Övervaka Apache Spark-program med Azure Log Analytics
I den här självstudien får du lära dig hur du aktiverar Synapse Studio-anslutningsappen som är inbyggd i Log Analytics. Du kan sedan samla in och skicka Apache Spark-programmått och loggar till din Log Analytics-arbetsyta. Slutligen kan du använda en Azure Monitor-arbetsbok för att visualisera mått och loggar.
Konfigurera information om arbetsytan
Följ de här stegen för att konfigurera nödvändig information i Synapse Studio.
Steg 1: Skapa en Log Analytics-arbetsyta
Kontakta någon av följande resurser för att skapa den här arbetsytan:
- Skapa en arbetsyta i Azure Portal.
- Skapa en arbetsyta med Azure CLI.
- Skapa och konfigurera en arbetsyta i Azure Monitor med hjälp av PowerShell.
Steg 2: Samla in konfigurationsinformation
Använd något av följande alternativ för att förbereda konfigurationen.
Alternativ 1: Konfigurera med Log Analytics-arbetsyte-ID och nyckel
Samla in följande värden för Spark-konfigurationen:
<LOG_ANALYTICS_WORKSPACE_ID>: Log Analytics-arbetsyte-ID.<LOG_ANALYTICS_WORKSPACE_KEY>: Log Analytics-nyckel. Om du vill hitta det går du till Primärnyckel för Azure Log Analytics-arbetsyteagenter>>i Azure Portal.
spark.synapse.logAnalytics.enabled true
spark.synapse.logAnalytics.workspaceId <LOG_ANALYTICS_WORKSPACE_ID>
spark.synapse.logAnalytics.secret <LOG_ANALYTICS_WORKSPACE_KEY>
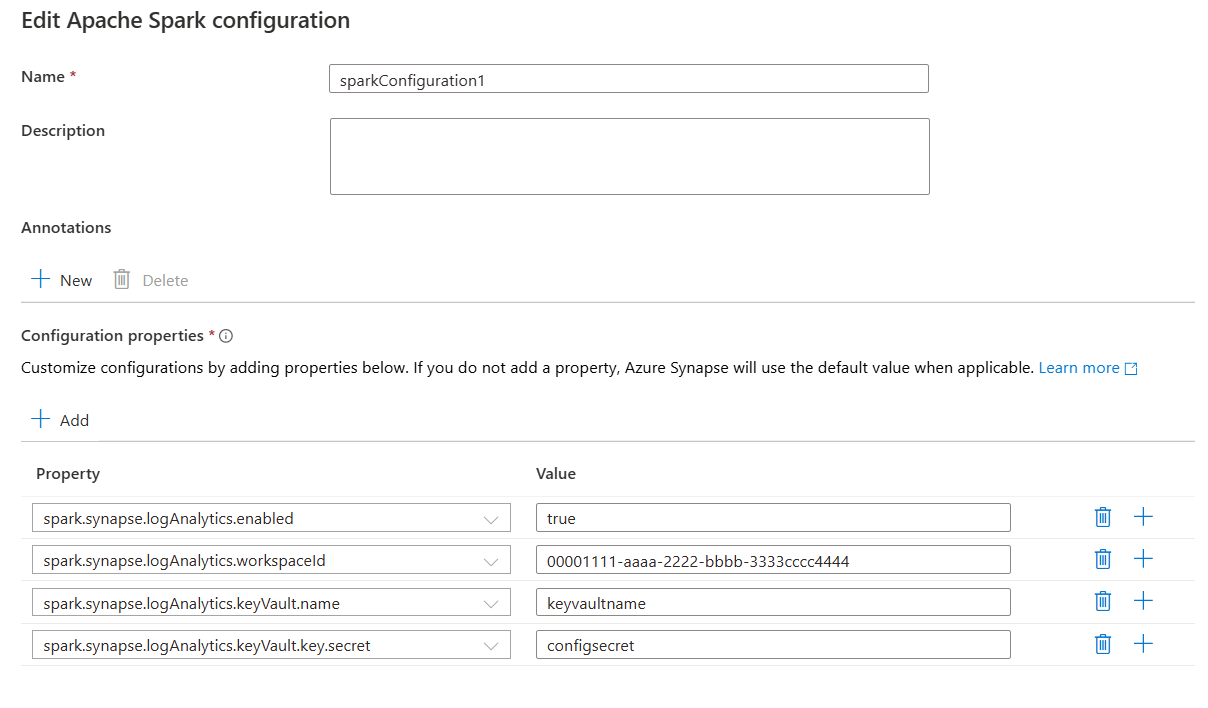
Alternativ 2: Konfigurera med Azure Key Vault
Kommentar
Du måste bevilja läshemlighetsbehörighet till de användare som skickar Apache Spark-program. Mer information finns i Ge åtkomst till Key Vault-nycklar, certifikat och hemligheter med en rollbaserad åtkomstkontroll i Azure. När du aktiverar den här funktionen i en Synapse-pipeline måste du använda alternativ 3. Detta är nödvändigt för att hämta hemligheten från Azure Key Vault med en hanterad identitet för arbetsytan.
