Руководство: Создание, оценка и выставление баллов для системы рекомендаций
В этом руководстве представлен полный пример рабочего процесса Обработки и анализа данных Synapse в Microsoft Fabric. Сценарий создает модель для рекомендаций по онлайн-книге.
В этом руководстве рассматриваются следующие действия.
- Загрузите данные в lakehouse
- Выполнение исследовательского анализа данных
- Обучение модели и ведение журнала с помощью MLflow
- Загрузка модели и создание прогнозов
У нас есть множество типов доступных алгоритмов рекомендаций. В этом руководстве используется алгоритм коэффициентизации матрицы Alternating Least Squares (ALS). ALS — это алгоритм совместной фильтрации на основе модели.

ALS пытается оценить матрицу рейтингов R как произведение двух матриц низкого ранга, U и V. Здесь R = U * V^T. Как правило, эти приближения называются матрицами фактора .
Алгоритм ALS является итеративным. Каждая итерация содержит одну из констант матриц факторов, а она решает другую с помощью метода наименьших квадратов. Затем он фиксирует новое решение для постоянной матрицы факторов, пока решает другую матрицу факторов.

Необходимые условия
Получите подписку Microsoft Fabric. Или подпишитесь на бесплатную пробную версию Microsoft Fabric.
Войдите в Microsoft Fabric.
Используйте переключатель интерфейса в левой нижней части домашней страницы, чтобы перейти на Fabric.

- При необходимости создайте озеро Microsoft Fabric, как описано в разделе Создание озера в Microsoft Fabric.
Следуйте инструкциям в записной книжке
Вы можете выбрать один из следующих вариантов для выполнения в записной книжке:
- Откройте и запустите встроенную записную книжку.
- Отправьте записную книжку из GitHub.
Открытие встроенной записной книжки
Пример рекомендации книги записной книжке сопровождается этим руководством.
Чтобы открыть образец блокнота для этого руководства, следуйте инструкциям в Подготовка системы для учебников по анализу данных.
Прежде чем начать выполнение кода, обязательно подключите lakehouse к записной книжке.
Импорт записной книжки из GitHub
Файл AIsample — Book Recommendation.ipynb сопровождает этот учебник.
Чтобы открыть сопровождающую записную книжку для этого руководства, следуйте инструкциям в подготовки системы для учебных курсов по науке о данных, чтобы импортировать записную книжку в вашу рабочую область.
Если вы хотите скопировать и вставить код на этой странице, можно создать новую записную книжку.
Не забудьте подключить lakehouse к ноутбуку перед тем, как начать выполнение кода.
Шаг 1. Загрузка данных
Набор данных рекомендаций книги в этом сценарии состоит из трех отдельных наборов данных:
Books.csv: Международный стандартный номер книги (ISBN) идентифицирует каждую книгу, с уже удалёнными недействительными датами. Набор данных также содержит заголовок, автор и издатель. Для книги с несколькими авторами файл Books.csv содержит только первого автора. URL-адреса указывают на ресурсы веб-сайта Amazon для изображений обложки в трех размерах.
Номер ISBN Book-Title Book-Author Год-Of-Publication Издатель Изображение —URL-S Изображение -URL-M Image-URL-l 0195153448 Классическая мифология Марк. О. Морфорд 2002 Оксфордский университет прессы http://images.amazon.com/images/P/0195153448.01.THUMBZZZ.jpg http://images.amazon.com/images/P/0195153448.01.MZZZZZZZ.jpg http://images.amazon.com/images/P/0195153448.01.LZZZZZZZ.jpg 0002005018 Клара Каллан Ричард Брюс Райт 2001 ХарперФламинго Канада http://images.amazon.com/images/P/0002005018.01.THUMBZZZ.jpg http://images.amazon.com/images/P/0002005018.01.MZZZZZZZ.jpg http://images.amazon.com/images/P/0002005018.01.LZZZZZZZ.jpg Ratings.csv: оценки для каждой книги являются явными (предоставляемыми пользователями по шкале от 1 до 10) или неявными (наблюдаемые без участия пользователя и обозначаются 0).
