Руководство. Создание приложения машинного обучения с помощью Apache Spark MLlib и Azure Synapse Analytics
В этой статье вы узнаете, как использовать Apache Spark MLlib для создания приложения машинного обучения, которое выполняет простой прогнозный анализ в открытом наборе данных Azure. Spark предоставляет встроенные библиотеки машинного обучения. В этом примере используется классификация с помощью логистической регрессии.
SparkML и MLlib — это основные библиотеки Spark, которые предоставляют множество служебных программ, полезных для задач машинного обучения, включая служебные программы, которые подходят для:
- Классификация
- Регрессия
- Кластеризация
- Моделирование тем
- Сингулярное разложение (SVD) и анализ главных компонентов (PCA)
- Тестирование гипотез и вычисление выборки статистики
Общие сведения о классификации и логистической регрессии
Классификация, популярная задача машинного обучения, — это процесс сортировки входных данных в категории. Это задание алгоритма классификации, чтобы выяснить, как назначать метки входным данным, которые вы предоставляете. Например, можно подумать о алгоритме машинного обучения, который принимает данные акций в качестве входных данных и делит акции на две категории: акции, которые следует продавать и акции, которые следует хранить.
Логистическая регрессия — это алгоритм, который можно использовать для классификации. API логистической регрессии Spark полезен для двоичной классификации или классификации входных данных в одну из двух групп. Дополнительные сведения о логистической регрессии см. в Википедии.
В итоге процесс логистической регрессии создает логистическую функцию , которую можно использовать для прогнозирования вероятности того, что входной вектор принадлежит одной группе или другой.
Пример прогнозного анализа данных такси Нью-Йорка
В этом примере вы используете Spark для выполнения некоторого прогнозного анализа данных советов по поездкам на такси из Нью-йорка. Данные доступны через открытые наборы данных Azure. Этот подмножество набора данных содержит сведения о желтых поездках на такси, включая сведения о каждой поездке, времени начала и окончания, стоимости и других интересных атрибутах.
Это важно
За извлечение этих данных из хранилища может взиматься дополнительная плата.
В следующих шагах вы разрабатываете модель для прогнозирования того, включает ли конкретная поездка подсказку или нет.
Создание модели машинного обучения Apache Spark
Создайте записную книжку, используя ядро PySpark. Инструкции см. в разделе Создание записной книжки.
Импортируйте типы, необходимые для этого приложения. Скопируйте и вставьте следующий код в пустую ячейку, а затем нажмите клавиши SHIFT+ВВОД. Или запустите ячейку с помощью синего значка воспроизведения слева от кода.
import matplotlib.pyplot as plt from datetime import datetime from dateutil import parser from pyspark.sql.functions import unix_timestamp, date_format, col, when from pyspark.ml import Pipeline from pyspark.ml import PipelineModel from pyspark.ml.feature import RFormula from pyspark.ml.feature import OneHotEncoder, StringIndexer, VectorIndexer from pyspark.ml.classification import LogisticRegression from pyspark.mllib.evaluation import BinaryClassificationMetrics from pyspark.ml.evaluation import BinaryClassificationEvaluatorЯдро PySpark позволяет не задавать контексты явным образом. Контекст Spark будет создан автоматически при выполнении первой ячейки кода.
Создание входного кадра данных
Так как необработанные данные имеют формат Parquet, вы можете использовать контекст Spark для извлечения файла в память непосредственно в качестве DataFrame. Хотя код в следующих шагах использует параметры по умолчанию, при необходимости можно принудительно сопоставить типы данных и другие атрибуты схемы.
Выполните следующие строки, чтобы создать кадр данных Spark, вставив код в новую ячейку. Этот шаг извлекает данные с помощью API Open Datasets. Извлечение всех этих данных создает около 1,5 миллиарда строк.
В зависимости от размера бессерверного пула Apache Spark необработанные данные могут быть слишком большими или занять слишком много времени для работы. Эти данные можно отфильтровать до меньшего размера. В следующем примере кода используется
start_dateиend_dateдля применения фильтра, возвращающего один месяц данных.from azureml.opendatasets import NycTlcYellow from datetime import datetime from dateutil import parser end_date = parser.parse('2018-05-08 00:00:00') start_date = parser.parse('2018-05-01 00:00:00') nyc_tlc = NycTlcYellow(start_date=start_date, end_date=end_date) filtered_df = spark.createDataFrame(nyc_tlc.to_pandas_dataframe())Недостатком простой фильтрации является то, что с статистической точки зрения она может привести к предвзятости в данные. Другой подход — использовать выборку, встроенную в Spark.
Следующий код сокращает набор данных примерно до 2000 строк, если он применяется после предыдущего кода. Этот шаг выборки можно использовать вместо простого фильтра или в сочетании с простым фильтром.
