Диагностика распространенных сценариев с помощью Service Fabric
В этой статье показаны общие сценарии, с которыми сталкиваются пользователи в области мониторинга и диагностики с помощью Service Fabric. Представленные сценарии охватывают все три уровня service fabric: Application, Cluster и Infrastructure. Для каждого сценария каждое решение использует Application Insights, журналы Azure Monitor и средства мониторинга Azure. Шаги в каждом решении позволяют пользователям понять, как использовать Application Insights и журналы Azure Monitor в контексте Service Fabric.
Предварительные требования и рекомендации
Решения в этой статье используют следующие средства. Мы рекомендуем вам настроить следующую конфигурацию:
- Application Insights в Service Fabric.
- Включение диагностики Azure в кластере.
- Настройка рабочей области Log Analytics
- Агент Log Analytics для отслеживания счетчиков производительности
Как я могу увидеть необработанные исключения в своем приложении?
Перейдите к ресурсу Application Insights, с помощью которого настроено ваше приложение.
Выберите "Поиск " в левом верхнем углу. Затем выберите фильтр на следующей панели.
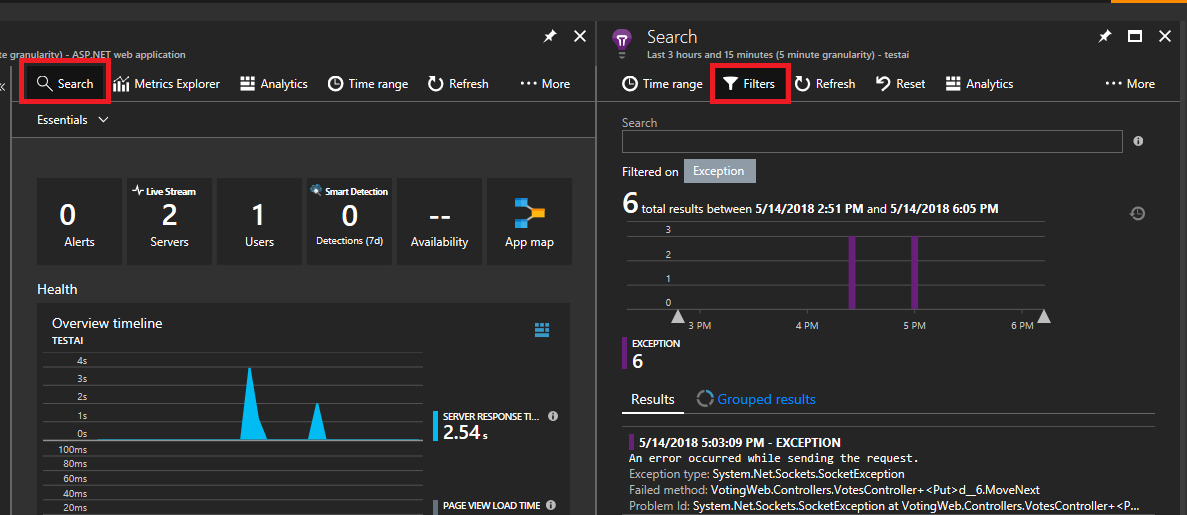
Вы увидите множество типов событий (трассировки, запросы, пользовательские события). Выберите "Исключение" в качестве фильтра.