User-ID Номер ISBN Book-Rating 276725 034545104X 0 276726 0155061224 5 Users.csv: идентификаторы пользователей анонимизированы и сопоставляются с целыми числами. Демографические данные, например расположение и возраст, предоставляются, если они доступны. Если эти данные недоступны, значения равны
null.User-ID Местоположение Возраст 1 Нью-Йорк Нью-Йорк США 2 Стоктон, Калифорния, США 18.0
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Определите эти параметры, чтобы эту записную книжку можно было использовать с различными наборами данных:
IS_CUSTOM_DATA = False # If True, the dataset has to be uploaded manually
USER_ID_COL = "User-ID" # Must not be '_user_id' for this notebook to run successfully
ITEM_ID_COL = "ISBN" # Must not be '_item_id' for this notebook to run successfully
ITEM_INFO_COL = (
"Book-Title" # Must not be '_item_info' for this notebook to run successfully
)
RATING_COL = (
"Book-Rating" # Must not be '_rating' for this notebook to run successfully
)
IS_SAMPLE = True # If True, use only <SAMPLE_ROWS> rows of data for training; otherwise, use all data
SAMPLE_ROWS = 5000 # If IS_SAMPLE is True, use only this number of rows for training
DATA_FOLDER = "Files/book-recommendation/" # Folder that contains the datasets
ITEMS_FILE = "Books.csv" # File that contains the item information
USERS_FILE = "Users.csv" # File that contains the user information
RATINGS_FILE = "Ratings.csv" # File that contains the rating information
EXPERIMENT_NAME = "aisample-recommendation" # MLflow experiment name
Скачивание и хранение данных в lakehouse
Этот код скачивает набор данных, а затем сохраняет его в lakehouse.
Важный
Перед запуском записной книжки обязательно добавить lakehouse. В противном случае вы получите ошибку.
if not IS_CUSTOM_DATA:
# Download data files into a lakehouse if they don't exist
import os, requests
remote_url = "https://synapseaisolutionsa.blob.core.windows.net/public/Book-Recommendation-Dataset"
file_list = ["Books.csv", "Ratings.csv", "Users.csv"]
download_path = f"/lakehouse/default/{DATA_FOLDER}/raw"
if not os.path.exists("/lakehouse/default"):
raise FileNotFoundError(
"Default lakehouse not found, please add a lakehouse and restart the session."
)
os.makedirs(download_path, exist_ok=True)
for fname in file_list:
if not os.path.exists(f"{download_path}/{fname}"):
r = requests.get(f"{remote_url}/{fname}", timeout=30)
with open(f"{download_path}/{fname}", "wb") as f:
f.write(r.content)
print("Downloaded demo data files into lakehouse.")
Настройка отслеживания экспериментов MLflow
Используйте этот код для настройки отслеживания экспериментов MLflow. В этом примере отключается автологирование. Дополнительные сведения см. в статье Автологинг в Microsoft Fabric.
# Set up MLflow for experiment tracking
import mlflow
mlflow.set_experiment(EXPERIMENT_NAME)
mlflow.autolog(disable=True) # Disable MLflow autologging
Чтение данных из хранилища данных (lakehouse)
После того как правильные данные будут размещены в lakehouse, считывайте три набора данных в отдельные кадры данных Spark в ноутбуке. Пути к файлам в этом коде используют параметры, определенные ранее.
