Типы объяснений в Microsoft Syntex
Область применения: ✓ Обработка неструктурированных документов
Объяснения используются для определения сведений, которые нужно пометить и извлечь в неструктурированных моделях обработки документов в Microsoft Syntex. При создании объяснения следует выбрать тип объяснения. Эта статья поможет вам узнать о разных типах объяснений и о том, как они используются.
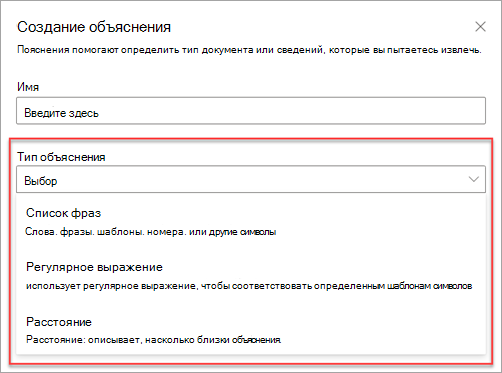
Существуют следующие типы объяснений:
Список фраз: список слов, фраз, цифр или других символов, которые можно использовать в документе или в извлекаемой информации. Например, текстовая строка Направивший врач находится во всех идентифицируемых документах с медицинскими направлениями. Или Номер телефона направившего врача из идентифицируемого документа с медицинским направлением.
Регулярное выражение: использует нотацию сопоставления с шаблоном для поиска определенных сочетаний символов. Например, с помощью регулярного выражения можно найти все адреса электронной почты в наборе документов.
Расстояние: описывает, насколько близки объяснения друг к другу. Например, список фраз с номерами улиц идет прямо перед списком фраз названия улицы без маркеров между ними (вы узнаете о маркерах далее в этой статье). Для использования типа расстояния необходимо, чтобы в модели было как минимум два объяснения, иначе эта функция будет отключена.
Список фраз
Список фраз — это тип объяснения, который обычно используется, чтобы идентифицировать и классифицировать документ через вашу модель. Как описано в примере с меткой Направивший врач, это строка со словами, фразами, номерами или символами, постоянно встречающимися в идентифицируемых документах.
Хоть это и не обязательно, но если считываемая фраза находится в одном и том же месте во всех документах, это позволяет добиться наилучших результатов. Например, метка Направивший врач может находиться в первом абзаце всех документов. Также можно использовать дополнительный параметр Настройка расположения фраз в документе для выбора определенных областей, в которых встречается фраза, особенно если существует вероятность ее нахождения в нескольких местах документа.
Если при идентификации метки важна точность, при использовании списка фраз вы можете указать это, выбрав флажок Только точная капитализация.

Тип фразы особенно полезен при создании объяснения, которое выявляет и извлекает информацию в различных форматах, например даты, номера телефонов и номера кредитных карт. Например, дата может быть представлена в нескольких различных форматах (1/1/2020, 1-1-2020, 01.01.20, 01.01.2020, 1 января 2020 г. и т. д.). Определение списка фраз делает объяснение более эффективным, так как оно будет содержать все возможные вариации данных, которые вы хотите выявить и извлечь.
В случае с номером телефона извлеките номер телефона каждого направляющего врача из документов с медицинскими направлениями, которые идентифицирует модель. При создании объяснения введите различные форматы, в которых номер телефона может отображаться в документе, для сбора возможных вариаций.
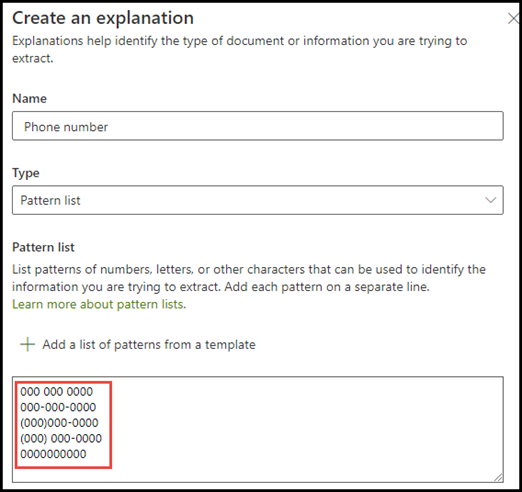
В этом случае в разделе Дополнительные параметры установите флажок Любая цифра от 0 до 9, чтобы распознавать каждое значение "0", используемое в списке фраз, как любую цифру от 0 до 9.
