Общие сведения об индексах columnstore
Применимо к:![]() SQL Server
SQL Server![]() База данных SQL Azure
База данных SQL Azure![]() Управляемый экземпляр SQL Azure
Управляемый экземпляр SQL Azure![]() Azure Synapse Analytics
Azure Synapse Analytics![]() Система аналитической платформы (PDW)
Система аналитической платформы (PDW)![]() SQL база данных в Microsoft Fabric
SQL база данных в Microsoft Fabric
Индексы columnstore являются стандартом для хранения и запросов к большим фактическим таблицам в хранилище данных. При этом используется формат хранения данных в столбцах и выполняется соответствующая обработка запросов, что позволяет практически в 10 раз повысить производительность запросов к хранилищу данных по сравнению с традиционным хранилищем, в котором данные хранятся в строках. Также, можно добиться 10-кратного сжатия данных относительно несжатых данных. Начиная с версии SQL Server 2016 (13.x) с пакетом обновления 1 (SP1), индексы columnstore позволяют выполнять операционную аналитику — производительный анализ транзакционной рабочей нагрузки в реальном времени.
Дополнительные сведения о связанных сценариях:
- Индексы Columnstore в хранилище данных
- Начните с Columnstore для операционной аналитики в реальном времени
Что такое индекс columnstore?
Индекс columnstore — это технология хранения и получения данных, а также управления ими с помощью формата хранения данных в столбцах, называемого columnstore.
Основные термины и понятия
Следующие основные концепции и понятия связаны с индексами columnstore.
Columnstore
Columnstore — это данные, которые логически организованы в виде таблицы, состоящей из строк и столбцов, и физически сохраняются в формате, где данные хранятся по столбцам.
Rowstore
Rowstore — это способ хранения данных, при котором они логически организованы в виде таблицы из строк и столбцов и физически размещаются в строковом формате хранения. Это стандартный способ хранения реляционных данных таблиц. В SQL Server rowstore ссылается на таблицу, в которой базовый формат хранилища данных — куча, кластеризованный индекс или оптимизированная для памяти таблица.
Примечание.
В обсуждениях индексов columnstore для обозначения формата хранения данных используются термины rowstore и columnstore.
Группа строк
Rowgroup — это группа строк, сжимаемых в формате columnstore одновременно. Rowgroup обычно содержит максимальное возможное число строк — 1 048 576 строк.
Чтобы добиться высокой производительности и высокого уровня сжатия, индекс columnstore разделяет таблицы на группы rowgroup, каждая из которых затем сжимается на уровне столбцов. Число строк в группе строк должно быть достаточно большим, чтобы повысить скорость сжатия, и достаточно малым для использования преимуществ использования операций в памяти.
Группа строк, из которой удалены все данные, переходит из состояния COMPRESSED в состояние TOMBSTONE, а затем удаляется фоновым процессом с названием tuple-mover. См. сведения о состояниях групп строк в статье sys.dm_db_column_store_row_group_physical_stats (Transact-SQL).
Совет
Слишком большое количество небольших групп строк ухудшает качество индекса columnstore. До SQL Server 2017 (14.x) требуется реорганизовать операцию для объединения небольших сжатых групп строк, следуя внутренней политике порогового значения, которая определяет, как удалить удаленные строки и объединить сжатые группы строк.
Начиная с SQL Server 2019 (15.x), фоновая задача слияния также работает для слияния групп строк COMPRESSED, из которых было удалено большое количество строк.
После объединения небольших групп строк качество индекса улучшается.
Примечание.
Начиная с SQL Server 2019 (15.x), Azure SQL Database, Azure SQL Managed Instance и выделенных пулов SQL в системе Azure Synapse Analytics, перемещению кортежей способствует фоновая задача слияния, которая автоматически сжимает небольшие дельта-группы строк, которые существовали в течение некоторого времени, определенного внутренним порогом, или объединяет сжатые группы строк, из которых было удалено большое количество строк. Со временем это улучшает качество columnstore-индекса.