df_items = (
spark.read.option("header", True)
.option("inferSchema", True)
.csv(f"{DATA_FOLDER}/raw/{ITEMS_FILE}")
.cache()
)
df_ratings = (
spark.read.option("header", True)
.option("inferSchema", True)
.csv(f"{DATA_FOLDER}/raw/{RATINGS_FILE}")
.cache()
)
df_users = (
spark.read.option("header", True)
.option("inferSchema", True)
.csv(f"{DATA_FOLDER}/raw/{USERS_FILE}")
.cache()
)
Шаг 2. Выполнение анализа аналитических данных
Отображение необработанных данных
Исследуйте DataFrame с помощью команды display. С помощью этой команды можно просмотреть высокоуровневую статистику dataFrame и понять, как разные столбцы набора данных связаны друг с другом. Перед изучением наборов данных используйте этот код для импорта необходимых библиотек:
import pyspark.sql.functions as F
from pyspark.ml.feature import StringIndexer
import matplotlib.pyplot as plt
import seaborn as sns
color = sns.color_palette() # Adjusting plotting style
import pandas as pd # DataFrames
Используйте этот код для просмотра кадра данных, содержащего данные книги:
display(df_items, summary=True)
Добавьте столбец _item_id для последующего использования. Значение _item_id должно быть целым числом для моделей рекомендаций. Этот код использует StringIndexer для преобразования ITEM_ID_COL в индексы:
df_items = (
StringIndexer(inputCol=ITEM_ID_COL, outputCol="_item_id")
.setHandleInvalid("skip")
.fit(df_items)
.transform(df_items)
.withColumn("_item_id", F.col("_item_id").cast("int"))
)
Отображение кадра данных и проверка того, увеличивается ли значение _item_id монотонно и последовательно, как ожидалось:
display(df_items.sort(F.col("_item_id").desc()))
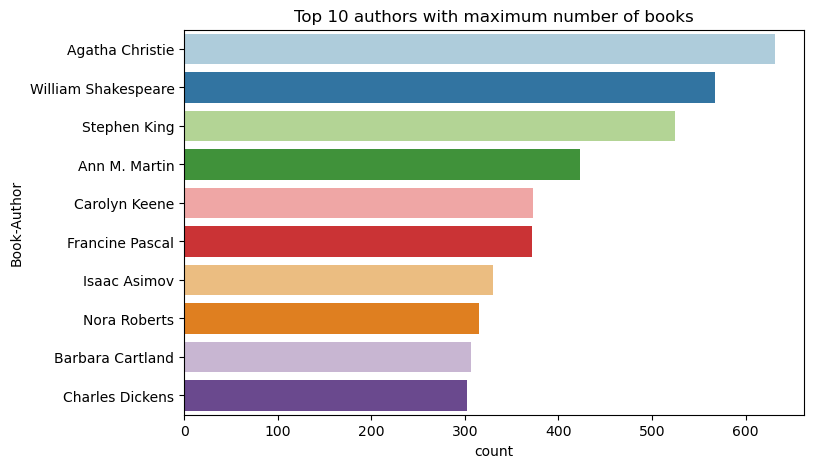
Используйте этот код для построения первых 10 авторов по количеству книг, написанных в порядке убывания. Агата Кристи является ведущим автором с более чем 600 книгами, за которым следует Уильям Шекспир.
df_books = df_items.toPandas() # Create a pandas DataFrame from the Spark DataFrame for visualization
plt.figure(figsize=(8,5))
sns.countplot(y="Book-Author",palette = 'Paired', data=df_books,order=df_books['Book-Author'].value_counts().index[0:10])
plt.title("Top 10 authors with maximum number of books")
Затем отобразите кадр данных, содержащий пользовательские данные:
display(df_users, summary=True)
Если строка имеет отсутствующее значение User-ID, удалите ее. Отсутствующие значения в настраиваемом наборе данных не вызывают проблем.
df_users = df_users.dropna(subset=(USER_ID_COL))
display(df_users, summary=True)
Добавьте столбец _user_id для последующего использования. Для моделей рекомендаций значение _user_id должно быть целым числом. В следующем примере кода используется StringIndexer для преобразования USER_ID_COL в индексы.
