Рекомендации по реагированию на инциденты безопасности
Применимо к Power Platform рекомендациям контрольного списка Well-Architected Security:
| СЭ:11 | Определите и протестируйте эффективные процедуры реагирования на инциденты, которые охватывают широкий спектр инцидентов, от локализованных проблем до аварийного восстановления. Четко определите группу или человека, которые должны выполнять процедуру. |
|---|
В этом руководстве описаны рекомендации по реализации процесса реагирования на инциденты безопасности для рабочей нагрузки. Если в системе существует угроза безопасности, систематический подход к реагированию на инциденты помогает сократить время, необходимое для выявления и смягчения последствий инцидентов безопасности, а также управления ими. Эти инциденты могут поставить под угрозу конфиденциальность, целостность и доступность программных систем и данных.
На большинстве предприятий есть центральная группа по обеспечению безопасности (также известная как Центр информационной безопасности [SOC] или SecOps). В обязанности группы по операциям обеспечения безопасности входит быстрое обнаружение, приоритизация и анализ потенциальных атак. Эта группа также отслеживает данные телеметрии, связанные с безопасностью, и расследует нарушения безопасности.
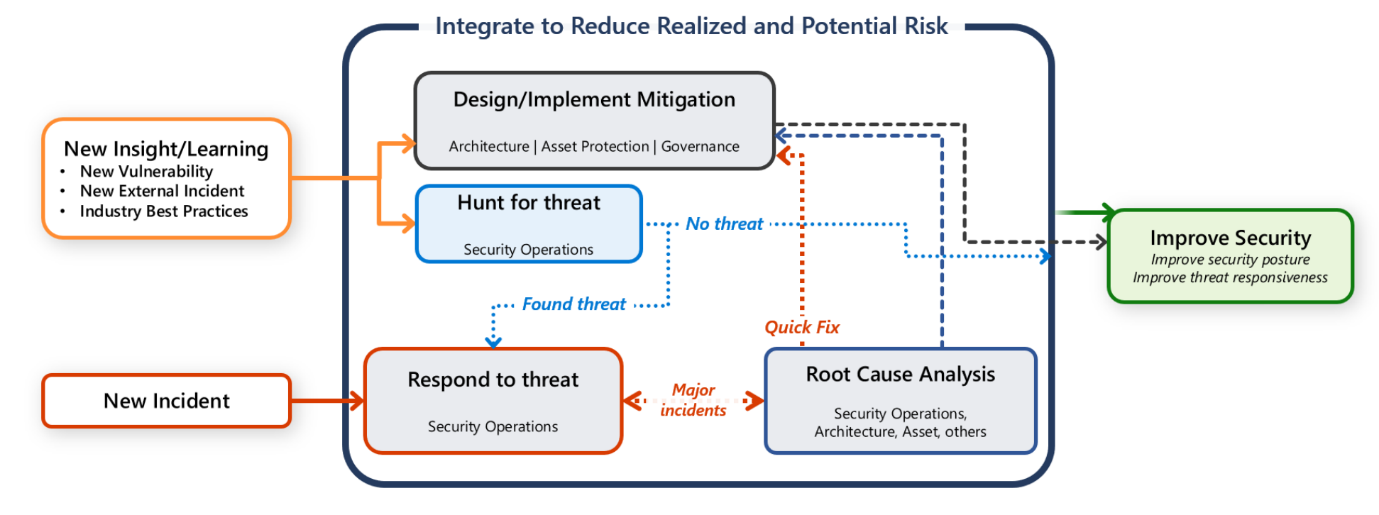
Однако вы также несете ответственность за защиту своей рабочей нагрузки. Важно, чтобы любые действия по коммуникации, расследованию и поиску осуществлялись совместными усилиями группы по рабочей нагрузке и отдела операций обеспечения безопасности.
В этом руководстве представлены рекомендации для вас и вашей группы по рабочей нагрузке, которые помогут вам быстро обнаруживать, классифицировать и расследовать атаки.
Определения
| Термин | Определение |
|---|---|
| Оповещение | Уведомление, содержащее информацию об инциденте. |
| Точность оповещения | Точность данных, определяющих оповещение. Оповещения высокой точности содержат контекст безопасности, необходимый для принятия немедленных мер. Оповещения с низкой точностью не содержат информации или содержат шум. |
| Ложноположительный результат | Оповещение, указывающее на инцидент, которого не было. |
| Инцидент | Событие, указывающее на несанкционированный доступ к системе. |
| Реакция на инцидент | Процесс, который обнаруживает и снижает риски, связанные с инцидентом, и реагирует на них. |
| Рассмотрение | Операция реагирования на инциденты, которая анализирует проблемы безопасности и определяет приоритетность их устранения. |
Ключевые стратегии проектирования
Вы и ваша рабочая группа выполняете операции по реагированию на инциденты, когда сигнал или предупреждение указывает на потенциальный инцидент безопасности. Оповещения высокой точности содержат обширный контекст безопасности, который упрощает принятие решений аналитиками. Оповещения высокой точности приводят к небольшому количеству ложных срабатываний. В этом руководстве предполагается, что система оповещения фильтрует сигналы низкой точности и уделяет основное внимание оповещениям высокой точности, которые могут указывать на реальный инцидент.