Följ dessa steg för att konfigurera Azure Key Vault att lagra arbetsytenyckeln:
Skapa och gå till ditt nyckelvalv i Azure Portal.
På inställningssidan för nyckelvalvet väljer du Hemligheter.
Välj Generera/Importera.
Välj följande värden på skärmen Skapa en hemlighet:
- Namn: Ange ett namn för hemligheten. Som standard anger du
SparkLogAnalyticsSecret. - Värde: Ange
<LOG_ANALYTICS_WORKSPACE_KEY>för hemligheten. - Lämna standardvärdena för de andra alternativen. Välj sedan Skapa.
- Namn: Ange ett namn för hemligheten. Som standard anger du
Samla in följande värden för Spark-konfigurationen:
<LOG_ANALYTICS_WORKSPACE_ID>: Log Analytics-arbetsytans ID.<AZURE_KEY_VAULT_NAME>: Namnet på nyckelvalvet som du konfigurerade.<AZURE_KEY_VAULT_SECRET_KEY_NAME>(valfritt): Det hemliga namnet i nyckelvalvet för arbetsytenyckeln. Standardvärdet ärSparkLogAnalyticsSecret.
spark.synapse.logAnalytics.enabled true
spark.synapse.logAnalytics.workspaceId <LOG_ANALYTICS_WORKSPACE_ID>
spark.synapse.logAnalytics.keyVault.name <AZURE_KEY_VAULT_NAME>
spark.synapse.logAnalytics.keyVault.key.secret <AZURE_KEY_VAULT_SECRET_KEY_NAME>
Kommentar
Du kan också lagra arbetsyte-ID:t i Key Vault. Se föregående steg och lagra arbetsyte-ID:t med det hemliga namnet SparkLogAnalyticsWorkspaceId. Du kan också använda konfigurationen spark.synapse.logAnalytics.keyVault.key.workspaceId för att ange arbetsyte-ID:ts hemliga namn i Key Vault.
Alternativ 3. Konfigurera med en länkad tjänst
Kommentar
I det här alternativet måste du bevilja läshemlighetsbehörighet till arbetsytans hanterade identitet. Mer information finns i Ge åtkomst till Key Vault-nycklar, certifikat och hemligheter med en rollbaserad åtkomstkontroll i Azure.
Följ dessa steg för att konfigurera en länkad Key Vault-tjänst i Synapse Studio för lagring av arbetsytenyckeln:
Följ alla steg i föregående avsnitt, "Alternativ 2".
Skapa en länkad Key Vault-tjänst i Synapse Studio:
a. Gå till Synapse Studio>Hantera>länkade tjänster och välj sedan Ny.
b. Sök efter Azure Key Vault i sökrutan.
c. Ange ett namn för den länkade tjänsten.
d. Välj ditt nyckelvalv och välj Skapa.
Lägg till ett
spark.synapse.logAnalytics.keyVault.linkedServiceNameobjekt i Apache Spark-konfigurationen.
spark.synapse.logAnalytics.enabled true
spark.synapse.logAnalytics.workspaceId <LOG_ANALYTICS_WORKSPACE_ID>
spark.synapse.logAnalytics.keyVault.key.secret <AZURE_KEY_VAULT_SECRET_KEY_NAME>
spark.synapse.logAnalytics.keyVault.linkedServiceName <LINKED_SERVICE_NAME>
En lista över Apache Spark-konfigurationer finns i Tillgängliga Apache Spark-konfigurationer
Steg 3: Skapa en Apache Spark-konfiguration
Du kan skapa en Apache Spark-konfiguration på din arbetsyta, och när du skapar en definition av Notebook- eller Apache Spark-jobb kan du välja den Apache Spark-konfiguration som du vill använda med din Apache Spark-pool. När du väljer den visas information om konfigurationen.
Välj Hantera>Apache Spark-konfigurationer.
Välj knappen Ny för att skapa en ny Apache Spark-konfiguration.
Ny Apache Spark-konfigurationssida öppnas när du har valt Ny knapp.