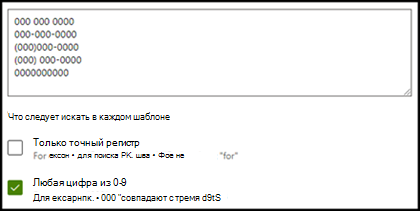
Точно так же при создании списка фраз, включающего текстовые символы, установите флажок Любая буква от a до я, чтобы распознавать каждый символ "a", используемый в списке фраз, как любую букву от "а" до "я".
Например, если вы создаете список фраз Дата и хотите, чтобы был распознан формат даты типа 1 янв 2020, нужно сделать следующее:
- Добавьте в список фраз aaa 0, 0000 и aaa 00, 0000.
- Убедитесь, что выбран флажок Любая буква от а до я.

Кроме того, если ваш список фраз содержит требования относительно заглавных букв, вы можете установить флажок Только точная капитализация. В примере с датами, если нужно, чтобы первая буква месяца была заглавной, сделайте следующее:
- Добавьте в список фраз Aaa 0, 0000 и Aaa 00, 0000.
- Убедитесь, что выбран флажок Только точная капитализация.

Примечание.
Вместо того, чтобы вручную создавать объяснение для списка фраз, воспользуйтесь библиотекой объяснений с шаблонами популярных списков фраз, например дата, номер телефона, номер кредитной карты и т. д.
Регулярное выражение
Тип объяснения регулярного выражения позволяет создавать шаблоны, помогающие находить и выявлять определенные текстовые строки в документах. С помощью регулярных выражений можно быстро анализировать большие объемы текста, чтобы:
- Находить сочетания символов, соответствующие определенным шаблонам.
- Проверять текст на соответствие заданному шаблону (например, адресу электронной почты).
- Извлекать, изменять, заменять и удалять подстроки текста.
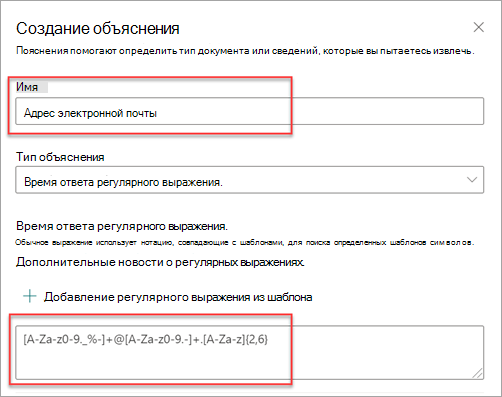
Тип регулярного выражения особенно полезен при создании объяснения, которое выявляет и извлекает информацию в различных форматах, например даты, номера телефонов и номера кредитных карт. Например, адрес электронной почты, например megan@contoso.com, отображается в определенном шаблоне ("megan" — это первая часть, а "com" — последняя часть).
Регулярное выражение для адреса электронной почты: [A-Za-z0-9._%-]+@[A-Za-z0-9.-]+.[A-Za-z]{2,6}.
Это выражение состоит из пяти частей в таком порядке:
Следующие символы в любом количестве:
а. буквы от a до z
б. цифры от 0 до 9
в. точка, символ подчеркивания, знак процент или дефис
Знак @
любое количество тех же символов, что и в первой части адреса электронной почты
точка
от двух до шести букв
Чтобы добавить тип объяснения регулярного выражения, выполните следующие шаги.
На панели Создание объяснения в элементе Тип объяснениявыберите Регулярное выражение.

Вы можете ввести выражение вручную в поле Регулярное выражение или выбрать Добавить регулярное выражение из шаблона.
При добавлении регулярного выражения с помощью шаблона в текстовое поле автоматически добавляются имя и регулярное выражение. Например, если выбрать шаблон адреса Email, будет заполнена панель Создание объяснения.