Уведомление о назначении инцидента
Оповещения безопасности должны доходить до соответствующих людей в вашей группе и в вашей организации. Назначьте определенное контактное лицо в своей группе по рабочей нагрузке для получения уведомлений об инцидентах. Эти уведомления должны включать как можно больше информации о скомпрометированном ресурсе и системе. Оповещение должно включать следующие шаги, чтобы ваша группа могла ускорить действия.
Мы рекомендуем вам регистрировать уведомления и действия об инцидентах и управлять ими с помощью специализированных инструментов, которые ведут журнал аудита. Используя стандартные инструменты, вы можете сохранить доказательства, которые могут потребоваться для потенциальных судебных расследований. Ищите возможности для внедрения автоматизации, которая может отправлять уведомления в зависимости от обязанностей подотчетных сторон. Сохраняйте четкую цепочку сообщений и отчетности во время инцидента.
Воспользуйтесь преимуществами решений по управлению событиями с информацией о безопасности (SIEM) и решений автоматического реагирования по оркестрации безопасности (SOAR), которые предоставляет ваша организация. Также вы можете приобрести инструменты управления инцидентами и предложить своей организации стандартизировать их для всех групп по рабочим нагрузкам.
Расследование с помощью группы анализа
Участник рабочей группы, который получает уведомление об инциденте, отвечает за настройку процесса анализа, в котором участвуют соответствующие люди на основе имеющихся данных. Группа анализа, которую часто называют группой по координации, должна согласовать режим и процесс коммуникации. Требует ли этот инцидент асинхронных обсуждений или координационных переговоров? Как рабочая группа должна отслеживать ход расследования и сообщать о нем? Где рабочая группа может получить доступ к ресурсам инцидента?
Реагирование на инциденты — это важнейшая причина, почему важно поддерживать актуальность документации, например архитектурной схемы системы, информации на уровне компонентов, сведений о классификации конфиденциальности или безопасности, владельцах и ключевых точках контакта. Если информация неточна или устарела, координационная группа тратит драгоценное время, пытаясь понять, как работает система, кто несет ответственность за каждую область и каковы могут быть последствия события.
Для дальнейшего расследования привлекайте подходящих людей. Вы можете включить менеджера по инцидентам, сотрудника по безопасности или руководителей, ответственных за рабочую нагрузку. Чтобы анализ был сфокусированным, исключайте людей, выходящих за рамки проблемы. Иногда инцидент расследуют отдельные группы. Может существовать группа, которая первоначально расследует проблему и пытается смягчить последствия инцидента, а также другая специализированная группа, которая может проводить криминалистическую экспертизу для более глубокого расследования с целью выявления более глубоких проблем. Вы можете изолировать среду рабочей нагрузки, чтобы дать возможность экспертной группе провести расследование. В некоторых случаях одна и та же группа может проводить полное расследование.
На начальном этапе группа анализа отвечает за определение потенциального вектора и его влияния на конфиденциальность, целостность и доступность системы (также называется триада CIA).
Внутри категорий CIA присвойте первоначальный уровень серьезности, который указывает на глубину ущерба и срочность устранения. Ожидается, что этот уровень со временем изменится по мере того, как на разных уровнях анализа будет обнаружено больше информации.
На этапе обнаружения важно определить непосредственный курс действий и планы передачи информации. Есть ли какие-либо изменения в рабочем состоянии системы? Как можно сдержать атаку, чтобы остановить дальнейшую эксплуатацию? Нужно ли рабочей группе рассылать внутренние или внешние сообщения, например, сообщения в рамках ответственного раскрытия информации? Учитывайте время обнаружения и реагирования. По закону вы можете быть обязаны сообщать о некоторых типах нарушений контролирующему органу в течение определенного периода времени, который часто составляет несколько часов или дней.
Если вы решите выключить систему, следующие шаги приведут к процессу аварийного восстановления (DR) рабочей нагрузки.
Если вы не выключите систему, определите способ устранения инцидента без влияния на функциональность системы.
