Рекомендации по аварийному восстановлению для конкретных возможностей
В этом документе содержатся рекомендации по восстановлению данных Fabric в случае региональной аварии.
Пример сценария
В некоторых разделах руководства в этом документе используется следующий пример сценария для объяснения и иллюстрации. При необходимости обратитесь к этому сценарию.
Предположим, что у вас есть емкость C1 в регионе A с рабочей областью W1. Если вы включили аварийное восстановление для емкости C1, данные OneLake будут реплицированы в резервную копию в регионе B. Если регион A сталкивается с нарушениями, служба Fabric в C1 выполняет отработку отказа в регион B.
Этот сценарий показан на следующем рисунке. В поле слева отображается нарушенный регион. Поле в середине представляет постоянную доступность данных после отработки отказа, а поле справа показывает полную ситуацию после того, как клиент будет действовать для восстановления служб до полной функции.
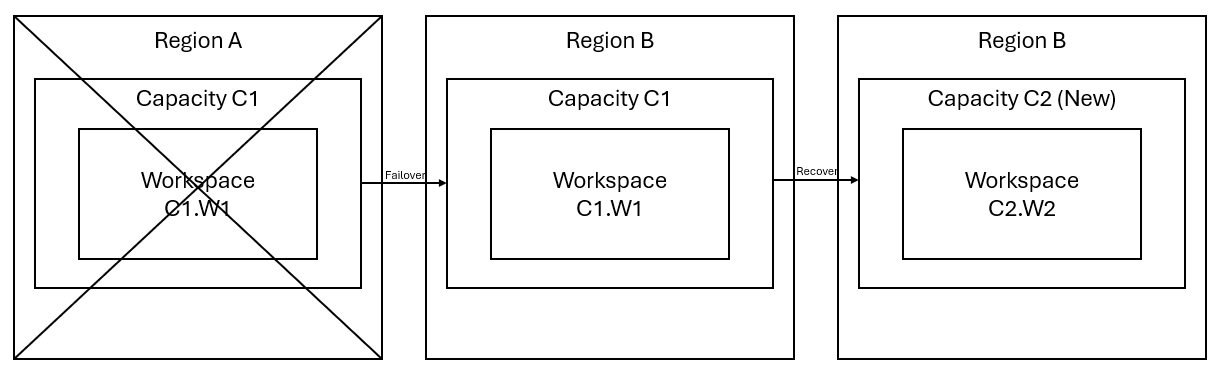
Ниже приведен общий план восстановления:
Создайте новую емкость Fabric C2 в новом регионе.
Создайте новую рабочую область W2 в C2, включая соответствующие элементы с теми же именами, что и в C1. W1.
Скопируйте данные из нарушенного C1. W1 до C2. W2.
Следуйте выделенным инструкциям для каждого компонента, чтобы восстановить элементы до полной функции.
Планы восстановления для конкретных возможностей
В следующих разделах приведены пошаговые руководства по каждому интерфейсу Fabric, помогающие клиентам через процесс восстановления.
Инжиниринг данных
В этом руководстве описаны процедуры восстановления для интерфейса Инжиниринг данных. В ней рассматриваются определения заданий Spark и lakehouses, записных книжек и заданий Spark.
Гибридное решение "хранилище и озеро данных"
Lakehouses из исходного региона остаются недоступными для клиентов. Чтобы восстановить lakehouse, клиенты могут повторно создать его в рабочей области C2. W2. Мы рекомендуем два подхода для восстановления лейкхаусов:
Подход 1. Использование пользовательского скрипта для копирования таблиц и файлов Delta Lakehouse
Клиенты могут воссоздать lakehouse с помощью пользовательского скрипта Scala.
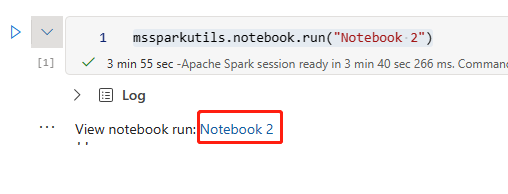
Создайте lakehouse (например, LH1) в созданной рабочей области C2. W2.
Создайте записную книжку в рабочей области C2. W2.
Чтобы восстановить таблицы и файлы из исходного lakehouse, обратитесь к данным с путями OneLake, такими как abfss (см . статью "Подключение к Microsoft OneLake"). В записной книжке можно использовать приведенный ниже пример кода (см . общие сведения о служебных программах Microsoft Spark), чтобы получить пути ABFS файлов и таблиц из исходного lakehouse. (Замените C1. W1 с фактическим именем рабочей области)
mssparkutils.fs.ls('abfs[s]://<C1.W1>@onelake.dfs.fabric.microsoft.com/<item>.<itemtype>/<Tables>/<fileName>')Используйте следующий пример кода для копирования таблиц и файлов в только что созданное озеро.
