Цены на фабрику данных в Microsoft Fabric
Фабрика данных в Microsoft Fabric предоставляет бессерверные и эластичные возможности службы интеграции данных, созданные для масштабирования облака. Нет вычислительных ресурсов фиксированного размера, которые необходимо планировать для пиковой нагрузки; вместо этого необходимо указать, какие операции следует выполнять при создании конвейеров и потоков данных, что преобразуется в объем потребляемых единиц емкости Fabric, которое можно отслеживать с помощью приложения метрик емкости Microsoft Fabric для планирования метрик потребления и управления ими. Это позволяет разрабатывать процессы ETL гораздо более масштабируемым образом. Кроме того, фабрика данных, как и другие интерфейсы Fabric, взимается плата за план на основе потребления, что означает, что вы оплачиваете только то, что вы используете.
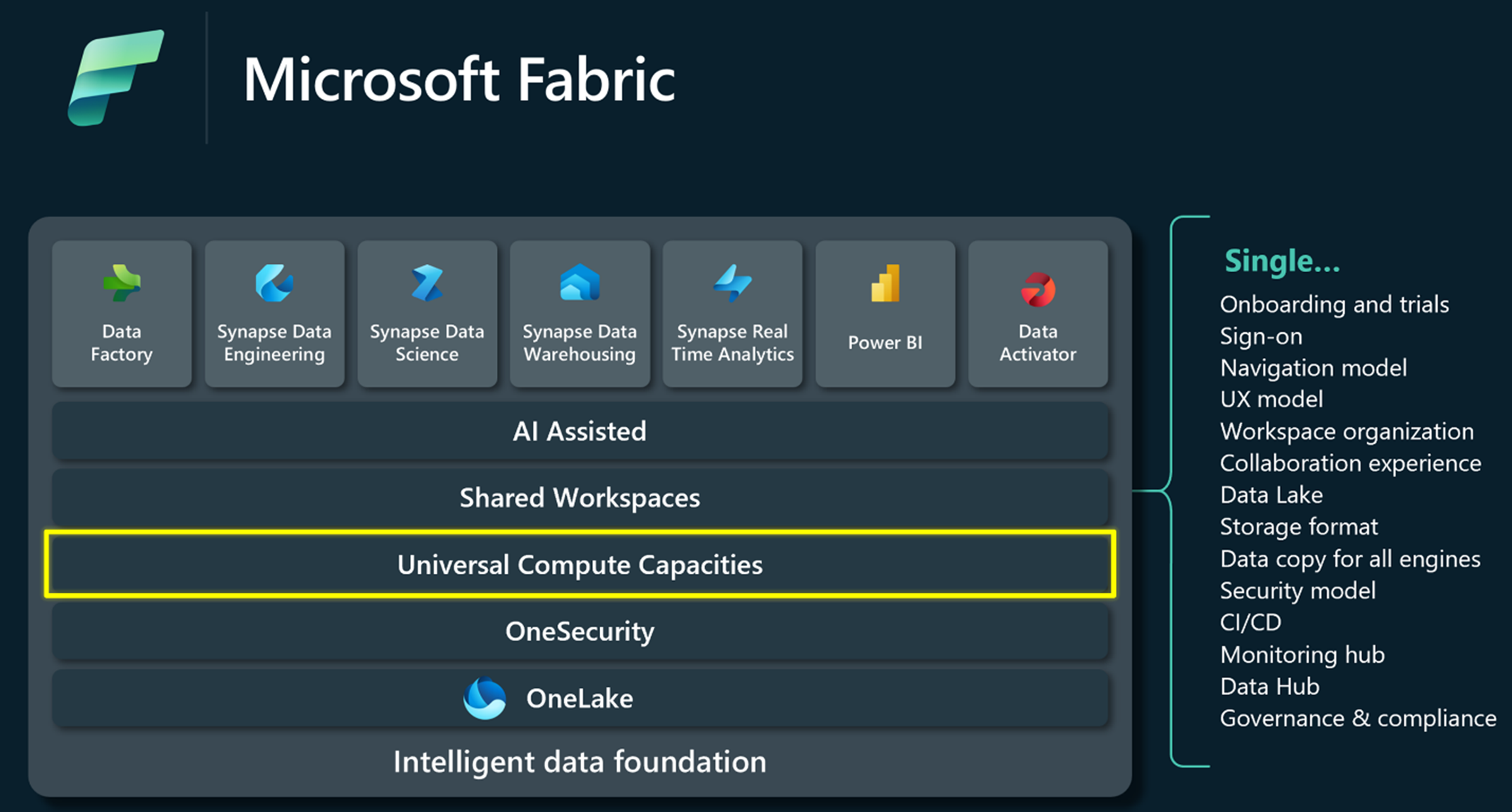
Емкости Microsoft Fabric
Fabric — это единая платформа данных, которая предлагает общий интерфейс, архитектуру, управление, соответствие и выставление счетов. Емкости обеспечивают вычислительную мощность, которая обеспечивает все эти возможности. Они предлагают простой и унифицированный способ масштабирования ресурсов в соответствии с требованиями клиентов и могут быть легко увеличены с помощью обновления SKU.
Вы можете легко управлять затратами на фабрику данных Fabric с помощью упрощенного выставления счетов. Дополнительные пользователи не требуют управления затратами на основе каждого пользователя, и вы можете сэкономить деньги путем планирования и фиксации емкостей Fabric для проектов интеграции данных заранее. С помощью варианта оплаты по мере использования вы можете легко масштабировать свои емкости вверх и вниз, чтобы настроить вычислительные мощности и приостановить их емкость, если не использовать для экономии затрат. Дополнительные сведения о емкостях Fabric и выставлении счетов за использование.
Счетчики цен фабрики данных
Независимо от того, являетесь ли вы гражданином или профессиональным разработчиком, фабрика данных позволяет разрабатывать решения для интеграции данных корпоративного масштаба с помощью потоков данных следующего поколения и конвейеров данных. Эти возможности работают с несколькими службами с различными счетчиками емкости. Конвейеры данных используют счетчики оркестрации и перемещения данных, а поток данных 2-го поколения использует стандартные вычисления и высокомасштабируемые вычисления. Кроме того, как и другие возможности Fabric, общий метр для потребления хранилища — Хранилище OneLake.

Примеры цен
Ниже приведены некоторые примеры сценариев ценообразования конвейеров данных:
- Загрузка 1 ТБ Parquet в хранилище данных
- Загрузка 1 ТБ Parquet в хранилище данных с помощью промежуточного хранения
- Загрузка CSV-файлов размером 1 ТБ в таблицу Lakehouse
- Загрузка CSV-файлов размером 1 ТБ в файлы Lakehouse с двоичной копией
- Загрузка 1 ТБ Parquet в таблицу Lakehouse
Ниже приведены некоторые примеры ценообразования для потока данных 2-го поколения: