Создание пользовательских пулов Spark в Microsoft Fabric
В этом документе мы объясним, как создать настраиваемые пулы Apache Spark в Microsoft Fabric для рабочих нагрузок аналитики. Пулы Apache Spark позволяют пользователям создавать специализированные вычислительные среды на основе конкретных требований, обеспечивая оптимальную производительность и использование ресурсов.
Вы указываете минимальные и максимальные узлы для автомасштабирования. На основе этих значений система динамически запрашивает и освобождает узлы по мере изменения требований к вычислительным ресурсам задания, что приводит к эффективному масштабированию и повышению производительности. Динамическое выделение исполнителей в пулах Spark также снижает потребность в настройке исполнителя вручную. Вместо этого система настраивает количество исполнителей в зависимости от объема данных и потребностей вычислений на уровне заданий. Этот процесс позволяет сосредоточиться на рабочих нагрузках, не беспокоясь о оптимизации производительности и управлении ресурсами.
Заметка
Чтобы создать пользовательский пул Spark, вам нужен доступ администратора к рабочей области. Администратор емкости должен включить параметр настраиваемых пулов рабочих областей в разделе вычислений Sparkпараметров администратора емкости. Дополнительные сведения см. в разделе Параметры вычислений Spark для емкостей Fabric.
Создание настраиваемых пулов Spark
Чтобы создать или управлять пулом Spark, связанным с вашей рабочей областью:
Перейдите в рабочую область и выберите параметры рабочей области .
Выберите опцию Инженерия данных/Наука, чтобы развернуть меню, а затем выберите настройки Spark.

Выберите опцию Новый пул. На экране Создание пула дайте имя вашему пулу Spark. Также выберите семейство узлов и выберите размер узла из доступных размеров (Маленький, Средний, Большой, Очень большойи Экстра большой) на основе требований к вычислительным ресурсам для ваших рабочих нагрузок.
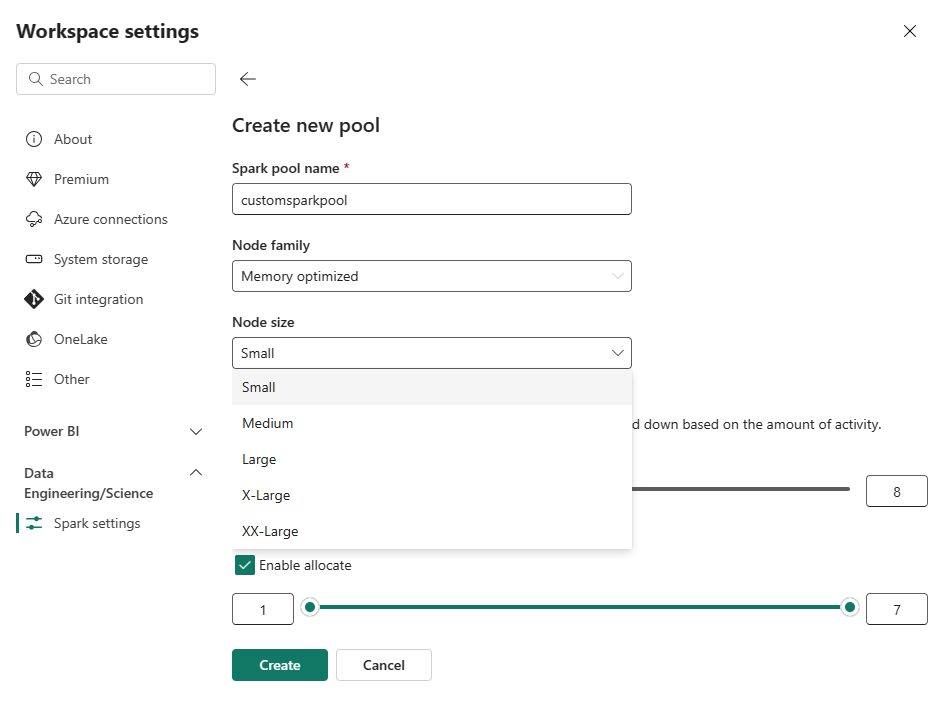
Можно задать минимальную конфигурацию узлов для пользовательских пулов 1. Поскольку Fabric Spark обеспечивает возможность восстановления доступности для кластеров с одним узлом, вам не придется беспокоиться о сбоях в выполнении заданий, потери сеанса во время сбоев или переплате за вычисления для небольших заданий Spark.
Вы можете включить или отключить автомасштабирование для пользовательских пулов Spark. При включении автоматического масштабирования пул динамически получает новые узлы до максимального предела узла, указанного пользователем, а затем удаляет их после выполнения задания. Эта функция обеспечивает более высокую производительность, изменяя ресурсы на основе требований задания. Вы можете изменить размер узлов так, чтобы они вписывались в единицы емкости, приобретенные в рамках SKU для емкости Fabric.
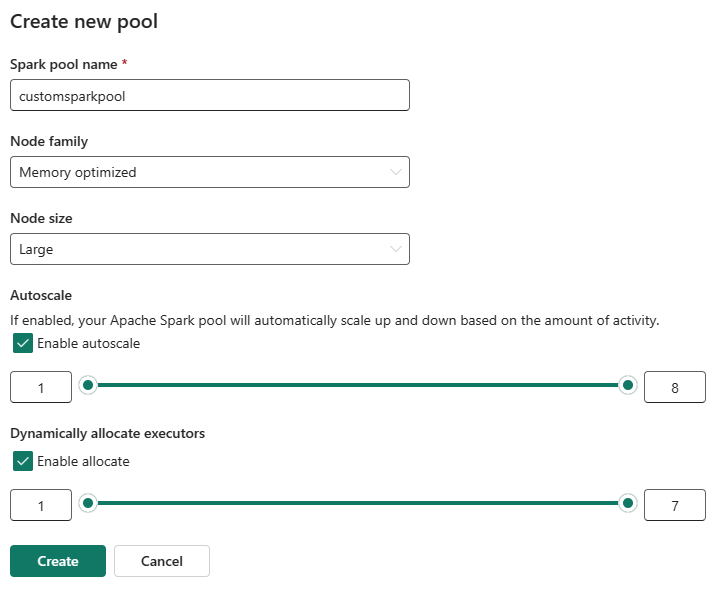
Вы также можете включить динамическое выделение исполнителя для пула Spark, которое автоматически определяет оптимальное количество исполнителей в пределах указанной пользователем максимальной границы. Эта функция настраивает количество исполнителей на основе тома данных, что приводит к повышению производительности и использованию ресурсов.

Эти настраиваемые пулы имеют продолжительность автопаузы по умолчанию 2 минуты. После достижения длительности автопаузы сеанс завершается, а кластеры освобождаются. Плата взимается в зависимости от количества узлов и длительности использования настраиваемых пулов Spark.
Связанное содержимое
- Подробнее см. в общедоступной документации по Apache Spark .
- Начало работы с параметрами администрирования рабочей области Spark в MicrosoftFabric.