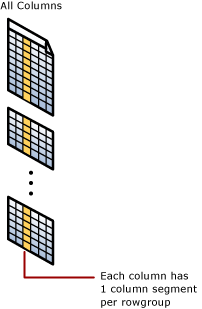
Сегмент столбца
Сегмент столбца — это столбец данных из rowgroup.
- Каждая rowgroup содержит один сегмент столбца для каждого столбца в таблице.
- Каждый сегмент столбца сжимается одновременно и сохраняется на физическом носителе.
- Метаданные с каждым сегментом позволяют быстро устранять сегменты, не считывая их.
Кластеризованный индекс колонночного хранилища
Кластеризованный индекс columnstore — это физическое хранилище для всей таблицы.

Чтобы снизить фрагментацию сегментов столбцов и повысить производительность, индекс columnstore может временно сохранять некоторые данные в кластеризованный индекс, который называется deltastore, а также использовать список идентификаторов на основе сбалансированного дерева для удалённых строк. Операции deltastore обрабатываются в фоновом режиме. Для возвращения правильных результатов запроса кластеризованный индекс columnstore объединяет результаты запроса из columnstore и deltastore.
Примечание.
В документации термин B-tree обычно используется в ссылке на индексы. В индексах rowstore ядро СУБД реализует дерево B+. Это не относится к индексам columnstore или индексам в таблицах, оптимизированных для памяти. Дополнительные сведения см. в руководстве по архитектуре и проектированию индексов SQL Sql Server и Azure.
Группа строк Дельта
Разностная группа строк — это кластеризованный индекс сбалансированного дерева, который используется только с индексами columnstore. Она улучшает сжатие columnstore и производительность, храня строки до тех пор, пока их количество не достигнет порогового значения (1 048 576 строк), после чего строки перемещаются в columnstore.
Когда количество строк в «дельта-группе строк» достигает максимального значения, состояние группы меняется с «OPEN» на «CLOSED». Фоновый процесс под названием tuple-mover проверяет закрытые группы строк. При обнаружении завершенной группы строк, группа строк дельта сжимается и сохраняется в колоночном хранилище в сжатом состоянии.
Когда разностная группа строк сжимается, существующая разностная группа строк становится в состояние TOMBSTONE, которое позже удаляется механизмом перемещения кортежей, если на него больше нет ссылок.
См. сведения о состояниях групп строк в статье sys.dm_db_column_store_row_group_physical_stats (Transact-SQL).
Примечание.
Начиная с SQL Server 2019 (15.x), перемещателю кортежей помогает фоновая задача слияния, которая автоматически сжимает небольшие дельта-группы строк OPEN, существующие в течение определенного времени по внутреннему пороговому значению, или объединяет сжатые группы строк, из которых было удалено большое количество строк. Это со временем повышает качество индекса columnstore.
Deltastore
Индекс columnstore может содержать более одной дельта-группы строк. Все дельта-группы строк в совокупности называются deltastore.
При крупной массовой загрузке большая часть строк направляется непосредственно в columnstore, минуя deltastore. Некоторых строк в конце массовой загрузки может оказаться слишком мало для соответствия минимальному размеру rowgroup, составляющему 102 400 строк. В результате этого последние строки переходят в deltastore вместо columnstore. Для небольших массовых загрузок с менее чем 102 400 строками все строки сразу же направляются в deltastore.
некластеризованный колоночный индекс
Некластеризованный индекс columnstore и кластеризованный индекс columnstore функционируют по одному принципу. Разница в том, что некластеризованный индекс вторичен и создается на основе таблицы индексов rowstore, а кластеризованный индекс columnstore является первичным хранилищем для всей таблицы.
Некластеризованный индекс содержит копию всех или части строк и столбцов в базовой таблице. Индекс определяется как один или несколько столбцов таблицы и включает дополнительное условие для фильтрации строк.
Некластеризованный индекс columnstore позволяет осуществлять операционную аналитику в реальном времени, когда рабочая нагрузка OLTP выполняется с использованием базового кластеризованного индекса, а аналитика при этом проводится параллельно на основе индекса columnstore. Дополнительные сведения см. в статье Начало работы с Columnstore для получения операционной аналитики в реальном времени.
