Использование Apache Kafka® и Apache Flink® в HDInsight на AKS
Важный
Azure HDInsight на AKS снято с обслуживания 31 января 2025 г. Дополнительные сведения в этом объявлении.
Необходимо перенести рабочие нагрузки в Microsoft Fabric или эквивалентный продукт Azure, чтобы избежать резкого завершения рабочих нагрузок.
Важный
Эта функция сейчас доступна в предварительной версии. Дополнительные условия использования для предварительных версий Microsoft Azure включают дополнительные юридические термины, применимые к функциям Azure, которые находятся в бета-версии, в предварительной версии или в противном случае еще не выпущены в общую доступность. Сведения об этой конкретной предварительной версии см. в Azure HDInsight в предварительной версии AKS. Для вопросов или предложений функций отправьте запрос на AskHDInsight с подробными сведениями и следуйте за дополнительными обновлениями в Azure HDInsight Community.
Хорошо известный вариант использования Apache Flink — это stream analytics. Популярный выбор среди пользователей — использование потоков данных, обрабатываемых с помощью Apache Kafka. Типичная установка Flink и Kafka начинается с того, что потоки событий отправляются в Kafka, чтобы их могли использовать задания Flink.
В этом примере используется HDInsight на кластерах AKS с Flink 1.17.0 для обработки потоковых данных, которые потребляют и создают темы Kafka.
Заметка
FlinkKafkaConsumer устарел и будет удален с Flink 1.17, используйте KafkaSource вместо этого. FlinkKafkaProducer устарел и будет удален с Flink 1.15, используйте KafkaSink вместо этого.
Необходимые условия
Как Kafka, так и Flink должны находиться в одной виртуальной сети или между двумя кластерами должен быть пиринг между виртуальными сетями.
создание кластера Kafka в той же виртуальной сети. Вы можете выбрать Kafka 3.2 или 2.4 в HDInsight на основе текущего использования.
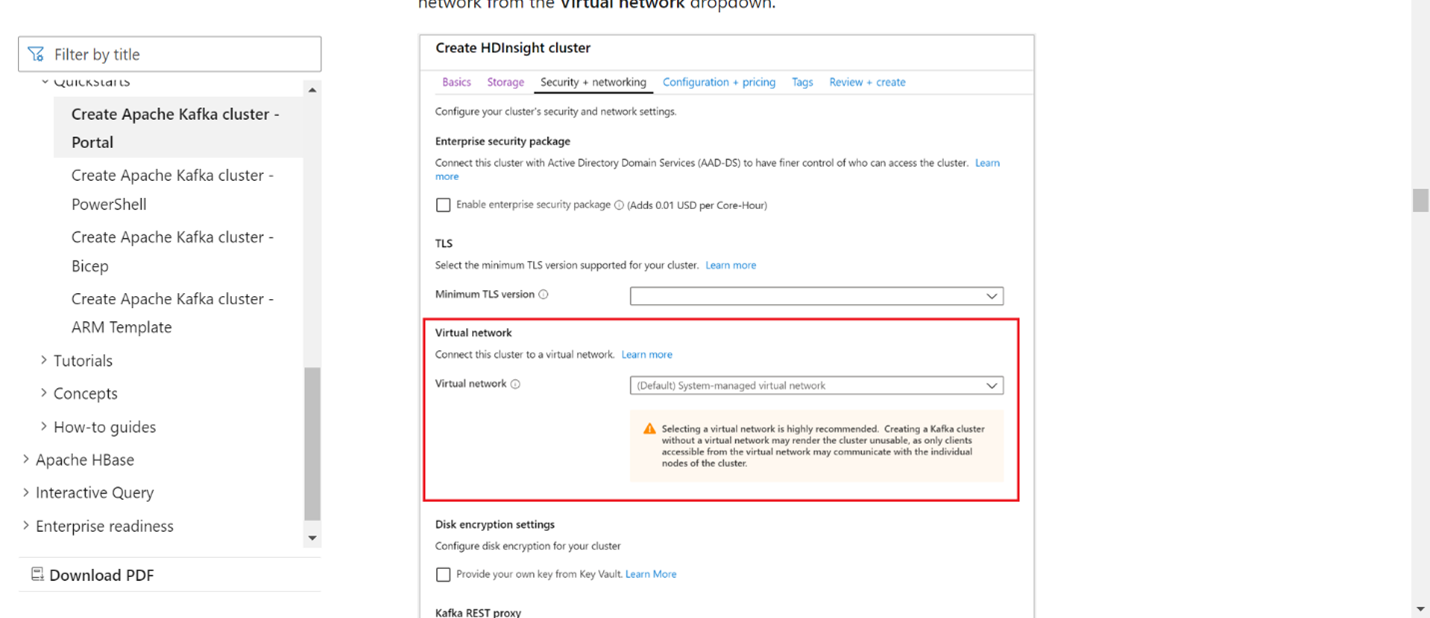
Добавьте сведения о виртуальной сети в разделе виртуальной сети.
Создайте HDInsight в пуле кластеров AKS с той же виртуальной сетью.
Создайте кластер Flink для созданного пула кластеров.