# To make development easier, faster, and less expensive, downsample for now sampled_taxi_df = filtered_df.sample(True, 0.001, seed=1234)Теперь можно посмотреть на данные, чтобы увидеть, что было прочитано. Обычно лучше просматривать данные с подмножеством, а не с полным набором в зависимости от размера набора данных.
Следующий код предлагает два способа просмотра данных. Первый способ — это базовый. Второй способ обеспечивает гораздо более широкий интерфейс сетки, а также возможность визуализации данных графически.
#sampled_taxi_df.show(5) display(sampled_taxi_df)В зависимости от размера созданного набора данных и необходимости экспериментировать или запускать записную книжку несколько раз, может потребоваться кэшировать набор данных локально в рабочей области. Существует три способа выполнения явного кэширования:
- Сохраните кадр данных локально в виде файла.
- Сохраните DataFrame как временную таблицу или представление.
- Сохраните DataFrame как постоянную таблицу.
Первые два из этих подходов включены в следующие примеры кода.
Создание временной таблицы или представления предоставляет различные пути доступа к данным, но созданная временная структура существует только в течение сеанса экземпляра Spark.
sampled_taxi_df.createOrReplaceTempView("nytaxi")
Подготовка данных
Данные в его необработанной форме часто не подходят для передачи непосредственно в модель. Необходимо выполнить ряд действий с данными, чтобы привести их в состояние, в котором модель может использовать их.
В следующем коде выполняется четыре класса операций:
- Удаление выбросов или неверных значений с помощью фильтрации.
- Удаление столбцов, которые не требуются.
- Создание новых столбцов, производных от необработанных данных, чтобы сделать модель более эффективной. Эта операция иногда называется признаковым представлением.
- Добавление меток. Так как вы выполняете двоичную классификацию (будут ли чаевые в данной поездке или нет), нужно преобразовать сумму чаевых в двоичное значение 0 или 1.
taxi_df = sampled_taxi_df.select('totalAmount', 'fareAmount', 'tipAmount', 'paymentType', 'rateCodeId', 'passengerCount'\
, 'tripDistance', 'tpepPickupDateTime', 'tpepDropoffDateTime'\
, date_format('tpepPickupDateTime', 'hh').alias('pickupHour')\
, date_format('tpepPickupDateTime', 'EEEE').alias('weekdayString')\
, (unix_timestamp(col('tpepDropoffDateTime')) - unix_timestamp(col('tpepPickupDateTime'))).alias('tripTimeSecs')\
, (when(col('tipAmount') > 0, 1).otherwise(0)).alias('tipped')
)\
.filter((sampled_taxi_df.passengerCount > 0) & (sampled_taxi_df.passengerCount < 8)\
& (sampled_taxi_df.tipAmount >= 0) & (sampled_taxi_df.tipAmount <= 25)\
& (sampled_taxi_df.fareAmount >= 1) & (sampled_taxi_df.fareAmount <= 250)\
& (sampled_taxi_df.tipAmount < sampled_taxi_df.fareAmount)\
& (sampled_taxi_df.tripDistance > 0) & (sampled_taxi_df.tripDistance <= 100)\
& (sampled_taxi_df.rateCodeId <= 5)
& (sampled_taxi_df.paymentType.isin({"1", "2"}))
)
Затем необходимо передать данные во второй раз, чтобы добавить окончательные функции.
taxi_featurised_df = taxi_df.select('totalAmount', 'fareAmount', 'tipAmount', 'paymentType', 'passengerCount'\
, 'tripDistance', 'weekdayString', 'pickupHour','tripTimeSecs','tipped'\
, when((taxi_df.pickupHour <= 6) | (taxi_df.pickupHour >= 20),"Night")\
.when((taxi_df.pickupHour >= 7) & (taxi_df.pickupHour <= 10), "AMRush")\
.when((taxi_df.pickupHour >= 11) & (taxi_df.pickupHour <= 15), "Afternoon")\
.when((taxi_df.pickupHour >= 16) & (taxi_df.pickupHour <= 19), "PMRush")\
.otherwise(0).alias('trafficTimeBins')
)\
.filter((taxi_df.tripTimeSecs >= 30) & (taxi_df.tripTimeSecs <= 7200))
Создание модели логистической регрессии
Последняя задача — преобразовать помеченные данные в формат, который можно проанализировать с помощью логистической регрессии. Входные данные алгоритма логистической регрессии должны быть набором пар векторов меток и признаков, где вектор признаков является вектором чисел, представляющих входную точку.
Поэтому необходимо преобразовать категориальные столбцы в числа. В частности, необходимо преобразовать столбцы trafficTimeBins и weekdayString в целочисленные представления. Существует несколько подходов к выполнению преобразования. В следующем примере OneHotEncoder используется подход, который является общим.