Для таблиц Delta необходимо скопировать таблицу по одному за раз, чтобы восстановиться в новом лейкхаусе. В случае файлов Lakehouse можно скопировать полную структуру файлов со всеми базовыми папками с одним выполнением.
Обратитесь в службу поддержки за меткой времени отработки отказа, необходимой в скрипте.
%%spark val source="abfs path to original Lakehouse file or table directory" val destination="abfs path to new Lakehouse file or table directory" val timestamp= //timestamp provided by Support mssparkutils.fs.cp(source, destination, true) val filesToDelete = mssparkutils.fs.ls(s"$source/_delta_log") .filter{sf => sf.isFile && sf.modifyTime > timestamp} for(fileToDelte <- filesToDelete) { val destFileToDelete = s"$destination/_delta_log/${fileToDelte.name}" println(s"Deleting file $destFileToDelete") mssparkutils.fs.rm(destFileToDelete, false) } mssparkutils.fs.write(s"$destination/_delta_log/_last_checkpoint", "", true)После запуска скрипта таблицы будут отображаться в новом лейкхаусе.
Подход 2. Использование обозревателя служба хранилища Azure для копирования файлов и таблиц
Чтобы восстановить только определенные файлы Или таблицы Lakehouse из исходного lakehouse, используйте служба хранилища Azure Explorer. Подробные инструкции см. в статье интеграции OneLake с обозревателем служба хранилища Azure. Для больших размеров данных используйте подход 1.
Примечание.
Два подхода, описанные выше, восстанавливают метаданные и данные для разностных таблиц, так как метаданные находятся совместно и хранятся вместе с данными в OneLake. Для таблиц, отличных от разностного формата (e.g. CSV, Parquet и т. д.), созданных с помощью скриптов и команд языка определения данных Spark (DDL), пользователь отвечает за обслуживание и повторное выполнение скриптов и команд Spark DDL для их восстановления.
Записная книжка
Записные книжки из основного региона остаются недоступными для клиентов, а код в записных книжках не будет реплицирован в дополнительный регион. Чтобы восстановить код записной книжки в новом регионе, существует два подхода к восстановлению содержимого кода записной книжки.
Подход 1. Избыточность, управляемая пользователем, с интеграцией Git (в общедоступной предварительной версии)
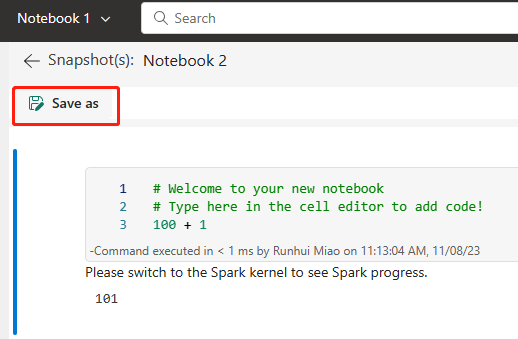
Лучший способ упростить и быстро использовать интеграцию Fabric Git, а затем синхронизировать записную книжку с репозиторием ADO. После отработки отказа службы в другой регион можно использовать репозиторий для перестроения записной книжки в созданной рабочей области.
Настройте интеграцию Git для вашей рабочей среды и выберите Подключиться и синхронизировать с репозиторием ADO.
