Определение конфиденциальной и защищенной информации для обеспечения соответствия австралийского правительства требованиям PSPF
В этой статье приводятся рекомендации для австралийских государственных организаций по использованию Microsoft Purview для идентификации конфиденциальной информации и информации, секретной для безопасности. Его цель заключается в том, чтобы помочь таким организациям укрепить свой подход к безопасности данных и их способность соблюдать требования, изложенные в Платформе политики защиты безопасности (PSPF) и Руководстве по информационной безопасности (ISM).
Ключом к защите информации и ее защите от потери данных сначала является понимание того, что такое информация. В этой статье рассматриваются методы идентификации информации в среде Microsoft 365 организации. Эти подходы часто называют сведениями об аспектах данных Microsoft Purview. После идентификации информация может быть защищена с помощью автоматической маркировки конфиденциальности и защиты от потери данных (DLP).
Типы конфиденциальных сведений
Типы конфиденциальной информации (SIT) — это классификаторы на основе шаблонов. Они обнаруживают конфиденциальную информацию с помощью регулярных выражений (RegEx) или ключевых слов.
Существует множество различных типов SIT, которые относятся к австралийским правительственным организациям:
- Предварительно созданные sits , созданные корпорацией Майкрософт, некоторые из которых соответствуют общим австралийским типам данных.
- Пользовательские sit создаются на основе требований организации.
- Именованные идентификаторы сущностей включают сложные идентификаторы на основе словаря, такие как физические адреса Австралии.
- Наборы SIT точного сопоставления данных (EDM) создаются на основе фактических конфиденциальных данных.
- SiT отпечатков документов основаны на формате документов, а не на их содержимом.
- SIT, относящиеся к сетевой или информационной безопасности , хотя технически предварительно созданные SIT, они имеют особое значение для киберкомаб, работающих с австралийскими правительственными организациями, и поэтому достойны своей собственной категории.
Предварительно созданные типы конфиденциальной информации
Предварительно созданные типы конфиденциальной информации основаны на общих типах информации, которые клиенты обычно считают конфиденциальными. Они могут быть универсальными и иметь глобальное значение (например, кредитные карта номера) или иметь локальное значение (например, номера австралийских банковских счетов).
Полный список предварительно созданных SIT корпорации Майкрософт можно найти в определениях сущностей типа конфиденциальной информации.
Специальные австралийские SIT включают в себя:
- Номер банковского счета в Австралии
- Номер водительского удостоверения Австралии
- Номер австралийского паспорта
- Физические адреса Австралии
- Номер налогового файла Австралии
- Австралийский бизнес-номер
- Номер австралийской компании
- Номер австралийского медицинского счета
Эти SIT можно найти на портале классификации данных Microsoft Purview в разделе Классификаторы>Типы конфиденциальной информации.
Предварительно созданные SIT полезны для организаций, которые начинают Information Protection или путь управления, так как они обеспечивают начало реализации таких возможностей, как защита от потери данных и автоматическая маркировка. Два самых простых способа использования этих SIT:
Использование предварительно созданных sit с помощью шаблонов политик защиты от потери данных
Некоторые предварительно созданные SIT включены в созданные корпорацией Майкрософт шаблоны политик защиты от потери данных, которые соответствуют австралийским правилам. Доступны следующие шаблоны политик защиты от потери данных, которые соответствуют австралийским требованиям:
- Расширенный закон о конфиденциальности Австралии
- Финансовые данные для Австралии
- Стандарт защиты данных PCI (PCI DSS)
- Персональные данные для Австралии
Включение политик защиты от потери данных на основе этих шаблонов позволяет осуществлять первоначальный мониторинг событий потери данных, что является отличной отправной точкой для организаций, внедряющих Microsoft 365 DLP. После развертывания эти политики предоставляют представление о масштабах проблемы с потерей данных в организации и могут помочь принять решения о дальнейших шагах.
Использование этих шаблонов политик рассматривается в целях ограничения распространения конфиденциальной информации.
