Руководство: Создание, анализ и оценка модели прогнозирования оттока клиентов
В этом руководстве представлен полный пример рабочего процесса Обработки и анализа данных Synapse в Microsoft Fabric. Сценарий создает модель для прогнозирования того, произойдет ли отток клиентов банка. Ставка оттока или ставка утери включает в себя ставку, с которой клиенты банка заканчивают свой бизнес с банком.
В этом руководстве рассматриваются следующие действия.
- Установка пользовательских библиотек
- Загрузка данных
- Понимать и обрабатывать данные с помощью эксплоративного анализа данных и демонстрировать использование функции Fabric Data Wrangler
- Использование scikit-learn и LightGBM для обучения моделей машинного обучения и отслеживания экспериментов с функциями автологирования MLflow и Fabric
- Оценка и сохранение конечной модели машинного обучения
- Отображение производительности модели с помощью визуализаций Power BI
Необходимые условия
Получите подписку Microsoft Fabric. Или зарегистрируйте бесплатную пробную Microsoft Fabric.
Войдите в Microsoft Fabric.
Используйте переключатель интерфейса в левой нижней части домашней страницы, чтобы перейти на Fabric.

- При необходимости создайте лейкхаус в Microsoft Fabric, как описано в разделе Создание лейкхауса.
Следуйте инструкциям в записной книжке
Вы можете выбрать один из следующих вариантов для выполнения в записной книжке:
- Откройте и запустите встроенную записную книжку.
- Отправьте записную книжку из GitHub.
Открытие встроенной записной книжки
Примерный блокнот по оттоку клиентов сопровождает это руководство.
Чтобы открыть пример записной книжки для этого руководства, следуйте инструкциям в Подготовка системы для учебников по науке о данных.
Перед началом выполнения кода обязательно подключите lakehouse к блокноту.
Импорт записной книжки из GitHub
AIsample — Bank Customer Churn.ipynb записная книжка сопровождается этим руководством.
Чтобы открыть сопровождающую записную книжку для этого руководства, следуйте инструкциям в Подготовка вашей системы для учебных пособий по науке о данных, чтобы импортировать записную книжку в ваше рабочее пространство.
Если вы хотите скопировать и вставить код на этой странице, можно создать новую записную книжку.
Не забудьте подключить lakehouse к ноутбуку перед началом выполнения кода.
Шаг 1. Установка пользовательских библиотек
Для разработки моделей машинного обучения или нерегламентированного анализа данных может потребоваться быстро установить пользовательскую библиотеку для сеанса Apache Spark. Существует два варианта установки библиотек.
- Используйте встроенные функции установки (
%pipили%conda) вашей записной книжки для установки библиотеки только в текущей записной книжке. - Кроме того, можно создать среду Fabric, установить библиотеки из общедоступных источников или отправить в нее пользовательские библиотеки, а затем администратор рабочей области может присоединить среду в качестве значения по умолчанию для рабочей области. Все библиотеки в среде будут доступны для использования в любых записных книжках и определениях заданий Spark в рабочей области. Дополнительные сведения о средах см. в создании, настройке и использовании среды в Microsoft Fabric.
В этом руководстве используйте %pip install для установки библиотеки imblearn в ноутбуке.
Заметка
Ядро PySpark перезапускается после %pip install запусков. Установите необходимые библиотеки перед запуском любых других ячеек.
# Use pip to install libraries
%pip install imblearn
Шаг 2. Загрузка данных
Набор данных в churn.csv содержит состояние оттока 10 000 клиентов, а также 14 атрибутов, которые включают:
- Кредитная оценка
- Географическое расположение (Германия, Франция, Испания)
- Пол (мужчина, женщина)
- Возраст
- Срок пребывания (количество лет, когда человек был клиентом в этом банке)
- Баланс счета
- Оценочная зарплата
- Количество продуктов, приобретенных клиентом через банк
- Состояние кредитной карты (независимо от того, имеет ли клиент кредитную карту)
- Статус активного участника (независимо от того, является ли пользователь активным клиентом банка)
Набор данных также содержит столбцы номера строки, идентификаторов клиентов и фамилии клиента. Значения в этих столбцах не должны влиять на решение клиента о выходе из банка.
Событие закрытия банковского счета клиента определяет отток для этого клиента. Столбец набора данных Exited относится к отказу клиента. Так как у нас мало контекста этих атрибутов, нам не нужны фоновые сведения о наборе данных. Мы хотим понять, как эти атрибуты способствуют состоянию Exited.
Из этих 10 000 клиентов, только 2037 клиентов (примерно 20%) покинули банк. В связи с дисбалансом классов мы рекомендуем создание синтетических данных. Точность матрицы путаницы может не иметь релевантности для несбалансированной классификации. Возможно, мы хотим измерить точность с помощью области под кривой Precision-Recall (AUPRC).