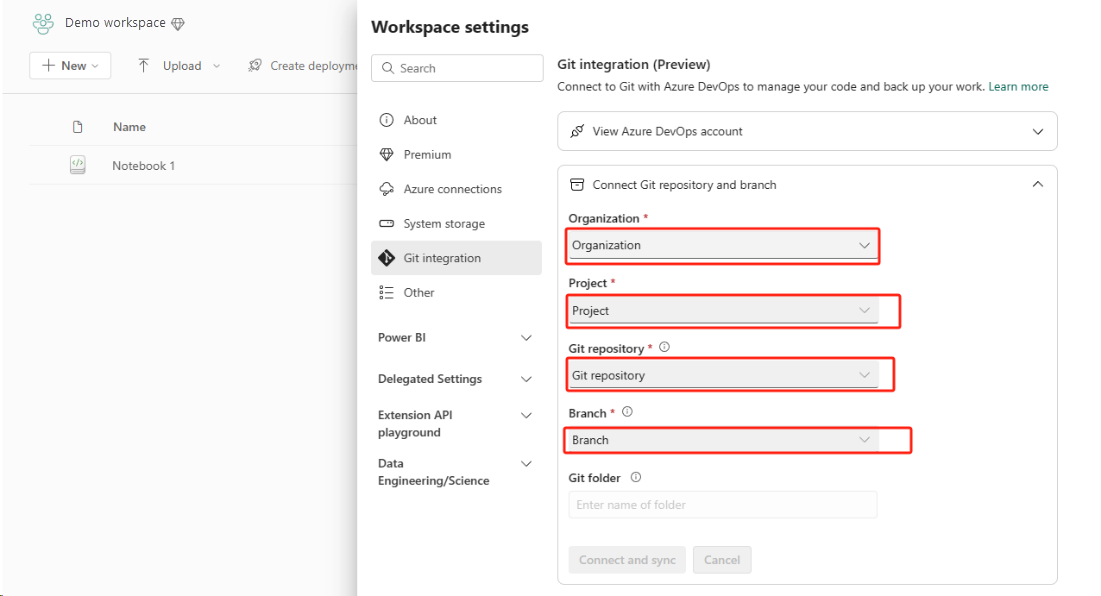
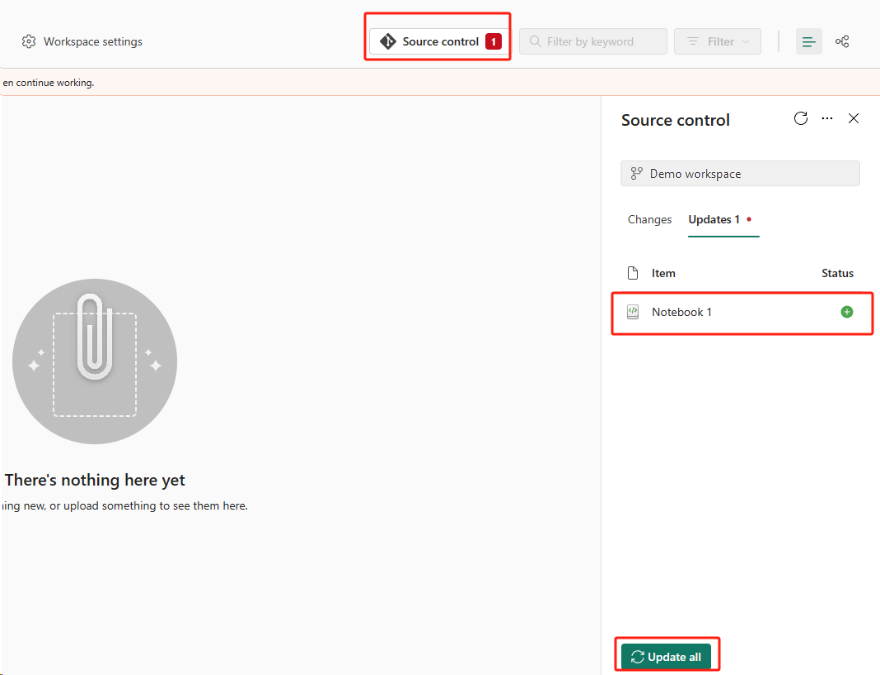
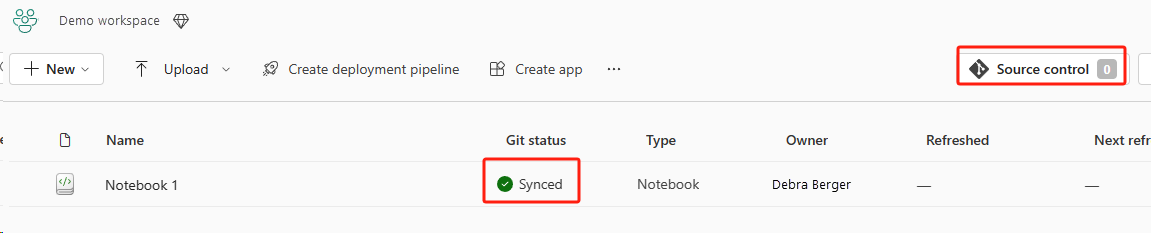
На следующем рисунке показана синхронизированная записная книжка.