Восстановление после инцидента
Относитесь к инциденту безопасности как к чрезвычайной ситуации. Если исправление требует полного восстановления, используйте надлежащие механизмы аварийного восстановления с точки зрения безопасности. Процесс восстановления должен предотвратить вероятность повторения инцидента. В противном случае восстановление из поврежденной резервной копии снова приведет к возникновению проблемы. Повторное развертывание системы с той же уязвимостью приводит к тому же инциденту. Проверка шагов и процессов аварийного переключения (отработки отказа) и восстановления после отказа.
Если система продолжает функционировать, оцените влияние на работающие части системы. Продолжайте отслеживать работу системы, чтобы гарантировать, что другие целевые показатели надежности и производительности достигаются или корректируются путем внедрения соответствующих процессов снижения производительности. Не ставьте под угрозу конфиденциальность в результате снижения рисков.
Диагностика — это интерактивный процесс до тех пор, пока не будут определены вектор, а также потенциальное решение и переход к резервному состоянию. После диагностики рабочая группа занимается исправлением проблемы, определяет и применяет необходимый способ исправления в течение приемлемого периода.
Метрики восстановления измеряют, сколько времени потребуется на устранение проблемы. В случае полной остановки процессов может возникнуть необходимость в срочном устранении неполадок. Чтобы стабилизировать систему, требуется время для применения исправлений и проведения тестов, а также для развертывания обновлений. Определить стратегии сдерживания, чтобы предотвратить дальнейший ущерб и распространение инцидента. Разработайте процедуры ликвидации, чтобы полностью устранить угрозу из среды.
Компромисс: существует компромисс между целями надежности и временем устранения неполадок. Во время инцидента вполне вероятно, что вы не соответствуете другим нефункциональным или функциональным требованиям. Например, вам может потребоваться отключить части вашей системы на время расследования инцидента или даже отключить всю систему, пока вы не определите масштаб инцидента. Лица, принимающие бизнес-решения, должны четко решить, каковы приемлемые цели во время инцидента. Четко определите человека, который несет ответственность за это решение.
Извлекайте уроки из инцидента
Инцидент обнаруживает пробелы или уязвимые места в проекте или реализации. Это возможность улучшения, основанная на извлеченных уроках, касающихся аспектов технического проектирования, автоматизации, процессов разработки продуктов, включающих тестирование, и эффективности процесса реагирования на инциденты. Ведите подробные записи об инцидентах, включая сведения о предпринятых действиях, сроках и результатах.
Мы настоятельно рекомендуем вам проводить структурированные проверки после инцидентов, такие как анализ первопричин и ретроспективный анализ. Отслеживайте результаты этих проверок и расставляйте приоритеты, а также рассмотрите возможность использования полученных знаний при разработке будущих рабочих нагрузок.
Планы улучшений должны включать обновления тренировочных упражнений и испытаний по безопасности, например практическая отработка в сфере непрерывности бизнес-процессов и аварийного восстановления (BCDR). Используйте компрометацию безопасности в качестве сценария для выполнения упражнений по практической отработке BCDR. Тренировочные упражнения помогают проверить, как работают документированные процессы. Не должно быть нескольких инструкций по реагированию на инциденты. Используйте один источник, который вы можете откорректировать в зависимости от размера инцидента, его распространенности или локализации его эффекта. Тренировочные упражнения основаны на гипотетических ситуациях. Проводите тренировочные упражнения в условиях низкого риска и включайте в них этап обучения.
Проведите анализ после инцидента или анализ последствий инцидентов, чтобы выявить слабые места в процессе реагирования и области, требующие улучшения. На основе уроков, извлеченных из инцидента, обновите план реагирования на инцидент (IRP) и средства управления безопасностью.
Отправляйте необходимые сообщения
Внедрите план коммуникации для уведомления пользователей о сбоях и информирования внутренних заинтересованных лиц об исправлениях и улучшениях. Другие люди в вашей организации должны быть уведомлены о любых изменениях в базовом уровне безопасности рабочей нагрузки, чтобы предотвратить будущие инциденты.
Создавайте отчеты об инцидентах для внутреннего использования и, при необходимости, для соблюдения нормативных требований или в юридических целях. Кроме того, внедрите отчет стандартного формата (шаблон документа с определенными разделами), который группа SOC использует для всех инцидентов. Прежде чем закрыть расследование, убедитесь, что для каждого инцидента есть связанный с ним отчет.
Возможности в Power Platform
В следующих разделах описаны механизмы, которые вы можете использовать в рамках процедур реагирования на инциденты безопасности.