выполнение в пакетном режиме.
Пакетный режим выполнения — это метод обработки запросов, при котором обрабатываются сразу несколько строк. Выполнение в пакетном режиме тесно интегрировано с форматом хранения "columnstore" и оптимизировано под него. Пакетный режим выполнения иногда называется выполнением на основе векторов или векторизированным выполнением. В запросах к индексам columnstore используется режим пакетного выполнения, что обычно повышает производительность запросов в 2–4 раза. Дополнительные сведения см. в статье Руководство по архитектуре обработки запросов.
Почему следует использовать индекс columnstore?
Индекс columnstore обеспечивает высокую (обычно десятикратную) степень сжатия данных, что позволяет существенно снизить затраты на хранение данных. Для аналитики столбцовый индекс обеспечивает на порядок лучшую производительность по сравнению с индексом B-дерева. Индексы columnstore — это предпочтительный формат для хранения данных и выполнения аналитики. Начиная с SQL Server 2016 (13.x), можно использовать индексы columnstore для аналитики в режиме реального времени в рабочей нагрузке.
Почему индексы columnstore такие быстрые.
В столбцах хранятся значения из одного и того же домена, которые часто похожи, что позволяет добиться высокой степени сжатия данных. Узкие места в системе, связанные с операциями ввода-вывода, сведены к минимуму или отсутствуют, а объем используемой памяти существенно сокращается.
Высокие степени сжатия повышают производительность запросов с помощью малого отпечатка в памяти. В свою очередь, производительность запросов может повыситься, так как SQL Server может выполнять больше операций запросов и данных в памяти.
Пакетное выполнение повышает эффективность запросов (обычно в 2–4 раза) благодаря обработке сразу нескольких строк.
Часто запросы выбирают только несколько столбцов из таблицы, что сокращает общее число операций ввода-вывода для физического носителя.
Когда следует использовать индекс Columnstore?
Рекомендуемые варианты использования
Используйте кластеризованный columnstore-индекс для хранения таблиц фактов и больших таблиц размерностей для рабочих нагрузок хранилищ данных. Этот метод повышает эффективность запросов и сжатие данных практически в 10 раз. Дополнительные сведения см. в статье об использовании индексов columnstore для хранения данных.
Используйте некластеризованный индекс columnstore для анализа рабочей нагрузки OLTP в режиме реального времени. Дополнительные сведения см. в статье Начало работы с Columnstore для получения операционной аналитики в реальном времени.
Дополнительные сценарии использования для индексов columnstore см. в разделе "Выбор оптимального индекса columnstore" для ваших потребностей.
Как сделать выбор между индексами rowstore и columnstore?
Индексы rowstore лучше всего работают с запросами, направленными на поиск данных или определенного значения, а также с запросами в небольших диапазонах данных. Используйте индексы rowstore с транзакционными рабочими нагрузками, так как для них чаще требуется поиск по таблицам, а не сканирование таблиц.
Индексы columnstore обеспечивают значительное повышение производительности при выполнении аналитических запросов, которые сканируют большие объемы данных (в частности, большие таблицы). Используйте индексы columnstore с рабочими нагрузками по хранению и аналитике данных (в частности, с таблицами фактов), так как для них чаще требуется полное сканирование таблиц, а не поиск по таблицам.
Упорядоченные кластеризованные индексы columnstore повышают производительность запросов на основе упорядоченных предикатов столбцов. Упорядоченные индексы columnstore могут улучшить исключение групп строк, что может привести к повышению производительности, полностью пропуская группы строк. Дополнительные сведения см. в разделе Настройка производительности с упорядоченными индексами columnstore. Сведения о доступности упорядоченного columnstore индекса см. в разделе Доступность упорядоченного индекса columnstore.
Можно ли использовать хранение строк (rowstore) и хранение столбцов (columnstore) в одной и той же таблице?
Да. Начиная с SQL Server 2016 (13.x), можно создать обновляемый некластеризованный индекс columnstore в таблице rowstore. В columnstore индексе хранится копия выбранных столбцов, поэтому для этих данных требуется дополнительное пространство, но выбранные данные в среднем сжимаются в 10 раз. Вы сможете выполнять аналитику на основе индекса columnstore и транзакции на основе индекса rowstore одновременно. Columnstore обновляется при каждом изменении данных в таблице rowstore, поэтому оба индекса работают с одними и теми же данными.