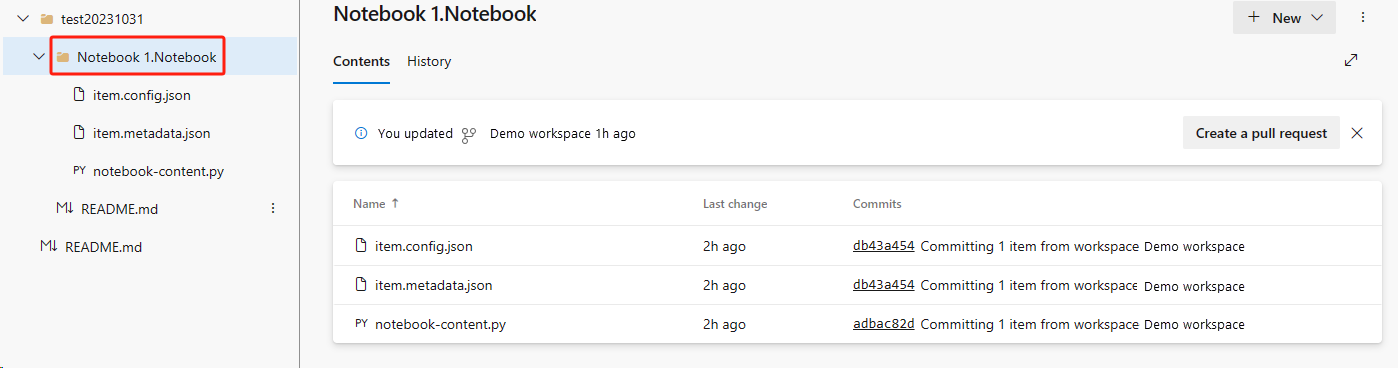
Восстановите записную книжку из репозитория ADO.
В созданной рабочей области снова подключитесь к репозиторию Azure ADO.
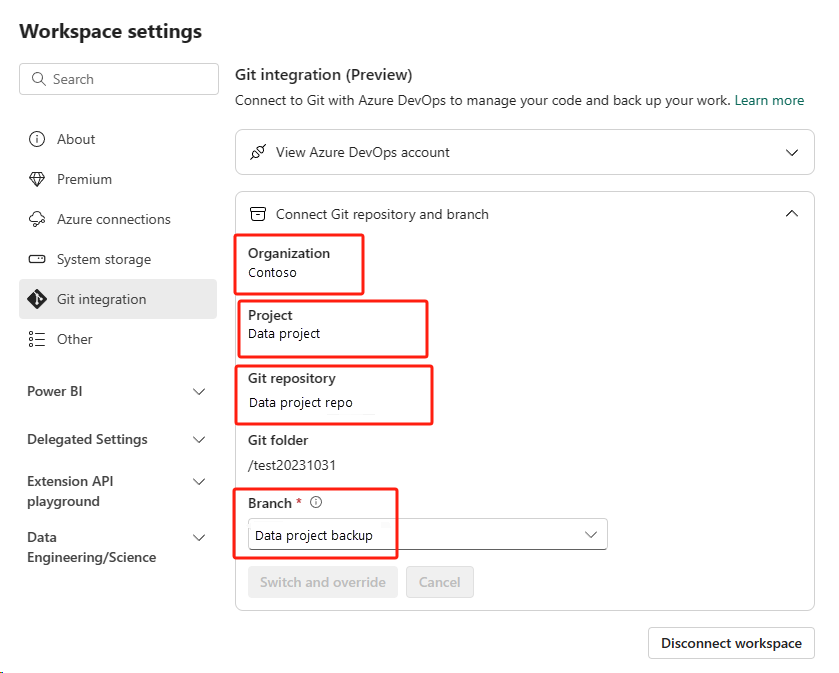
Нажмите кнопку управления версиями. Затем выберите соответствующую ветвь репозитория. Затем нажмите кнопку "Обновить все". Появится исходная записная книжка.
Если исходная записная книжка имеет озеро по умолчанию, пользователи могут обратиться к разделу Lakehouse, чтобы восстановить озеро, а затем подключить только что восстановленный lakehouse к вновь восстановленной записной книжке.
Интеграция Git не поддерживает синхронизацию файлов, папок или моментальных снимков записных книжек в обозревателе ресурсов записной книжки.
Если исходная записная книжка содержит файлы в обозревателе ресурсов записной книжки:
Не забудьте сохранить файлы или папки на локальный диск или в другом месте.
Повторно отправьте файл с локального диска или облачных дисков в восстановленную записную книжку.
Если в исходной записной книжке есть моментальный снимок записной книжки, сохраните моментальный снимок записной книжки в собственной системе управления версиями или локальном диске.
Дополнительные сведения об интеграции с Git см. в статье "Введение в интеграцию с Git".
Подход 2. Ручной подход к резервному копированию содержимого кода
Если вы не используете подход к интеграции с Git, вы можете сохранить последнюю версию кода, файлы в обозревателе ресурсов и моментальный снимок записной книжки в системе управления версиями, например Git, и вручную восстановить содержимое записной книжки после аварии:
Используйте функцию импорта записной книжки для импорта кода записной книжки, который требуется восстановить.