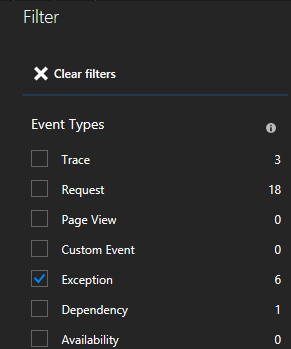
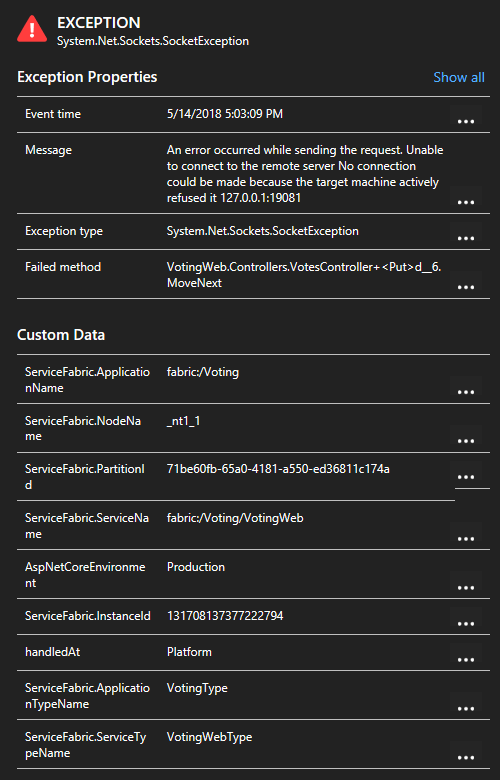
Щелкнув исключение в списке, вы можете просмотреть дополнительные сведения, включая контекст службы, если вы используете пакет SDK Для Application Insights Для Service Fabric.
Как просмотреть HTTP-вызовы, которые используются в моих службах?
В том же ресурсе Application Insights вы можете фильтровать запросы вместо исключений и просматривать все сделанные запросы.
Если вы используете пакет SDK Для Application Insights Service Fabric, вы увидите визуальное представление служб, подключенных друг к другу, и количество успешных и неудачных запросов. Слева выберите "Карта приложения"
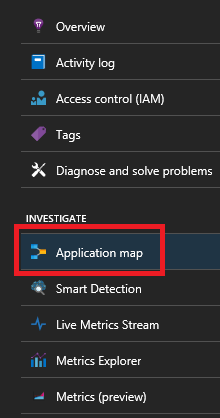
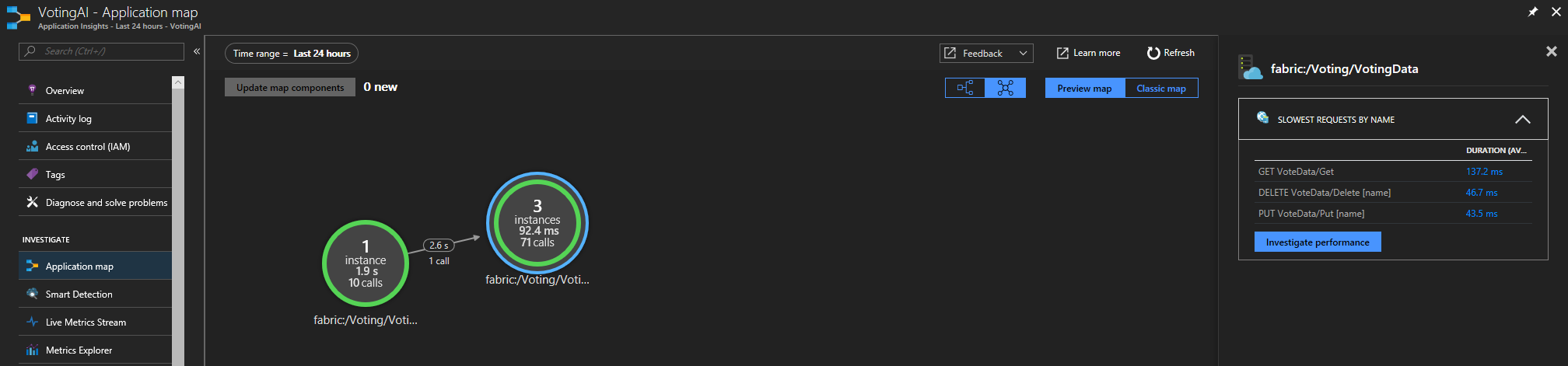
Дополнительные сведения о схеме приложения см. в документации по схеме приложения.