- В этой таблице показана предварительная версия данных
churn.csv:
| Идентификатор клиента | Фамилия | кредитный рейтинг | География | Пол | Возраст | Владение | Равновесие | NumOfProducts | HasCrCard | АктивныйЧлен | Оценочная зарплата | Вышла |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 15634602 | Харграв | 619 | Франция | Женский | 42 | 2 | 0.00 | 1 | 1 | 1 | 101348.88 | 1 |
| 15647311 | Холм | 608 | Испания | Женский | 41 | 1 | 83807.86 | 1 | 0 | 1 | 112542.58 | 0 |
Скачайте набор данных и отправьте его в lakehouse
Определите эти параметры, чтобы использовать эту записную книжку с различными наборами данных:
IS_CUSTOM_DATA = False # If TRUE, the dataset has to be uploaded manually
IS_SAMPLE = False # If TRUE, use only SAMPLE_ROWS of data for training; otherwise, use all data
SAMPLE_ROWS = 5000 # If IS_SAMPLE is True, use only this number of rows for training
DATA_ROOT = "/lakehouse/default"
DATA_FOLDER = "Files/churn" # Folder with data files
DATA_FILE = "churn.csv" # Data file name
Этот код загружает общедоступную версию набора данных, а затем сохраняет его в Fabric Lakehouse.
Важный
Добавить lakehouse в записную книжку перед запуском. Сбой этого приведет к ошибке.
import os, requests
if not IS_CUSTOM_DATA:
# With an Azure Synapse Analytics blob, this can be done in one line
# Download demo data files into the lakehouse if they don't exist
remote_url = "https://synapseaisolutionsa.blob.core.windows.net/public/bankcustomerchurn"
file_list = ["churn.csv"]
download_path = "/lakehouse/default/Files/churn/raw"
if not os.path.exists("/lakehouse/default"):
raise FileNotFoundError(
"Default lakehouse not found, please add a lakehouse and restart the session."
)
os.makedirs(download_path, exist_ok=True)
for fname in file_list:
if not os.path.exists(f"{download_path}/{fname}"):
r = requests.get(f"{remote_url}/{fname}", timeout=30)
with open(f"{download_path}/{fname}", "wb") as f:
f.write(r.content)
print("Downloaded demo data files into lakehouse.")
Начните запись времени, необходимого для запуска записной книжки:
# Record the notebook running time
import time
ts = time.time()
Читать необработанные данные из лейкхауса
Этот код считывает необработанные данные из раздела файлов на lakehouse и добавляет дополнительные столбцы для различных частей даты. Создание секционированных разностных таблиц использует эту информацию.
df = (
spark.read.option("header", True)
.option("inferSchema", True)
.csv("Files/churn/raw/churn.csv")
.cache()
)
Создайте кадр данных pandas из набора данных
Этот код преобразует кадр данных Spark в кадр данных pandas для упрощения обработки и визуализации:
df = df.toPandas()
Шаг 3. Выполнение анализа аналитических данных
Отображение необработанных данных
Изучите необработанные данные с помощью display, вычислите базовые статистики и покажите диаграммы. Сначала необходимо импортировать необходимые библиотеки для визуализации данных, например морских. Seaborn — это библиотека визуализации данных Python, которая предоставляет высокоуровневый интерфейс для создания визуальных элементов на кадрах и массивах данных.
import seaborn as sns
sns.set_theme(style="whitegrid", palette="tab10", rc = {'figure.figsize':(9,6)})
import matplotlib.pyplot as plt
import matplotlib.ticker as mticker
from matplotlib import rc, rcParams
import numpy as np
import pandas as pd
import itertools
display(df, summary=True)
Используйте Data Wrangler для выполнения начальной очистки данных.
Запустите Data Wrangler непосредственно из блокнота, чтобы изучать и преобразовывать DataFrame Pandas. Выберите раскрывающееся меню Data Wrangler на горизонтальной панели инструментов, чтобы просмотреть активированные DataFrame pandas, доступные для редактирования. Выберите кадр данных, который вы хотите открыть в Data Wrangler.
Заметка
Невозможно открыть Data Wrangler, пока ядро записной книжки занято. Выполнение ячейки должно завершиться перед запуском Data Wrangler. Дополнительные сведения о Data Wrangler.

После запуска Data Wrangler создается описательный обзор панели данных, как показано на следующих изображениях. Обзор включает информацию о размерах DataFrame, наличии отсутствующих значений и т. д. Вы можете использовать Data Wrangler для создания скрипта для удаления строк с пропущенными значениями, повторяющихся строк и столбцов с определёнными именами. Затем можно скопировать скрипт в ячейку. В следующей ячейке показан скопированный скрипт.