Microsoft Sentinel
Решение Microsoft Sentinel для Microsoft Power Platform позволяет клиентам обнаруживать различные подозрительные действия, включая следующие:
- Исполнение Power Apps из несанкционированных географических регионов
- Подозрительное уничтожение данных Power Apps
- Массовое удаление Power Apps
- Фишинговые атаки, осуществленные через Power Apps
- Активность потоков Power Automate со стороны увольняющихся сотрудников
- Соединители Microsoft Power Platform, добавленные в среду
- Обновление или удаление политик защиты от потери данных Microsoft Power Platform
Дополнительную информацию см. в разделе решение Microsoft Sentinel для обзора Microsoft Power Platform.
Ведение журнала действий Microsoft Purview
Журналы действий Power Apps, Power Automate, соединителей, защиты от потери данных и административных действий Power Platform отслеживаются и просматриваются на портале соответствия требованиям Microsoft Purview.
Дополнительные сведения:
- Power Apps ведение журнала активности
- Power Automate ведение журнала активности
- Copilot Studio ведение журнала активности
- Power Pages ведение журнала активности
- Power Platform регистрация активности коннектора
- Регистрация действий по предотвращению потери данных
- Power Platform административные действия регистрация активности
- Microsoft Dataverse и регистрация активности приложений на основе моделей
Защищенное хранилище
Большинство операций, выполняемых персоналом Майкрософт (в том числе и дополнительными обработчиками данных), а также осуществление поддержки и устранение неполадок не требуют доступа к данным клиентов. Используя защищенное хранилище Power Platform, Microsoft предоставляет интерфейс, позволяющий клиентам просматривать и утверждать (или отклонять) запросы на доступ к данным в тех редких случаях, когда доступ к данным клиентов необходим. Оно используется в тех случаях, когда инженеру Майкрософт необходимо получить доступ к данным клиента, для обработки инициированного клиентом запроса в службу поддержки или для решения проблемы, выявленной корпорацией Майкрософт. Дополнительные сведения см. в разделе Безопасный доступ к данным клиентов с помощью защищенного хранилища в Power Platform и Dynamics 365.
Обновления безопасности
Рабочая группа служб регулярно выполняет следующие действия, чтобы гарантировать безопасность системы:
- Сканирование службы для выявления возможных уязвимостей безопасности.
- Оценки службы, позволяющие гарантировать эффективную работу ключевых средств обеспечения безопасности.
- Оценки службы, позволяющие определить наличие любых уязвимостей, выявленных Центром Майкрософт по реагированию на угрозы, который регулярно отслеживает внешние сайты, информирующие об уязвимостях.
Эти группы также выявляют и отслеживают любые обнаруженные проблемы, а при необходимости — оперативно предпринимает действия по снижению рисков.
Как мне узнать об обновлениях безопасности?
Поскольку рабочая группа службы стремится проводить меры по снижению риска так, чтобы для них не требовались простои службы, администраторы обычно не видят уведомлений Центра сообщений об обновлениях безопасности. Если обновление для системы безопасности требует воздействия службы, оно считается запланированным обслуживанием и будет размещено с расчетной длительностью воздействия и окном, когда работа произойдет.
Дополнительные сведения о безопасности см. в Центре управления безопасностью Microsoft.
Управление периодом обслуживания
Корпорация Майкрософт проводит обновления и обслуживание, чтобы обеспечить безопасность, производительность и доступность, а также для ввода новых возможностей и функциональности. Этот процесс обновления обеспечивает безопасность и небольшие улучшения обслуживания на еженедельной основе, при этом каждое обновление развертывается от региона к региону в соответствии с расписанием безопасного развертывания, составленным на станциях. Сведения о периоде обслуживания по умолчанию для сред см. в разделе Политики и взаимодействие для инцидентов с обслуживанием. Также см. раздел Управление периодом обслуживания.
Убедитесь, что портал регистрации Azure содержит контактную информацию администратора, чтобы можно было уведомлять об операциях безопасности напрямую через внутренний процесс. Дополнительные сведения см. в статье Обновление параметров уведомлений.
Согласованность внутри организации
Cloud Adoption Framework для Azure предоставляет инструкции по планированию реагирования на инциденты и операциям безопасности. Дополнительные сведения см. в разделе Операции по безопасности.
Дополнительные сведения
- Microsoft Решение Sentinel для Microsoft Power Platform обзора
- Автоматически создавать инциденты из оповещений безопасности Microsoft
- Проведите сквозной поиск угроз с помощью функции Hunts
- Используйте Hunts для проведения сквозного упреждающего поиска угроз в Microsoft Sentinel
- Обзор инцидента ответ
Контрольный список безопасности
Обратитесь к полному набору рекомендаций.