Общие сведения о дедупликации данных
В этом документе описывается, как работает дедупликация данных.
Как работает дедупликация данных
Дедупликация данных для Windows Server разрабатывалась на основе двух важнейших принципов.
Оптимизация не должна выполнять запись на диск Дедупликация данных, оптимизируя данные с помощью модели последующей обработки. Все данные записываются на диск в неоптимизированном виде, а затем оптимизируются с помощью дедупликации данных.
Оптимизация не должна изменять семантику доступа пользователей и приложений, которые получают доступ к данным в оптимизированном томе, полностью не знают, что доступ к файлам, к которым они обращаются, были дедупликированы.
После включения дедупликации данных для тома она выполняет в фоновом режиме следующие задачи:
- выявляет повторяющиеся фрагменты в файлах тома;
- автоматически перемещает эти фрагменты (блоки) со специальными указателями, которые называются точками повторного анализа и указывают на уникальную копию блока.
Этот процесс выполняется в четыре этапа:
- Проверка файловой системы на наличие файлов, отвечающих политике оптимизации.

- разбиение файлов на блоки переменного размера;

- выявление уникальных блоков;
- помещение блоков в хранилище блоков со сжатием, если применимо;
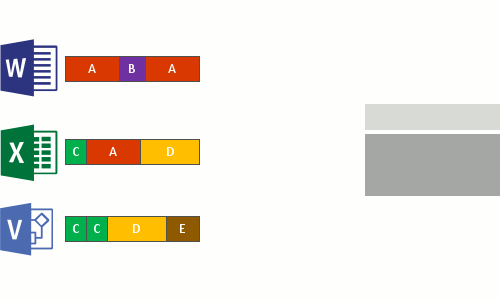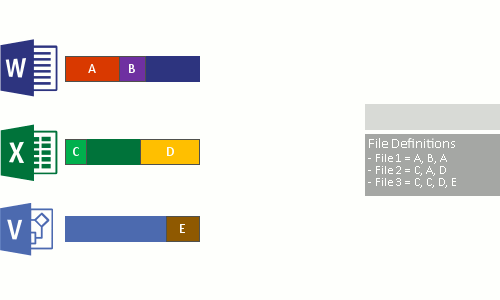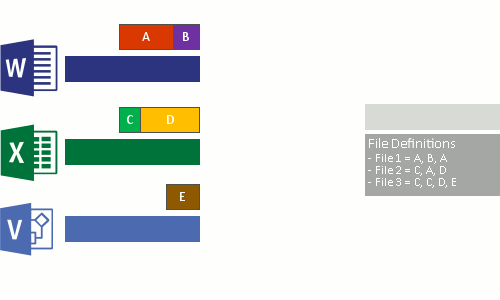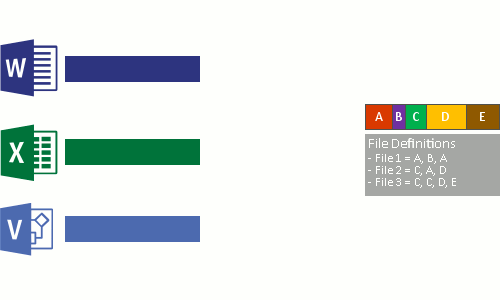
- Замена исходного потока данных в оптимизированных файлах на точки повторного анализа, указывающие на хранилище блоков.
При считывании оптимизированных файлов файловая система отправляет файлы с точкой повторного анализа в фильтр дедупликации данных файловой системы (Dedup.sys). Фильтр перенаправляет операцию чтения к соответствующим блокам, которые образуют поток этого файла в хранилище блоков. Изменения фрагментов дедуплицированного файла записываются на диск в неоптимизированном виде. Их при следующем запуске обрабатывает задание оптимизации.