def clean_data(df):
# Drop rows with missing data across all columns
df.dropna(inplace=True)
# Drop duplicate rows in columns: 'RowNumber', 'CustomerId'
df.drop_duplicates(subset=['RowNumber', 'CustomerId'], inplace=True)
# Drop columns: 'RowNumber', 'CustomerId', 'Surname'
df.drop(columns=['RowNumber', 'CustomerId', 'Surname'], inplace=True)
return df
df_clean = clean_data(df.copy())
Определение атрибутов
Этот код определяет категориальные, числовые и целевые атрибуты:
# Determine the dependent (target) attribute
dependent_variable_name = "Exited"
print(dependent_variable_name)
# Determine the categorical attributes
categorical_variables = [col for col in df_clean.columns if col in "O"
or df_clean[col].nunique() <=5
and col not in "Exited"]
print(categorical_variables)
# Determine the numerical attributes
numeric_variables = [col for col in df_clean.columns if df_clean[col].dtype != "object"
and df_clean[col].nunique() >5]
print(numeric_variables)
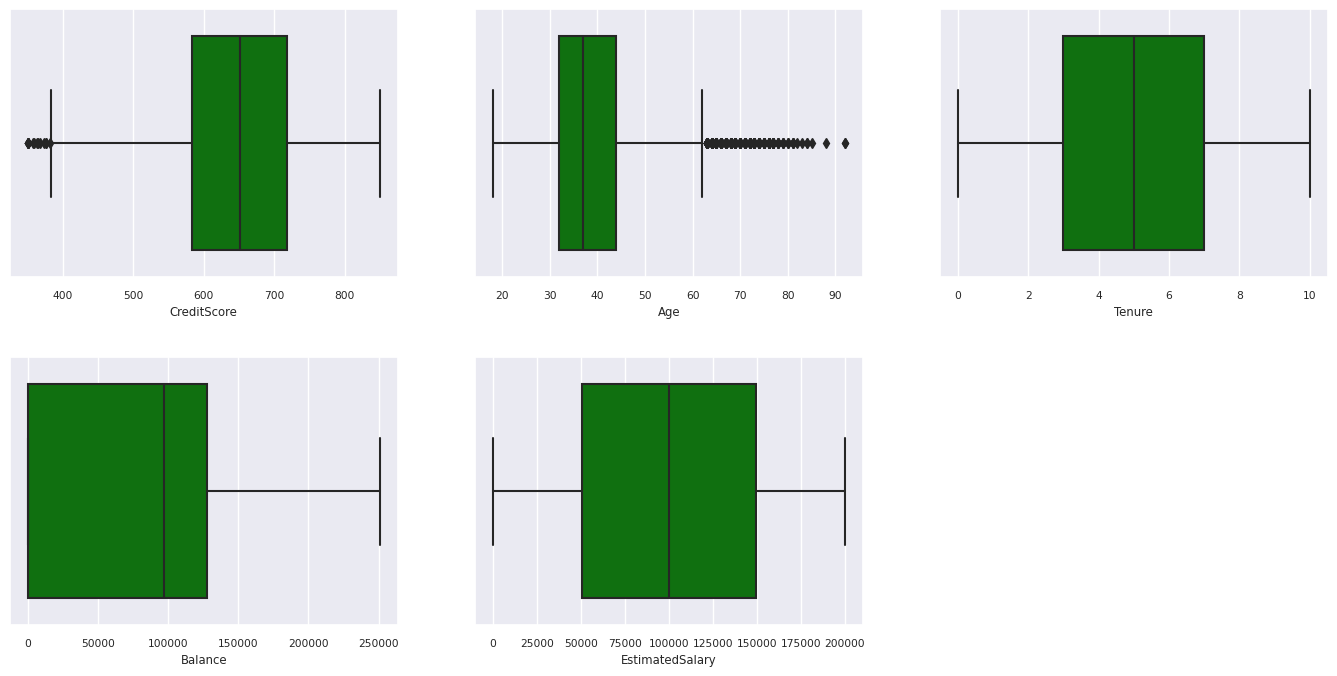
Показать сводку пяти чисел
Отображение сводки с пятью числами с помощью полей
- минимальная оценка
- первый квартиль
- медиана
- третий квартиль
- максимальная оценка
для числовых атрибутов.
