Использование Tidyverse
Tidyverse — это коллекция пакетов R, которые специалисты по обработке и анализу данных обычно используют в повседневном анализе данных. Он включает пакеты для импорта данных (), визуализации данных (readr), обработки данных (ggplot2dplyr, tidyrфункционального программированияpurrr) и сборки моделей (tidymodels) и т. д. tidyverse Пакеты предназначены для эффективной работы и выполнения согласованного набора принципов проектирования.
Microsoft Fabric распространяет последнюю стабильную версию tidyverse каждого выпуска среды выполнения. Импортируйте и начните использовать знакомые пакеты R.
Необходимые компоненты
Получение подписки Microsoft Fabric. Или зарегистрируйте бесплатную пробную версию Microsoft Fabric.
Войдите в Microsoft Fabric.
Используйте переключатель интерфейса в левой нижней части домашней страницы, чтобы перейти на Fabric.

Откройте или создайте записную книжку. Узнайте, как использовать записные книжки Microsoft Fabric.
Задайте для параметра языка значение SparkR (R), чтобы изменить основной язык.
Подключите записную книжку к lakehouse. В левой части нажмите кнопку "Добавить ", чтобы добавить существующее озеро или создать озеро.
Груз tidyverse
# load tidyverse
library(tidyverse)
Импорт данных
readr — это пакет R, предоставляющий средства для чтения прямоугольных файлов данных, таких как CSV, TSV и файлы фиксированной ширины.
readr обеспечивает быстрый и понятный способ чтения прямоугольных файлов данных, таких как предоставление функций read_csv() и read_tsv() чтение CSV-файлов и TSV соответственно.
Сначала создадим R data.frame, напишите его в lakehouse с помощью readr::write_csv() и считываем его обратно readr::read_csv().
Примечание.
Чтобы получить доступ к файлам Lakehouse с помощью readr, необходимо использовать путь к API файлов. В обозревателе Lakehouse щелкните правой кнопкой мыши файл или папку, к которой требуется получить доступ, и скопируйте путь к API файла из контекстного меню.
# create an R data frame
set.seed(1)
stocks <- data.frame(
time = as.Date('2009-01-01') + 0:9,
X = rnorm(10, 20, 1),
Y = rnorm(10, 20, 2),
Z = rnorm(10, 20, 4)
)
stocks
Затем давайте напишем данные в Lakehouse с помощью пути к API файлов.
# write data to lakehouse using the File API path
temp_csv_api <- "/lakehouse/default/Files/stocks.csv"
readr::write_csv(stocks,temp_csv_api)
Чтение данных из Lakehouse.
# read data from lakehouse using the File API path
stocks_readr <- readr::read_csv(temp_csv_api)
# show the content of the R date.frame
head(stocks_readr)
Очистка данных
tidyr — это пакет R, предоставляющий средства для работы с грязными данными. Основные функции tidyr предназначены для переформатирования данных в приливный формат. Данные Tidy имеют определенную структуру, в которой каждая переменная является столбцом, и каждое наблюдение является строкой, что упрощает работу с данными в R и других средствах.
Например, функцию gather() можно tidyr использовать для преобразования широких данных в длинные данные. Приведем пример:
# convert the stock data into longer data
library(tidyr)
stocksL <- gather(data = stocks, key = stock, value = price, X, Y, Z)
stocksL
Функциональное программирование
purrr — это пакет R, который улучшает функциональный набор средств программирования R, предоставляя полный и согласованный набор средств для работы с функциями и векторами. Лучше всего начать purrr с семейства map() функций, которые позволяют заменить многие циклы на код, который является более кратким и простым для чтения. Ниже приведен пример использования map() для применения функции к каждому элементу списка:
# double the stock values using purrr
library(purrr)
stocks_double = map(stocks %>% select_if(is.numeric), ~.x*2)
stocks_double
Обработка данных
dplyr — это пакет R, который предоставляет согласованный набор команд, которые помогают решить наиболее распространенные проблемы обработки данных, такие как выбор переменных на основе имен, выбор вариантов на основе значений, сокращение нескольких значений до одной сводки и изменение порядка строк и т. д. Ниже приведены некоторые примеры.
# pick variables based on their names using select()
stocks_value <- stocks %>% select(X:Z)
stocks_value
# pick cases based on their values using filter()
filter(stocks_value, X >20)
# add new variables that are functions of existing variables using mutate()
library(lubridate)
stocks_wday <- stocks %>%
select(time:Z) %>%
mutate(
weekday = wday(time)
)
stocks_wday
# change the ordering of the rows using arrange()
arrange(stocks_wday, weekday)
# reduce multiple values down to a single summary using summarise()
stocks_wday %>%
group_by(weekday) %>%
summarize(meanX = mean(X), n= n())
Визуализация данных
ggplot2 — это пакет R для декларативного создания графики на основе грамматики графики. Вы предоставляете данные, расскажите ggplot2 , как сопоставить переменные с эстетикой, какие графические примитивы следует использовать, и он заботится о деталях. Далее приводятся некоторые примеры.