Ограничения
В следующей таблице показаны встроенные параметры символов, которые в настоящее время недоступны для использования в шаблонах регулярных выражений.
| Вариант | Состояние | Текущая функциональность |
|---|---|---|
| Учет регистра | В настоящее время не поддерживается. | Все совпадения — без учета регистра. |
| Привязки линий | В настоящее время не поддерживается. | Невозможно указать определенное положение в строке, в котором должно быть совпадение. |
Расстояние
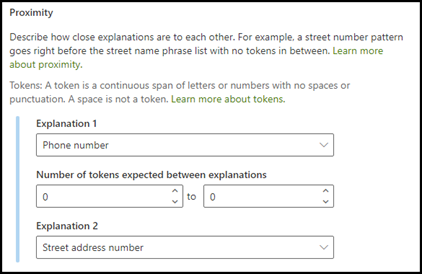
Тип объяснения по расстоянию позволяет идентифицировать информацию по ее схожести с другим фрагментом данных. Например, вы определили в модели два типа объяснений, которые помечают Улицу и номер дома и Номер телефона клиента.
Обратите внимание, что номера телефонов клиента всегда идут до номера дома и улицы.
Алексей Виноградов
555-555-5555
One Microsoft Way
Redmond, WA 98034
Используйте объяснение по расстоянию, чтобы определить, насколько далеко находится объяснение номера телефона, чтобы лучше идентифицировать адрес в документах.
Примечание.
Регулярные выражения в настоящее время нельзя использовать с типом объяснения близкого взаимодействия.
Что такое маркеры?
Чтобы использовать тип объяснения по расстоянию, необходимо понять, что такое маркер. Тип объяснения по расстоянию измеряет расстояние в маркерах. Маркер — это непрерывный диапазон (без пробелов или пунктуации) букв и цифр.
В таблице ниже приведены примеры определения количества маркеров в фразе.
| Фраза | Количество маркеров | Объяснение |
|---|---|---|
Dog |
1 | Отдельное слово без пунктуации и пробелов. |
RMT33W |
1 | Номер локатора записи. Он может содержать буквы и цифры, но не знаки пунктуации. |
425-555-5555 |
5 | Номер телефона. Каждый знак препинания является маркером, поэтому в 425-555-5555 5 маркеров:425-555-5555 |
https://luis.ai |
7 | https://luis.ai |
Настройка типа объяснения по расстоянию
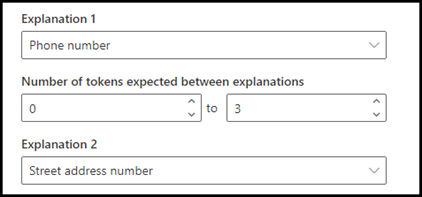
В качестве примера настройте расстояние так, чтобы определить диапазон количества маркеров от объяснения Номер телефона до объяснения Номер дома. Обратите внимание, что в качестве минимального диапазона указан «0», потому что между номером телефона и номером дома нет маркеров.
Однако к некоторым номерам телефонов в примерах документов добавлен (мобильный).
Николай Белых
111-111-1111 (мобильный)
One Microsoft Way
Redmond, WA 98034
В примере (мобильный) три маркера:
| Фраза | Количество маркеров |
|---|---|
| ( | 1 |
| мобильный | 2 |
| ) | 3 |
Настройте параметры расстояния так, чтобы диапазон был от 0 до 3.
Настройка расположения фраз в документе
Когда вы создаете объяснение, по умолчанию поиск фразы, которую вы пытаетесь извлечь, выполняется по всему документу. Однако вы можете использовать дополнительный параметр Где встречаются эти фразы, чтобы изолировать определенное место в документе, в котором встречается фраза. Это удобно в ситуациях, когда похожие вхождения фразы могут появляться в другом месте документа и вы хотите убедиться в том, что выбран нужный вариант.
В нашем примере, когда документ представляет собой медицинское направление, Направивший врач всегда упоминается в первом абзаце документа. С помощью параметра Где встречаются эти фразы в этом примере вы можете настроить свое объяснение для поиска этой метки только в начальном разделе документа или в любом другом месте, где она может встречаться.
