Подготовка к использованию Apache Spark
Apache Spark — это распределенная платформа обработки данных, которая позволяет масштабировать аналитику данных путем координации работы между несколькими узлами обработки в кластере, известной в Microsoft Fabric как пул Spark. Проще говоря, Spark использует подход "разделять и завоевать" для обработки больших объемов данных быстро путем распределения работы на нескольких компьютерах. Процесс распространения задач и сортировки результатов обрабатывается Spark.
Spark может выполнять код, написанный на разных языках, включая Java, Scala (язык сценариев на основе Java), Spark R, Spark SQL и PySpark (вариант Python для конкретного spark). На практике большинство рабочих нагрузок проектирования и аналитики данных выполняются с помощью сочетания PySpark и Spark SQL.
Пулы Spark
Пул Spark состоит из вычислительных узлов, которые распределяют задачи обработки данных. Общая архитектура показана на следующей схеме.
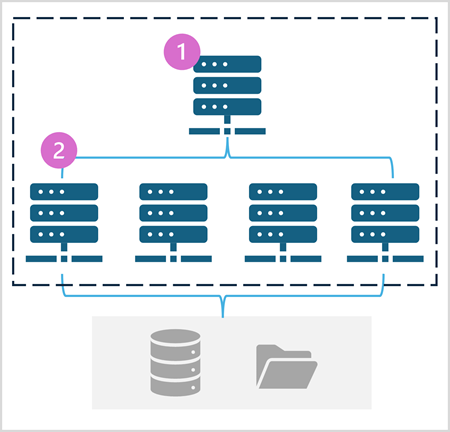
Как показано на схеме, пул Spark содержит два типа узла:
- Головной узел в пуле Spark координирует распределенные процессы через программу драйвера.
- Пул включает несколько рабочих узлов, на которых процессы исполнителя выполняют фактические задачи обработки данных.
Пул Spark использует эту распределенную архитектуру вычислений для доступа к данным и обработки данных в совместимом хранилище данных, например в хранилище озера данных, основанном на OneLake.
Пулы Spark в Microsoft Fabric
Microsoft Fabric предоставляет начальный пул в каждой рабочей области, что позволяет запускать и запускать задания Spark быстро с минимальными параметрами установки и настройки. Начальный пул можно настроить для оптимизации узлов, содержащихся в соответствии с конкретными потребностями рабочей нагрузки или ограничениями затрат.
Кроме того, можно создать настраиваемые пулы Spark с определенными конфигурациями узлов, которые поддерживают определенные потребности в обработке данных.
Примечание.
Возможность настройки параметров пула Spark может быть отключена администраторами Fabric на уровне емкости Fabric. Дополнительные сведения см. в разделе "Параметры администрирования емкости" для Инжиниринг данных и Обработка и анализ данных в документации по Fabric.
Вы можете управлять параметрами начального пула и создавать новые пулы Spark в разделе Инжиниринг данных/Science параметров рабочей области.
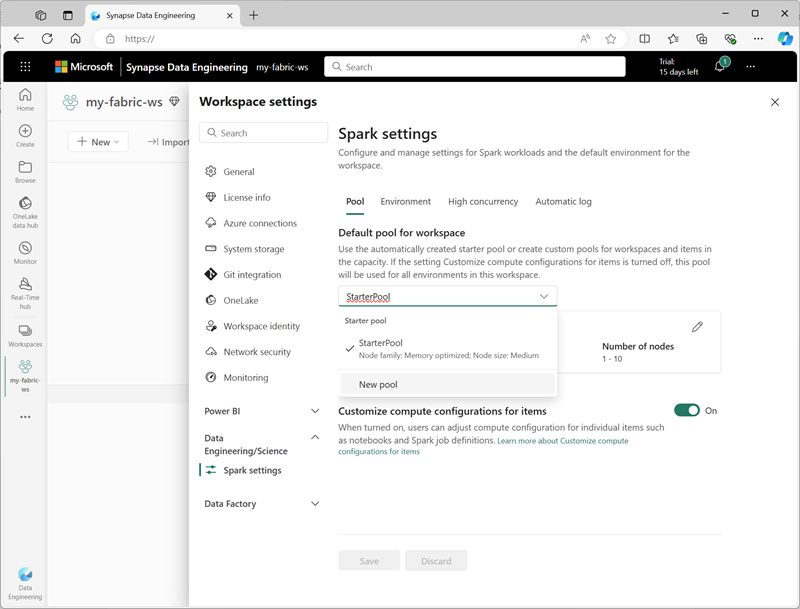
К определенным параметрам конфигурации для пулов Spark относятся:
- Семейство узлов: тип виртуальных машин, используемых для узлов кластера Spark. В большинстве случаев оптимизированные для памяти узлы обеспечивают оптимальную производительность.