Соединитель Apache Kafka
Flink предоставляет коннектор Apache Kafka для чтения данных из и записи данных в разделы Kafka с гарантией 'ровно один раз'.
зависимость Maven
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-kafka</artifactId>
<version>1.17.0</version>
</dependency>
Строительство приемника Kafka
Приемник Kafka предоставляет класс для построения экземпляра KafkaSink. Мы используем тот же подход для создания нашего приемника и применяем его вместе с кластером Flink, работающим на платформе HDInsight в AKS
SinKafkaToKafka.java
import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.common.serialization.SimpleStringSchema;
import org.apache.flink.connector.base.DeliveryGuarantee;
import org.apache.flink.connector.kafka.sink.KafkaRecordSerializationSchema;
import org.apache.flink.connector.kafka.sink.KafkaSink;
import org.apache.flink.connector.kafka.source.KafkaSource;
import org.apache.flink.connector.kafka.source.enumerator.initializer.OffsetsInitializer;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
public class SinKafkaToKafka {
public static void main(String[] args) throws Exception {
// 1. get stream execution environment
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 2. read kafka message as stream input, update your broker IPs below
String brokers = "X.X.X.X:9092,X.X.X.X:9092,X.X.X.X:9092";
KafkaSource<String> source = KafkaSource.<String>builder()
.setBootstrapServers(brokers)
.setTopics("clicks")
.setGroupId("my-group")
.setStartingOffsets(OffsetsInitializer.earliest())
.setValueOnlyDeserializer(new SimpleStringSchema())
.build();
DataStream<String> stream = env.fromSource(source, WatermarkStrategy.noWatermarks(), "Kafka Source");
// 3. transformation:
// https://www.taobao.com,1000 --->
// Event{user: "Tim",url: "https://www.taobao.com",timestamp: 1970-01-01 00:00:01.0}
SingleOutputStreamOperator<String> result = stream.map(new MapFunction<String, String>() {
@Override
public String map(String value) throws Exception {
String[] fields = value.split(",");
return new Event(fields[0].trim(), fields[1].trim(), Long.valueOf(fields[2].trim())).toString();
}
});
// 4. sink click into another kafka events topic
KafkaSink<String> sink = KafkaSink.<String>builder()
.setBootstrapServers(brokers)
.setProperty("transaction.timeout.ms","900000")
.setRecordSerializer(KafkaRecordSerializationSchema.builder()
.setTopic("events")
.setValueSerializationSchema(new SimpleStringSchema())
.build())
.setDeliveryGuarantee(DeliveryGuarantee.EXACTLY_ONCE)
.build();
result.sinkTo(sink);
// 5. execute the stream
env.execute("kafka Sink to other topic");
}
}
Написание программы на Java Event.java
import java.sql.Timestamp;
public class Event {
public String user;
public String url;
public Long timestamp;
public Event() {
}
public Event(String user,String url,Long timestamp) {
this.user = user;
this.url = url;
this.timestamp = timestamp;
}
@Override
public String toString(){
return "Event{" +
"user: \"" + user + "\"" +
",url: \"" + url + "\"" +
",timestamp: " + new Timestamp(timestamp) +
"}";
}
}
Упаковка jar-файла и отправка задания в Flink
Загрузите jar-файл и передайте его в Webssh.

Пользовательский интерфейс панели мониторинга Flink

Создать тему — щелчки на Kafka

Обработка темы - события в Kafka

Ссылка
- Соединитель Apache Kafka
- Apache, Apache Kafka, Kafka, Apache Flink, Flink и связанные имена проектов с открытым кодом являются товарными знакамиApache Software Foundation (ASF).