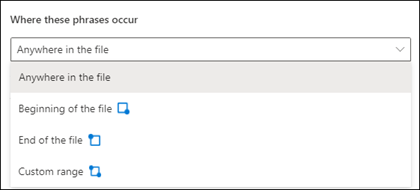
В этом параметре доступны следующие варианты на выбор.
В любом месте файла: поиск фразы выполняется во всем документе.
Начало файла: в документе выполняется поиск от начала до расположения фразы.
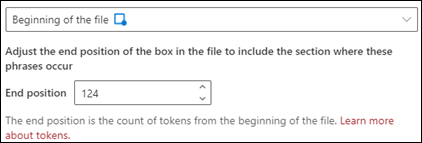
В средстве просмотра вы можете вручную изменить поле выбора, чтобы включить расположение фразы. Значение Конечной позиции обновляется, чтобы отобразить количество маркеров, включаемых в выбранную область. Обратите внимание, что вы можете изменить значение Конечное положение, а также настроить выбранную область.
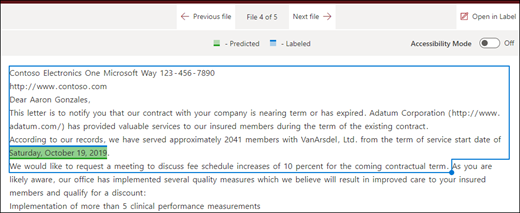
Конец файла: поиск в документе выполняется с конца до места, где расположена фраза.
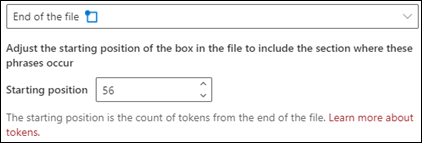
В средстве просмотра вы можете вручную изменить поле выбора, чтобы включить расположение фразы. Значение Начальной позиции обновляется, чтобы отобразить количество маркеров, включаемых в выбранную область. Обратите внимание, что вы можете изменить значение "Начальное положение", а также настроить выбранную область.

Произвольный диапазон: поиск расположения фразы в документе выполняется в указанном диапазоне.
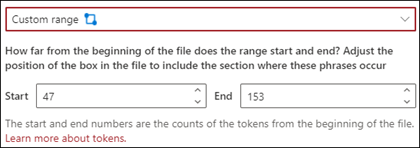
В средстве просмотра вы можете вручную изменить поле выбора, чтобы включить расположение фразы. Для этого параметра требуется выбрать положение Начало и Конец. Эти значения отражают количество маркеров с начала документа. Хотя вы можете вручную ввести эти значения, проще вручную изменить поле выбора в средстве просмотра.
Рекомендации по настройке объяснений
При обучении классификатора следует помнить о нескольких вещах, которые приведут к более предсказуемым результатам:
Чем больше документов вы обучаете, тем точнее будет классификатор. По возможности используйте более пяти хороших документов и более одного плохого документа. Если библиотеки, с которыми вы работаете, имеют несколько разных типов документов, несколько типов каждого из них приводят к более предсказуемым результатам.
Маркировка документа играет важную роль в процессе обучения. Они используются вместе с объяснениями для обучения модели. Вы можете увидеть некоторые аномалии при обучении классификатора с документами, в которых нет большого содержимого. Объяснение может не совпадать ни с чем в документе, но так как он был помечен как "хороший" документ, вы можете увидеть, что оно совпадает во время обучения.
При создании объяснений используется логика OR в сочетании с меткой, чтобы определить, соответствует ли она. Регулярное выражение, использующее логику AND, может быть более предсказуемым. Ниже приведен пример регулярного выражения для использования в реальных документах при их обучении. Обратите внимание, что текст, выделенный красным цветом, — это фраза или фразы, которые вы ищете.
(?=.*network provider)(?=.*participating providers).*
Метки и объяснения работают вместе и используются при обучении модели. Это не ряд правил, которые могут быть развязаны и точные весовые коэффициенты или прогнозы, применяемые к каждой настроенной переменной. Чем больше вариативность документов, используемых в обучении, будет обеспечивать большую точность в модели.