- Автомасштабирование: следует ли автоматически подготавливать узлы по мере необходимости, а если да, начальное и максимальное количество узлов, выделенных пулу.
- Динамическое выделение: следует ли динамически выделять процессы исполнителя на рабочих узлах на основе томов данных.
При создании одного или нескольких настраиваемых пулов Spark в рабочей области можно задать один из них (или начальный пул) в качестве пула по умолчанию, если определенный пул не указан для заданного задания Spark.
Совет
Дополнительные сведения об управлении пулами Spark в Microsoft Fabric см. в разделе "Настройка начальных пулов в Microsoft Fabric" и "Как создать настраиваемые пулы Spark в Microsoft Fabric" в документации по Microsoft Fabric.
Среды выполнения и среды
Экосистема Spark открытый код включает несколько версий среды выполнения Spark, которая определяет версию Apache Spark, Delta Lake, Python и другие основные компоненты программного обеспечения, установленные. Кроме того, в среде выполнения можно установить и использовать широкий выбор библиотек кода для распространенных (а иногда и очень специализированных) задач. Так как большая часть обработки Spark выполняется с помощью PySpark, огромный спектр библиотек Python гарантирует, что все задачи, которые необходимо выполнить, вероятно, есть библиотека, чтобы помочь.
В некоторых случаях организациям может потребоваться определить несколько сред для поддержки различных задач обработки данных. Каждая среда определяет определенную версию среды выполнения, а также библиотеки, которые должны быть установлены для выполнения определенных операций. Затем специалисты по обработке и анализу данных могут выбрать среду, которую они хотят использовать с пулом Spark для конкретной задачи.
Среды выполнения Spark в Microsoft Fabric
Microsoft Fabric поддерживает несколько сред выполнения Spark и будет продолжать добавлять поддержку новых сред выполнения по мере их выпуска. Интерфейс параметров рабочей области можно использовать для указания среды выполнения Spark, используемой средой по умолчанию при запуске пула Spark.
Совет
Дополнительные сведения о средах выполнения Spark в Microsoft Fabric см. в документации по Microsoft Fabric в среде выполнения Apache Spark в Fabric .
Среды в Microsoft Fabric
Пользовательские среды можно создавать в рабочей области Fabric, позволяя использовать определенные среды выполнения Spark, библиотеки и параметры конфигурации для различных операций обработки данных.
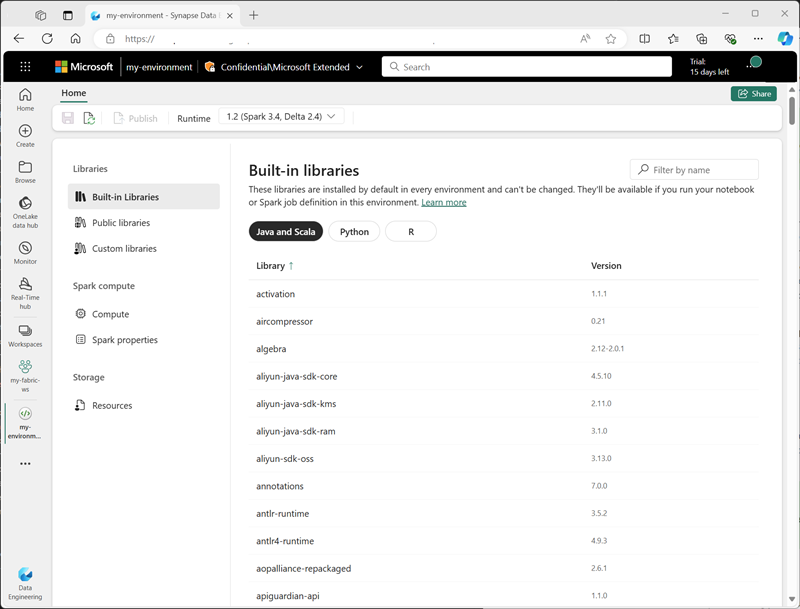
При создании среды можно:
- Укажите среду выполнения Spark, который он должен использовать.