df_num_cols = df_clean[numeric_variables]
sns.set(font_scale = 0.7)
fig, axes = plt.subplots(nrows = 2, ncols = 3, gridspec_kw = dict(hspace=0.3), figsize = (17,8))
fig.tight_layout()
for ax,col in zip(axes.flatten(), df_num_cols.columns):
sns.boxplot(x = df_num_cols[col], color='green', ax = ax)
# fig.suptitle('visualize and compare the distribution and central tendency of numerical attributes', color = 'k', fontsize = 12)
fig.delaxes(axes[1,2])
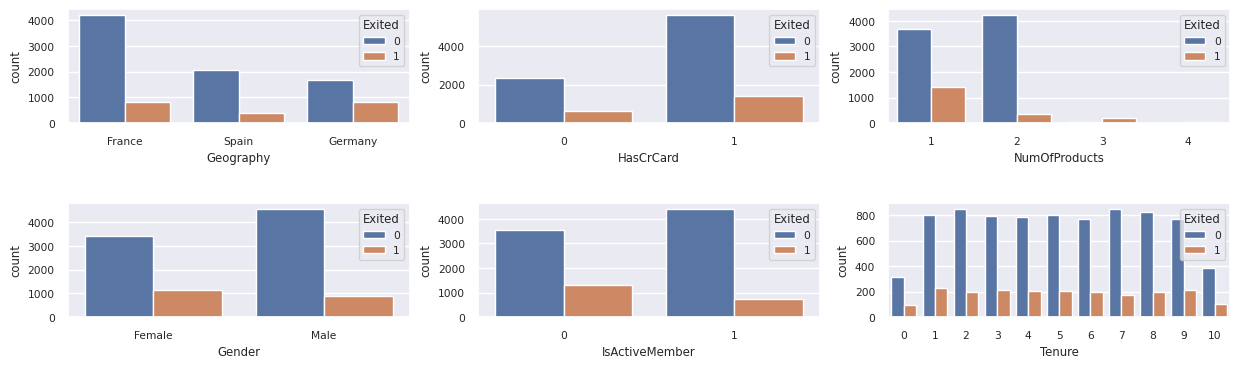
Отобразите распределение ушедших и не ушедших клиентов
Показать распределение ушедших и неушедших клиентов по категориям атрибутам.
attr_list = ['Geography', 'Gender', 'HasCrCard', 'IsActiveMember', 'NumOfProducts', 'Tenure']
fig, axarr = plt.subplots(2, 3, figsize=(15, 4))
for ind, item in enumerate (attr_list):
sns.countplot(x = item, hue = 'Exited', data = df_clean, ax = axarr[ind%2][ind//2])
fig.subplots_adjust(hspace=0.7)
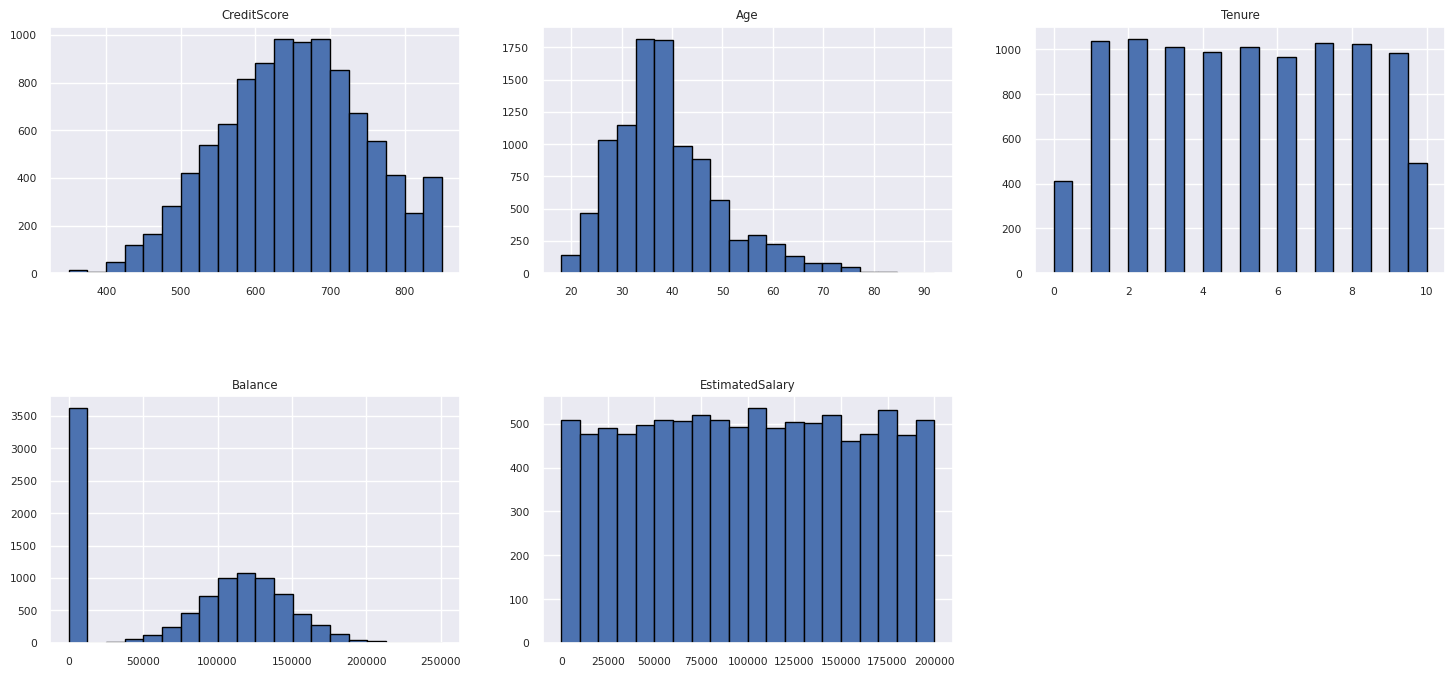
Отображение распределения числовых атрибутов
Используйте гистограмму для отображения распределения частот числовых атрибутов:
columns = df_num_cols.columns[: len(df_num_cols.columns)]
fig = plt.figure()
fig.set_size_inches(18, 8)
length = len(columns)
for i,j in itertools.zip_longest(columns, range(length)):
plt.subplot((length // 2), 3, j+1)
plt.subplots_adjust(wspace = 0.2, hspace = 0.5)
df_num_cols[i].hist(bins = 20, edgecolor = 'black')
plt.title(i)
# fig = fig.suptitle('distribution of numerical attributes', color = 'r' ,fontsize = 14)
plt.show()
Выполнение проектирования компонентов
Эта инженерия функций создает новые атрибуты на основе текущих атрибутов:
df_clean["NewTenure"] = df_clean["Tenure"]/df_clean["Age"]
df_clean["NewCreditsScore"] = pd.qcut(df_clean['CreditScore'], 6, labels = [1, 2, 3, 4, 5, 6])
df_clean["NewAgeScore"] = pd.qcut(df_clean['Age'], 8, labels = [1, 2, 3, 4, 5, 6, 7, 8])
df_clean["NewBalanceScore"] = pd.qcut(df_clean['Balance'].rank(method="first"), 5, labels = [1, 2, 3, 4, 5])
df_clean["NewEstSalaryScore"] = pd.qcut(df_clean['EstimatedSalary'], 10, labels = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10])
Используйте Data Wrangler для выполнения one-hot кодирования
Следуя тем же шагам, которые были описаны ранее для запуска Data Wrangler, используйте Data Wrangler для выполнения однократного кодирования. В этой ячейке отображается скопированный и созданный скрипт для one-hot кодирования.