Как создать оповещение, когда узел выходит из строя
События узла отслеживаются кластером Service Fabric. Перейдите к ресурсу решения Аналитики Service Fabric с именем ServiceFabric (NameofResourceGroup)
Выберите граф в нижней части колонки с заголовком "Сводка"
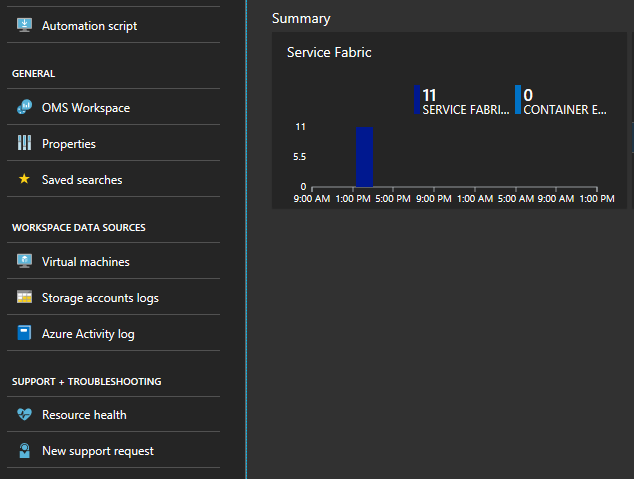
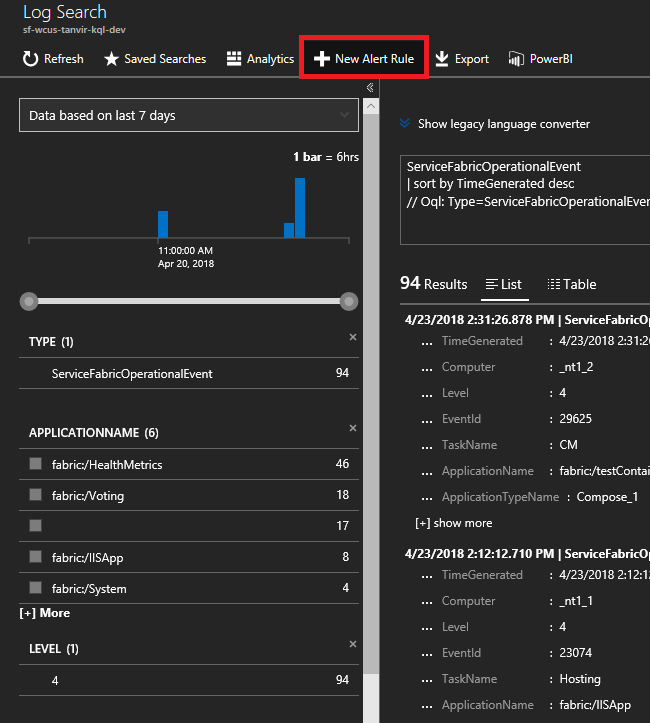
Здесь находится множество графиков и плиток, отображающих различные показатели. Выберите один из графов и перейдите к поиску по журналам. Здесь вы можете запросить любые события кластера или счетчики производительности.
Введите следующий запрос. Эти идентификаторы событий находятся в справке по событиям узла.
ServiceFabricOperationalEvent | where EventID >= 25622 and EventID <= 25626Выберите "Новое правило генерации оповещений" в верхней части и теперь в любой момент, когда событие поступает на основе этого запроса, вы получите оповещение в выбранном методе связи.
Как можно получить уведомления об откате обновления приложений?
В том же окне поиска по журналам, что и раньше, введите следующий запрос на откат обновления. Эти идентификаторы событий находятся в справке по событиям приложений.
ServiceFabricOperationalEvent | where EventID == 29623 or EventID == 29624Выберите "Новое правило генерации оповещений" в верхней части и теперь в любое время, когда событие поступает на основе этого запроса, вы получите оповещение.