- Просмотрите встроенные библиотеки, установленные в каждой среде.
- Установите определенные общедоступные библиотеки из индекса пакетов Python (PyPI).
- Установите пользовательские библиотеки, отправив файл пакета.
- Укажите пул Spark, который следует использовать в среде.
- Укажите свойства конфигурации Spark, чтобы переопределить поведение по умолчанию.
- Отправьте файлы ресурсов, которые должны быть доступны в среде.
После создания хотя бы одной пользовательской среды ее можно указать в качестве среды по умолчанию в параметрах рабочей области.
Совет
Дополнительные сведения об использовании пользовательских сред в Microsoft Fabric см. в статье "Создание, настройка и использование среды в Microsoft Fabric" в документации по Microsoft Fabric .
Дополнительные параметры конфигурации Spark
Управление пулами и средами Spark — это основные способы управления обработкой Spark в рабочей области Fabric. Однако существуют некоторые дополнительные параметры, которые можно использовать для дальнейшей оптимизации.
Собственный модуль выполнения
Собственный механизм выполнения в Microsoft Fabric — это векторный обработчик обработки, который выполняет операции Spark непосредственно в инфраструктуре Lakehouse. Использование собственного обработчика выполнения может значительно повысить производительность запросов при работе с большими наборами данных в форматах Parquet или Delta.
Чтобы использовать собственный механизм выполнения, его можно включить на уровне среды или в отдельной записной книжке. Чтобы включить собственный обработчик выполнения на уровне среды, задайте следующие свойства Spark в конфигурации среды:
- spark.native.enabled: true
- spark.shuffle.manager: org.apache.spark.shuffle.sort.ColumnarShuffleManager
Чтобы включить собственный обработчик выполнения для определенного скрипта или записной книжки, можно задать следующие свойства конфигурации в начале кода, как показано ниже.
%%configure
{
"conf": {
"spark.native.enabled": "true",
"spark.shuffle.manager": "org.apache.spark.shuffle.sort.ColumnarShuffleManager"
}
}
Совет
Дополнительные сведения о собственном обработчике выполнения см. в документации по Microsoft Fabric в машинном обработчике выполнения для Fabric Spark .
Режим высокой параллелизма
При запуске кода Spark в Microsoft Fabric запускается сеанс Spark. Вы можете оптимизировать эффективность использования ресурсов Spark с помощью режима высокой параллелизма для совместного использования сеансов Spark между несколькими параллельными пользователями или процессами. Если для записных книжек включен режим высокой параллелизма, несколько пользователей могут запускать код в записных книжках, использующих один сеанс Spark, обеспечивая изоляцию кода, чтобы избежать изменения в одной записной книжке, затронутой кодом в другой записной книжке. Вы также можете включить режим высокой параллелизма для заданий Spark, обеспечивая аналогичную эффективность для параллельного неинтерактивного выполнения скрипта Spark.
Чтобы включить режим высокой параллелизма, используйте раздел Инжиниринг данных/Science интерфейса параметров рабочей области.
Совет
Дополнительные сведения о режиме высокого параллелизма см . в разделе "Режим высокой параллелизма" в Apache Spark для Fabric в документации по Microsoft Fabric .
Автоматическое ведение журнала MLFlow
MLFlow — это библиотека открытый код, используемая в рабочих нагрузках обработки и анализа данных для управления обучением машинного обучения и развертыванием моделей. Ключевой возможностью MLFlow является возможность журналов операций обучения и управления моделью. По умолчанию Microsoft Fabric использует MLFlow для неявного журнала действий эксперимента машинного обучения, не требуя, чтобы специалист по обработке и анализу данных включал явный код для этого. Эту функцию можно отключить в параметрах рабочей области.
Администрирование Spark для емкости Fabric
Администраторы могут управлять параметрами Spark на уровне емкости Fabric, что позволяет ограничить и переопределить параметры Spark в рабочих областях в организации.
Совет
Дополнительные сведения об управлении конфигурацией Spark на уровне емкости Fabric см. в статье "Настройка и управление параметрами проектирования данных и обработки и анализа данных" для емкостей Fabric в документации по Microsoft Fabric.