df_clean = pd.get_dummies(df_clean, columns=['Geography', 'Gender'])
Создание разностной таблицы для создания отчета Power BI
table_name = "df_clean"
# Create a PySpark DataFrame from pandas
sparkDF=spark.createDataFrame(df_clean)
sparkDF.write.mode("overwrite").format("delta").save(f"Tables/{table_name}")
print(f"Spark DataFrame saved to delta table: {table_name}")
Сводка наблюдений по исследовательскому анализу данных
- Большинство клиентов из Франции. Испания имеет самый низкий показатель оттока, по сравнению с Францией и Германией.
- Большинство клиентов имеют кредитные карты
- Некоторые клиенты старше 60 лет и имеют кредитные оценки ниже 400. Тем не менее, они не могут рассматриваться как выбросы
- Очень немногие клиенты имеют более двух банковских продуктов
- Неактивные клиенты имеют более высокую скорость оттока
- Пол и срок пребывания в должности не влияют на решение клиента закрыть банковский счет
Шаг 4. Проведение обучения моделей и их отслеживание.
Теперь можно определить модель с помощью данных. Примените модели случайных лесов и LightGBM в этом блокноте.
Используйте библиотеки scikit-learn и LightGBM для реализации моделей с несколькими строками кода. Кроме того, используйте автологирование MLfLow и Fabric для отслеживания экспериментов.
Этот пример кода загружает разностную таблицу из lakehouse. Вы можете использовать другие дельта-таблицы, которые сами используют лэйкхаус в качестве источника.
SEED = 12345
df_clean = spark.read.format("delta").load("Tables/df_clean").toPandas()
Создание эксперимента для отслеживания и ведения журнала моделей с помощью MLflow
В этом разделе показано, как создать эксперимент, а также указать параметры модели и обучения и метрики оценки. Кроме того, в нем показано, как обучить модели, записать их в журнал и сохранить обученные модели для последующего использования.
import mlflow
# Set up the experiment name
EXPERIMENT_NAME = "sample-bank-churn-experiment" # MLflow experiment name
Автологирование автоматически фиксирует значения входных параметров и выходные метрики модели машинного обучения, так как эта модель обучена. Затем эти сведения записываются в рабочую область, где API MLflow или соответствующий эксперимент в рабочей области могут получить доступ и визуализировать его.