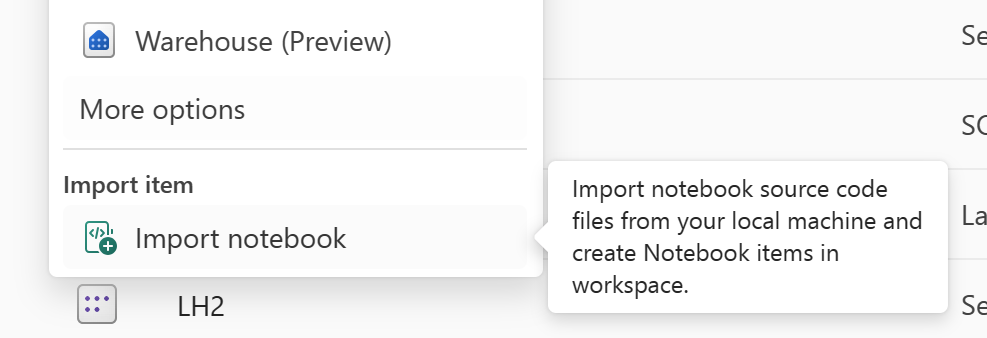
После импорта перейдите в нужную рабочую область (например, "C2". W2") для доступа к нему.
Если исходная записная книжка имеет озеро по умолчанию, обратитесь к разделу Lakehouse. Затем подключите вновь восстановленный lakehouse (который имеет то же содержимое, что и исходное озеро по умолчанию) к вновь восстановленной записной книжке.
Если исходная записная книжка содержит файлы или папки в обозревателе ресурсов, повторно отправьте файлы или папки, сохраненные в системе управления версиями пользователя.
Определение задания Spark
Определения заданий Spark (SJD) из основного региона остаются недоступными для клиентов, а основной файл определения и файл ссылок в записной книжке будут реплицированы в дополнительный регион через OneLake. Если вы хотите восстановить SJD в новом регионе, выполните описанные ниже действия, чтобы восстановить SJD. Обратите внимание, что исторические запуски SJD не будут восстановлены.
Чтобы восстановить элементы SJD, скопируйте код из исходного региона с помощью обозревателя служба хранилища Azure и повторного подключения ссылок Lakehouse после аварии.
Создайте новый элемент SJD (например, SJD1) в новой рабочей области C2. W2 с теми же параметрами и конфигурациями, что и исходный элемент SJD (например, язык, среда и т. д.).
Используйте обозреватель хранилища Azure для копирования папок Libs, Mains и моментальных снимков из исконного элемента SJD в новый элемент SJD.
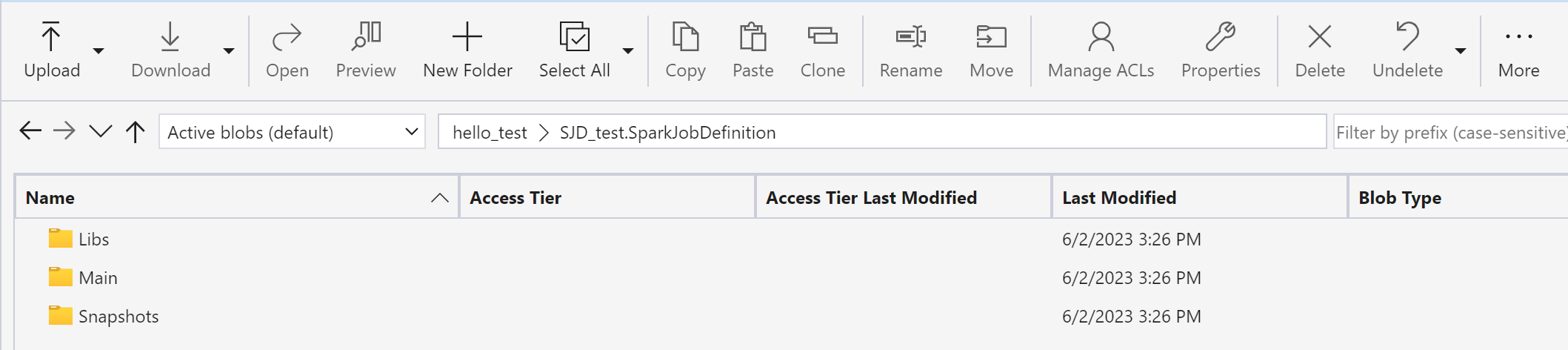
Содержимое кода появится в только что созданном SJD. Вам потребуется вручную добавить только что восстановленную ссылку Lakehouse на задание (см . инструкции по восстановлению Lakehouse). Пользователям потребуется повторно ввести исходные аргументы командной строки вручную.