# Because the sample uses an algorithm that works only with numeric features, convert them so they can be consumed
sI1 = StringIndexer(inputCol="trafficTimeBins", outputCol="trafficTimeBinsIndex")
en1 = OneHotEncoder(dropLast=False, inputCol="trafficTimeBinsIndex", outputCol="trafficTimeBinsVec")
sI2 = StringIndexer(inputCol="weekdayString", outputCol="weekdayIndex")
en2 = OneHotEncoder(dropLast=False, inputCol="weekdayIndex", outputCol="weekdayVec")
# Create a new DataFrame that has had the encodings applied
encoded_final_df = Pipeline(stages=[sI1, en1, sI2, en2]).fit(taxi_featurised_df).transform(taxi_featurised_df)
Это действие приводит к созданию новой таблицы данных, в которой все столбцы находятся в нужном формате для обучения модели.
Обучение модели логистической регрессии
Первая задача — разделить набор данных на набор обучения и набор тестирования или проверки. Разделение здесь произвольно. Поэкспериментируйте с разными параметрами разделения, чтобы узнать, влияют ли они на модель.
# Decide on the split between training and testing data from the DataFrame
trainingFraction = 0.7
testingFraction = (1-trainingFraction)
seed = 1234
# Split the DataFrame into test and training DataFrames
train_data_df, test_data_df = encoded_final_df.randomSplit([trainingFraction, testingFraction], seed=seed)
Теперь, когда уже существуют две таблицы данных, следующая задача — создать формулу модели и применить ее к обучающей таблице данных. Затем можно провести проверку на тестовом DataFrame. Поэкспериментируйте с различными версиями формулы модели, чтобы увидеть влияние различных сочетаний.
Примечание.
Чтобы сохранить модель, назначьте роль Сотрудник данных хранилища Blob в объёме ресурсов сервера базы данных Azure SQL. Подробные инструкции см. в статье Назначение ролей Azure с помощью портала Microsoft Azure. Этот шаг может выполнять только члены с привилегиями владельца.
## Create a new logistic regression object for the model
logReg = LogisticRegression(maxIter=10, regParam=0.3, labelCol = 'tipped')
## The formula for the model
classFormula = RFormula(formula="tipped ~ pickupHour + weekdayVec + passengerCount + tripTimeSecs + tripDistance + fareAmount + paymentType+ trafficTimeBinsVec")
## Undertake training and create a logistic regression model
lrModel = Pipeline(stages=[classFormula, logReg]).fit(train_data_df)
## Saving the model is optional, but it's another form of inter-session cache
datestamp = datetime.now().strftime('%m-%d-%Y-%s')
fileName = "lrModel_" + datestamp
logRegDirfilename = fileName
lrModel.save(logRegDirfilename)
## Predict tip 1/0 (yes/no) on the test dataset; evaluation using area under ROC
predictions = lrModel.transform(test_data_df)
predictionAndLabels = predictions.select("label","prediction").rdd
metrics = BinaryClassificationMetrics(predictionAndLabels)
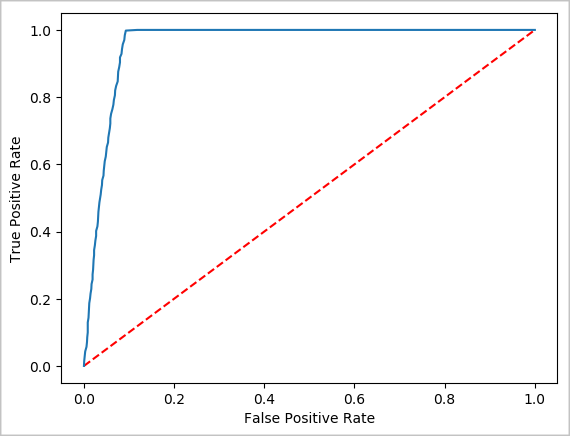
print("Area under ROC = %s" % metrics.areaUnderROC)
Выходные данные из этой ячейки:
Area under ROC = 0.9779470729751403
Создание визуального представления прогноза
Теперь можно создать окончательную визуализацию, чтобы помочь вам подумать о результатах этого теста. Кривая ROC является одним из способов проверки результата.
## Plot the ROC curve; no need for pandas, because this uses the modelSummary object
modelSummary = lrModel.stages[-1].summary
plt.plot([0, 1], [0, 1], 'r--')
plt.plot(modelSummary.roc.select('FPR').collect(),
modelSummary.roc.select('TPR').collect())
plt.xlabel('False Positive Rate')
plt.ylabel('True Positive Rate')
plt.show()
Завершение работы экземпляра Spark
После завершения работы приложения закройте записную книжку, чтобы освободить ресурсы, закрыв вкладку. Или выберите "Завершить сеанс" на панели состояния в нижней части записной книжки.