Анализ данных с помощью Apache Spark
Из этого учебника вы узнаете, как выполнять исследовательский анализ данных с помощью Открытых наборов данных Azure и Apache Spark. Затем можно визуализировать результаты в записной книжке Synapse Studio в Azure Synapse Analytics.
В частности, вы проанализируете набор данных о такси Нью-Йорка. Данные доступны через открытые наборы данных Azure. Это подмножество набора данных содержит сведения о поездках на такси: информацию о каждой поездке, времени начала и окончания и расположениях, стоимости и других интересных атрибутах.
Подготовка к работе
Создайте пул Apache Spark, выполнив инструкции из этого руководства.
Скачивание и подготовка данных
Создайте записную книжку, используя ядро PySpark. Инструкции см. в разделе Создание записной книжки.
Примечание
Ядро PySpark позволяет не задавать контексты явным образом. Контекст Spark будет создан автоматически при выполнении первой ячейки кода.
В этом учебнике мы будем использовать несколько различных библиотек, которые помогут нам визуализировать набор данных. Чтобы выполнить этот анализ, импортируйте следующие библиотеки:
import matplotlib.pyplot as plt import seaborn as sns import pandas as pdТак как необработанные данные имеют формат Parquet, вы можете использовать контекст Spark, чтобы извлечь файл в память напрямую в виде кадра данных. Создайте DataFrame в Spark, получив данные с помощью API Открытых наборов данных. Здесь мы будем использовать свойства схемы при чтении для кадра данных Spark, чтобы определить типы и схему данных.
from azureml.opendatasets import NycTlcYellow from datetime import datetime from dateutil import parser end_date = parser.parse('2018-05-08 00:00:00') start_date = parser.parse('2018-05-01 00:00:00') nyc_tlc = NycTlcYellow(start_date=start_date, end_date=end_date) df = spark.createDataFrame(nyc_tlc.to_pandas_dataframe())После считывания данных необходимо выполнить начальную фильтрацию для очистки набора данных. При этом можно удалить ненужные столбцы и добавить те, в которые извлекаются важные сведения. Кроме того, необходимо отфильтровать аномалии в наборе данных.
# Filter the dataset from pyspark.sql.functions import * filtered_df = df.select('vendorID', 'passengerCount', 'tripDistance','paymentType', 'fareAmount', 'tipAmount'\ , date_format('tpepPickupDateTime', 'hh').alias('hour_of_day')\ , dayofweek('tpepPickupDateTime').alias('day_of_week')\ , dayofmonth(col('tpepPickupDateTime')).alias('day_of_month'))\ .filter((df.passengerCount > 0)\ & (df.tipAmount >= 0)\ & (df.fareAmount >= 1) & (df.fareAmount <= 250)\ & (df.tripDistance > 0) & (df.tripDistance <= 200)) filtered_df.createOrReplaceTempView("taxi_dataset")
Анализ данных
Аналитикам данных доступен широкий спектр средств, позволяющих извлекать ценные сведения из данных. В этой части учебника мы рассмотрим несколько полезных средств, доступных в записных книжках Azure Synapse Analytics. В результате этого анализа необходимо понять, какие факторы способствовали повышению чаевых за такси за выбранный период.
Магические команды Apache Spark SQL
Для начала мы выполним исследовательский анализ данных с помощью магических команд Apache Spark SQL, используя записную книжку Azure Synapse. После выполнения запроса мы визуализируем результаты с помощью встроенной возможности chart options.
В записной книжке создайте новую ячейку и скопируйте в нее следующий код. С помощью этого запроса мы хотим понять, как менялся средний размер чаевых в течение выбранного периода. Этот запрос также поможет нам определить другие аналитические сведения, в том числе минимальную и максимальную сумму чаевых в день и среднюю стоимость поездки.