Использование предварительно созданных SIT в автоматическом присвоении меток конфиденциальности
Если обнаруживается, что элемент содержит номер австралийского медицинского счета, один или несколько медицинских терминов и полное имя, то можно предположить, что этот элемент содержит личную медицинскую информацию и может представлять собой медицинскую запись. Исходя из этого предположения, мы можем предложить пользователю, чтобы элемент был помечен как "OFFICIAL: конфиденциальность личных данных" или какой-либо метки, наиболее подходящей в вашей организации для идентификации и защиты медицинских записей.
Дополнительные сведения о том, где эта функция может помочь государственным организациям обеспечить соответствие ТРЕБОВАНИЯМ PSPF, см. в статье Автоматическое применение меток конфиденциальности и сценарии автоматической маркировки на основе клиентов для австралийского правительства.
Пользовательские типы конфиденциальной информации
Помимо предварительно созданных SIT, организации могут создавать sit на основе собственных определений конфиденциальной информации. Ниже приведены примеры сведений, относящихся к австралийским правительственным организациям, которые можно определить с помощью пользовательского СИТ:
- Защитная маркировка
- Идентификатор зазора или идентификатор приложения для очистки
- Классификации из других штатов или территорий
- Классификации, которые не должны отображаться на платформе (например, TOP SECRET)
- Брифинги или корреспонденция министров
- Номер запроса на свободу информации (FOI)
- Информация, связанная с достоверностью
- Условия, относящиеся к конфиденциальным системам, проектам или приложениям
- Маркировка абзаца
- Обрезные или целевые номера записей
Пользовательские sit состоят из основного идентификатора, который может быть основан на регулярном выражении или ключевых словах, уровне достоверности и необязательных вспомогательных элементах.
Более подробное описание sit и их компонентов см. в статье Сведения о типах конфиденциальной информации.
Регулярные выражения (регулярные выражения)
Регулярные выражения — это кодовые идентификаторы, которые можно использовать для идентификации шаблонов информации. Например, если номер свободы информации (FOI) состоит из букв, за которыми следует четыре цифры FOI года, дефис и еще три цифры (например, FOI2023-123), он может быть представлен в регулярном выражении:
[Ff][Oo][Ii]20[01234]\d{1}-\d{3}
Чтобы объяснить это выражение, выполните следующее:
-
[Ff][Oo][Ii]соответствует верхним или строчным буквам F, O и I. -
20соответствует числу 20 в качестве первой половины четырехзначного года. -
[0123]соответствует 0, 1, 2 или 3 в третьей цифре в нашем четырехзначном значении года, что позволяет нам сопоставлять номера FOI с 2000 по 2039 год. -
-соответствует дефису. -
\d{3}соответствует любым трем цифрам.
Совет
Copilot довольно искусно создает регулярные выражения (RegEx). Вы можете использовать естественный язык, чтобы попросить Copilot создать regEx для вас.
Список ключевых слов или словарь ключевое слово
Списки ключевых слов и словари состоят из слов, терминов или фраз, которые, скорее всего, будут включены в элементы, которые вы хотите определить. брифинг илизаявка на проведение тендера — это термины, которые могут быть полезны в качестве ключевых слов.
Ключевые слова могут быть чувствительными к регистру или не учитывать регистр. Регистр может быть полезен для устранения ложноположительных результатов. Например, строчная official буква с большей вероятностью будет использоваться в общей беседе, но прописные буквы OFFICIAL имеют более высокую вероятность того, что они являются частью защитной маркировки.
Словари ключевых слов, содержащие большие наборы данных, также можно передавать в формате CSV или TXT . Дополнительные сведения о том, как отправить словарь ключевое слово, см. в статье Создание словаря ключевое слово.