По завершении эксперимент напоминает это изображение:

Все эксперименты с соответствующими именами регистрируются, и вы можете отслеживать их параметры и метрики производительности. Дополнительные сведения об автологировании см. в Автологирование в Microsoft Fabric.
Настройка спецификаций эксперимента и автологирования
mlflow.set_experiment(EXPERIMENT_NAME) # Use a date stamp to append to the experiment
mlflow.autolog(exclusive=False)
Импортируйте scikit-learn и LightGBM
# Import the required libraries for model training
from sklearn.model_selection import train_test_split
from lightgbm import LGBMClassifier
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score, f1_score, precision_score, confusion_matrix, recall_score, roc_auc_score, classification_report
Подготовка обучающих и тестовых наборов данных
y = df_clean["Exited"]
X = df_clean.drop("Exited",axis=1)
# Train/test separation
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.20, random_state=SEED)
Примените SMOTE к обучающим данным
Несбалансированная классификация имеет проблему, так как она имеет слишком мало примеров класса меньшинства для эффективного изучения границы принятия решений. Чтобы справиться с этим, метод синтетического увеличения выборки для меньшинств (SMOTE) является наиболее широко используемым для синтезирования новых образцов для меньшинственного класса. Доступ к SMOTE с помощью библиотеки imblearn, установленной на шаге 1.
Примените SMOTE только к набору обучающих данных. Чтобы получить допустимое приближение производительности модели к исходным данным, необходимо оставить тестовый набор данных в исходном несбалансированном распределении. Этот эксперимент представляет ситуацию в рабочей среде.
from collections import Counter
from imblearn.over_sampling import SMOTE
sm = SMOTE(random_state=SEED)
X_res, y_res = sm.fit_resample(X_train, y_train)
new_train = pd.concat([X_res, y_res], axis=1)
Дополнительные сведения см. в SMOTE и От случайной передискретизации к SMOTE и ADASYN. Сайт imbalanced-learn содержит эти ресурсы.
Обучение модели
Используйте случайный лес для обучения модели с максимальной глубиной четырех и с четырьмя функциями:
mlflow.sklearn.autolog(registered_model_name='rfc1_sm') # Register the trained model with autologging
rfc1_sm = RandomForestClassifier(max_depth=4, max_features=4, min_samples_split=3, random_state=1) # Pass hyperparameters
with mlflow.start_run(run_name="rfc1_sm") as run:
rfc1_sm_run_id = run.info.run_id # Capture run_id for model prediction later
print("run_id: {}; status: {}".format(rfc1_sm_run_id, run.info.status))
# rfc1.fit(X_train,y_train) # Imbalanced training data
rfc1_sm.fit(X_res, y_res.ravel()) # Balanced training data
rfc1_sm.score(X_test, y_test)
y_pred = rfc1_sm.predict(X_test)
cr_rfc1_sm = classification_report(y_test, y_pred)
cm_rfc1_sm = confusion_matrix(y_test, y_pred)
roc_auc_rfc1_sm = roc_auc_score(y_res, rfc1_sm.predict_proba(X_res)[:, 1])
Используйте случайный лес для обучения модели с максимальной глубиной восьми и шестью функциями:
mlflow.sklearn.autolog(registered_model_name='rfc2_sm') # Register the trained model with autologging
rfc2_sm = RandomForestClassifier(max_depth=8, max_features=6, min_samples_split=3, random_state=1) # Pass hyperparameters
with mlflow.start_run(run_name="rfc2_sm") as run:
rfc2_sm_run_id = run.info.run_id # Capture run_id for model prediction later
print("run_id: {}; status: {}".format(rfc2_sm_run_id, run.info.status))
# rfc2.fit(X_train,y_train) # Imbalanced training data
rfc2_sm.fit(X_res, y_res.ravel()) # Balanced training data
rfc2_sm.score(X_test, y_test)
y_pred = rfc2_sm.predict(X_test)
cr_rfc2_sm = classification_report(y_test, y_pred)
cm_rfc2_sm = confusion_matrix(y_test, y_pred)
roc_auc_rfc2_sm = roc_auc_score(y_res, rfc2_sm.predict_proba(X_res)[:, 1])
Обучить модель с помощью LightGBM:
# lgbm_model
mlflow.lightgbm.autolog(registered_model_name='lgbm_sm') # Register the trained model with autologging
lgbm_sm_model = LGBMClassifier(learning_rate = 0.07,
max_delta_step = 2,
n_estimators = 100,
max_depth = 10,
eval_metric = "logloss",
objective='binary',
random_state=42)
with mlflow.start_run(run_name="lgbm_sm") as run:
lgbm1_sm_run_id = run.info.run_id # Capture run_id for model prediction later
# lgbm_sm_model.fit(X_train,y_train) # Imbalanced training data
lgbm_sm_model.fit(X_res, y_res.ravel()) # Balanced training data
y_pred = lgbm_sm_model.predict(X_test)
accuracy = accuracy_score(y_test, y_pred)
cr_lgbm_sm = classification_report(y_test, y_pred)
cm_lgbm_sm = confusion_matrix(y_test, y_pred)
roc_auc_lgbm_sm = roc_auc_score(y_res, lgbm_sm_model.predict_proba(X_res)[:, 1])
Просмотр артефакта эксперимента для отслеживания производительности модели
Результаты эксперимента автоматически сохраняются в артефакте. Этот артефакт можно найти в рабочей области. Имя артефакта основано на имени, используемом для задания эксперимента. На странице эксперимента регистрируются все обученные модели, их запуски, метрики производительности и параметры модели.