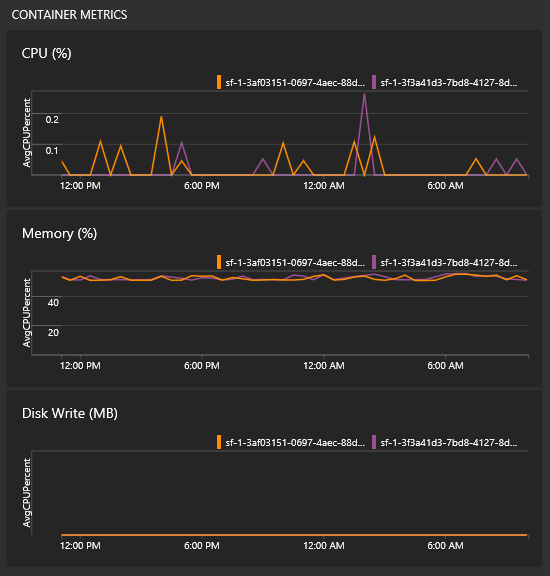
Как просмотреть метрики контейнера?
В одном представлении со всеми графами вы увидите некоторые плитки для производительности контейнеров. Для заполнения этих плиток вам потребуется агент Log Analytics и решение для мониторинга контейнеров.
Примечание.
Для телеметрии инструментирования внутри вашего контейнера вам нужно добавить пакет nuget Application Insights для контейнеров.
Как я могу контролировать счетчики производительности?
После того как вы добавили агент Log Analytics в свой кластер, вам нужно добавить определенные счетчики производительности, которые вы хотите отслеживать. Перейдите на страницу рабочей области Log Analytics на портале. На странице решения вкладка рабочей области находится в меню слева.
Когда вы находитесь на странице рабочей области, выберите "Дополнительные параметры" в том же левом меню.
Выберите счетчики производительности Windows данных > (счетчики производительности Linux для > компьютеров Linux), чтобы начать сбор определенных счетчиков с узлов с помощью агента Log Analytics. Вот примеры формата добавления счетчиков
.NET CLR Memory(<ProcessNameHere>)\\# Total committed BytesProcessor(_Total)\\% Processor TimeВ этом кратком руководстве именами процессов являются VotingData и VotingWeb, поэтому отслеживание этих счетчиков будет выглядеть так:
.NET CLR Memory(VotingData)\\# Total committed Bytes.NET CLR Memory(VotingWeb)\\# Total committed Bytes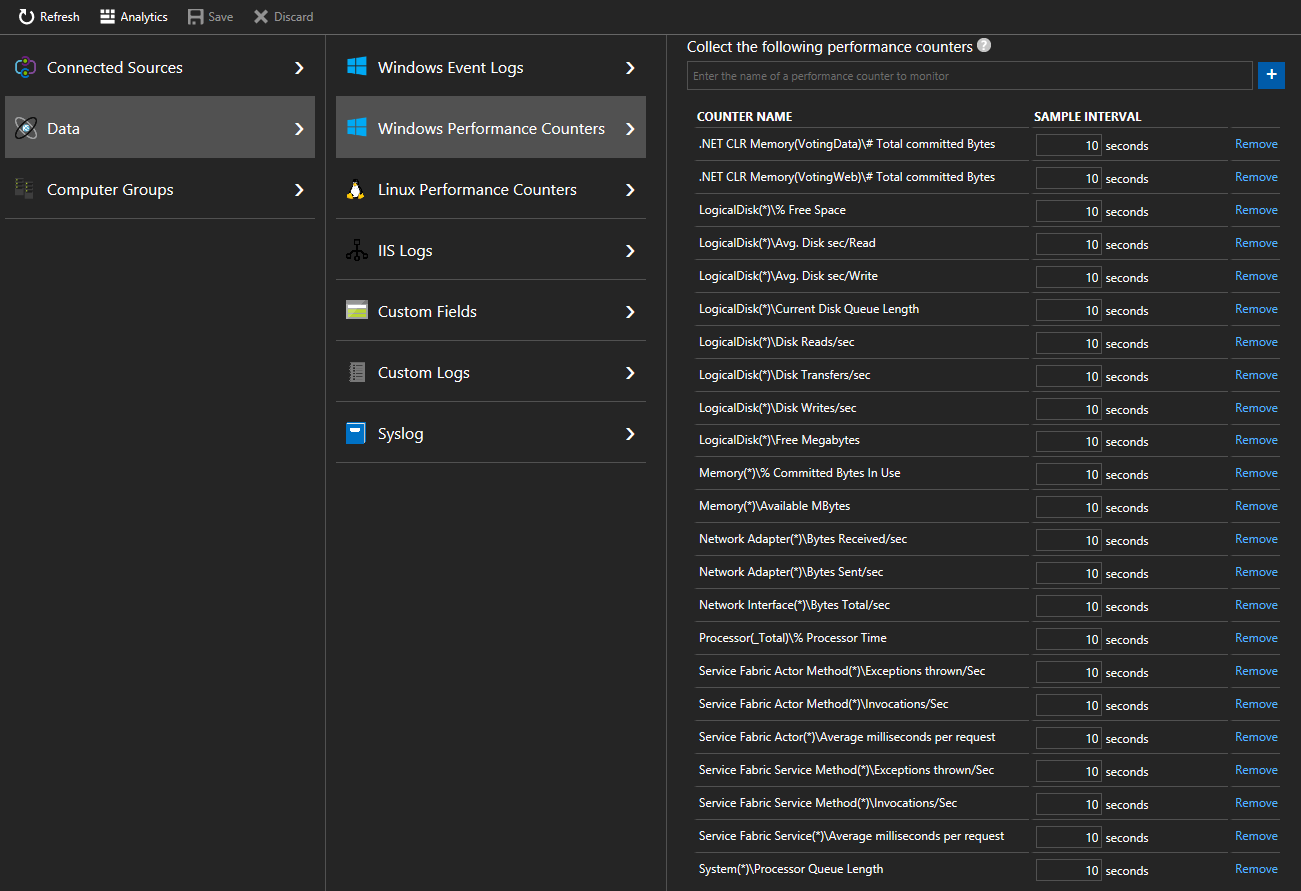
Это позволяет узнать, как инфраструктура обрабатывает рабочие нагрузки, а также задать соответствующие оповещения на основе использования ресурсов. Например, вы можете задать оповещение, если общий объем использования процессора превышает 90% или ниже 5%. Имя счетчика, которое вы использовали для этого, — % Processor Time. Вы можете сделать это, создав правило оповещения для следующего запроса:
Perf | where CounterName == "% Processor Time" and InstanceName == "_Total" | where CounterValue >= 90 or CounterValue <= 5.