Уровень вероятности
Некоторые ключевые слова или регулярные выражения могут обеспечить точное сопоставление без необходимости уточнения. Выражение "Свобода информации" (FOI), включенное в предыдущий пример значения, вряд ли появится в общем разговоре, и когда оно появляется в корреспонденции, скорее всего, будет соответствовать соответствующей информации. Тем не менее, если мы пытались сопоставить номер австралийского работника государственной службы, который представлен в виде восьми числовых цифр, наше сопоставление, скорее всего, приведет к многочисленным ложным срабатываниям. Уровень достоверности позволяет нам назначить вероятность того, что наличие ключевое слово или шаблона в элементе, например в сообщении электронной почты или документе, на самом деле является тем, что мы ищем. Дополнительные сведения об уровнях достоверности см. в статье Управление уровнями доверия.
Основные и вспомогательные элементы
Пользовательские SIT также имеют концепцию основных и вспомогательных элементов. Основным элементом является ключевой шаблон, который мы хотим обнаружить в содержимом. Вспомогательные элементы можно добавить в основной объект, чтобы создать аргумент для вхождения значения, являющегося точным совпадением. Например, при попытке сопоставить данные на основе восьмизначного числа сотрудников мы могли бы использовать ключевые слова "номер сотрудника" или номер австралийского правительства AGSили австралийскую базу данных APSED государственных служащих в качестве вспомогательного элемента для повышения уверенности в том, что совпадение имеет значение. Дополнительные сведения о создании основных и вспомогательных элементов см. в разделе Общие сведения об элементах.
Близкое расположение символов
Последнее значение, которое мы обычно настраиваем в SIT, — это близость символов. Это расстояние между основным и вспомогательным элементами. Если мы ожидаем, что ключевое слово AGS будет близка к числовой величине из восьми цифр, мы настраиваем близость 10 символов. Если первичные и вспомогательные элементы, скорее всего, не будут отображаться рядом друг с другом, мы задаем значение близкого взаимодействия как большее количество символов. Дополнительные сведения о том, как создать близкое расположение символов, см. в разделе Общие сведения о близком расположении.
SIT для идентификации защитной маркировки
Для австралийских государственных организаций ценным способом использования пользовательских SIT является выявление защитной маркировки. В организации Greenfield ко всем элементам в среде применяется метка конфиденциальности. Однако большинство государственных организаций имеют устаревшие метки, требующие модернизации в Microsoft Purview. SIT используются для идентификации и применения маркировки к:
- Помеченные устаревшие файлы
- Помеченные файлы, созданные внешними сущностями
- Email беседы, инициированные и помеченные извне
- Сообщения электронной почты, потерявшие сведения о метках (x-заголовки)
- Сообщения электронной почты, в которых их метки были неправильно понижены
При обнаружении такого маркера пользователь будет уведомлен об обнаружении и ему предоставляется рекомендация по метки. Если они принимают рекомендацию, к элементу применяются меры защиты на основе меток. Эти понятия подробно рассматриваются в сценариях автоматической маркировки на основе клиентов для австралийского правительства.
SiT на основе классификации также полезны для защиты от потери данных. Вот некоторые примеры.
- Пользователь получает информацию и определяет ее как конфиденциальную с помощью маркировки, но не хочет переклассифицировать ее, так как она не переводится в классификацию PSPF (например, "ОФИЦИАЛЬНОЕ конфиденциальное правительство NSW"). Создание политики защиты от потери данных для защиты вложенных сведений на основе маркировки, а не примененной метки, означает, что к ней можно применить меру безопасности данных.
- Пользователь копирует текст из беседы по электронной почте, которая включает в себя защитную маркировку. Они вставляют информацию в чат Teams с внешним участником, который не должен иметь доступа к этой информации. С помощью политики защиты от потери данных, применяемой к службе Teams, можно обнаружить маркировку и предотвратить раскрытие.
- Пользователь неправильно понижает метку конфиденциальности в беседе по электронной почте (злонамеренно или по ошибке пользователя). Так как ранее к сообщению были применены защитные маркировки, видимые в тексте сообщения, Microsoft Purview обнаруживает, что текущая и предыдущая маркировка несогласованы. В зависимости от конфигурации действие регистрирует событие, предупреждает пользователя или блокирует сообщение электронной почты.
