Что такое Apache Flink® в Azure HDInsight в AKS? (предварительная версия)
Важный
Azure HDInsight на AKS завершил своё действие 31 января 2025 г. Узнайте больше из этого объявления.
Необходимо перенести рабочие нагрузки в Microsoft Fabric или эквивалентный продукт Azure, чтобы избежать резкого завершения рабочих нагрузок.
Важный
Эта функция сейчас доступна в предварительной версии. Дополнительные условия использования для предварительных версий Microsoft Azure включают дополнительные юридические термины, применимые к функциям Azure, которые находятся в бета-версии, в предварительной версии или в противном случае еще не выпущены в общую доступность. Сведения об этой конкретной предварительной версии см. в Azure HDInsight в предварительной версии AKS. Для вопросов или предложений функций отправьте запрос на AskHDInsight с подробными сведениями и следуйте за дополнительными обновлениями в Azure HDInsight Community.
Apache Flink — это платформа и подсистема распределенной обработки для вычислений с отслеживанием состояния по несвязанным и привязанным потокам данных. Flink был разработан для работы во всех распространённых средах кластеров, выполнения вычислений и приложений для потоковой передачи с сохранением состояния на скорости оперативной памяти и в любом масштабе. Приложения параллелизуются на, возможно, тысячи задач, которые распределяются и одновременно выполняются в кластере. Поэтому приложение может использовать неограниченное количество виртуальных ЦП, основной памяти, дискового и сетевого ввода-вывода. Кроме того, Flink легко поддерживает большое состояние приложения. Его асинхронный и инкрементный алгоритм контрольных точек обеспечивает минимальное влияние на задержки обработки при гарантии точной согласованности состояния.
Apache Flink — это масштабируемый модуль аналитики для потоковой обработки.
Ниже приведены некоторые ключевые функции, которые предлагает Flink:
- Операции с привязанными и несвязанными потоками
- Производительность при работе с памятью
- Возможность потоковой передачи и пакетных вычислений
- Низкая задержка, операции высокой пропускной способности
- Обработка ровно один раз
- Высокий уровень доступности
- Состояние и отказоустойчивость
- Полностью совместим с экосистемой Hadoop
- Унифицированные API SQL для потокового и пакетного пакетов
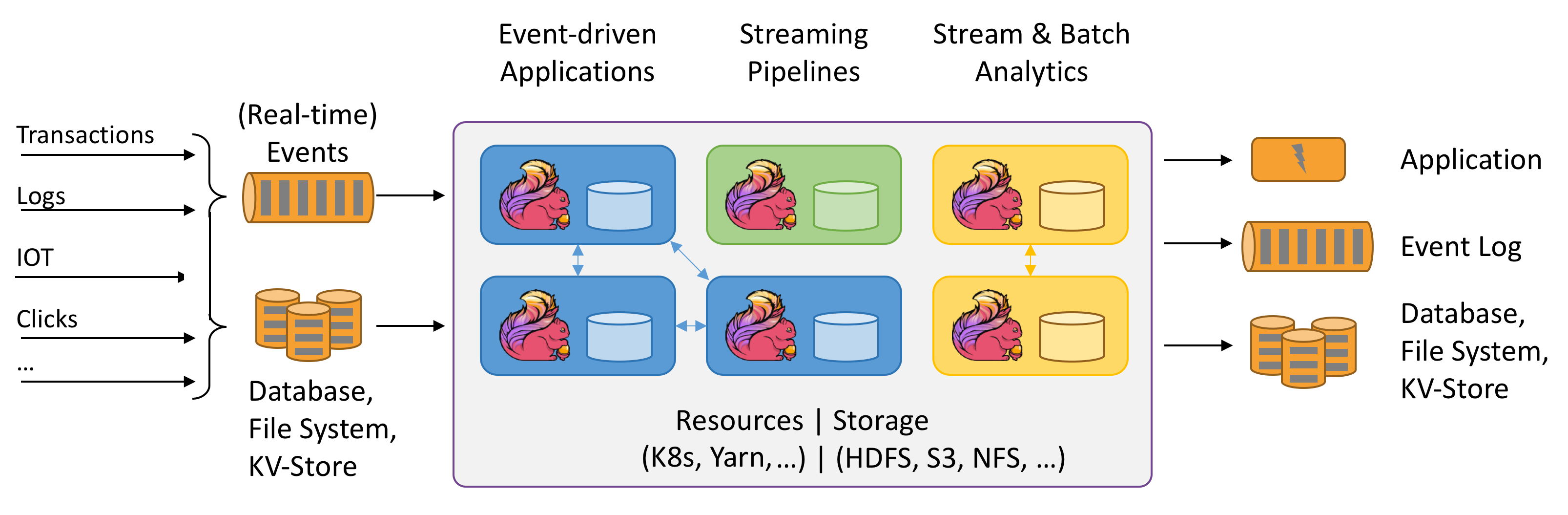
Почему Apache Flink?