Как отслеживать работу моих Reliable Services и субъектов?
Чтобы отслеживать эффективность Reliable Services или субъектов в ваших приложениях, вы должны также собирать данные со счетчиков субъекта Service Fabric, метода субъекта, службы и метода службы. Ниже приведены примеры счетчиков производительности Reliable Services и субъектов, с которых необходимо собирать данные.
Примечание.
В настоящее время агент Log Analytics не может собирать данные со счетчиков производительности Service Fabric, но это могут делать другие диагностические решения
Service Fabric Service(*)\\Average milliseconds per requestService Fabric Service Method(*)\\Invocations/SecService Fabric Actor(*)\\Average milliseconds per requestService Fabric Actor Method(*)\\Invocations/Sec
Проверьте полный список счетчиков производительности по этим ссылкам Reliable Services и Субъекты.
Следующие шаги
- Поиск распространенных ошибок активации пакетов кода
- Настройте оповещения в Application Insights, чтобы узнавать об изменениях в производительности или характере использования.
- Интеллектуальное обнаружение в Application Insights осуществляет упреждающий анализ данных телеметрии, отправляемых в Application Insights, и предупреждает о потенциальных проблемах с производительностью.
- Узнайте больше об оповещениях Azure Monitor, которые помогут в обнаружении и диагностике.
- Для локальных кластеров журналы Azure Monitor предлагают шлюз (прокси-сервер переадресации HTTP), который можно использовать для отправки данных в журналы Azure Monitor. Дополнительные сведения см. в разделе Подключение компьютеров к журналам Azure Monitor с помощью шлюза Log Analytics без доступа к Интернету
- Ознакомьтесь с функциями поиска по журналам и запросов к журналам, которые являются частью журналов Azure Monitor
- Подробные сведения о журналах Azure Monitor и их предложениях см. в статье "Что такое журналы Azure Monitor?