%%sql SELECT day_of_month , MIN(tipAmount) AS minTipAmount , MAX(tipAmount) AS maxTipAmount , AVG(tipAmount) AS avgTipAmount , AVG(fareAmount) as fareAmount FROM taxi_dataset GROUP BY day_of_month ORDER BY day_of_month ASCПосле завершения выполнения запроса можно визуализировать результаты, переключившись на представление диаграммы. В этом примере для создания графика поле
day_of_monthзадается в качестве ключа, а полеavgTipAmount— в качестве значения. После выбора параметров нажмите кнопку Применить, чтобы обновить диаграмму.
Визуализируйте данные
Помимо встроенных параметров создания диаграмм для записных книжек, вы можете использовать популярные библиотеки с открытым кодом для создания собственных визуализаций. В следующих примерах мы будем использовать Seaborn и Matplotlib. Это часто используемые библиотеки Python для визуализации данных.
Примечание
По умолчанию каждый пул Apache Spark в Azure Synapse Analytics содержит набор часто используемых и стандартных библиотек. Полный список библиотек можно просмотреть в документации по среде выполнения Azure Synapse. Кроме того, чтобы сделать написанный сторонними или собственными разработчиками код доступным для приложений, можно установить библиотеку в одном из пулов Spark.
Чтобы упростить процесс разработки и снизить расходы, мы сократим этот набор данных. Для этого мы будем использовать встроенную возможность выборки Apache Spark. Кроме того, для Seaborn и Matplotlib требуется кадр данных Pandas или массив NumPy. Чтобы получить кадр данных Pandas, используйте команду
toPandas()для преобразования кадра данных.# To make development easier, faster, and less expensive, downsample for now sampled_taxi_df = filtered_df.sample(True, 0.001, seed=1234) # The charting package needs a Pandas DataFrame or NumPy array to do the conversion sampled_taxi_pd_df = sampled_taxi_df.toPandas()Нам необходимо понять, как распределены чаевые в нашем наборе данных. Мы будем использовать Matplotlib для создания гистограммы, показывающей распределение суммы чаевых и их количества. Распределение указывает на то, что суммы чаевых преимущественно не превышают 10 $.
# Look at a histogram of tips by count by using Matplotlib ax1 = sampled_taxi_pd_df['tipAmount'].plot(kind='hist', bins=25, facecolor='lightblue') ax1.set_title('Tip amount distribution') ax1.set_xlabel('Tip Amount ($)') ax1.set_ylabel('Counts') plt.suptitle('') plt.show()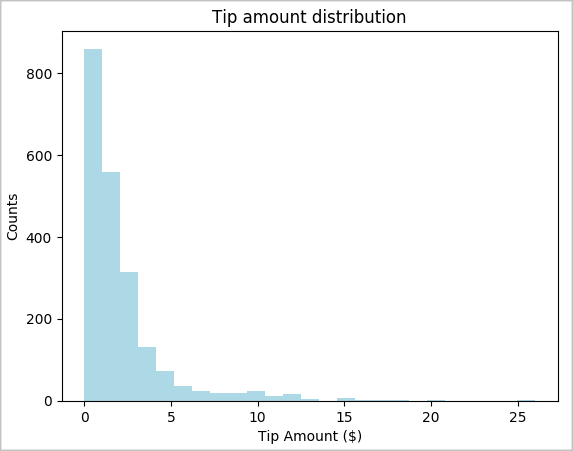
Далее мы хотим понять связь между чаевыми для определенной поездки и днем недели. Воспользуйтесь Seaborn, чтобы создать блочную диаграмму, на которой подытожены тенденции за каждый день недели.