- Помеченное сообщение электронной почты отправляется внешнему получателю, который использует платформу электронной почты или клиента, не являющихся клиентами. Платформа или клиент удаляет метаданные электронной почты (x-заголовки), что приводит к тому, что в ответном письме внешнего получателя не применяется метка конфиденциальности, когда она поступает в почтовый ящик пользователя организации. Обнаружение предыдущей маркировки с помощью SIT позволяет прозрачно повторно применить метку или рекомендовать пользователю повторно применить метку к следующему ответу.
В каждом из этих сценариев для обнаружения примененной защитной маркировки и устранения потенциальной утечки данных можно использовать SIT на основе классификации.
Пример синтаксиса SIT для обнаружения защитной маркировки
Следующие регулярные выражения можно использовать в пользовательских SIT для идентификации защитной маркировки.
Важно!
Создание SIT для идентификации защитной маркировки помогает в соответствии с PSPF. SiT на основе классификации также используются в сценариях защиты от потери данных и автоматической маркировки.
| Имя SIT | Регулярное выражение |
|---|---|
| REGEX1 | UNOFFICIAL |
| ОФИЦИАЛЬНЫЙ регулярный регистр1,2 | (?<!UN)OFFICIAL |
| ОФИЦИАЛЬНЫЙ конфиденциальный regex1,3,4,5 | OFFICIAL[:- ]\s?Sensitive(?!(?:\s\|\/\/\|\s\/\/\s)[Pp]ersonal[- ][Pp]rivacy)(?!(?:\s\|\/\/\|\s\/\/\s)[Ll]egislative[- ][Ss]ecrecy)(?!(?:\s\|\/\/\|\s\/\/\s)[Ll]egal[- ][Pp]rivilege)(?!(?:\s\|\/\/\|\s\/\/\s)NATIONAL[ -]CABINET) |
| ОФИЦИАЛЬНЫЙ REGEXконфиденциальности конфиденциальности 1,4,5 | OFFICIAL[:- ]\s?Sensitive(?:\s\|\/\/\|\s\/\/\s\|,\sACCESS=)Personal[ -]Privacy |
| OFFICIAL Sensitive Legal Privilege Regex1,4,5 | OFFICIAL[:- ]\s?Sensitive(?:\s\|\/\/\|\s\/\/\s\|,\sACCESS=)Legal[ -]Privilege |
| ОФИЦИАЛЬНЫЙ конфиденциальный законодательный секретный regex1,4,5 | OFFICIAL[:- ]\s?Sensitive(?:\s\|\/\/\|\s\/\/\s\|,\sACCESS=)Legislative[ -]Secrecy |
| ОФИЦИАЛЬНЫЙ КОНФИДЕНЦИАЛЬНЫЙ НАЦИОНАЛЬНЫЙ КАБИНЕТ регулярный учет1,4,5 | OFFICIAL[:- ]\s?Sensitive(?:\s\|\/\/\|\s\/\/\s\|,\sCAVEAT=SH:)NATIONAL[ -]CABINET |
| ЗАЩИЩЕННЫЙ regex1,3,5 | PROTECTED(?!,\sACCESS=)(?!(?:\s\|\/\/\|\s\/\/\s)[Pp]ersonal[- ][Pp]rivacy)(?!(?:\s\|\/\/\|\s\/\/\s)[Ll]egislative[- ][Ss]ecrecy)(?!(?:\s\|\/\/\|\s\/\/\s)[Ll]egal[- ][Pp]rivilege)(?!(?:\s\|\/\/\|\s\/\/\s)NATIONAL[ -]CABINET)(?!(?:\s\|\/\/\|\s\/\/\s)CABINET) |
| Regex 1,5 protected Personal Privacy Regex1,5 | PROTECTED(?:\s\|\/\/\|\s\/\/\s\|,\sACCESS=)Personal[ -]Privacy |
| Regex1,5 PROTECTED Legal Privilege Regex | PROTECTED(?:\s\|\/\/\|\s\/\/\s\|,\sACCESS=)Legal[ -]Privilege |
| Защищенный законодательный тайна Regex1,5 | PROTECTED(?:\s\|\/\/\|\s\/\/\s\|,\sACCESS=)Legislative[ -]Secrecy |
| ЗАЩИЩЕННЫЙ НАЦИОНАЛЬНЫЙ РЕГИСТР КАБИНЕТА1,5 | PROTECTED(?:\s\|\/\/\|\s\/\/\s\|,\sCAVEAT=SH:)NATIONAL[ -]CABINET |
| ЗАЩИЩЕННЫЙ REGEX1,5 | PROTECTED(?:\s\|\/\/\|\s\/\/\s\|,\sCAVEAT=SH:)CABINET |
При оценке предыдущих примеров SIT обратите внимание на следующую логику выражений:
- 1 Эти выражения соответствуют маркировке, примененной как к документам (например, OFFICIAL: Sensitive NATIONAL CABINET), так и к электронной почте (например, "[SEC=OFFICIAL:Sensitive, CAVEAT=NATIONAL-CABINET]).
