Сценарий ценообразования с помощью потока данных 2-го поколения для загрузки данных Parquet в таблицу Lakehouse
В этом сценарии поток данных 2-го поколения использовался для загрузки 2 ГБ данных Parquet, хранящихся в Azure Data Lake служба хранилища (ADLS) 2-го поколения в таблицу Lakehouse в Microsoft Fabric. Мы использовали примеры данных NYC Taxi-green для данных Parquet.
Цены, используемые в следующем примере, являются гипотетическими и не намерены подразумевать точные фактические цены. Это просто для демонстрации того, как можно оценить, спланировать и управлять затратами на проекты Фабрики данных в Microsoft Fabric. Кроме того, так как емкости Fabric имеют уникальную цену в разных регионах, мы используем цены на оплату по мере использования для емкости Fabric на западе США 2 (типичный регион Azure) на 0,18 долл. США в час. См. здесь сведения о ценах на Microsoft Fabric. Чтобы изучить другие варианты ценообразования емкости Fabric.
Настройка
Чтобы выполнить этот сценарий, необходимо создать поток данных, выполнив следующие действия.
- Инициализация потока данных: получение данных 2 ГБ Parquet из учетной записи хранения ADLS 2-го поколения.
- Настройка Power Query:
- Перейдите в Power Query.
- Убедитесь, что параметр промежуточного выполнения запроса включен.
- Перейдите к сочетанию файлов Parquet.
- Преобразование данных:
- Повышение уровня заголовков для ясности.
- Удалите ненужные столбцы.
- При необходимости настройте типы данных столбцов.
- Определение назначения выходных данных:
- Настройте Lakehouse в качестве назначения выходных данных.
- В этом примере был создан и использован Lakehouse в Fabric.
Оценка затрат с помощью приложения метрик Fabric






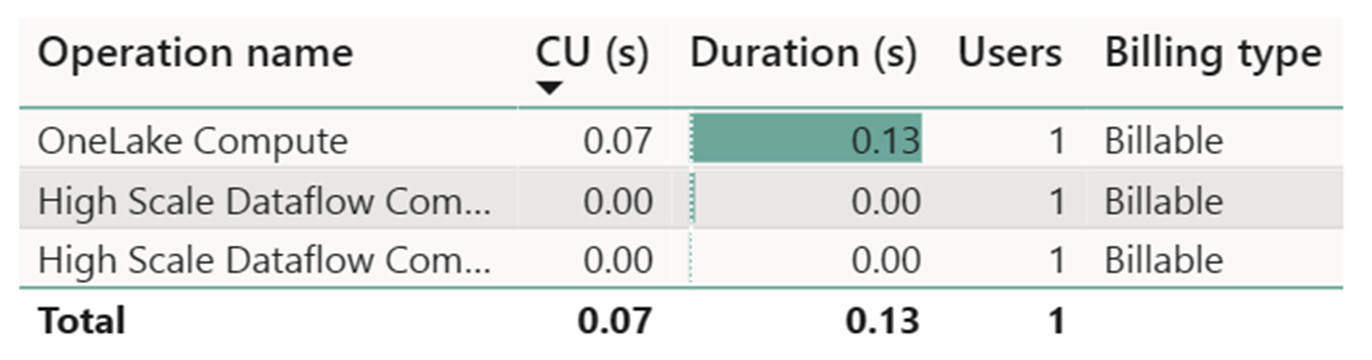
Счетчик вычислений потока данных высокого масштаба записал незначительное действие. Стандартный счетчик вычислений для операций обновления Dataflow 2-го поколения использует 112 098,540 единиц вычислений (ЦС). Важно учитывать, что другие операции, включая хранилище запросов, запрос конечной точки SQL и обновление набора данных по запросу, представляют собой подробные аспекты реализации потока данных 2-го поколения, которые в настоящее время прозрачны и необходимы для их соответствующих операций. Однако эти операции будут скрыты в будущих обновлениях и должны игнорироваться при оценке затрат на поток данных 2-го поколения.
Примечание.
Несмотря на то, что эта метрика отображается как метрика, фактическое время выполнения не имеет значения при вычислении эффективных часов CU с приложением метрик Структуры, так как метрика метрики CU, которая также сообщает уже о учетных записях в течение его длительности.
| Metric | Среда выполнения приложений уровня "Стандартный" | Высокомасштабируемые вычисления |
|---|---|---|
| Всего секунд cu | 112 098,54 секунды CU | 0 секунд cu |
| Счета за действующие часы cu-часов | 112 098.54 / (60*60) = 31,14 часов CU | 0 / (60*60) = 0 часов CU |
Общая стоимость выполнения на $0,18/CU hour = (31,14 CU-hours ) * ($0,18/CU час) ~= $5,60