Типы использования
Следующие типы использования содержат рациональные настройки дедупликации данных для некоторых распространенных рабочих нагрузок.
| Тип использования | Подходящие рабочие нагрузки | Отличия |
|---|---|---|
| По умолчанию | Файловый сервер общего назначения.
|
|
| Hyper-V | Серверы инфраструктуры виртуальных рабочих столов (VDI). |
|
| Резервная копия | Виртуализированные приложения резервного копирования, например Microsoft Data Protection Manager (DPM) |
|
Работы
Функция дедупликации данных использует стратегию постобработки для оптимизации и эффективного использования пространства на томе.
| Имя задания | Описание заданий | Расписание по умолчанию |
|---|---|---|
| Оптимизация | Задание оптимизации выполняет дедупликацию, разбивая на блоки данные, хранящиеся на томе, в соответствии с настройками политики для этого тома, а также (необязательно) сжимая эти блоки и сохраняя их уникальные копии в хранилище блоков. Процесс оптимизации, используемый дедупликацией данных, подробно описан в разделе Как работает дедупликация данных? | Каждый час |
| Сборка мусора | Задание сборки мусора выполняет освобождение места на диске, удаляя ставшие ненужными блоки, на которые не осталось ссылок после изменения или удаления файлов. | Каждую субботу в 02:35 |
| Очистка целостности | Задание проверки целостности обнаруживает повреждения в хранилище блоков, связанные со сбоями диска или поврежденными секторами. По мере возможности дедупликация данных автоматически применяет доступные для тома функции (например, зеркала или контроль четности для тома дисковых пространств), чтобы восстановить поврежденные данные. Кроме того, дедупликация данных сохраняет в отдельной "активной зоне" резервные копии популярных блоков, на которые существует более 100 ссылок. | Каждую субботу в 03:35 |
| Unoptimization | Задание отмены оптимизации, особое задание, которое может выполняться только вручную, отменяет всю оптимизацию, выполненную службой дедупликации, и отключает дедупликацию данных для тома. | Только по запросу |
Глоссарий дедупликации данных
| Термин | Определение |
|---|---|
| Ломоть | Блоком называется фрагмент файла, отобранный алгоритмом дедупликации данных, который с высокой долей вероятности будет повторяться в других схожих файлах. |
| Хранилище блоков | Хранилище блоков — это упорядоченный набор файлов в папке "System Volume Information", который дедупликация данных использует исключительно для хранения блоков. |
| Дедупликации | Сокращенная форма англоязычного названия дедупликации данных, которая часто используется в PowerShell, интерфейсах API и компонентах Windows Server, а также в сообществе Windows Server. |
| Метаданные файла | Каждый файл содержит метаданные, которые описывают важные свойства файла, не связанные напрямую с основным содержимым файла. Например: дата создания файла, дата последнего чтения, создатель файла и т. д. |
| Поток файлов | Так называется основное содержимое файла. Именно эту часть файла оптимизирует дедупликация данных. |
| Файловая система | Файловой системой называют специализированное программное обеспечение и структуру хранящихся на диске данных, которые используются операционной системой для хранения файлов на любых носителях. Дедупликация данных поддерживается только на томах с файловой системой NTFS. |
| Фильтр файловой системы | Так называется подключаемый модуль, который изменяет стандартное поведение файловой системы. Чтобы сохранить семантику доступа, дедупликация данных использует фильтр файловой системы (Dedup.sys), который перенаправляет запросы на чтение оптимизированного содержимого незаметным для пользователя или приложения образом. |
| Оптимизация | Файл считается оптимизированным с точки зрения дедупликации данных (дедуплицированным), если он разделен на уникальные блоки, которые перенесены в хранилище блоков. |
| Политика оптимизации | Политика оптимизации определяет, для каких файлов следует применять дедупликацию данных. Например, политика может исключать из оптимизации недавно созданные или открытые файлы, все файлы в определенном расположении в томе или файлы определенного типа. |
| Точка повторного восстановления | Точкой повторного анализа называют специальный тег, который уведомляет файловую систему о необходимости перенаправить запрос ввода-вывода на указанный фильтр файловой системы. В тех файлах, для которых выполнена оптимизация, дедупликация данных заменяет файловый поток точкой повторного анализа, что позволяет полностью сохранять семантику доступа к этому файлу. |
| Том | Том — это используемое Windows обозначение для логического диска хранения данных, который может включать несколько физических устройств хранения, расположенных на одном или нескольких серверах. Дедупликация включается на уровне отдельного тома. |
| Загруженность | Рабочей нагрузкой называется приложение, выполняемое на Windows Server. Пример рабочей нагрузки — файловый сервер общего назначения, сервер Hyper-V и SQL Server. |
Предупреждение
Не пытайтесь вручную изменять содержимое хранилища блоков, если вы не получали таких указаний от авторизованных представителей службы поддержки корпорации Майкрософт. Такие действия могут привести к повреждению или утрате данных.