-
2 Отрицательный взгляд в OFFICIAL Regex (
(?<!UN)) не позволяет сопоставить элементы OFFICIAL как OFFICIAL. -
3OFFICIAL Sensitive Regex и PROTECTED Regex используют отрицательные внешние точки (
(?!)), чтобы гарантировать, что маркеры управления информацией (IMM) или предостережение не будут применены после классификации безопасности. Это помогает предотвратить идентификацию элементов с мгновенными сообщениями или предупреждениями в качестве версии классификации, отличной от IMM или предостережения. -
4 Использование
[:\- ]в OFFICIAL: Sensitive предназначено для обеспечения гибкости в формате маркировки и важно из-за использования символов двоеточия в x-заголовках. -
5
(?:\s\|\/\/\|\s\/\/\s)используется для определения пространства между компонентами маркировки и позволяет использовать одно пространство, двойное пространство, двойную косую черту или двойную косую черту с пробелами. Это предназначено для того, чтобы обеспечить различные толкования формата маркировки PSPF, существующего между австралийскими правительственными организациями.
Типы конфиденциальной информации именованных сущностей
Идентификаторы именованных сущностей — это сложные словари и идентификаторы на основе шаблонов, созданные корпорацией Майкрософт, которые можно использовать для обнаружения таких сведений, как:
- имена Люди
- Физические адреса
- Медицинские условия
СИИ именованных сущностей можно использовать изолированно, но они также могут быть полезными в качестве вспомогательных элементов. Например, медицинский термин, существующий в сообщении электронной почты, может быть не полезен как указание на то, что элемент содержит конфиденциальную информацию. Однако медицинский термин в сочетании со значением, которое может указывать на номер клиента или пациента, а также имя и фамилию, будет веской указывать на то, что элемент является конфиденциальным.
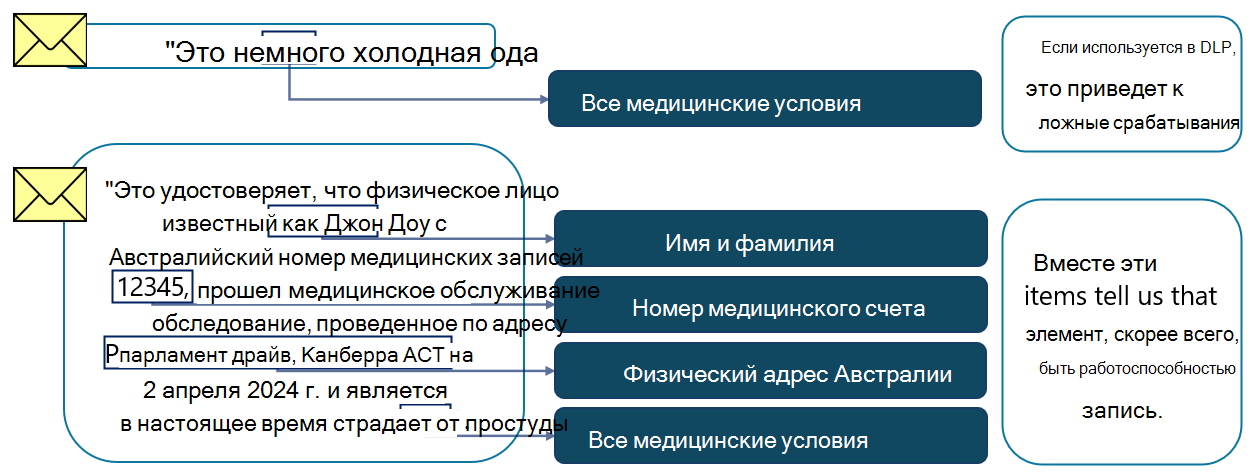
Именованные sit сущности могут быть связаны с пользовательскими sit, используются в качестве вспомогательных элементов или даже включены в другие SIT в политиках защиты от потери данных.