Чтобы просмотреть эксперименты, выполните следующее:
- На левой панели выберите рабочую область.
- Найдите и выберите имя эксперимента, в этом случае пример-банк-чурн-эксперимент.
Шаг 5. Оценка и сохранение конечной модели машинного обучения
Откройте сохраненный эксперимент из рабочей области, чтобы выбрать и сохранить лучшую модель:
# Define run_uri to fetch the model
# MLflow client: mlflow.model.url, list model
load_model_rfc1_sm = mlflow.sklearn.load_model(f"runs:/{rfc1_sm_run_id}/model")
load_model_rfc2_sm = mlflow.sklearn.load_model(f"runs:/{rfc2_sm_run_id}/model")
load_model_lgbm1_sm = mlflow.lightgbm.load_model(f"runs:/{lgbm1_sm_run_id}/model")
Оценка производительности сохраненных моделей в тестовом наборе данных
ypred_rfc1_sm = load_model_rfc1_sm.predict(X_test) # Random forest with maximum depth of 4 and 4 features
ypred_rfc2_sm = load_model_rfc2_sm.predict(X_test) # Random forest with maximum depth of 8 and 6 features
ypred_lgbm1_sm = load_model_lgbm1_sm.predict(X_test) # LightGBM
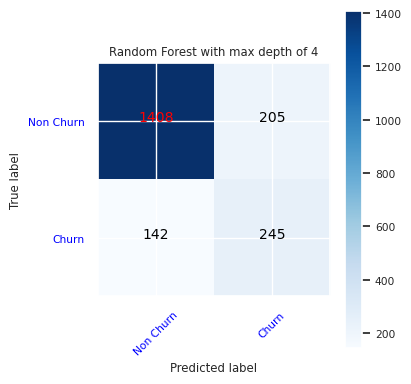
Отображение истинных и ложных положительных/отрицательных результатов с помощью матрицы ошибок.
Чтобы оценить точность классификации, создайте скрипт, который создает матрицу путаницы. Вы также можете создать матрицу путаницы с помощью средств SynapseML, как показано в примере обнаружения мошенничества .
def plot_confusion_matrix(cm, classes,
normalize=False,
title='Confusion matrix',
cmap=plt.cm.Blues):
print(cm)
plt.figure(figsize=(4,4))
plt.rcParams.update({'font.size': 10})
plt.imshow(cm, interpolation='nearest', cmap=cmap)
plt.title(title)
plt.colorbar()
tick_marks = np.arange(len(classes))
plt.xticks(tick_marks, classes, rotation=45, color="blue")
plt.yticks(tick_marks, classes, color="blue")
fmt = '.2f' if normalize else 'd'
thresh = cm.max() / 2.
for i, j in itertools.product(range(cm.shape[0]), range(cm.shape[1])):
plt.text(j, i, format(cm[i, j], fmt),
horizontalalignment="center",
color="red" if cm[i, j] > thresh else "black")
plt.tight_layout()
plt.ylabel('True label')
plt.xlabel('Predicted label')
Создайте матрицу путаницы для классификатора случайного леса с максимальной глубиной 4 и четырьмя признаками.