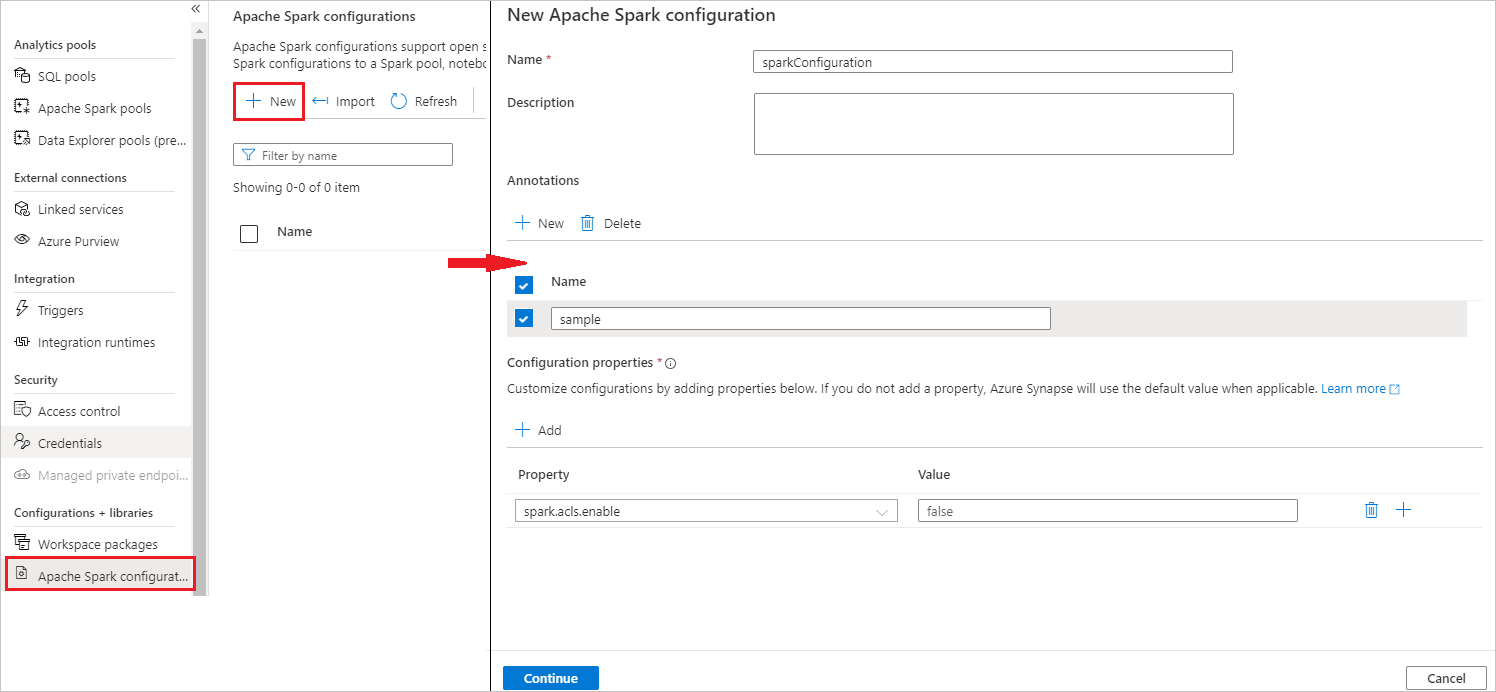
Som Namn kan du ange önskat och giltigt namn.
För Beskrivning kan du ange en beskrivning i den.
För Anteckningar kan du lägga till anteckningar genom att klicka på knappen Nytt , och du kan även ta bort befintliga anteckningar genom att välja och klicka på knappen Ta bort .
För Konfigurationsegenskaper lägger du till alla egenskaper från konfigurationsalternativet du valde genom att välja knappen Lägg till . För Egenskap lägger du till egenskapsnamnet enligt listan och för Värde använder du det värde som du samlade in under steg 2. Om du inte lägger till en egenskap använder Azure Synapse standardvärdet när det är tillämpligt.
Skicka ett Apache Spark-program och visa loggarna och måtten
Så här gör du:
Skicka ett Apache Spark-program till Apache Spark-poolen som konfigurerades i föregående steg. Du kan använda något av följande sätt att göra det:
- Kör en notebook-fil i Synapse Studio.
- I Synapse Studio skickar du ett Apache Spark-batchjobb via en Apache Spark-jobbdefinition.
- Kör en pipeline som innehåller Apache Spark-aktivitet.
Gå till den angivna Log Analytics-arbetsytan och visa sedan programmåtten och loggarna när Apache Spark-programmet börjar köras.
Skriva anpassade programloggar
Du kan använda Apache Log4j-biblioteket för att skriva anpassade loggar.
