Секционирование служб Reliable Services в Service Fabric
В этой статье рассматриваются основные понятия, связанные с секционированием служб Reliable Services в инфраструктуре Azure Service Fabric. Секционирование позволяет хранить данные на локальных компьютерах, что дает возможность одновременно масштабировать данные и вычислительные ресурсы.
Совет
Полный пример кода для этой статьи размещен на сайте GitHub.
Секционирование
Секционирование не является уникальной особенностью Service Fabric. По сути, это основной способ создания масштабируемых служб. В более широком смысле понятие секционирования означает разбивку состояния (данных) и вычисления на более мелкие единицы для повышения производительности и улучшения масштабируемости. Распространенный пример секционирования — это секционирование данных, которое еще называют сегментированием.
Секционирование служб без отслеживания состояния в Service Fabric
В случае со службами без отслеживания состояния секцию можно описать как логическую единицу, содержащую один или несколько экземпляров службы. На рис. 1 показана служба без отслеживания состояния с пятью экземплярами, распределенными в кластере и объединенными в одну секцию.
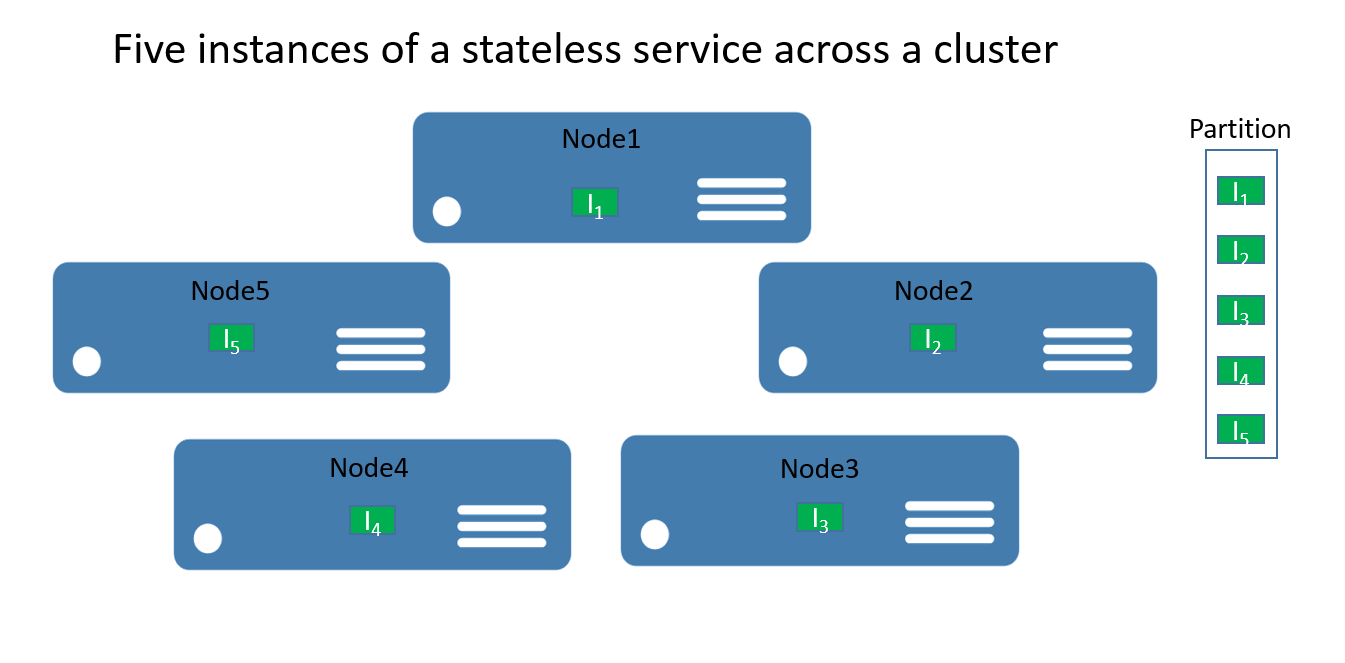
Есть два типа решений служб без отслеживания состояния. Первый — это служба, которая хранит свое состояние во внешней системе, например в базе данных Базы данных SQL Azure (например, данные и сведения о сеансе для веб-сайта). Второй — только вычислительные службы (например, калькулятор или создание эскизов для изображений), которые не управляют устойчивыми состояниями.
Секционирование служб без отслеживания состояния выполняется очень редко. поэтому секционирование таких служб уместно лишь тогда, когда вам нужно выполнять особые запросы на маршрутизацию.
Примером может быть случай, когда пользователи с идентификаторами из определенного диапазона должны обслуживаться только определенным экземпляром службы. Вот еще один пример, когда может потребоваться секционирование службы без отслеживания состояния. У вас есть по-настоящему секционированный сервер (например, сегментированная база данных в Базе данных SQL), и вы хотите управлять записью экземпляров службы в определенные сегменты базы данных или выполнять другие подготовительные задачи в рамках службы без отслеживания состояния, для которых требуются те же сведения о секционировании, которые используются на сервере. Подобные сценарии также можно решить другими способами, не требующими секционирования службы.
Оставшаяся часть этого пошагового руководства посвящена службам с отслеживанием состояния.
Секционирование служб с отслеживанием состояния в Service Fabric
Service Fabric упрощает процесс разработки масштабируемых служб с отслеживанием состояния, предоставляя лучший способ секционирования состояния (данных). По сути, секция службы с отслеживанием состояния является единицей масштабирования, высокую надежность которой обеспечивают реплики , равномерно распределяющиеся между узлами кластера.
В контексте служб Service Fabric с отслеживанием состояния секционирование — это процесс определения секции службы, которая отвечает за определенную часть полного состояния службы. (Как уже говорилось ранее, секция представляет собой набор реплик.) Service Fabric размещает секции на разных узлах. Из-за этого размер секции может увеличиваться в пределах ресурса узла. По мере роста объема данных размер секций увеличивается, и Service Fabric перераспределяет секции между узлами. Таким образом, аппаратные ресурсы постоянно используются с максимальной эффективностью.
Рассмотрим это все на примере. Предположим, у нас есть кластер из пяти узлов и служба, которая должна иметь десять секций и три реплики. В этом случае Service Fabric распределит реплики в кластере так, что мы получим по две первичные реплики на каждом узле. Если масштаб кластера горизонтально увеличится до десяти узлов, Service Fabric перераспределит первичные реплики между десятью узлами. Если количество узлов в кластере снова уменьшится до пяти, все реплики опять будут перераспределены между пятью узлами.
На рис. 2 показано распределение десяти разделов до и после масштабирования в кластере.
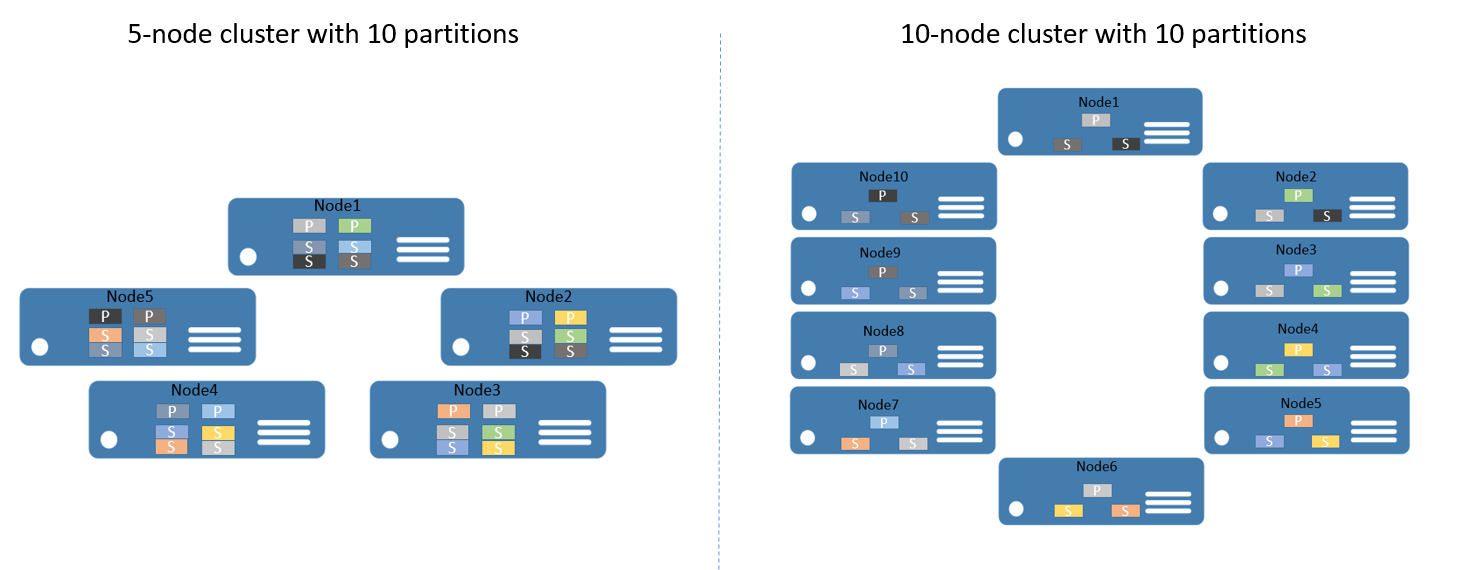
В итоге мы получаем увеличение масштаба, при котором запросы от клиентов распределяются между компьютерами. Повышается общая производительность приложения, а конкуренция за доступ к блокам данных уменьшается.
Планирование секционирования
Прежде чем создавать службу, всегда продумывайте стратегию секционирования с возможностью ее масштабирования. Для этого есть несколько методов, каждый из которых нацелен на определенные потребности приложения. В этой статье мы затронем некоторые наиболее важные аспекты.
Сначала следует подумать о структуре состояния, которое нужно секционировать.
Давайте рассмотрим простой пример. Предположим, вам нужно создать службу для обработки результатов выборов в округе. Для каждого города в округе вы создаете отдельную секцию. Затем в секции вы сохраняете голоса каждого человека в городе, который относится к соответствующей секции. На рис. 3 приведен набор людей и городов, в которых они находятся.
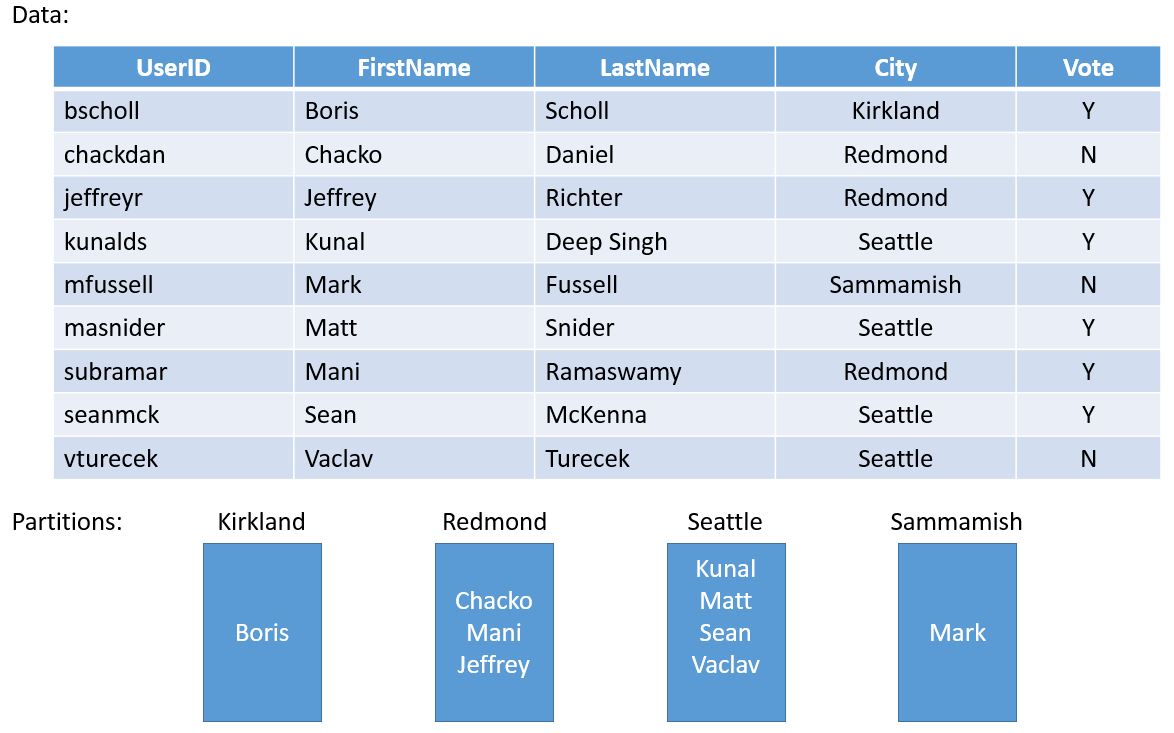
Так как население городов значительно отличается, в итоге может оказаться, что некоторые секции содержат большое количество данных (например, Сиэтл), а другие — незначительное (например, Кирклэнд). Каковы последствия наличия разделов с неравномерным состоянием?
Нетрудно заметить, что секция, которая содержит голоса для Сиэтла, будет получать больше трафика, чем секция для Кирклэнда. По умолчанию Service Fabric следит за тем, чтобы на каждом узле было примерно одинаковое количество первичных и вторичных реплик. Поэтому у вас могут получиться узлы, реплики на которых обслуживают разный объем трафика. Желательно избегать таких чрезмерно активных и пассивных участков в кластере.
Вот две рекомендации, как избежать такой ситуации.
- Старайтесь секционировать состояние так, чтобы оно равномерно распределялось между всеми разделами.
- Загрузите отчеты из каждой реплики для службы. (Чтобы узнать, как это сделать, прочитайте эту статью о метриках и загрузке.) В Service Fabric есть возможность сообщать о нагрузке, создаваемой службами, по таким показателям, как объем памяти или число записей. На основе полученных метрик Service Fabric определяет, какие секции загружены больше, чем другие. Затем платформа перераспределяет реплики в кластере, перемещая их на более подходящие узлы, чтобы ни один из узлов не был перегружен.
В некоторых случаях невозможно заранее определить, какой объем данных будет в той или иной секции. Поэтому обычно рекомендуется использовать оба подхода: разработать стратегию секционирования, согласно которой данные будут равномерно распределяться между секциями, и использовать сведения о нагрузке. Первый способ предотвращает ситуации, описанные в примере с опросом, тогда как второй помогает сгладить временную разницу в доступе или загрузке.
Другим аспектом планирования секционирования является выбор правильного количества разделов. В Service Fabric нет никаких ограничений относительно использования большего количества секций, чем требуется для тех или иных целей. Задать максимальное количество — вполне допустимый подход.
Большее количество секций, чем выбрано изначально, может понадобиться в редких случаях. Так как изменять выбранное количество секций нельзя, вам придется прибегнуть к дополнительным методам секционирования, в частности создать новый экземпляр службы того же типа. Кроме того, вам нужно будет внедрить клиентскую логику, которая будет направлять запросы к правильному экземпляру службы на основе сведений, которыми располагает клиент (в клиентском коде должна быть реализована соответствующая поддержка).
При планировании секционирования вам также необходимо учитывать доступные ресурсы компьютеров. Так как состояние нужно не только хранить, но и получать к нему доступ, вам нужно учитывать следующие ограничения:
- пропускная способность сети;
- память системы;
- место на диске.
Что произойдет, если во время работы кластера возникнут проблемы ограничения ресурсов? Ответ прост: масштаб кластера можно горизонтально увеличить в соответствии с новыми требованиями.
Руководство по планированию емкости поможет определить требуемое количество узлов в кластере.
Начало секционирования
В этом разделе описывается, как секционировать службу.
В Service Fabric можно выбрать одну из трех возможных схем секционирования.
- Секционирование по диапазонам значений (также известное как UniformInt64Partition).
- Секционирование по именам. Как правило, данные приложений, которые используют эту модель, можно поместить в контейнер в рамках ограниченного набора данных. Вот некоторые наиболее распространенные примеры полей данных, которые используются в качестве ключей для секционирования по именам: регионы, почтовые индексы, группы клиентов и др.
- Одноэлементное секционирование. Одноэлементное секционирование обычно используется, если служба не требует дополнительной маршрутизации. Например, службы без отслеживания состояния используют эту схему секционирования по умолчанию.
Схемы секционирования по именам и одноэлементного секционирования являются особыми формами секционирования по диапазонам. По умолчанию в шаблонах Visual Studio для Service Fabric используется секционирование по диапазонам, так как оно является наиболее распространенным и практичным. В оставшейся части этой статьи рассматривается схема секционирования по диапазонам.
Схема секционирования по диапазонам
Она используется для указания целочисленного диапазона (определенного низким и высоким ключами) и количества секций (n). Создается n разделов, каждый из которых отвечает за неперекрывающийся поддиапазон всего диапазона ключей раздела. Например, схема секционирования по диапазонам, в которой нижний ключ равен 0, верхний ключ равен 99, а количество секций равно 4, создаст четыре секции, как показано ниже.
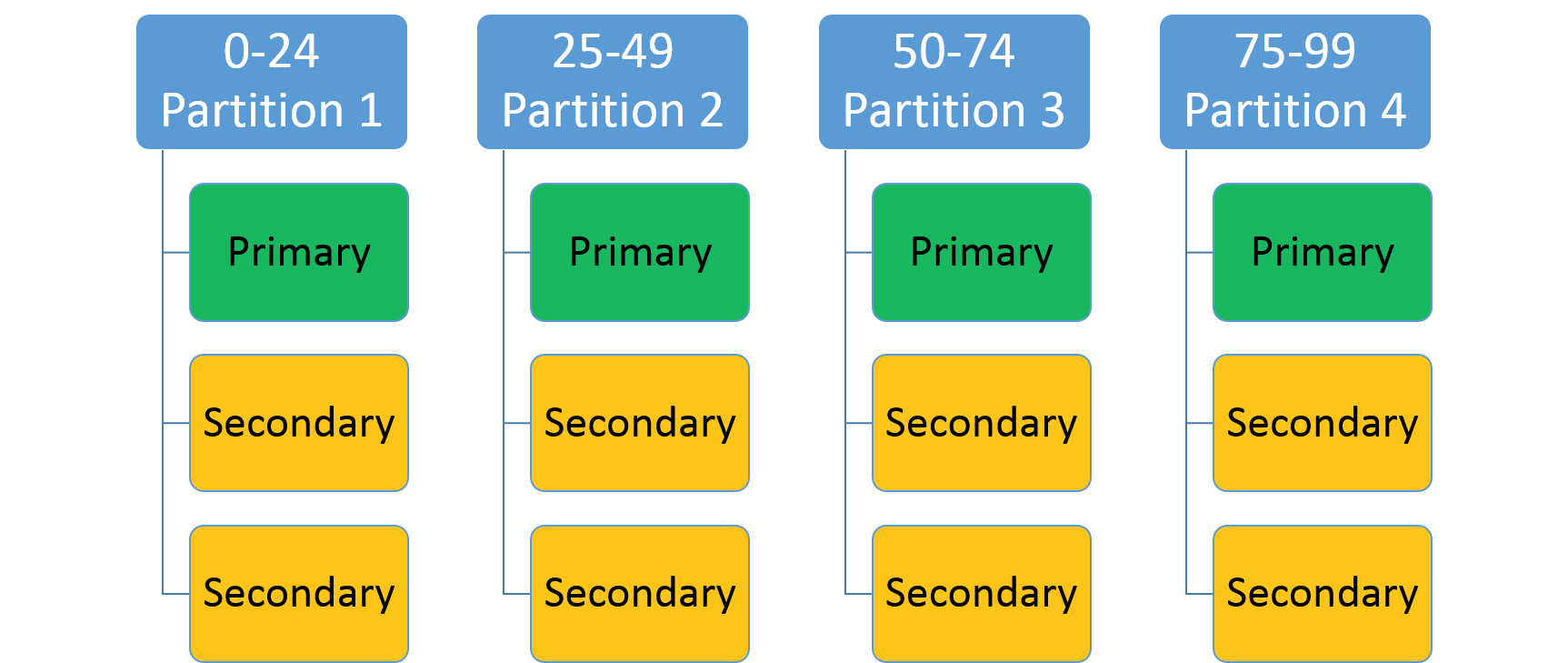
Наиболее распространенным приемом является создание хэша на основе уникального ключа в наборе данных. Вот некоторые наиболее распространенные примеры ключей: код идентификации транспортного средства (VIN), идентификатор сотрудника, уникальная строка и пр. Используя этот уникальный ключ, вы создаете хэш-код, модуль диапазона ключей, который будет использоваться как ключ. Для допустимого диапазона ключей можно указать верхнюю и нижнюю границы.
Выбор хэш-алгоритма
Важной частью хэширования является выбор хэш-алгоритма. Вам необходимо решить следующее: следует ли группировать одинаковые ключи рядом друг с другом (хэширование с учетом местоположения) или распределить действия по всем секциям (хэширование с распределением). Последний алгоритм используется чаще.
Хороший хэш-алгоритм с распределением отличается простотой вычисления, небольшим количеством конфликтов и равномерным распределением ключей. Примером эффективного хэш-алгоритма является FNV-1 .
Хороший выбор общих хэш-алгоритмов представлен в Википедии на странице, посвященной хэш-функциям.
Создание службы с отслеживанием состояния с несколькими секциями
Далее вы создадите свою первую службу Reliable Services с отслеживанием состояния с несколькими разделами. В приведенном ниже примере мы создадим очень простое приложение, в каждой секции которого будут храниться фамилии, начинающиеся с определенной буквы.
Прежде чем приступать к написанию кода, следует определиться с секциями и их ключами. Нам потребуется 26 секций — по одной для каждой буквы английского алфавита. Но как определить нижнюю и верхнюю границы ключей? Нам нужно иметь по одной секции на каждую букву. Следовательно, мы можем использовать 0 в качестве нижнего ключа и 25 — в качестве верхнего, так как каждая буква выступает собственным ключом.
Примечание.
Это упрощенный сценарий, так как на самом деле распределение было бы неравномерным. Фамилии, начинающиеся с буквы S или M, встречаются чаще, чем те, которые начинаются с X или Y.
Выберите Visual Studio>Файл>Создать>Проект.
В диалоговом окне Создание проекта выберите приложение Service Fabric.
Назовите проект AlphabetPartitions.
В диалоговом окне Создание службы выберите службу с отслеживанием состояния и назовите ее Alphabet.Processing.
Укажите количество секций. Откройте файл ApplicationManifest.xml в папке ApplicationPackageRoot проекта AlphabetPartitions и обновите параметр Processing_PartitionCount до 26, как показано ниже.
<Parameter Name="Processing_PartitionCount" DefaultValue="26" />Кроме того, в элементе StatefulService в ApplicationManifest.xml нужно изменить свойства LowKey и HighKey, как показано ниже.
<Service Name="Alphabet.Processing"> <StatefulService ServiceTypeName="Alphabet.ProcessingType" TargetReplicaSetSize="[Processing_TargetReplicaSetSize]" MinReplicaSetSize="[Processing_MinReplicaSetSize]"> <UniformInt64Partition PartitionCount="[Processing_PartitionCount]" LowKey="0" HighKey="25" /> </StatefulService> </Service>Чтобы сделать службу доступной, откройте конечную точку на порте. Для этого добавьте для службы Alphabet.Processing элемент конечной точки из файла ServiceManifest.xml (расположен в папке PackageRoot), как показано ниже.
<Endpoint Name="ProcessingServiceEndpoint" Port="8089" Protocol="http" Type="Internal" />Теперь служба настроена на прослушивание внутренней конечной точки в 26 разделах.
Далее нужно переопределить метод
CreateServiceReplicaListeners()класса Processing.Примечание.
В этом примере предполагается, что вы используете простой прослушиватель HttpCommunicationListener. Дополнительные сведения о модели взаимодействия Reliable Services см. в этой статье.
URL-адрес, который реплика использует для ожидания передачи данных, рекомендуется указывать в таком формате:
{scheme}://{nodeIp}:{port}/{partitionid}/{replicaid}/{guid}. Таким образом, вам нужно настроить прослушиватель на правильные конечные точки, используя именно этот шаблон.На одном компьютере может быть размещено несколько реплик этой службы, поэтому адрес должен быть уникальным для каждой реплики. Именно по этой причине в URL-адресе указываются идентификаторы секции и реплики. HttpListener может прослушивать несколько адресов на одном порту при условии, что префикс URL-адреса является уникальным.
Дополнительный GUID используется в сложных случаях, когда вторичные реплики также прослушивают запросы только для чтения. Если это так, следует убедиться, что новый уникальный адрес используется при переходе от первичной реплики к вторичной для принудительного разрешения адресов клиентами. Здесь в качестве адреса используется "+", чтобы реплика прослушивала все доступные узлы (IP-адрес, полное доменное имя, localhost и т. д.). Ниже приводится пример кода.
protected override IEnumerable<ServiceReplicaListener> CreateServiceReplicaListeners() { return new[] { new ServiceReplicaListener(context => this.CreateInternalListener(context))}; } private ICommunicationListener CreateInternalListener(ServiceContext context) { EndpointResourceDescription internalEndpoint = context.CodePackageActivationContext.GetEndpoint("ProcessingServiceEndpoint"); string uriPrefix = String.Format( "{0}://+:{1}/{2}/{3}-{4}/", internalEndpoint.Protocol, internalEndpoint.Port, context.PartitionId, context.ReplicaOrInstanceId, Guid.NewGuid()); string nodeIP = FabricRuntime.GetNodeContext().IPAddressOrFQDN; string uriPublished = uriPrefix.Replace("+", nodeIP); return new HttpCommunicationListener(uriPrefix, uriPublished, this.ProcessInternalRequest); }Также следует отметить, что опубликованный URL-адрес немного отличается от префикса URL-адреса прослушивания. URL-адрес прослушивания назначается HttpListener. Опубликованный URL-адрес — это URL-адрес, опубликованный в службе именования Service Fabric, который используется для обнаружения службы. Клиенты будут запрашивать этот адрес с помощью службы обнаружения. Адрес, который получают клиенты, должен содержать фактический IP-адрес или полное доменное имя узла (в противном случае подключение будет невозможно). Поэтому вам нужно вместо символа «+» указать IP-адрес или полное доменное имя, как показано выше.
Последним шагом является добавление логики обработки к службе, как показано ниже.
private async Task ProcessInternalRequest(HttpListenerContext context, CancellationToken cancelRequest) { string output = null; string user = context.Request.QueryString["lastname"].ToString(); try { output = await this.AddUserAsync(user); } catch (Exception ex) { output = ex.Message; } using (HttpListenerResponse response = context.Response) { if (output != null) { byte[] outBytes = Encoding.UTF8.GetBytes(output); response.OutputStream.Write(outBytes, 0, outBytes.Length); } } } private async Task<string> AddUserAsync(string user) { IReliableDictionary<String, String> dictionary = await this.StateManager.GetOrAddAsync<IReliableDictionary<String, String>>("dictionary"); using (ITransaction tx = this.StateManager.CreateTransaction()) { bool addResult = await dictionary.TryAddAsync(tx, user.ToUpperInvariant(), user); await tx.CommitAsync(); return String.Format( "User {0} {1}", user, addResult ? "successfully added" : "already exists"); } }ProcessInternalRequestсчитывает значения параметра строки запроса, который используется для вызова раздела, и вызывает методAddUserAsyncдля добавления lastname в надежный словарьdictionary.Добавим в проект службу без отслеживания состояния, чтобы посмотреть, как можно вызвать определенный раздел.
Эта служба выступает в качестве простого веб-интерфейса, который принимает фамилию как параметр строки запроса, определяет ключ секции и отправляет его на обработку в службу Alphabet.Processing.
В диалоговом окне Создание службы выберите службу без отслеживания состояния и назовите ее Alphabet.Web, как показано ниже.
 .
.Откройте порт, изменив сведения о конечной точке в файле ServiceManifest.xml службы Alphabet.WebApi, как показано ниже.