Набор данных книги уже имеет целочисленный столбец User-ID. Однако добавление столбца _user_id для совместимости с различными наборами данных делает этот пример более надежным. Используйте этот код для добавления столбца _user_id:
df_users = (
StringIndexer(inputCol=USER_ID_COL, outputCol="_user_id")
.setHandleInvalid("skip")
.fit(df_users)
.transform(df_users)
.withColumn("_user_id", F.col("_user_id").cast("int"))
)
display(df_users.sort(F.col("_user_id").desc()))
Используйте этот код для просмотра данных оценки:
display(df_ratings, summary=True)
Получите различные оценки и сохраните их для последующего использования в списке с именем ratings:
ratings = [i[0] for i in df_ratings.select(RATING_COL).distinct().collect()]
print(ratings)
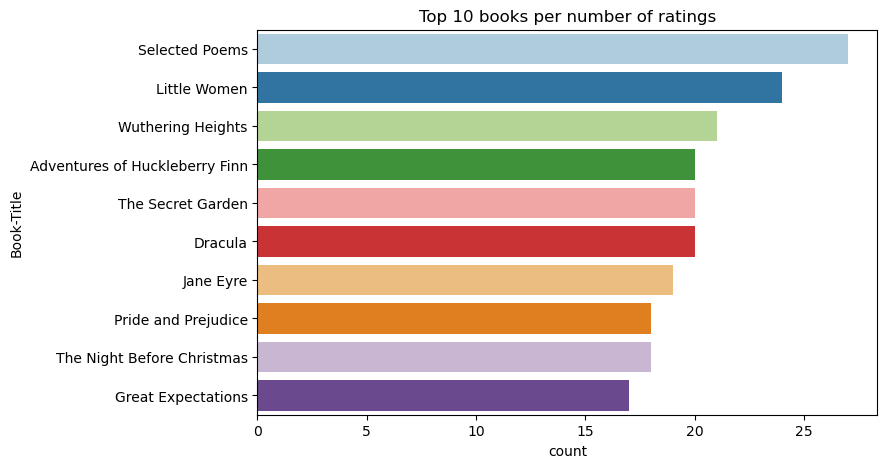
Используйте этот код для отображения лучших 10 книг с самыми высокими рейтингами:
plt.figure(figsize=(8,5))
sns.countplot(y="Book-Title",palette = 'Paired',data= df_books, order=df_books['Book-Title'].value_counts().index[0:10])
plt.title("Top 10 books per number of ratings")
По оценкам, Избранные стихотворения являются самой популярной книгой. Приключения Хаклберри Финн, Секретный сад, и Дракула имеют тот же рейтинг.
Слияние данных
Объединить три кадра данных в один кадр данных для более полного анализа:
df_all = df_ratings.join(df_users, USER_ID_COL, "inner").join(
df_items, ITEM_ID_COL, "inner"
)
df_all_columns = [
c for c in df_all.columns if c not in ["_user_id", "_item_id", RATING_COL]
]
# Reorder the columns to ensure that _user_id, _item_id, and Book-Rating are the first three columns
df_all = (
df_all.select(["_user_id", "_item_id", RATING_COL] + df_all_columns)
.withColumn("id", F.monotonically_increasing_id())
.cache()
)
display(df_all)
Используйте этот код для отображения количества отдельных пользователей, книг и взаимодействий:
print(f"Total Users: {df_users.select('_user_id').distinct().count()}")
print(f"Total Items: {df_items.select('_item_id').distinct().count()}")
print(f"Total User-Item Interactions: {df_all.count()}")
Вычисление и построение наиболее популярных элементов
Используйте этот код для вычисления и отображения лучших 10 самых популярных книг:
# Compute top popular products
df_top_items = (
df_all.groupby(["_item_id"])
.count()
.join(df_items, "_item_id", "inner")
.sort(["count"], ascending=[0])
)
# Find top <topn> popular items
topn = 10
pd_top_items = df_top_items.limit(topn).toPandas()
pd_top_items.head(10)
Совет (if the meaning is advice)
Используйте значение <topn> для популярных или наиболее покупаемых разделов рекомендаций.