cfm = confusion_matrix(y_test, y_pred=ypred_rfc1_sm)
plot_confusion_matrix(cfm, classes=['Non Churn','Churn'],
title='Random Forest with max depth of 4')
tn, fp, fn, tp = cfm.ravel()
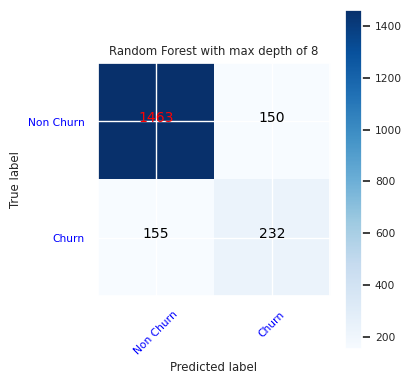
Создайте матрицу путаницы для классификатора случайного леса с максимальной глубиной 8, с шестью функциями:
cfm = confusion_matrix(y_test, y_pred=ypred_rfc2_sm)
plot_confusion_matrix(cfm, classes=['Non Churn','Churn'],
title='Random Forest with max depth of 8')
tn, fp, fn, tp = cfm.ravel()
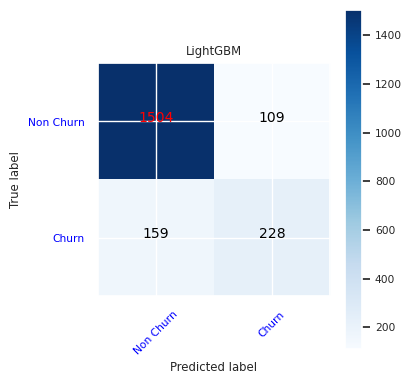
Создайте матрицу путаницы для LightGBM:
cfm = confusion_matrix(y_test, y_pred=ypred_lgbm1_sm)
plot_confusion_matrix(cfm, classes=['Non Churn','Churn'],
title='LightGBM')
tn, fp, fn, tp = cfm.ravel()
Сохранение результатов для Power BI
Сохраните делта-кадр в хранилище данных, для переноса результатов прогнозирования модели в визуализацию Power BI.
df_pred = X_test.copy()
df_pred['y_test'] = y_test
df_pred['ypred_rfc1_sm'] = ypred_rfc1_sm
df_pred['ypred_rfc2_sm'] =ypred_rfc2_sm
df_pred['ypred_lgbm1_sm'] = ypred_lgbm1_sm
table_name = "df_pred_results"
sparkDF=spark.createDataFrame(df_pred)
sparkDF.write.mode("overwrite").format("delta").option("overwriteSchema", "true").save(f"Tables/{table_name}")
print(f"Spark DataFrame saved to delta table: {table_name}")
Шаг 6. Доступ к визуализациям в Power BI
Доступ к сохраненной таблице в Power BI:
- Слева выберите OneLake.
- Выберите дом у озера, который вы добавили в эту записную книжку.
- В разделе Открыть этот Lakehouse выберите Открыть.
- На ленте выберите Новая семантическая модель. Выберите
df_pred_results, затем выберите и Подтвердите для создания новой семантической модели Power BI, связанной с прогнозами. - Откройте новую семантику. Его можно найти в OneLake.
- Выберите Создать новый отчет в разделе "Файл" среди инструментов на странице семантических моделей в верхней части, чтобы открыть страницу разработки отчетов Power BI.
На следующем снимках экрана показаны некоторые примеры визуализаций. На панели данных отображаются разностные таблицы и столбцы для выбора из таблицы. После выбора соответствующей оси категории (x) и значения (y) можно выбрать фильтры и функции, например сумму или среднее значение столбцов таблицы.
Заметка
На этом снимке экрана показан пример, в котором описывается анализ сохраненных результатов прогнозирования в Power BI:

Тем не менее, для реального варианта использования оттока клиентов пользователю может потребоваться более подробные требования к визуализациям, основанные на экспертных знаниях в соответствующей области, а также стандартах, установленных фирмой и командой бизнес-аналитики в отношении метрик.
В отчете Power BI показано, что клиенты, использующие более двух банковских продуктов, имеют более высокую скорость оттока. Однако у немногих клиентов было более двух продуктов. (См. график на левой нижней панели.) Банк должен собирать больше данных, но также должен исследовать другие функции, которые коррелируют с большими продуктами.
Клиенты банка в Германии имеют более высокую скорость оттока по сравнению с клиентами во Франции и Испании. (См. график на нижней правой панели). Основываясь на результатах отчета, исследование факторов, которые призвали клиентов уйти, могут помочь.
Существуют более средние клиенты (от 25 до 45). Клиенты в возрасте от 45 до 60 лет, как правило, уходят чаще.
Наконец, клиенты с более низким кредитным рейтингом, скорее всего, покинут банк для других финансовых учреждений. Банк должен изучить способы поощрения клиентов с более низкими кредитными оценками и балансами счетов, чтобы оставаться в банке.
# Determine the entire runtime
print(f"Full run cost {int(time.time() - ts)} seconds.")
Связанное содержимое
- модель машинного обучения в Microsoft Fabric
- Обучение моделей машинного обучения
- эксперименты машинного обучения в Microsoft Fabric