Дополнительные сведения о идентификаторах именованных сущностей см. в статье Об именованных сущностях.
Точное сопоставление данных типов конфиденциальной информации
SiT точного сопоставления данных (EDM) создаются на основе фактических данных. Числовые значения, такие как числовые идентификаторы клиентов, трудно сопоставить с помощью стандартных SIT из-за столкновений с другими числовыми значениями, такими как номера телефонов. Вспомогательные элементы улучшают сопоставление, помогая уменьшить количество ложных срабатываний.
Точное сопоставление данных помогает австралийским государственным организациям, которые имеют системы, содержащие данные, относящиеся к сотрудникам, клиентам или гражданам, для точной идентификации этой информации.
Дополнительные сведения о реализации SIT EDM см. в статье о типах конфиденциальной информации на основе точного сопоставления данных.
Создание отпечатка документа
Дактилоскопия документа — это метод идентификации информации, который вместо поиска значений, содержащихся в элементе, вместо этого просматривает формат и структуру элемента. По сути, это позволяет преобразовать стандартную форму в тип конфиденциальной информации, который можно использовать для идентификации информации.
Государственные организации могут использовать метод идентификации содержимого с помощью отпечатков документов для идентификации элементов, созданных с помощью рабочего процесса или форм, отправленных другими организациями или представителями общественности.
Сведения о реализации отпечатков документов см. в разделе Отпечаток документа.
Типы конфиденциальной информации, связанной с сетью или безопасностью
Существуют многочисленные способы использования sit помимо идентификации конфиденциальной информации безопасности или иным образом конфиденциальной информации. Одним из таких вариантов использования является обнаружение учетных данных. Предварительно созданные SIT предоставляются для следующих типов учетных данных:
- Учетные данные для входа пользователя
- Microsoft Entra ID маркеры клиентского доступа
- пакетная служба Azure ключей общего доступа
- Подписанные url-адреса учетной записи хранения Azure
- Секрет клиента или ключи API
Эти предварительно созданные sit используются независимо и также объединяются в sit с именем Все учетные данные.Все учетные данные SIT полезны для кибер-команд, которые используют его в:
- Политики защиты от потери данных для выявления и предотвращения бокового перемещения злоумышленниками или внешними злоумышленниками.
- Политики автоматического присвоения меток для применения шифрования к элементам, которые не должны содержать учетные данные, блокировки пользователей из файлов и разрешения на начало действий по исправлению.
- Политики защиты от потери данных, чтобы запретить пользователям делиться своими учетными данными с другими пользователями в политиках организации.
- Выделение элементов, хранящихся в расположениях SharePoint или Exchange, в которых неуместно хранятся учетные данные.
Предварительно созданные SIT также существуют для сетевых адресов (как IPv4, так и IPv6) и полезны для защиты элементов, содержащих сведения о сети, или запретить пользователям совместно использовать IP-адреса по электронной почте, чату Teams или сообщениям канала.