Exempel för Scala:
%%spark
val logger = org.apache.log4j.LogManager.getLogger("com.contoso.LoggerExample")
logger.info("info message")
logger.warn("warn message")
logger.error("error message")
//log exception
try {
1/0
} catch {
case e:Exception =>logger.warn("Exception", e)
}
// run job for task level metrics
val data = sc.parallelize(Seq(1,2,3,4)).toDF().count()
Exempel för PySpark:
%%pyspark
logger = sc._jvm.org.apache.log4j.LogManager.getLogger("com.contoso.PythonLoggerExample")
logger.info("info message")
logger.warn("warn message")
logger.error("error message")
Använda exempelarbetsboken för att visualisera mått och loggar
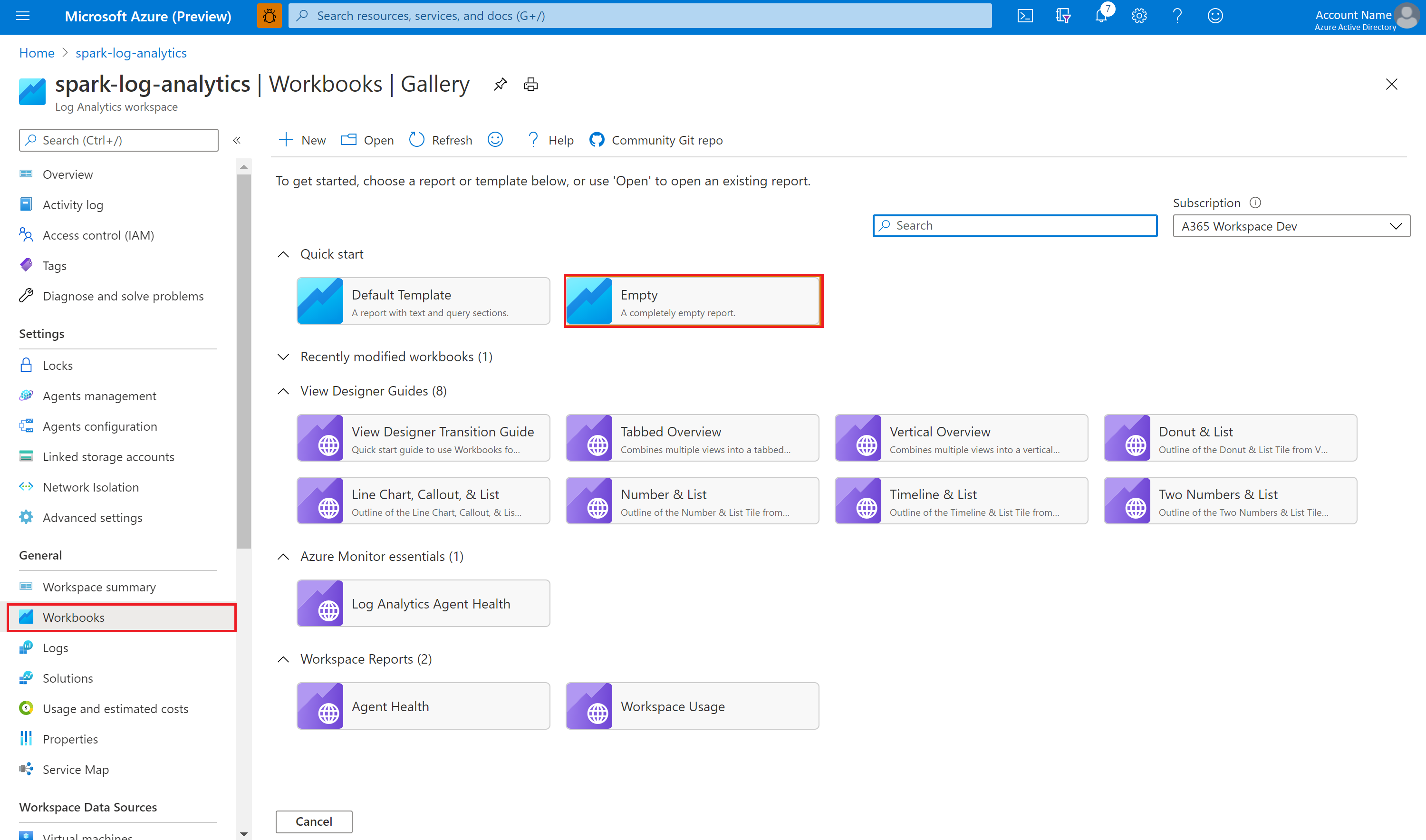
Öppna och kopiera innehållet i arbetsbokens fil.
I Azure Portal väljer du Log Analytics-arbetsytearbetsböcker>.