# Plot top <topn> items
f, ax = plt.subplots(figsize=(10, 5))
plt.xticks(rotation="vertical")
sns.barplot(y=ITEM_INFO_COL, x="count", data=pd_top_items)
ax.tick_params(axis='x', rotation=45)
plt.xlabel("Number of Ratings for the Item")
plt.show()

Подготовка обучающих и тестовых наборов данных
Матрица ALS требует некоторой подготовки данных перед обучением. Используйте этот пример кода для подготовки данных. Код выполняет следующие действия:
- Приведение столбца рейтинга к правильному типу
- Пример обучающих данных с оценками пользователей
- Разделение данных на обучающие и тестовые наборы данных
if IS_SAMPLE:
# Must sort by '_user_id' before performing limit to ensure that ALS works normally
# If training and test datasets have no common _user_id, ALS will fail
df_all = df_all.sort("_user_id").limit(SAMPLE_ROWS)
# Cast the column into the correct type
df_all = df_all.withColumn(RATING_COL, F.col(RATING_COL).cast("float"))
# Using a fraction between 0 and 1 returns the approximate size of the dataset; for example, 0.8 means 80% of the dataset
# Rating = 0 means the user didn't rate the item, so it can't be used for training
# We use the 80% of the dataset with rating > 0 as the training dataset
fractions_train = {0: 0}
fractions_test = {0: 0}
for i in ratings:
if i == 0:
continue
fractions_train[i] = 0.8
fractions_test[i] = 1
# Training dataset
train = df_all.sampleBy(RATING_COL, fractions=fractions_train)
# Join with leftanti will select all rows from df_all with rating > 0 and not in the training dataset; for example, the remaining 20% of the dataset
# test dataset
test = df_all.join(train, on="id", how="leftanti").sampleBy(
RATING_COL, fractions=fractions_test
)
Разреженность относится к разреженным данным обратной связи, которые не могут идентифицировать сходство в интересах пользователей. Для лучшего понимания данных и текущей проблемы используйте этот код для вычисления разреженности набора данных:
# Compute the sparsity of the dataset
def get_mat_sparsity(ratings):
# Count the total number of ratings in the dataset - used as numerator
count_nonzero = ratings.select(RATING_COL).count()
print(f"Number of rows: {count_nonzero}")
# Count the total number of distinct user_id and distinct product_id - used as denominator
total_elements = (
ratings.select("_user_id").distinct().count()
* ratings.select("_item_id").distinct().count()
)
# Calculate the sparsity by dividing the numerator by the denominator
sparsity = (1.0 - (count_nonzero * 1.0) / total_elements) * 100
print("The ratings DataFrame is ", "%.4f" % sparsity + "% sparse.")
get_mat_sparsity(df_all)
# Check the ID range
# ALS supports only values in the integer range
print(f"max user_id: {df_all.agg({'_user_id': 'max'}).collect()[0][0]}")
print(f"max user_id: {df_all.agg({'_item_id': 'max'}).collect()[0][0]}")
Шаг 3. Разработка и обучение модели
Обучите модель ALS, чтобы предоставить пользователям персонализированные рекомендации.
Определение модели
Машинное обучение Spark предоставляет удобный API для создания модели ALS. Однако модель не надёжно обрабатывает такие проблемы, как разреженность данных и холодный старт, делая рекомендации для новых пользователей или элементов. Чтобы повысить производительность модели, объедините перекрестную проверку и автоматическую настройку гиперпараметра.
Используйте этот код для импорта библиотек, необходимых для обучения и оценки моделей:
# Import Spark required libraries
from pyspark.ml.evaluation import RegressionEvaluator
from pyspark.ml.recommendation import ALS
from pyspark.ml.tuning import ParamGridBuilder, CrossValidator, TrainValidationSplit
# Specify the training parameters
num_epochs = 1 # Number of epochs; here we use 1 to reduce the training time
rank_size_list = [64] # The values of rank in ALS for tuning
reg_param_list = [0.01, 0.1] # The values of regParam in ALS for tuning
model_tuning_method = "TrainValidationSplit" # TrainValidationSplit or CrossValidator
# Build the recommendation model by using ALS on the training data
# We set the cold start strategy to 'drop' to ensure that we don't get NaN evaluation metrics
als = ALS(
maxIter=num_epochs,
userCol="_user_id",
itemCol="_item_id",
ratingCol=RATING_COL,
coldStartStrategy="drop",
implicitPrefs=False,
nonnegative=True,
)
Настройка гиперпараметров модели
Следующий пример кода создает сетку параметров для поиска по гиперпараметрам. Код также создает средство оценки регрессии, использующее в качестве метрики оценки ошибку корневого среднего квадрата (RMSE):
# Construct a grid search to select the best values for the training parameters
param_grid = (
ParamGridBuilder()
.addGrid(als.rank, rank_size_list)
.addGrid(als.regParam, reg_param_list)
.build()
)
print("Number of models to be tested: ", len(param_grid))
# Define the evaluator and set the loss function to the RMSE
evaluator = RegressionEvaluator(
metricName="rmse", labelCol=RATING_COL, predictionCol="prediction"
)
Следующий пример кода инициирует различные методы настройки модели на основе предварительно настроенных параметров. Дополнительные сведения о настройке модели см. в разделе Настройка машинного обучения: выбор модели и настройка гиперпараметров на веб-сайте Apache Spark.