Начиная с SQL Server 2016 (13.x), вы можете иметь один или несколько некластеризованных индексов rowstore в индексе columnstore и эффективно выполнять поиск в базовом хранилище столбцов. Кроме того, появляется доступ к другим возможностям. Например, можно принудительно задать ограничение PRIMARY KEY, применив к таблице rowstore ограничение UNIQUE. Так как неуниковое значение не вставляется в таблицу rowstore, SQL Server не может вставить значение в columnstore.
Упорядоченные колоночные индексы
Благодаря включению функции эффективной ликвидации сегментов, индексы columnstore с упорядочиванием обеспечивают более высокую производительность, пропуская большие объемы упорядоченных данных, не соответствующих условиям запроса. Загрузка данных в упорядоченный индекс columnstore может занять больше времени, чем в неупорядоченный индекс из-за операции сортировки данных, однако с упорядоченными индексами columnstore запросы могут выполняться быстрее после этого.
- Дополнительные сведения о настройке производительности рабочих нагрузок хранилищ данных в SQL Server Database Engine с упорядоченными колоночными индексами см. в разделе Настройка производительности с упорядоченными колоночными индексами.
- Дополнительные сведения об использовании типа индекса columnstore см. в разделе "Выбор оптимального индекса columnstore" для ваших потребностей.
Доступность сортированного индекса columnstore
Впервые появилось ![]() SQL Server 2022 (16.x), упорядоченные индексы columnstore доступны на следующих платформах:
SQL Server 2022 (16.x), упорядоченные индексы columnstore доступны на следующих платформах:
| Платформа | Упорядоченные кластеризованные индексы columnstore | Упорядоченные некластеризованные индексы columnstore |
|---|---|---|
| База данных SQL Azure | Да | Да |
| Управляемый экземпляр SQL AzureAUTD | Да | Да |
| Управляемый экземпляр SQL Azure2022 | Да | Нет |
| База данных SQL в Microsoft Fabric | Да1 | Да |
| SQL Server 2022 (16.x) | Да | Нет |
| Выделенный пул SQL в Azure Synapse Analytics | Да | Нет |
AUTD применяется к Управляемому экземпляру SQL Azure, настроенной с помощью политики обновленияAlways-up-to-date.
2022 Применяется к Управляемому экземпляру Azure SQL, настроенному с политикой обновления SQL Server 2022.
1в базе данных SQL Fabric таблицы с кластеризованными индексами columnstore не зеркально отображены в Fabric OneLake.
Метаданные
Все столбцы в индексе columnstore хранятся в метаданных как включенные столбцы. Индекс columnstore не имеет ключевых столбцов.
Связанные задачи
Для всех реляционных таблиц, не заданных как кластеризованный индекс columnstore, в качестве базового формата данных используется индекс rowstore.
CREATE TABLE создает таблицу rowstore, если не указан параметр WITH CLUSTERED COLUMNSTORE INDEX.
С помощью оператора CREATE TABLE можно создать таблицу в формате columnstore, указав параметр WITH CLUSTERED COLUMNSTORE INDEX. Чтобы конвертировать таблицу rowstore в columnstore, используйте инструкцию CREATE COLUMNSTORE INDEX.