Часто задаваемые вопросы
Чем отличается дедупликация данных от других средств оптимизации? Есть несколько важных различий между дедупликацией данных и другими распространенными решениями для оптимизации хранения.
Чем отличается дедупликация данных от хранилища единственных копий? Хранилище единственных копий (SIS) является предшественником технологии дедупликации данных и впервые было представлено в выпуске Windows Storage Server 2008 R2. Для оптимизации тома хранилище единственных копий выявляло в нем полностью идентичные файлы и заменяло их логическими ссылками на одну копию такого файла, размещенную в общем хранилище SIS. В отличие от хранилища единственных копий, дедупликация данных способна уменьшить пространство, занимаемое файлами, которые не полностью идентичны, но имеют некоторые одинаковые элементы, а также файлами, в которых встречается много повторяющихся элементов. Хранилище единственных копий считается устаревшим начиная с выпуска Windows Server 2012 R2, а в Windows Server 2016 его полностью заменила дедупликация данных.
Чем отличается дедупликация данных от сжатия NTFS? Сжатие NTFS используется файловой системой NTFS на уровне тома. Эта необязательная функция NTFS оптимизирует каждый файл по отдельности, сжимая его во время записи. В отличие от сжатия NTFS, дедупликация данных использует для экономии места одновременно все файлы на томе. Это гораздо эффективнее, чем сжатие NTFS, ведь файл может одновременно иметь как внутреннее дублирование данных (которое устраняется сжатием NTFS), так и сходство с другими файлами в томе (которое не устраняется сжатием NTFS). Кроме того, дедупликация данных использует модель постобработки. Это означает, что новые или измененные файлы записываются на диск в неоптимизированном виде, и лишь затем дедупликация данных оптимизирует их.
Чем отличается дедупликация данных от форматов архивации файлов, таких как ZIP, RAR, 7Z, CAB и т. д.? Форматы ZIP, RAR, 7Z, CAB и другие выполняют сжатие для определенного набора файлов. Как и в случае с дедупликацией данных, оптимизируются повторяющиеся фрагменты внутри файлов и в разных файлах. Однако вам необходимо выбрать файлы, которые должны быть включены в архив. Семантика доступа также отличается. Чтобы получить доступ к определенному файлу в архиве, необходимо открыть архив, выбрать файл, а затем распаковать его для использования. Дедупликация данных работает незаметно для пользователей и администраторов, не требуя никаких ручных операций. Кроме того, дедупликация данных сохраняет семантику доступа — оптимизированные файлы выглядят для пользователя точно так же, как и раньше.
Можно ли изменить параметры дедупликации данных для выбранного типа использования? Да. Хотя дедупликация данных обеспечивает рациональные значения по умолчанию для рекомендуемых рабочих нагрузок, вам может потребоваться настроить параметры для наиболее эффективного использования хранилища. И не забывайте, что в некоторых случаях определенная дополнительная настройка нужна для того, чтобы дедупликация не мешала рабочей нагрузке.
Можно ли вручную запускать задания дедупликации данных? Да, все задания дедупликации данных можно запускать вручную. Это удобно, если запланированное задание не было выполнено из-за недостатка системных ресурсов или ошибки. Кроме того, есть специальное задание отмены оптимизации, которое запускается только вручную.
Можно ли просмотреть историю запусков заданий дедупликации данных? Да, все задания дедупликации данных создают записи в журнале событий Windows.
Можно ли изменить расписание по умолчанию для заданий дедупликации данных? Да, все расписания можно настраивать вручную. Важнее всего изменять расписание дедупликации данных в тех случаях, когда нужно обеспечить достаточное время для завершения заданий, чтобы дедупликация данных не претендовала на ресурсы, требуемые для рабочей нагрузки.