# Build cross-validation by using CrossValidator and TrainValidationSplit
if model_tuning_method == "CrossValidator":
tuner = CrossValidator(
estimator=als,
estimatorParamMaps=param_grid,
evaluator=evaluator,
numFolds=5,
collectSubModels=True,
)
elif model_tuning_method == "TrainValidationSplit":
tuner = TrainValidationSplit(
estimator=als,
estimatorParamMaps=param_grid,
evaluator=evaluator,
# 80% of the training data will be used for training; 20% for validation
trainRatio=0.8,
collectSubModels=True,
)
else:
raise ValueError(f"Unknown model_tuning_method: {model_tuning_method}")
Оценка модели
Вы должны оценивать модули с использованием тестовых данных. Хорошо обученная модель должна иметь высокие метрики в наборе данных.
Переобученной модели может потребоваться увеличение размера обучающих данных или сокращение некоторых избыточных признаков. Может потребоваться изменить архитектуру модели, или ее параметры могут потребовать точной настройки.
Заметка
Отрицательное значение метрики с квадратом R указывает на то, что обученная модель работает хуже горизонтальной прямой линии. В этом случае предполагается, что обученная модель не объясняет данные.
Чтобы определить функцию оценки, используйте следующий код:
def evaluate(model, data, verbose=0):
"""
Evaluate the model by computing rmse, mae, r2, and variance over the data.
"""
predictions = model.transform(data).withColumn(
"prediction", F.col("prediction").cast("double")
)
if verbose > 1:
# Show 10 predictions
predictions.select("_user_id", "_item_id", RATING_COL, "prediction").limit(
10
).show()
# Initialize the regression evaluator
evaluator = RegressionEvaluator(predictionCol="prediction", labelCol=RATING_COL)
_evaluator = lambda metric: evaluator.setMetricName(metric).evaluate(predictions)
rmse = _evaluator("rmse")
mae = _evaluator("mae")
r2 = _evaluator("r2")
var = _evaluator("var")
if verbose > 0:
print(f"RMSE score = {rmse}")
print(f"MAE score = {mae}")
print(f"R2 score = {r2}")
print(f"Explained variance = {var}")
return predictions, (rmse, mae, r2, var)
Отслеживание эксперимента с помощью MLflow
Используйте MLflow для отслеживания всех экспериментов и журналов параметров, метрик и моделей. Чтобы начать обучение и оценку модели, используйте следующий код:
from mlflow.models.signature import infer_signature
with mlflow.start_run(run_name="als"):
# Train models
models = tuner.fit(train)
best_metrics = {"RMSE": 10e6, "MAE": 10e6, "R2": 0, "Explained variance": 0}
best_index = 0
# Evaluate models
# Log models, metrics, and parameters
for idx, model in enumerate(models.subModels):
with mlflow.start_run(nested=True, run_name=f"als_{idx}") as run:
print("\nEvaluating on test data:")
print(f"subModel No. {idx + 1}")
predictions, (rmse, mae, r2, var) = evaluate(model, test, verbose=1)
signature = infer_signature(
train.select(["_user_id", "_item_id"]),
predictions.select(["_user_id", "_item_id", "prediction"]),
)
print("log model:")
mlflow.spark.log_model(
model,
f"{EXPERIMENT_NAME}-alsmodel",
signature=signature,
registered_model_name=f"{EXPERIMENT_NAME}-alsmodel",
dfs_tmpdir="Files/spark",
)
print("log metrics:")
current_metric = {
"RMSE": rmse,