Обучаемые классификаторы
Обучаемые классификаторы — это модели машинного обучения, которые можно обучить распознавать конфиденциальные сведения. Как и в случае с SIT, корпорация Майкрософт предоставляет предварительно обученные классификаторы. В следующей таблице перечислены предварительно обученные классификаторы, относящиеся к австралийским правительственным организациям:
| Категория классификатора | Примеры обучаемых классификаторов |
|---|---|
| Финансы | Банковские выписки, бюджет, отчеты о финансовом аудите, финансовые отчеты, налоги, отчет о счетах, бюджетные оценки (BE), отчет о деловой активности (BAS). |
| Для бизнеса | Операционные процедуры, соглашения о неразглашении, закупки, слова кода проекта, оценки Сената (SE), вопросы об уведомлении (QoNs). |
| Управление персоналом | Резюме, файлы о дисциплинарных мерах, трудовой договор, разрешение Австралийского агентства по обеспечению безопасности (AGSVA), кредитная программа высшего образования (HELP), военный идентификатор, разрешение на иностранную работу (FWA). |
| Медицинские | Здравоохранение, медицинские формы, MyHealth Record. |
| Юридические аспекты | Юридические вопросы, соглашения, лицензионные соглашения. |
| Технический | Файлы разработки программного обеспечения, документы проекта, файлы проектирования сети. |
| Поведение | оскорбительные выражения, ненормативная лексика, угроза, целевые домогательства, дискриминация, нормативный сговор, жалоба клиента. |
Ниже приведены некоторые примеры того, как государственные организации могут использовать эти предварительно созданные классификаторы:
- Бизнес-правила могут диктовать, что некоторые элементы в категории кадров, такие как резюме, должны быть помечены как "OFFICIAL: конфиденциальность личных данных", так как они содержат конфиденциальную личную информацию. Для этих элементов рекомендации по меткам можно настроить с помощью автоматической маркировки на основе клиента.
- Файлы проектирования сети, особенно для защищенных сетей, следует тщательно обрабатывать, чтобы избежать компрометации. Они могут быть достойны либо метки PROTECTED, либо, по крайней мере, политик защиты от потери данных, предотвращающих несанкционированное раскрытие информации неавторизованных пользователей.
- Классификаторы поведения интересны, и хотя они могут не иметь прямой корреляции с защитной маркировкой или требованиями защиты от потери данных, они по-прежнему могут иметь высокую ценность для бизнеса. Например, сотрудники отдела кадров могут получать уведомления о случаях домогательств и (или) предоставлять возможность просматривать помеченную корреспонденцию через соответствие требованиям к коммуникациям.
Организации также могут обучать собственные классификаторы. Классификаторы можно обучить, предоставив им наборы положительных и отрицательных выборок. Классификатор обрабатывает примеры и создает модель прогнозирования. После завершения обучения классификаторы можно использовать для применения меток конфиденциальности, политик соответствия требованиям связи и политик меток хранения. Использование классификаторов в политиках защиты от потери данных доступно в предварительной версии.
Дополнительные сведения о обучаемых классификаторах см. в статье Сведения о обучаемых классификаторах.
Использование идентифицированной конфиденциальной информации
После идентификации информации с помощью sit или классификатора (через сведения об аспектах данных Microsoft Purview), мы можем использовать эти знания, чтобы помочь нам в выполнении других трех основных принципов управления информацией Microsoft 365, а именно:
- Защита данных
- Предотвращение потери данных и
- Управление данными
В следующей таблице приведены преимущества и примеры того, как знание элемента, содержащего конфиденциальную информацию, может помочь в управлении информацией на платформе Microsoft 365.
