Руководство, часть 3. Обучение и регистрация модели машинного обучения
В этом руководстве вы узнаете, как обучить несколько моделей машинного обучения, чтобы выбрать лучший, чтобы предсказать, какие клиенты банка, скорее всего, уходят.
В этом руководстве вы выполните следующие действия.
- Обучение моделей случайного леса и LightGBM.
- Используйте встроенную интеграцию Microsoft Fabric с платформой MLflow для регистрации обученных моделей машинного обучения, используемых гиперпараметров и метрик оценки.
- Зарегистрируйте обученную модель машинного обучения.
- Оцените производительность обученных моделей машинного обучения в наборе данных проверки.
MLflow — это платформа открытый код для управления жизненным циклом машинного обучения с такими функциями, как отслеживание, модели и реестр моделей. MLflow изначально интегрирован с интерфейсом Обработка и анализ данных Fabric.
Необходимые компоненты
Получение подписки Microsoft Fabric. Или зарегистрируйте бесплатную пробную версию Microsoft Fabric.
Войдите в Microsoft Fabric.
Используйте переключатель интерфейса в левой нижней части домашней страницы, чтобы перейти на Fabric.

Это часть 3 из 5 в серии учебников. Чтобы завершить работу с этим руководством, сначала выполните указанные ниже действия.
- Часть 1. Прием данных в microsoft Fabric lakehouse с помощью Apache Spark.
- Часть 2. Изучение и визуализация данных с помощью записных книжек Microsoft Fabric для получения дополнительных сведений о данных.
Следуйте инструкциям в записной книжке
3-train-evaluate.ipynb — это записная книжка, сопровождающая это руководство.
Чтобы открыть сопровождающую записную книжку для этого руководства, следуйте инструкциям в Подготовьте систему для учебников по науке о данных, чтобы импортировать записную книжку в ваше рабочее пространство.
Если вы хотите скопировать и вставить код на этой странице, можно создать новую записную книжку.
Перед запуском кода обязательно подключите lakehouse к записной книжке .
Внимание
Прикрепите тот же лейкхаус, который использовался в части 1 и части 2.
Установка пользовательских библиотек
Для этой записной книжки вы установите несбалансированное обучение (импортированное как imblearn) с помощью %pip install. Несбалансированное обучение — это библиотека для синтетического метода oversampling (SMOTE), которая используется при работе с несбалансированных наборов данных. Ядро PySpark будет перезапущено после %pip installэтого, поэтому перед запуском других ячеек необходимо установить библиотеку.
Вы получите доступ к SMOTE с помощью библиотеки imblearn . Установите его теперь с помощью встроенных возможностей установки (например, %pip, %conda).
# Install imblearn for SMOTE using pip
%pip install imblearn
Внимание
Запустите эту установку при каждом перезапуске записной книжки.
При установке библиотеки в записную книжку она доступна только в течение сеанса записной книжки, а не в рабочей области. Если перезапустить записную книжку, необходимо снова установить библиотеку.
Если у вас часто используется библиотека, и вы хотите сделать ее доступной для всех записных книжек в рабочей области, вы можете использовать среду Fabric для этой цели. Вы можете создать среду, установить в нее библиотеку, а затем администратор рабочей области может присоединить среду к рабочей области в качестве среды по умолчанию. Дополнительные сведения о настройке среды в качестве рабочей области по умолчанию см. в разделе "Администраторы" задает библиотеки по умолчанию для рабочей области.
Сведения о переносе существующих библиотек рабочей области и свойств Spark в среду см. в разделе "Миграция библиотек рабочей области" и свойств Spark в среду по умолчанию.
Загрузка данных
Перед обучением любой модели машинного обучения необходимо загрузить разностную таблицу из lakehouse, чтобы прочитать чистые данные, созданные в предыдущей записной книжке.
import pandas as pd
SEED = 12345
df_clean = spark.read.format("delta").load("Tables/df_clean").toPandas()
Создание эксперимента для отслеживания и ведения журнала модели с помощью MLflow
В этом разделе показано, как создать эксперимент, указать модель машинного обучения и параметры обучения, а также метрики оценки, обучить модели машинного обучения, записать их и сохранить обученные модели для последующего использования.
import mlflow
# Setup experiment name
EXPERIMENT_NAME = "bank-churn-experiment" # MLflow experiment name
Расширение возможностей автологирования MLflow, автоматическое создание журнала работает путем автоматического записи значений входных параметров и выходных метрик модели машинного обучения при его обучении. Затем эти сведения записываются в рабочую область, где ее можно получить и визуализировать с помощью API MLflow или соответствующего эксперимента в рабочей области.
Все эксперименты с соответствующими именами регистрируются, и вы сможете отслеживать их параметры и метрики производительности. Дополнительные сведения об автологе см. в статье "Автологирование" в Microsoft Fabric.
Настройка спецификаций эксперимента и автологирования
mlflow.set_experiment(EXPERIMENT_NAME)
mlflow.autolog(exclusive=False)
Импорт scikit-learn и LightGBM
С помощью данных теперь можно определить модели машинного обучения. В этой записной книжке будут применяться модели Случайного леса и LightGBM. Использование scikit-learn и lightgbm реализация моделей в нескольких строках кода.
# Import the required libraries for model training
from sklearn.model_selection import train_test_split
from lightgbm import LGBMClassifier
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score, f1_score, precision_score, confusion_matrix, recall_score, roc_auc_score, classification_report
Подготовка наборов данных для обучения, проверки и тестирования
Используйте функцию train_test_split для scikit-learn разделения данных на наборы для обучения, проверки и тестирования.
y = df_clean["Exited"]
X = df_clean.drop("Exited",axis=1)
# Split the dataset to 60%, 20%, 20% for training, validation, and test datasets
# Train-Test Separation
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.20, random_state=SEED)
# Train-Validation Separation
X_train, X_val, y_train, y_val = train_test_split(X_train, y_train, test_size=0.25, random_state=SEED)
Сохранение тестовых данных в разностную таблицу
Сохраните тестовые данные в разностную таблицу для использования в следующей записной книжке.
table_name = "df_test"
# Create PySpark DataFrame from Pandas
df_test=spark.createDataFrame(X_test)
df_test.write.mode("overwrite").format("delta").save(f"Tables/{table_name}")
print(f"Spark test DataFrame saved to delta table: {table_name}")
Применение SMOTE к учебным данным для синтеза новых образцов для класса меньшинства
Исследование данных в части 2 показало, что из 10 000 точек данных, соответствующих 10 000 клиентов, только 20 037 клиентов (около 20%) покинули банк. Это означает, что набор данных сильно несбалансирован. Проблема с несбалансированной классификацией заключается в том, что существует слишком мало примеров класса меньшинства для эффективного изучения границы принятия решений. SMOTE является наиболее широко используемым подходом для синтеза новых образцов для класса меньшинства. Узнайте больше о SMOTE здесь и здесь.
Совет
Обратите внимание, что SMOTE следует применять только к набору обучающих данных. Чтобы получить допустимое приближение модели машинного обучения к исходному несбалансированному распределению, необходимо оставить тестовый набор данных в исходном распределении, представляющего ситуацию в рабочей среде.
from collections import Counter
from imblearn.over_sampling import SMOTE
sm = SMOTE(random_state=SEED)
X_res, y_res = sm.fit_resample(X_train, y_train)
new_train = pd.concat([X_res, y_res], axis=1)
Совет
Вы можете безопасно игнорировать предупреждение MLflow, которое отображается при запуске этой ячейки.
Если вы видите сообщение ModuleNotFoundError , вы пропустили первую ячейку в этой записной книжке, которая устанавливает библиотеку imblearn . Эту библиотеку необходимо установить при каждом перезапуске записной книжки. Вернитесь и повторно запустите все ячейки, начиная с первой ячейки в этой записной книжке.