"MAE": mae,
"R2": r2,
"Explained variance": var,
}
mlflow.log_metrics(current_metric)
if rmse < best_metrics["RMSE"]:
best_metrics = current_metric
best_index = idx
print("log parameters:")
mlflow.log_params(
{
"subModel_idx": idx,
"num_epochs": num_epochs,
"rank_size_list": rank_size_list,
"reg_param_list": reg_param_list,
"model_tuning_method": model_tuning_method,
"DATA_FOLDER": DATA_FOLDER,
}
)
# Log the best model and related metrics and parameters to the parent run
mlflow.spark.log_model(
models.subModels[best_index],
f"{EXPERIMENT_NAME}-alsmodel",
signature=signature,
registered_model_name=f"{EXPERIMENT_NAME}-alsmodel",
dfs_tmpdir="Files/spark",
)
mlflow.log_metrics(best_metrics)
mlflow.log_params(
{
"subModel_idx": idx,
"num_epochs": num_epochs,
"rank_size_list": rank_size_list,
"reg_param_list": reg_param_list,
"model_tuning_method": model_tuning_method,
"DATA_FOLDER": DATA_FOLDER,
}
)
Выберите эксперимент с именем aisample-recommendation из вашей рабочей области, чтобы просмотреть зарегистрированные сведения выполненного обучения. Если вы изменили имя эксперимента, выберите эксперимент с новым именем. Записанные в журнал сведения похожи на это изображение:

Шаг 4. Загрузка окончательной модели для оценки и прогнозирования
После завершения обучения модели выберите лучшую модель и загрузите её для оценки (иногда это называется выводом). Этот код загружает модель и использует прогнозы, чтобы рекомендовать первые 10 книг для каждого пользователя:
# Load the best model
# MLflow uses PipelineModel to wrap the original model, so we extract the original ALSModel from the stages
model_uri = f"models:/{EXPERIMENT_NAME}-alsmodel/1"
loaded_model = mlflow.spark.load_model(model_uri, dfs_tmpdir="Files/spark").stages[-1]
# Generate top 10 book recommendations for each user
userRecs = loaded_model.recommendForAllUsers(10)
# Represent the recommendations in an interpretable format
userRecs = (
userRecs.withColumn("rec_exp", F.explode("recommendations"))
.select("_user_id", F.col("rec_exp._item_id"), F.col("rec_exp.rating"))
.join(df_items.select(["_item_id", "Book-Title"]), on="_item_id")
)
userRecs.limit(10).show()
Выходные данные похожи на эту таблицу:
| _идентификатор_элемента | _user_id | рейтинг | Book-Title |
|---|---|---|---|
| 44865 | 7 | 7.9996786 | Ласер: Жизнь ... |
| 786 | 7 | 6.2255826 | Пианист D... |
| 45330 | 7 | 4.980466 | Состояние ума |
| 38960 | 7 | 4.980466 | Все, что он когда-либо хотел |
| 125415 | 7 | 4.505084 | Гарри Поттер и ... |
| 44939 | 7 | 4.3579073 | Taltos: Жизнь ... |
| 175247 | 7 | 4.3579073 | Коститтер ... |
| 170183 | 7 | 4.228735 | Жить простой... |
| 88503 | 7 | 4.221206 | Остров Блу... |
| 32894 | 7 | 3.9031885 | Зимнее солнцестояние |
Сохранение прогнозов в лейкхаусе
Используйте этот код для записи рекомендаций обратно в lakehouse:
# Code to save userRecs into the lakehouse
userRecs.write.format("delta").mode("overwrite").save(
f"{DATA_FOLDER}/predictions/userRecs"
)
Связанное содержимое
- Обучение и оценка модели классификации текста
- модель машинного обучения в Microsoft Fabric
- Обучение моделей машинного обучения
- эксперименты машинного обучения в Microsoft Fabric