| Возможность | Пример использования |
|---|---|
| Защита от потери данных | Помогает управлению, уменьшая риски утечки данных. |
| Метки конфиденциальности | Рекомендуется применить соответствующую метку конфиденциальности. После присвоения метки к информации применяются связанные с метками меры защиты. |
| Метки хранения | Автоматически применяет метку хранения, обеспечивая соответствие требованиям к управлению архивами или записями. |
| Обозреватель содержимого | Просмотр элементов, содержащих конфиденциальную информацию, в службах Microsoft 365, включая SharePoint, Teams, OneDrive и Exchange. |
| Управление внутренними рисками | Отслеживайте действия пользователей, связанные с конфиденциальной информацией, устанавливайте уровень риска пользователей на основе поведения и передавайте подозрительное поведение соответствующим командам. |
| Соответствие требованиям к обмену данными | Экранирование корреспонденции с высоким риском, включая любой чат или сообщение электронной почты, содержащие конфиденциальное или подозрительное содержимое. Соблюдение требований по вопросам коммуникации может помочь в обеспечении того, чтобы австралийское правительство выполнило обязательства по обеспечению удостоверения. |
| Microsoft Priva | Обнаружение хранения конфиденциальной информации, в том числе персональных данных, в таких расположениях, как OneDrive, и руководство пользователей по правильному хранению информации. |
| Обнаружение электронных данных | Наносите конфиденциальную информацию в рамках процессов отдела кадров или FOI и применяйте удержание к информации, которая может быть частью активного запроса или исследования. |
Обозреватель содержимого
Обозреватель содержимого Microsoft 365 позволяет сотрудникам по обеспечению соответствия требованиям, безопасности и конфиденциальности получить быструю, но исчерпывающую информацию о том, где хранится конфиденциальная информация в среде Microsoft 365. Это средство позволяет авторизованным пользователям просматривать расположения и элементы по типу информации. Служба индексирует и предоставляет элементы, находящиеся в Exchange, OneDrive и SharePoint. Элементы, расположенные на базовых сайтах групп SharePoint Teams, также видны.
С помощью этого средства мы можем выбрать тип конфиденциальной информации или метку конфиденциальности, просмотреть количество элементов, которые соответствуют ему в каждой из служб Microsoft 365:
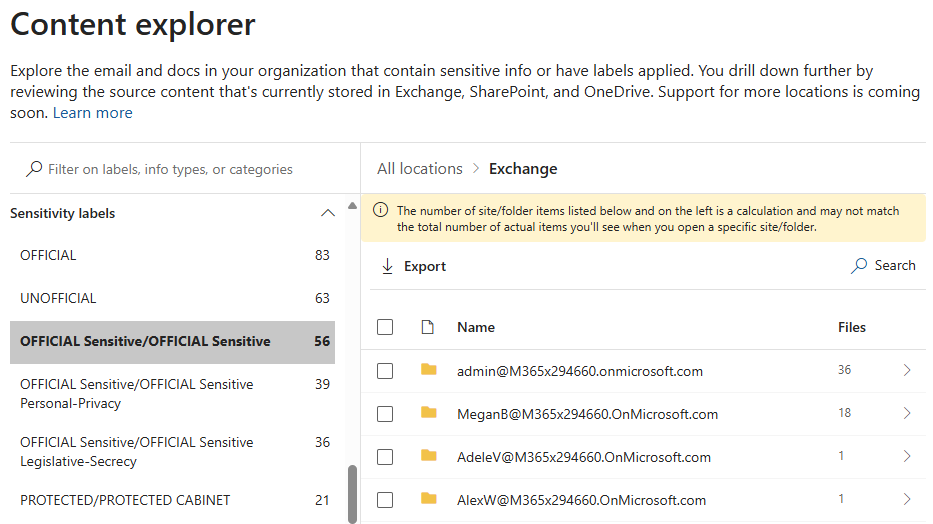
Обозреватель содержимого может предоставить ценные сведения о расположениях, в которых в среде находятся классифицированные или иным образом конфиденциальные элементы безопасности. Такое консолидированное представление о расположении информации вряд ли возможно через локальные системы.
Для организаций, которые включают метки, которые не разрешены в учетной записи организации (например, SECRET или TOP SECRET), а также связанные политики автоматического применения меток, обозреватель содержимого может найти сведения, которые не должны храниться на платформе. Так как обозреватель содержимого также может отображать SIT, аналогичный подход можно достичь с помощью SIT для выявления защитной маркировки.
Дополнительные сведения о Обозреватель содержимого см. в статье Начало работы с обозревателем содержимого.