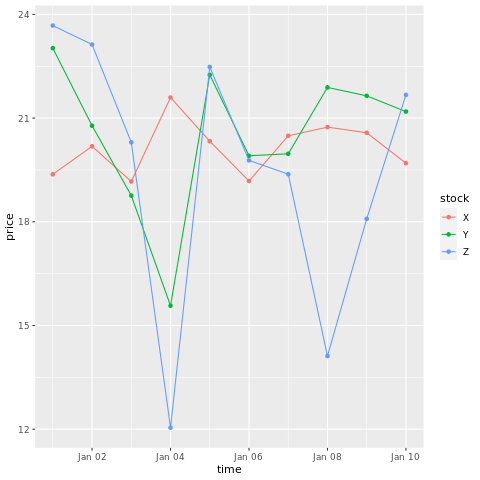
# draw a chart with points and lines all in one
ggplot(stocksL, aes(x=time, y=price, colour = stock)) +
geom_point()+
geom_line()
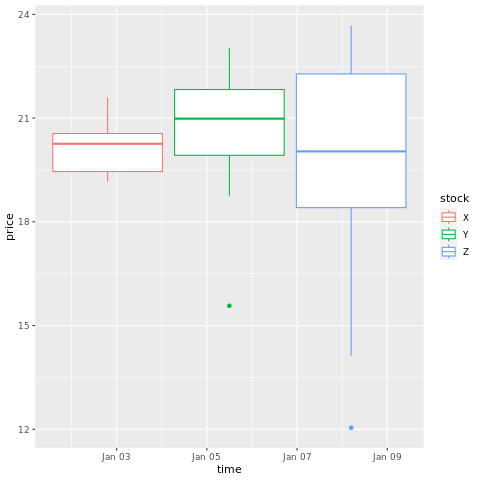
# draw a boxplot
ggplot(stocksL, aes(x=time, y=price, colour = stock)) +
geom_boxplot()
Построение модели
Платформа tidymodels — это коллекция пакетов для моделирования и машинного обучения с помощью tidyverse принципов. Он охватывает список основных пакетов для широкого спектра задач построения модели, таких как rsample разделение выборки набора данных для обучения и тестирования, parsnip для предварительной recipes обработки workflows данных, для обработки рабочих процессов tune моделирования, для настройки yardstick гиперпараметров, для оценки модели, broom для вывода выходных данных модели и dials управления параметрами настройки. Дополнительные сведения о пакетах можно узнать, перейдя на веб-сайт tidymodels. Ниже приведен пример построения линейной регрессионной модели для прогнозирования миль на галлон (mpg) автомобиля на основе его веса (wt):
# look at the relationship between the miles per gallon (mpg) of a car and its weight (wt)
ggplot(mtcars, aes(wt,mpg))+
geom_point()
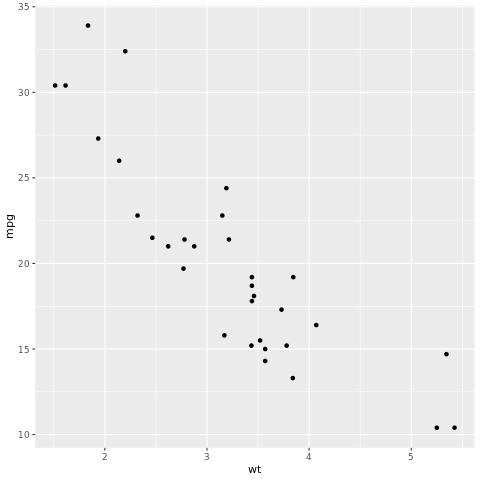
Из точечной диаграммы связь выглядит примерно линейно, а дисперсия выглядит константой. Давайте попробуем моделировать это с помощью линейной регрессии.
library(tidymodels)
# split test and training dataset
set.seed(123)
split <- initial_split(mtcars, prop = 0.7, strata = "cyl")
train <- training(split)
test <- testing(split)
# config the linear regression model
lm_spec <- linear_reg() %>%
set_engine("lm") %>%
set_mode("regression")
# build the model
lm_fit <- lm_spec %>%
fit(mpg ~ wt, data = train)
tidy(lm_fit)
Примените модель линейной регрессии для прогнозирования в тестовом наборе данных.
# using the lm model to predict on test dataset
predictions <- predict(lm_fit, test)
predictions
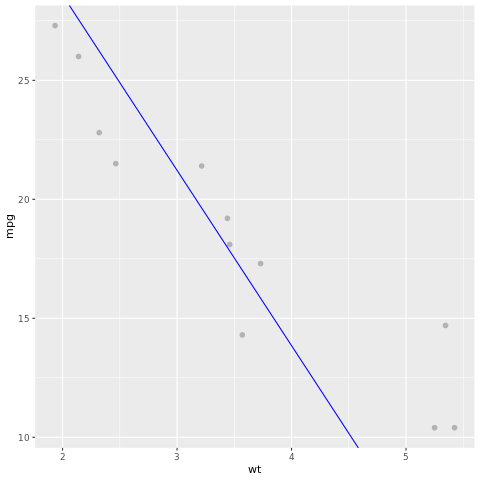
Рассмотрим результат модели. Мы можем нарисовать модель в виде графики и данные о проверке истины в виде точек на той же диаграмме. Модель выглядит хорошо.
# draw the model as a line chart and the test data groundtruth as points
lm_aug <- augment(lm_fit, test)
ggplot(lm_aug, aes(x = wt, y = mpg)) +
geom_point(size=2,color="grey70") +
geom_abline(intercept = lm_fit$fit$coefficients[1], slope = lm_fit$fit$coefficients[2], color = "blue")