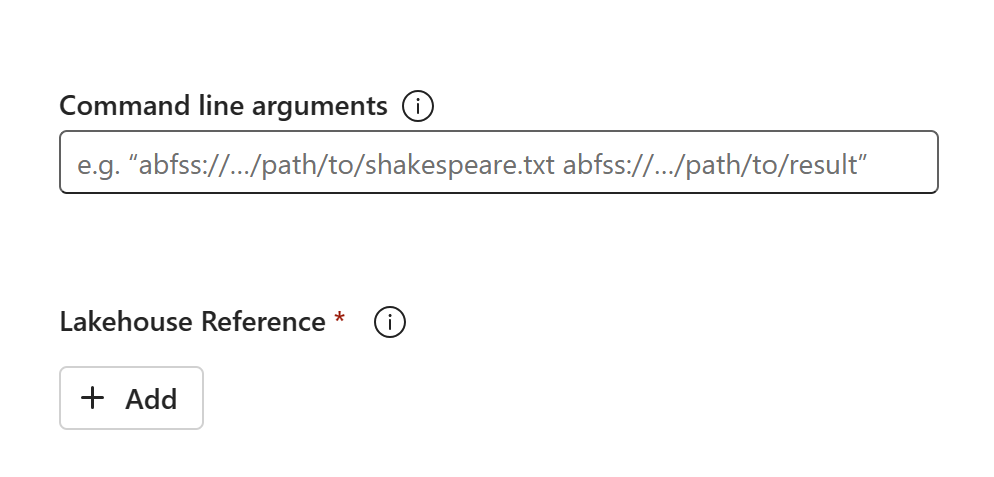
Теперь вы можете запустить или запланировать только что восстановленный SJD.
Дополнительные сведения о обозревателе служба хранилища Azure см. в статье Интеграция OneLake с служба хранилища Azure Explorer.
Обработка и анализ данных
В этом руководстве описаны процедуры восстановления для интерфейса Обработка и анализ данных. В нем рассматриваются модели машинного обучения и эксперименты.
Модель машинного обучения и эксперимент
Обработка и анализ данных элементы из основного региона остаются недоступными для клиентов, а содержимое и метаданные в моделях машинного обучения и экспериментах не будут реплицироваться в дополнительный регион. Чтобы полностью восстановить их в новом регионе, сохраните содержимое кода в системе управления версиями (например, Git) и повторно запустите содержимое кода после аварии.
Восстановите записную книжку. Ознакомьтесь с инструкциями по восстановлению записной книжки.
Конфигурация, исторически выполняемые метрики и метаданные не будут реплицироваться в парный регион. Вам придется повторно запустить каждую версию кода для обработки и анализа данных, чтобы полностью восстановить модели машинного обучения и эксперименты после аварии.
Хранилище данных
В этом руководстве описаны процедуры восстановления для интерфейса хранилища данных. Он охватывает склады.
Склад
Склады из исходного региона остаются недоступными для клиентов. Чтобы восстановить склады, выполните следующие два шага.
Создайте промежуточное озеро в рабочей области C2. W2 для данных, которые будут скопированы из исходного хранилища.
Заполните разностные таблицы хранилища, используя обозреватель хранилища и возможности T-SQL (см . таблицы в хранилище данных в Microsoft Fabric).
Примечание.
Рекомендуется сохранить код хранилища (схему, таблицу, представление, хранимую процедуру, определения функций и коды безопасности), версию и сохранение в безопасном расположении (например, Git) в соответствии с рекомендациями по разработке.
Прием данных с помощью кода Lakehouse и T-SQL
В созданной рабочей области C2. W2:
Создайте промежуточный озерный дом "LH2" в C2. W2.
Восстановите таблицы Delta в промежуточном озерном доме из исходного склада, выполнив действия по восстановлению Lakehouse.
Создайте хранилище "WH2" в C2. W2.
Подключите промежуточное озеро в обозревателе хранилища.
В зависимости от способа развертывания определений таблиц перед импортом данных фактический T-SQL, используемый для импорта, может отличаться. Вы можете использовать метод INSERT INTO, SELECT INTO или CREATE TABLE AS SELECT для восстановления таблиц хранилища из lakehouses. Далее в примере мы будем использовать в качестве варианта INSERT INTO. (Если вы используете приведенный ниже код, замените примеры фактическими именами таблиц и столбцов)
USE WH1 INSERT INTO [dbo].[aggregate_sale_by_date_city]([Date],[City],[StateProvince],[SalesTerritory],[SumOfTotalExcludingTax],[SumOfTaxAmount],[SumOfTotalIncludingTax], [SumOfProfit]) SELECT [Date],[City],[StateProvince],[SalesTerritory],[SumOfTotalExcludingTax],[SumOfTaxAmount],[SumOfTotalIncludingTax], [SumOfProfit] FROM [LH11].[dbo].[aggregate_sale_by_date_city] GOНаконец, измените строка подключения в приложениях с помощью хранилища Fabric.