Обучение модели
- Обучение модели с помощью случайного леса с максимальной глубиной 4 и 4 функций
mlflow.sklearn.autolog(registered_model_name='rfc1_sm') # Register the trained model with autologging
rfc1_sm = RandomForestClassifier(max_depth=4, max_features=4, min_samples_split=3, random_state=1) # Pass hyperparameters
with mlflow.start_run(run_name="rfc1_sm") as run:
rfc1_sm_run_id = run.info.run_id # Capture run_id for model prediction later
print("run_id: {}; status: {}".format(rfc1_sm_run_id, run.info.status))
# rfc1.fit(X_train,y_train) # Imbalanaced training data
rfc1_sm.fit(X_res, y_res.ravel()) # Balanced training data
rfc1_sm.score(X_val, y_val)
y_pred = rfc1_sm.predict(X_val)
cr_rfc1_sm = classification_report(y_val, y_pred)
cm_rfc1_sm = confusion_matrix(y_val, y_pred)
roc_auc_rfc1_sm = roc_auc_score(y_res, rfc1_sm.predict_proba(X_res)[:, 1])
- Обучение модели с помощью случайного леса с максимальной глубиной 8 и 6 функций
mlflow.sklearn.autolog(registered_model_name='rfc2_sm') # Register the trained model with autologging
rfc2_sm = RandomForestClassifier(max_depth=8, max_features=6, min_samples_split=3, random_state=1) # Pass hyperparameters
with mlflow.start_run(run_name="rfc2_sm") as run:
rfc2_sm_run_id = run.info.run_id # Capture run_id for model prediction later
print("run_id: {}; status: {}".format(rfc2_sm_run_id, run.info.status))
# rfc2.fit(X_train,y_train) # Imbalanced training data
rfc2_sm.fit(X_res, y_res.ravel()) # Balanced training data
rfc2_sm.score(X_val, y_val)
y_pred = rfc2_sm.predict(X_val)
cr_rfc2_sm = classification_report(y_val, y_pred)
cm_rfc2_sm = confusion_matrix(y_val, y_pred)
roc_auc_rfc2_sm = roc_auc_score(y_res, rfc2_sm.predict_proba(X_res)[:, 1])
- Обучение модели с помощью LightGBM
# lgbm_model
mlflow.lightgbm.autolog(registered_model_name='lgbm_sm') # Register the trained model with autologging
lgbm_sm_model = LGBMClassifier(learning_rate = 0.07,
max_delta_step = 2,
n_estimators = 100,
max_depth = 10,
eval_metric = "logloss",
objective='binary',
random_state=42)
with mlflow.start_run(run_name="lgbm_sm") as run:
lgbm1_sm_run_id = run.info.run_id # Capture run_id for model prediction later
# lgbm_sm_model.fit(X_train,y_train) # Imbalanced training data
lgbm_sm_model.fit(X_res, y_res.ravel()) # Balanced training data
y_pred = lgbm_sm_model.predict(X_val)
accuracy = accuracy_score(y_val, y_pred)
cr_lgbm_sm = classification_report(y_val, y_pred)
cm_lgbm_sm = confusion_matrix(y_val, y_pred)
roc_auc_lgbm_sm = roc_auc_score(y_res, lgbm_sm_model.predict_proba(X_res)[:, 1])
Артефакт экспериментов для отслеживания производительности модели
Выполнение эксперимента автоматически сохраняется в артефакте эксперимента, который можно найти в рабочей области. Они называются на основе имени, используемого для задания эксперимента. Регистрируются все обученные модели машинного обучения, их запуски, метрики производительности и параметры модели.
Чтобы просмотреть эксперименты, выполните следующее:
На левой панели выберите рабочую область.
В правом верхнем углу отфильтруйте только эксперименты, чтобы упростить поиск нужного эксперимента.
Найдите и выберите имя эксперимента, в данном случае банк-отток-эксперимент. Если эксперимент не отображается в рабочей области, обновите браузер.


Оценка производительности обученных моделей в наборе данных проверки
После обучения модели машинного обучения можно оценить производительность обученных моделей двумя способами.
Откройте сохраненный эксперимент из рабочей области, загрузите модели машинного обучения и оцените производительность загруженных моделей в наборе данных проверки.
# Define run_uri to fetch the model # mlflow client: mlflow.model.url, list model load_model_rfc1_sm = mlflow.sklearn.load_model(f"runs:/{rfc1_sm_run_id}/model") load_model_rfc2_sm = mlflow.sklearn.load_model(f"runs:/{rfc2_sm_run_id}/model") load_model_lgbm1_sm = mlflow.lightgbm.load_model(f"runs:/{lgbm1_sm_run_id}/model") # Assess the performance of the loaded model on validation dataset ypred_rfc1_sm_v1 = load_model_rfc1_sm.predict(X_val) # Random Forest with max depth of 4 and 4 features ypred_rfc2_sm_v1 = load_model_rfc2_sm.predict(X_val) # Random Forest with max depth of 8 and 6 features ypred_lgbm1_sm_v1 = load_model_lgbm1_sm.predict(X_val) # LightGBMНепосредственно оцените производительность обученных моделей машинного обучения в наборе данных проверки.
ypred_rfc1_sm_v2 = rfc1_sm.predict(X_val) # Random Forest with max depth of 4 and 4 features ypred_rfc2_sm_v2 = rfc2_sm.predict(X_val) # Random Forest with max depth of 8 and 6 features ypred_lgbm1_sm_v2 = lgbm_sm_model.predict(X_val) # LightGBM
В зависимости от вашего предпочтения любой подход хорошо подходит и должен предлагать идентичные производительности. В этой записной книжке вы выберете первый подход, чтобы лучше продемонстрировать возможности автологирования MLflow в Microsoft Fabric.