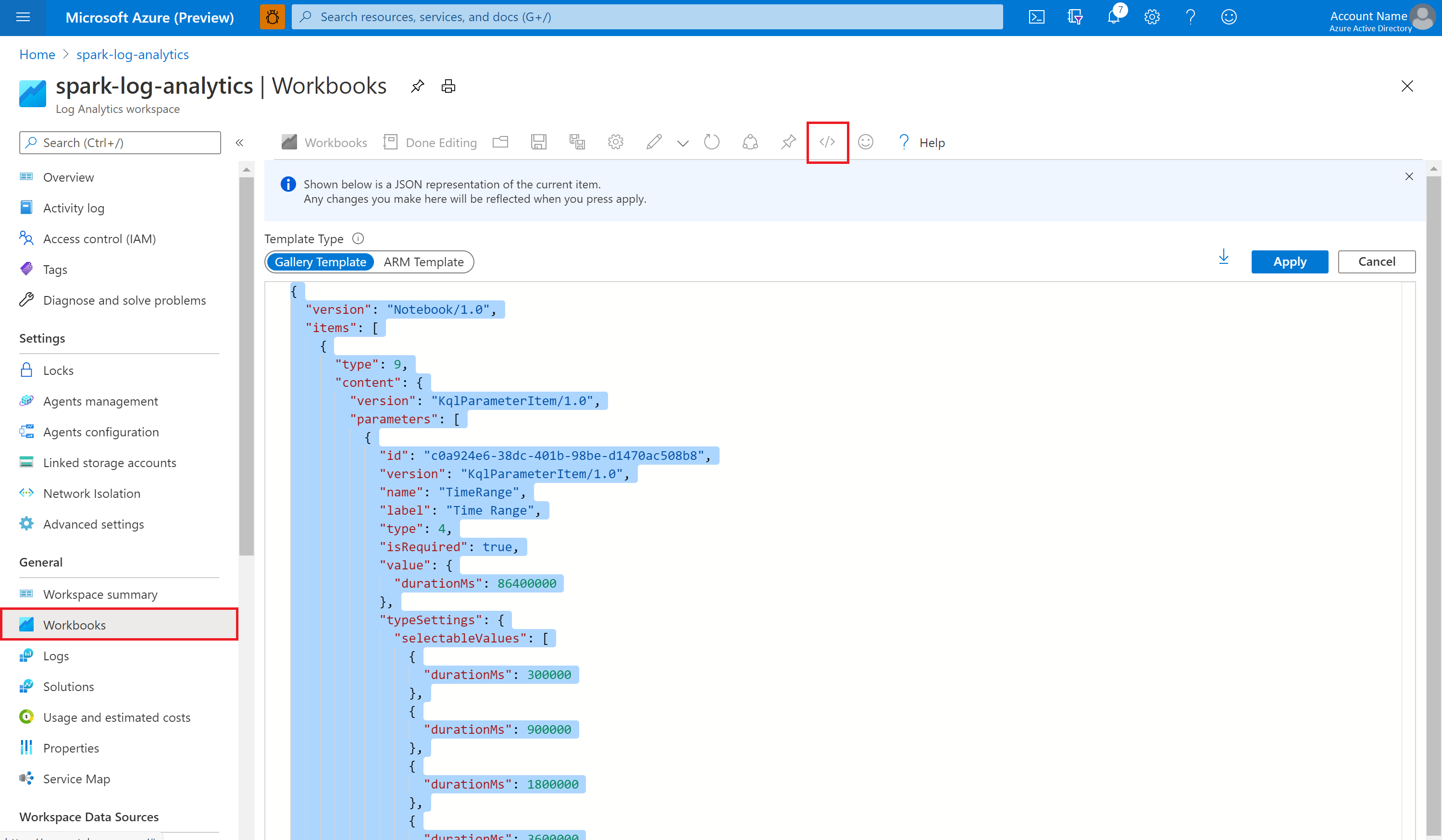
Öppna den tomma arbetsboken. Använd läget Avancerad redigerare genom att< välja ikonen />.
Klistra in all JSON-kod som finns.
Välj Använd och välj sedan Klar redigering.
Skicka sedan ditt Apache Spark-program till den konfigurerade Apache Spark-poolen. När programmet har körts väljer du det program som körs i listrutan för arbetsboken.
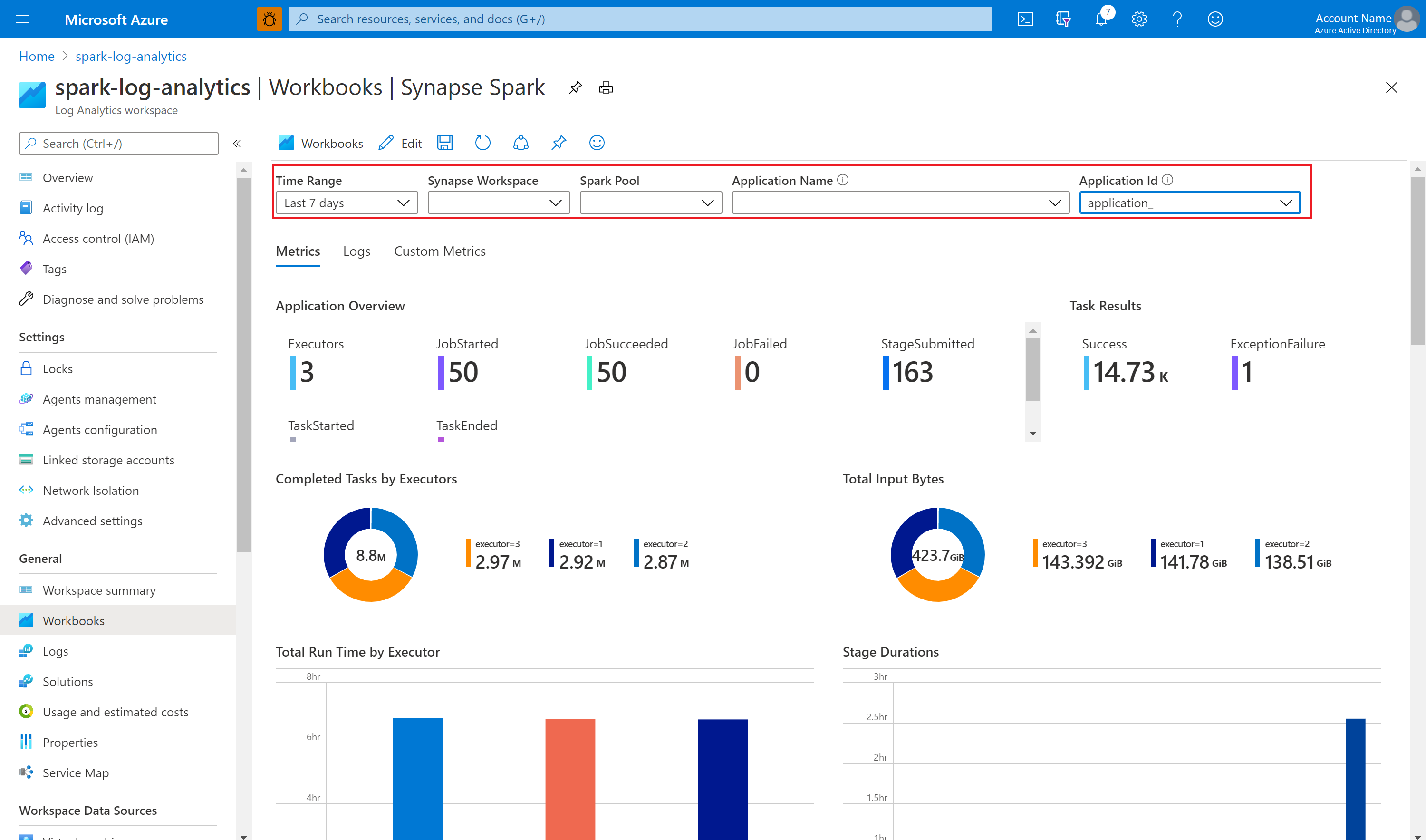
Du kan anpassa arbetsboken. Du kan till exempel använda Kusto-frågor och konfigurera aviseringar.
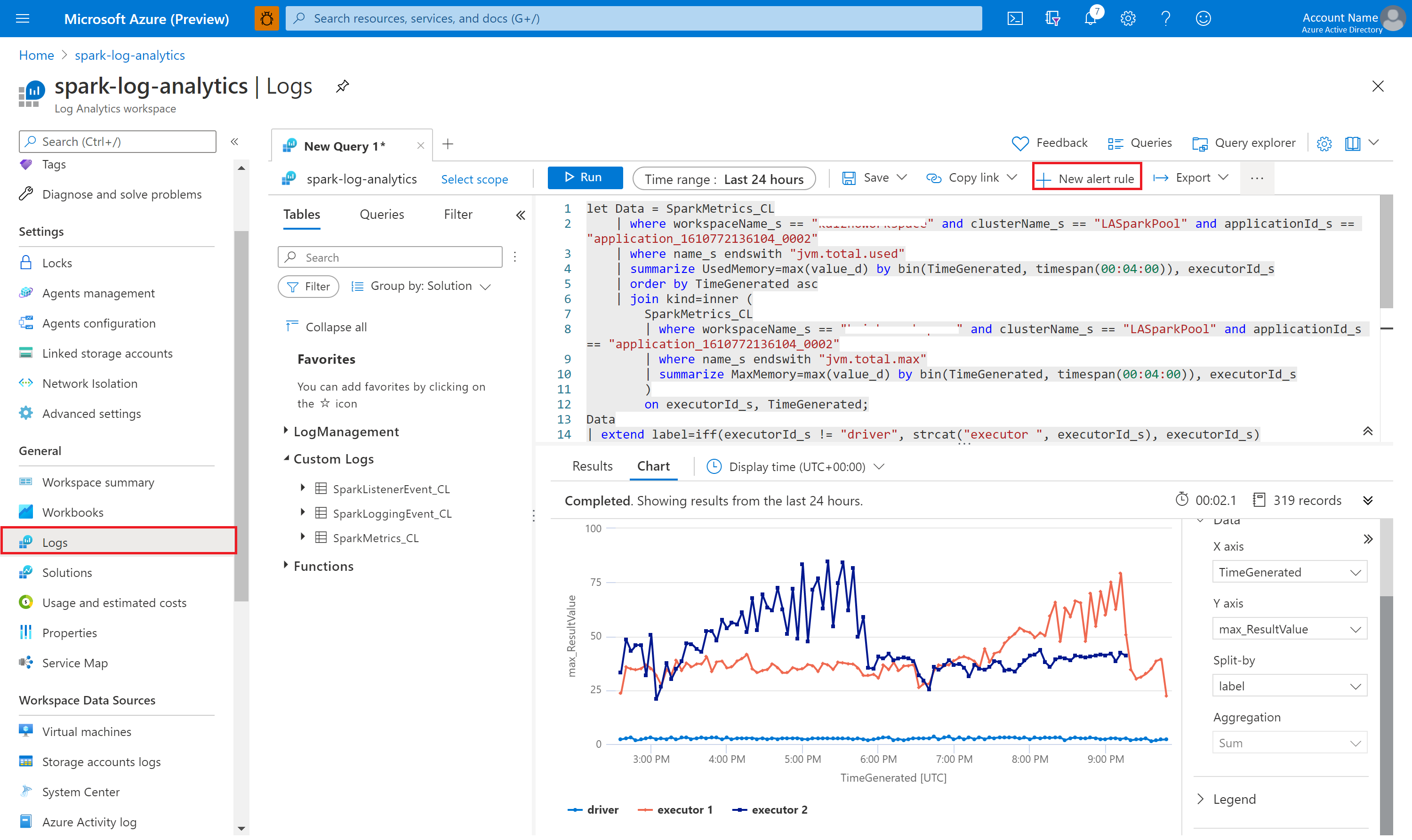
Fråga efter data med Kusto
Följande är ett exempel på att köra frågor mot Apache Spark-händelser:
SparkListenerEvent_CL
| where workspaceName_s == "{SynapseWorkspace}" and clusterName_s == "{SparkPool}" and livyId_s == "{LivyId}"
| order by TimeGenerated desc
| limit 100
Här är ett exempel på hur du kör frågor mot Apache Spark-programdrivrutinen och körloggarna:
SparkLoggingEvent_CL
| where workspaceName_s == "{SynapseWorkspace}" and clusterName_s == "{SparkPool}" and livyId_s == "{LivyId}"
| order by TimeGenerated desc
| limit 100
Och här är ett exempel på frågor mot Apache Spark-mått:
SparkMetrics_CL
| where workspaceName_s == "{SynapseWorkspace}" and clusterName_s == "{SparkPool}" and livyId_s == "{LivyId}"
| where name_s endswith "jvm.total.used"
| summarize max(value_d) by bin(TimeGenerated, 30s), executorId_s
| order by TimeGenerated asc
Skapa och hantera aviseringar
Användare kan fråga för att utvärdera mått och loggar med en angivna frekvens och utlösa en avisering baserat på resultaten. Mer information finns i Skapa, visa och hantera loggaviseringar med hjälp av Azure Monitor.
Synapse-arbetsyta med dataexfiltreringsskydd aktiverat
När Synapse-arbetsytan har skapats med dataexfiltreringsskydd aktiverat.
När du vill aktivera den här funktionen måste du skapa hanterade privata slutpunktsanslutningsbegäranden till Azure Monitor private link scopes (AMPLS) i arbetsytans godkända Microsoft Entra-klienter.
Du kan följa stegen nedan för att skapa en hanterad privat slutpunktsanslutning till Azure Monitor private link scopes (AMPLS):
- Om det inte finns någon befintlig AMPLS kan du följa konfigurationen av Azure Monitor Private Link-anslutningen för att skapa en.
- Gå till AMPLS i Azure Portal på sidan Azure Monitor-resurser och välj Lägg till för att lägga till anslutning till din Azure Log Analytics-arbetsyta.
- Gå till Synapse Studio > Hantera > hanterade privata slutpunkter, välj knappen Ny , välj Azure Monitor Private Link Scopes och fortsätt.
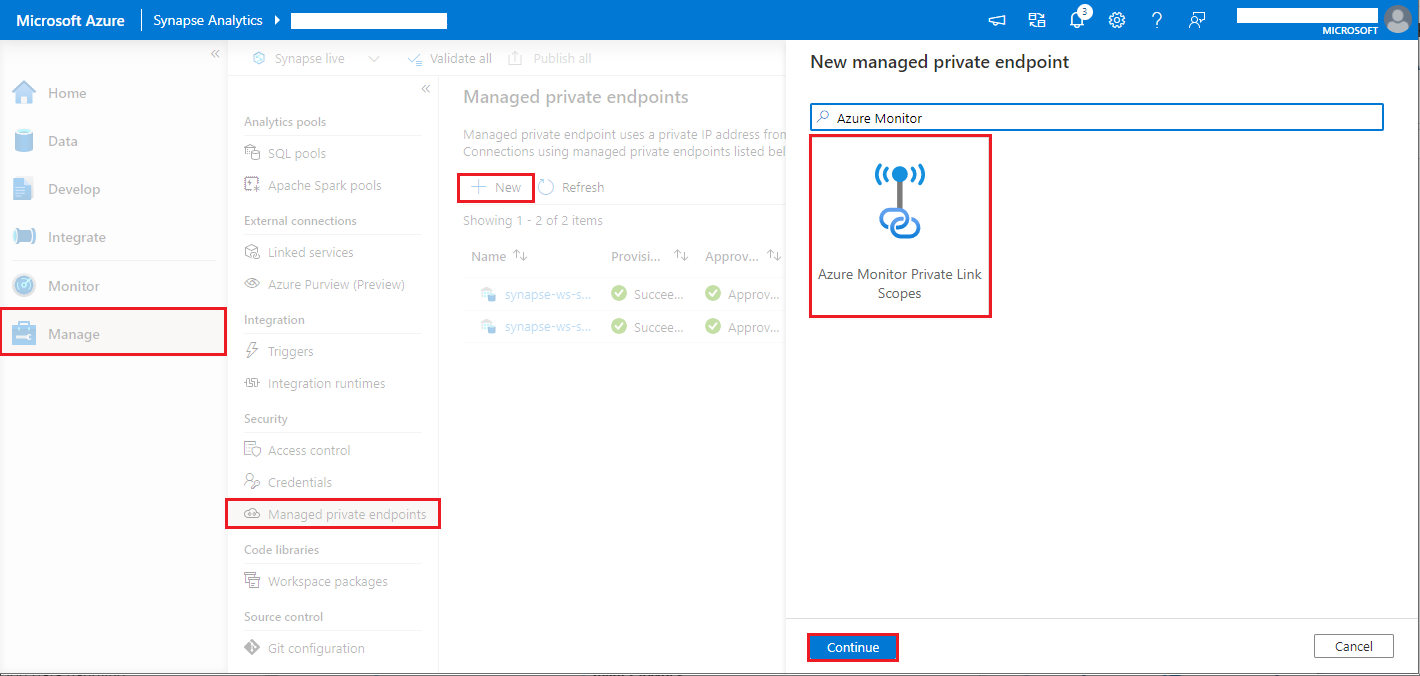
- Välj ditt Azure Monitor Private Link-omfång som du skapade och välj knappen Skapa .
