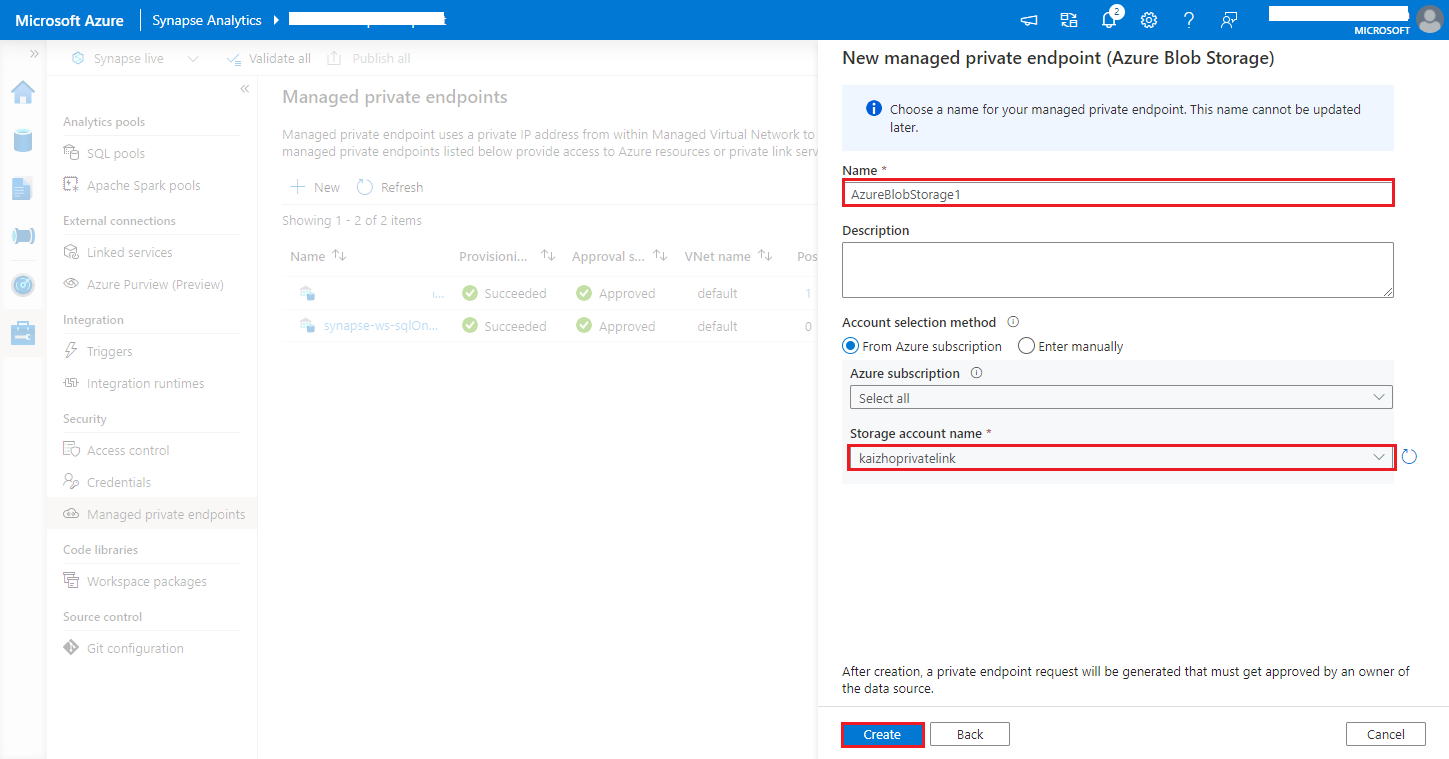
Vänta några minuter på etablering av privata slutpunkter.
Gå till ditt lagringskonto i Azure Portal på sidan Nätverksanslutningar> för privata slutpunkter, välj den etablerade anslutningen och Godkänn.