# View the distribution of tips by day of week using Seaborn ax = sns.boxplot(x="day_of_week", y="tipAmount",data=sampled_taxi_pd_df, showfliers = False) ax.set_title('Tip amount distribution per day') ax.set_xlabel('Day of Week') ax.set_ylabel('Tip Amount ($)') plt.show()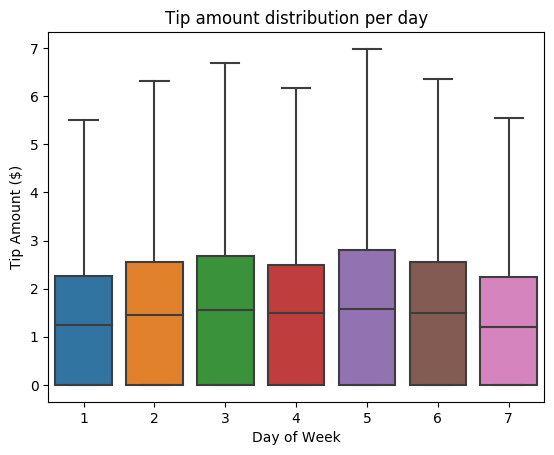
Другой гипотезой может быть наличие положительной связи между числом пассажиров и общей суммой чаевых за такси. Чтобы проверить эту связь, выполните следующий код, который создаст блочную диаграмму, иллюстрирующую распределение чаевых по числу пассажиров.
# How many passengers tipped by various amounts ax2 = sampled_taxi_pd_df.boxplot(column=['tipAmount'], by=['passengerCount']) ax2.set_title('Tip amount by Passenger count') ax2.set_xlabel('Passenger count') ax2.set_ylabel('Tip Amount ($)') ax2.set_ylim(0,30) plt.suptitle('') plt.show()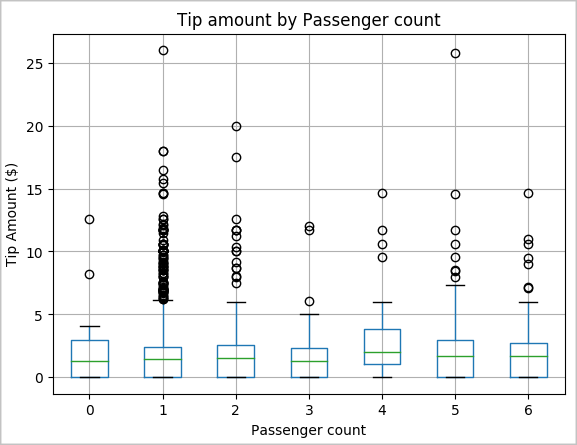
Наконец, мы хотим понять связь между стоимостью поездки и суммой чаевых. На основе результатов можно прийти к выводу, что наблюдается ряд ситуаций, в которых люди не дают чаевые. Однако также наблюдается положительная связь между общей стоимостью поездки и суммами чаевых.
# Look at the relationship between fare and tip amounts ax = sampled_taxi_pd_df.plot(kind='scatter', x= 'fareAmount', y = 'tipAmount', c='blue', alpha = 0.10, s=2.5*(sampled_taxi_pd_df['passengerCount'])) ax.set_title('Tip amount by Fare amount') ax.set_xlabel('Fare Amount ($)') ax.set_ylabel('Tip Amount ($)') plt.axis([-2, 80, -2, 20]) plt.suptitle('') plt.show()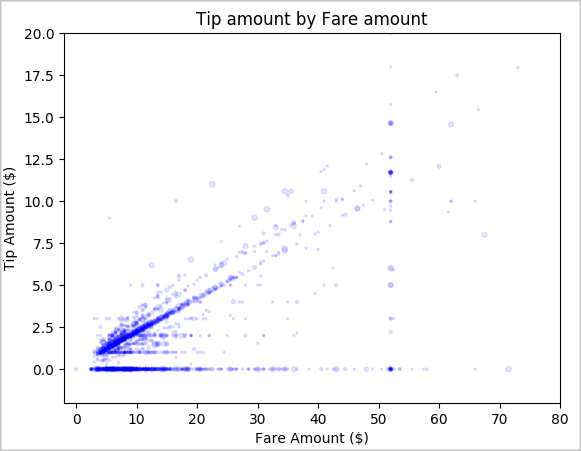
Завершение работы экземпляра Spark
По окончании использования приложения завершите работу записной книжки и освободите ресурсы. Можно закрыть вкладку или выбрать элемент Завершить сеанс в строке состояния в нижней части записной книжки.
См. также раздел
- Обзор: Apache Spark в Azure Synapse Analytics
- Создание модели машинного обучения с помощью Apache SparkML