Apache Flink — отличный выбор для разработки и запуска различных типов приложений из-за его обширного набора функций. Функции Flink включают поддержку потоковой и пакетной обработки, сложное управление состоянием, семантику обработки событий во времени и гарантии точной единовременной согласованности для управления состоянием. Flink не имеет единой точки сбоя. Способность Flink масштабироваться до тысяч ядер и терабайтов состояния приложения доказана. Он обеспечивает высокую пропускную способность и низкую задержку, а также поддерживает одни из самых требовательных приложений потоковой обработки в мире.
- обнаружение мошенничества: Flink можно использовать для обнаружения мошеннических транзакций или действий в режиме реального времени путем применения сложных правил и моделей машинного обучения для потоковой передачи данных.
- обнаружение аномалий: Flink можно использовать для выявления выбросов или аномальных паттернов в потоковых данных, таких как показатели датчиков, сетевой трафик или поведение пользователя.
- оповещения на основе правил: Flink можно использовать для активации оповещений или уведомлений на основе предопределенных условий или пороговых значений потоковых данных, таких как температура, давление или цены на акции.
- мониторинг бизнес-процессов: Flink можно использовать для отслеживания и анализа состояния и производительности бизнес-процессов или рабочих процессов в режиме реального времени, таких как выполнение заказов, доставка или обслуживание клиентов.
- веб-приложение (социальная сеть): Flink можно использовать для работы веб-приложений, требующих обработки данных, созданных пользователем в реальном времени, таких как сообщения, лайки, комментарии или рекомендации.
Узнайте больше о распространенных вариантах использования, описанных в случаях использования Apache Flink
Кластеры Apache Flink в HDInsight в AKS — это полностью управляемая служба. Ниже перечислены преимущества создания кластера Flink в HDInsight в AKS.
| Особенность | Описание |
|---|---|
| Облегчение создания | Вы можете создать новый кластер Flink в HDInsight в минутах с помощью портала Azure, Azure PowerShell или пакета SDK. См. начало работы с кластером Apache Flink в HDInsight в AKS. |
| Простота использования | Кластеры Flink в HDInsight на AKS включают управление конфигурацией через портал и масштабирование. Помимо этого с API управления заданиями, вы используете REST API или портал Azure для управления заданиями. |
| REST API | Кластеры Flink в HDInsight на AKS включают API управления заданиями, метод отправки заданий Flink через REST API для удаленной отправки и мониторинга заданий на портале Azure. |
| Тип развертывания | Flink может выполнять приложения в режиме сеанса или в режиме приложения. В настоящее время HDInsight в AKS поддерживает только кластеры сеансов. В кластере сеансов можно выполнять несколько заданий Flink. Режим приложения включён в дорожную карту для HDInsight на кластерах AKS. |
| Поддержка хранилища метаданных | Кластеры Flink в HDInsight в AKS могут поддерживать каталоги с хранилище метаданных Hive в разных открытых форматах файлов с удаленными контрольными точками в Azure Data Lake Storage 2-го поколения. |