Отображение истинных и ложных срабатываний/отрицательных значений с помощью матрицы путаницы
Затем вы создадите скрипт для построения матрицы путаницы, чтобы оценить точность классификации с помощью набора данных проверки. Матрица путаницы может быть представлена с помощью средств SynapseML, который также показан в примере обнаружения мошенничества, который доступен здесь.
import seaborn as sns
sns.set_theme(style="whitegrid", palette="tab10", rc = {'figure.figsize':(9,6)})
import matplotlib.pyplot as plt
import matplotlib.ticker as mticker
from matplotlib import rc, rcParams
import numpy as np
import itertools
def plot_confusion_matrix(cm, classes,
normalize=False,
title='Confusion matrix',
cmap=plt.cm.Blues):
print(cm)
plt.figure(figsize=(4,4))
plt.rcParams.update({'font.size': 10})
plt.imshow(cm, interpolation='nearest', cmap=cmap)
plt.title(title)
plt.colorbar()
tick_marks = np.arange(len(classes))
plt.xticks(tick_marks, classes, rotation=45, color="blue")
plt.yticks(tick_marks, classes, color="blue")
fmt = '.2f' if normalize else 'd'
thresh = cm.max() / 2.
for i, j in itertools.product(range(cm.shape[0]), range(cm.shape[1])):
plt.text(j, i, format(cm[i, j], fmt),
horizontalalignment="center",
color="red" if cm[i, j] > thresh else "black")
plt.tight_layout()
plt.ylabel('True label')
plt.xlabel('Predicted label')
- Матрица путаницы для классификатора случайного леса с максимальной глубиной 4 и 4 признаков
cfm = confusion_matrix(y_val, y_pred=ypred_rfc1_sm_v1)
plot_confusion_matrix(cfm, classes=['Non Churn','Churn'],
title='Random Forest with max depth of 4')
tn, fp, fn, tp = cfm.ravel()
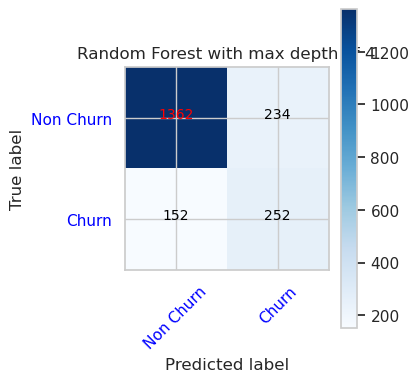
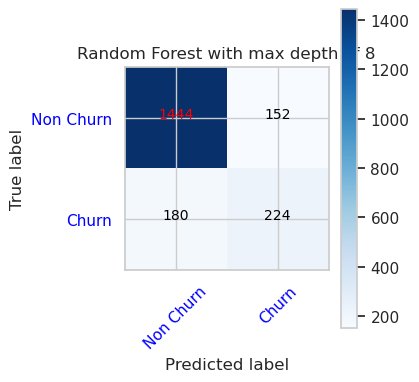
- Матрица путаницы для классификатора случайного леса с максимальной глубиной 8 и 6 функций
cfm = confusion_matrix(y_val, y_pred=ypred_rfc2_sm_v1)
plot_confusion_matrix(cfm, classes=['Non Churn','Churn'],
title='Random Forest with max depth of 8')
tn, fp, fn, tp = cfm.ravel()
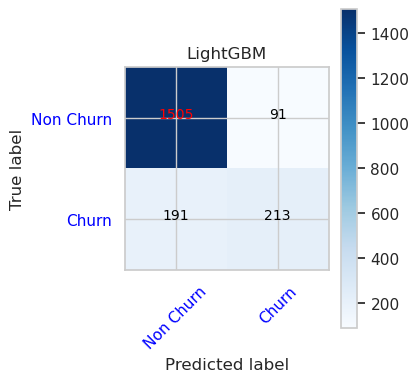
- Матрица путаницы для LightGBM
cfm = confusion_matrix(y_val, y_pred=ypred_lgbm1_sm_v1)
plot_confusion_matrix(cfm, classes=['Non Churn','Churn'],
title='LightGBM')
tn, fp, fn, tp = cfm.ravel()