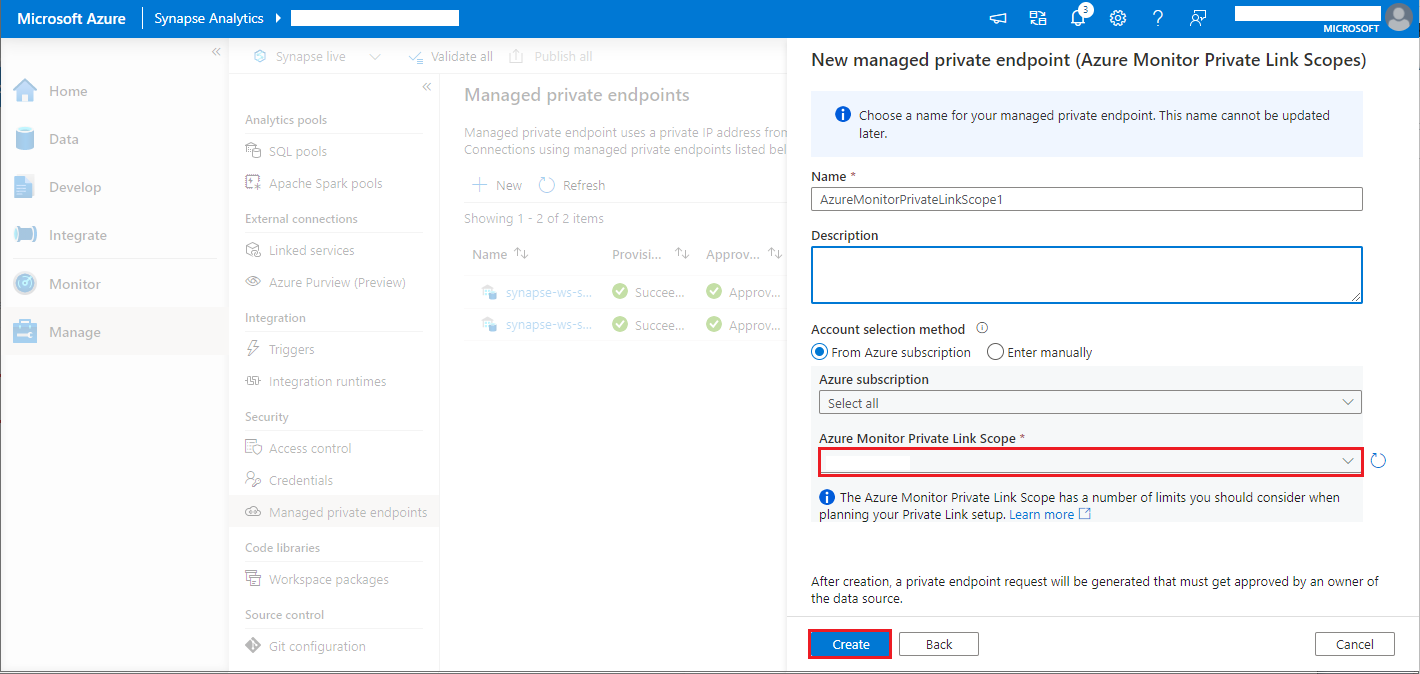
- Vänta några minuter på etablering av privata slutpunkter.
- Gå till AMPLS i Azure Portal igen. På sidan Privata slutpunktsanslutningar väljer du den etablerade anslutningen och Godkänner.
Kommentar
- AMPLS-objektet har ett antal gränser som du bör tänka på när du planerar din Private Link-konfiguration. Mer information om dessa gränser finns i AMPLS-gränser .
- Kontrollera om du har rätt behörighet att skapa en hanterad privat slutpunkt.