Примечание.
Для клиентов, которым требуется аварийное восстановление между регионами и полностью автоматизированная непрерывность бизнес-процессов, рекомендуется сохранять две настройки хранилища Fabric в отдельных регионах Fabric и поддерживать четность кода и данных, выполняя регулярные развертывания и прием данных на обоих сайтах.
Зеркальная база данных
Зеркальные базы данных из основного региона остаются недоступными для клиентов, и параметры не реплицируются в дополнительный регион. Чтобы восстановить его в случае регионального сбоя, необходимо повторно создать зеркальную базу данных в другой рабочей области из другого региона.
Фабрика данных
Элементы фабрики данных из основного региона остаются недоступными для клиентов, а параметры и конфигурация в конвейерах данных или элементах потока данных 2-го поколения не будут реплицироваться в дополнительный регион. Чтобы восстановить эти элементы в случае регионального сбоя, необходимо повторно создать элементы Интеграция данных в другой рабочей области из другого региона. В следующих разделах описаны сведения.
Потоки данных 2-го поколения
Если вы хотите восстановить элемент потока данных 2-го поколения в новом регионе, необходимо экспортировать PQT-файл в систему управления версиями, например Git, а затем вручную восстановить содержимое потока данных 2-го поколения после аварии.
В элементе потока данных 2-го поколения на вкладке "Главная" редактора Power Query выберите "Экспорт шаблона".
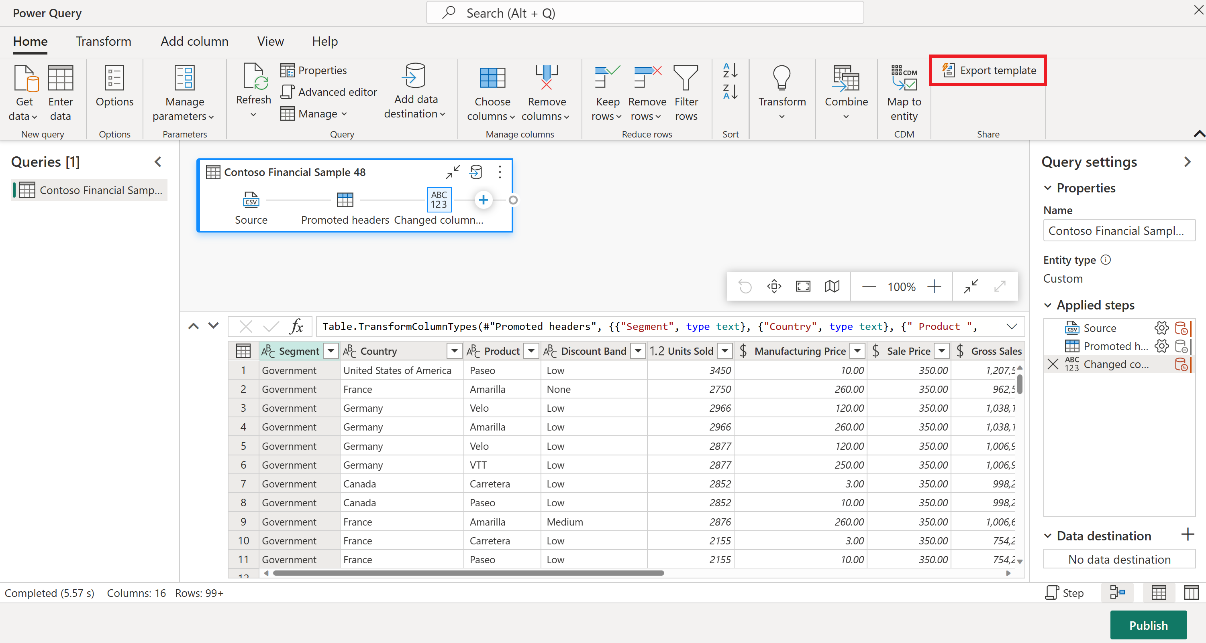
В диалоговом окне "Экспорт шаблона" введите имя (обязательно) и описание (необязательно) для этого шаблона. При готовности выберите ОК.
После аварии создайте элемент потока данных 2-го поколения в новой рабочей области "C2". W2".
В текущей области представления редактора Power Query выберите "Импорт" из шаблона Power Query.
В диалоговом окне "Открыть" перейдите к папке загрузки по умолчанию и выберите PQT-файл , сохраненный на предыдущих шагах. Щелкните Открыть.