| Поддержка службы хранилища Azure | Кластеры Flink в HDInsight могут использовать Azure Data Lake Storage 2-го поколения в качестве приемника файлов. Дополнительные сведения о Data Lake Storage 2-го поколения см. в Azure Data Lake Storage 2-го поколения. |
| Интеграция со службами Azure | Кластер Flink в HDInsight на AKS поставляется с интеграцией с Kafka, а также с Azure Event Hubs и Azure HDInsight. Вы можете создавать приложения потоковой передачи с помощью Центров событий или HDInsight. |
| Приспособляемость | HDInsight в AKS позволяет масштабировать узлы кластера Flink на основе расписания с помощью функции автомасштабирования. См. автоматическое масштабирование Azure HDInsight в кластерах AKS. |
| Механизм управления состоянием | HDInsight в AKS использует RocksDB в качестве stateBackend по умолчанию. RocksDB — это встраиваемое хранилище сохраняемых значений ключей для быстрого хранения. |
| Контрольные точки | Ведение контрольных точек включено в HDInsight на кластерах AKS по умолчанию. Параметры по умолчанию в HDInsight в AKS поддерживают последние пять контрольных точек в постоянном хранилище. В случае сбоя задания задание может быть перезапущено с последней контрольной точки. |
| Добавочные контрольные точки | RocksDB поддерживает добавочные контрольные точки. Мы рекомендуем использовать добавочные контрольные точки для большого состояния, необходимо включить эту функцию вручную. Установка значения по умолчанию в flink-conf.yaml: state.backend.incremental: true включает инкрементные контрольные точки, если только приложение не переопределяет этот параметр в коде. Это утверждение является верным по умолчанию. Можно также настроить это значение непосредственно в коде (переопределяет конфигурацию по умолчанию) EmbeddedRocksDBStateBackend` backend = new `EmbeddedRocksDBStateBackend(true);. По умолчанию мы сохраняем последние пять контрольных точек в настроенном каталоге контрольных точек. Это значение можно изменить, изменив конфигурацию в разделе управления конфигурацией state.checkpoints.num-retained: 5 |
Кластеры Apache Flink в HDInsight в AKS включают следующие компоненты, они доступны в кластерах по умолчанию.
Обратитесь к дорожной карте, чтобы узнать, что ожидается скоро!
Управление заданиями Apache Flink
Flink планирует задания с помощью трех распределенных компонентов, диспетчера заданий, диспетчера задач и клиента заданий, которые задаются в шаблоне Leader-Follower.
задание Flink: задание или программа Flink состоит из нескольких задач. Задачи — это базовая единица выполнения в Flink. Каждая задача Flink имеет несколько экземпляров в зависимости от уровня параллелизма, и каждый экземпляр выполняется в TaskManager.
диспетчер заданий: диспетчер заданий выступает в качестве планировщика и планирует задачи в диспетчерах задач.
диспетчер задач: диспетчеры задач поставляются с одним или несколькими слотами для параллельного выполнения задач.
клиент задания: клиент задания взаимодействует с диспетчером заданий для отправки Flink-заданий
Веб-интерфейс Flink: Flink располагает веб-интерфейсом для проверки, мониторинга и отладки запущенных приложений.
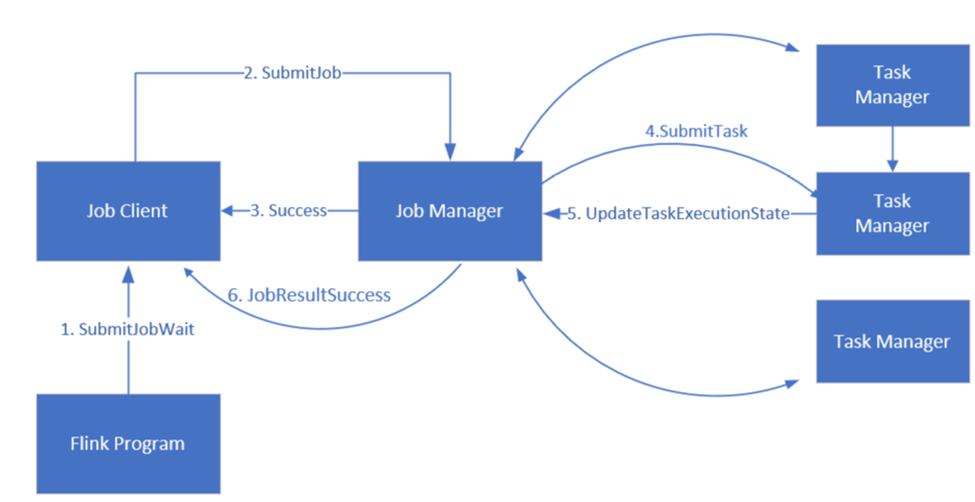
Ссылка
- веб-сайт Apache Flink
- Apache, Apache Kafka, Kafka, Apache Flink, Flink и другие названия связанных с ними проектов с открытым исходным кодом являются товарными знакамиApache Software Foundation (ASF).