| Задача | Справочные статьи | Примечания. |
|---|---|---|
| Создать таблицу в формате columnstore. | CREATE TABLE (Transact-SQL) | Начиная с SQL Server 2016 (13.x), можно создать таблицу в виде кластеризованного индекса columnstore. Для этого не нужно сначала создавать таблицу rowstore, а затем конвертировать ее в columnstore. |
| Создайте оптимизированную для памяти таблицу с индексом columnstore. | CREATE TABLE (Transact-SQL) | Начиная с SQL Server 2016 (13.x), можно создать оптимизированную для памяти таблицу с индексом columnstore. Индекс columnstore можно добавить и после создания таблицы, используя синтаксис ALTER TABLE ADD INDEX. |
| Преобразование таблицы rowstore в таблицу columnstore | CREATE COLUMNSTORE INDEX (Transact-SQL) | Преобразуйте существующую кучу или B-дерево в колоночное хранилище. В примерах показано, как обрабатывать существующие индексы, а также имя индекса, которое нужно использовать в процессе преобразования. |
| Преобразование таблицы columnstore в rowstore | CREATE CLUSTERED INDEX (Transact-SQL) или Преобразовать таблицу columnstore обратно в кучу rowstore | Обычно это преобразование не требуется, но бывают ситуации, когда оно необходимо. В примерах показано, как преобразовать columnstore в кучу или кластеризованный индекс. |
| Создайте индекс columnstore в таблице rowstore. | CREATE COLUMNSTORE INDEX (Transact-SQL) | Таблица rowstore может включать один индекс columnstore. Начиная с SQL Server 2016 (13.x), индекс columnstore может иметь отфильтрованное условие. В примерах показан основной синтаксис. |
| Создание высокопроизводительных индексов для оперативной аналитики | Начните использовать Columnstore для анализации операционных данных в реальном времени | Описывает, как создать дополнительные индексы columnstore и индексы B-дерева, чтобы запросы OLTP использовали индексы B-дерева, а аналитические запросы использовали индексы columnstore. |
| Создайте высокопроизводительные индексы columnstore для хранилищ данных. | Индексы колумнстоур для хранилищ данных | Описывает использование индексов B-дерева в колонковых таблицах для создания высокопроизводительных запросов к хранилищу данных. |
| Используйте индекс B-дерева для принудительного применения ограничения первичного ключа к индексу колоночного хранилища. | Столбцовые индексы для хранилищ данных | Показывается, как объединить B-деревья и колонночные индексы для обеспечения ограничений первичного ключа на колонночном индексе. |
| Удалите индекс columnstore. | DROP INDEX (Transact-SQL) | Для удаления индекса columnstore используется стандартный синтаксис DROP INDEX, применяемый для B-деревьев. При удалении кластеризованного индекса колонкового хранилища данных таблица преобразуется в кучу. |
| Удалите строку из индекса columnstore. | DELETE (Transact-SQL) | Удалите строку с помощью DELETE (Transact-SQL ). Строка columnstore: SQL Server помечает строку как логически удалённую, но не освобождает физическое хранилище для строки, пока индекс не перестроится. deltastore строка: SQL Server логически и физически удаляет строку. |
| Обновление строки в индексе columnstore. | UPDATE (Transact-SQL) | Чтобы обновить строку, используйте UPDATE (Transact-SQL). Строка columnstore: SQL Server помечает строку как логически удаленной, а затем вставляет обновленную строку в deltastore. строка deltastore: SQL Server обновляет строку в deltastore. |
| Загрузка данных в колонковый индекс. | Загрузка данных в индексы columnstore | |
| Принудительное перемещение всех строк из deltastore в columnstore |
ALTER INDEX (Transact-SQL) ... REBUILDОптимизация обслуживания индексов позволяет повысить производительность запросов и снизить уровень потребления ресурсов |
Инструкция ALTER INDEX с параметром REBUILD принудительно перемещает все строки в columnstore. |
| Дефрагментируйте индекс столбчатого хранилища. | ALTER INDEX (Transact-SQL) | Инструкция ALTER INDEX ... REORGANIZE дефрагментирует индексы columnstore в оперативном режиме. |
| Слияние таблиц с индексами columnstore. | MERGE (Transact-SQL) |
Связанный контент
- Новые возможности индексов columnstore
- Индексы для колонночного хранения данных - Руководство по загрузке данных
- Индексы columnstore - производительность запросов
- Приступите к работе с Columnstore для оперативной операционной аналитики в реальном времени
- Колонночные индексы в хранилище данных
- Дефрагментация индексов колоностора
- Руководство по архитектуре и разработке индексов SQL Server и Azure SQ
- Архитектура индекса columnstore
- CREATE COLUMNSTORE INDEX (Transact-SQL)