Затем шаблон импортируется в новый элемент потока данных 2-го поколения.
Конвейеры данных
Клиенты не могут получить доступ к конвейерам данных в случае региональной аварии, а конфигурации не реплицируются в парном регионе. Рекомендуется создавать критически важные конвейеры данных в нескольких рабочих областях в разных регионах.
Создать копию задания
Пользователи CopyJob должны предпринять упреждающие меры для защиты от региональной катастрофы. Данный подход гарантирует, что копии заданий пользователя остаются доступными после региональной катастрофы.
Избыточность, управляемая пользователем, с интеграцией Git (в общедоступной предварительной версии)
Лучший способ упростить этот процесс и быстро — использовать интеграцию Fabric Git, а затем синхронизировать CopyJob с репозиторием ADO. После перехода службы на другой регион, можно использовать репозиторий для перестройки задания CopyJob в созданной вами рабочей области.
Настройте интеграцию Git рабочей области и выберите подключиться и синхронизировать с репозиторием ADO.
На следующем рисунке показан синхронизированный файл CopyJob.
Восстановите файл CopyJob из репозитория ADO.
В созданной рабочей области снова подключитесь и синхронизируйте его с вашим репозиторием Azure ADO. Все элементы Fabric в этом репозитории автоматически скачиваются в новое рабочее пространство.
Если исходный CopyJob использует Lakehouse, пользователи могут ссылаться на раздел Lakehouse для восстановления Lakehouse, а затем подключить только что восстановленный CopyJob к вновь восстановленному Lakehouse.
Дополнительные сведения об интеграции с Git см. в статье "Введение в интеграцию с Git".
Аналитика в режиме реального времени
В этом руководстве описаны процедуры восстановления для интерфейса аналитики в режиме реального времени. В нем рассматриваются базы данных KQL, наборы запросов и потоки событий.
База данных или набор запросов KQL
Пользователи базы данных и набора запросов KQL должны предпринять упреждающие меры для защиты от региональной катастрофы. Следующий подход гарантирует, что в случае региональной аварии данные в наборах запросов к базам данных KQL остаются безопасными и доступными.
Чтобы гарантировать эффективное решение аварийного восстановления для баз данных и наборов запросов KQL, выполните следующие действия.
Создайте независимые базы данных KQL: настройте две или более независимые базы данных или наборы запросов KQL на выделенных емкостях Fabric. Они должны быть настроены в двух разных регионах Azure (желательно в парных регионах Azure), чтобы обеспечить максимальную устойчивость.
Репликация действий управления: все действия управления, выполненные в одной базе данных KQL, должны быть зеркально отражены в другой. Это гарантирует, что обе базы данных остаются в синхронизации. Ключевые действия для репликации включают:
Таблицы. Убедитесь, что структуры таблиц и определения схемы согласованы между базами данных.
Сопоставление: дублируются все необходимые сопоставления. Убедитесь, что источники данных и назначения правильно выравниваются.
Политики. Убедитесь, что обе базы данных имеют аналогичные политики хранения, доступа и других соответствующих политик.
Управление проверкой подлинности и авторизацией. Для каждой реплики настройте необходимые разрешения. Убедитесь, что установлены соответствующие уровни авторизации, предоставляя доступ к требуемому персоналу при сохранении стандартов безопасности.
Параллельное прием данных. Чтобы обеспечить согласованность и готовность данных в нескольких регионах, загрузите один и тот же набор данных в каждую базу данных KQL одновременно с приемом данных.
Поток событий
Поток событий — это централизованное место на платформе Fabric для записи, преобразования и маршрутизации событий в режиме реального времени в различные места назначения (например, lakehouses, KQL database/querysets) с интерфейсом без кода. До тех пор, пока назначения поддерживаются аварийным восстановлением, потоки событий не теряют данные. Поэтому клиенты должны использовать возможности аварийного восстановления этих целевых систем для обеспечения доступности данных.
Клиенты также могут достичь геоизбыточности путем развертывания идентичных рабочих нагрузок Eventstream в нескольких регионах Azure в рамках многосайтовой стратегии активности и активности. Благодаря многосайтовому активному и активному подходу клиенты могут получить доступ к рабочей нагрузке в любом развернутом регионе. Этот подход является самым сложным и дорогостоящим подходом к аварийному восстановлению, но может сократить время восстановления до нуля в большинстве ситуаций. Чтобы быть полностью геоизбыточным, клиенты могут
Создайте реплики источников данных в разных регионах.
Создание элементов Eventstream в соответствующих регионах.
Подключите эти новые элементы к идентичным источникам данных.
Добавьте одинаковые назначения для каждого потока событий в разных регионах.