<Endpoint Name="WebApiServiceEndpoint" Protocol="http" Port="8081"/>Необходимо вернуть коллекцию ServiceInstanceListeners в класс Web. Опять же, вы можете реализовать простой прослушиватель HttpCommunicationListener.
protected override IEnumerable<ServiceInstanceListener> CreateServiceInstanceListeners() { return new[] {new ServiceInstanceListener(context => this.CreateInputListener(context))}; } private ICommunicationListener CreateInputListener(ServiceContext context) { // Service instance's URL is the node's IP & desired port EndpointResourceDescription inputEndpoint = context.CodePackageActivationContext.GetEndpoint("WebApiServiceEndpoint") string uriPrefix = String.Format("{0}://+:{1}/alphabetpartitions/", inputEndpoint.Protocol, inputEndpoint.Port); var uriPublished = uriPrefix.Replace("+", FabricRuntime.GetNodeContext().IPAddressOrFQDN); return new HttpCommunicationListener(uriPrefix, uriPublished, this.ProcessInputRequest); }Теперь нам необходимо реализовать логику обработки. После получения запроса прослушиватель HttpCommunicationListener вызывает
ProcessInputRequest, поэтому давайте добавим приведенный ниже код.private async Task ProcessInputRequest(HttpListenerContext context, CancellationToken cancelRequest) { String output = null; try { string lastname = context.Request.QueryString["lastname"]; char firstLetterOfLastName = lastname.First(); ServicePartitionKey partitionKey = new ServicePartitionKey(Char.ToUpper(firstLetterOfLastName) - 'A'); ResolvedServicePartition partition = await this.servicePartitionResolver.ResolveAsync(alphabetServiceUri, partitionKey, cancelRequest); ResolvedServiceEndpoint ep = partition.GetEndpoint(); JObject addresses = JObject.Parse(ep.Address); string primaryReplicaAddress = (string)addresses["Endpoints"].First(); UriBuilder primaryReplicaUriBuilder = new UriBuilder(primaryReplicaAddress); primaryReplicaUriBuilder.Query = "lastname=" + lastname; string result = await this.httpClient.GetStringAsync(primaryReplicaUriBuilder.Uri); output = String.Format( "Result: {0}. <p>Partition key: '{1}' generated from the first letter '{2}' of input value '{3}'. <br>Processing service partition ID: {4}. <br>Processing service replica address: {5}", result, partitionKey, firstLetterOfLastName, lastname, partition.Info.Id, primaryReplicaAddress); } catch (Exception ex) { output = ex.Message; } using (var response = context.Response) { if (output != null) { output = output + "added to Partition: " + primaryReplicaAddress; byte[] outBytes = Encoding.UTF8.GetBytes(output); response.OutputStream.Write(outBytes, 0, outBytes.Length); } } }Давайте разберемся в процессе, шаг за шагом. Код считывает первую букву из параметра строки запроса в
lastnameв тип char. Затем он определяет ключ раздела для этой буквы, вычитая шестнадцатеричное значениеAиз шестнадцатеричного значения первой буквы фамилии.string lastname = context.Request.QueryString["lastname"]; char firstLetterOfLastName = lastname.First(); ServicePartitionKey partitionKey = new ServicePartitionKey(Char.ToUpper(firstLetterOfLastName) - 'A');Напоминаем, что в этом примере мы используем 26 секций с одним ключом на секцию. Далее для этого ключа мы получаем секцию службы
partition. Для этого мы используем методResolveAsyncв объектеservicePartitionResolver.servicePartitionResolverопределяется так:private readonly ServicePartitionResolver servicePartitionResolver = ServicePartitionResolver.GetDefault();В качестве параметров метод
ResolveAsyncпринимает универсальный код ресурса (URI) службы, ключ секции и маркер отмены. URI службы обработки выглядит так:fabric:/AlphabetPartitions/Processing. Далее мы получаем конечную точку секции.ResolvedServiceEndpoint ep = partition.GetEndpoint()В самом конце мы создаем URL-адрес конечной точки и строку запроса и обращаемся к службе обработки.
JObject addresses = JObject.Parse(ep.Address); string primaryReplicaAddress = (string)addresses["Endpoints"].First(); UriBuilder primaryReplicaUriBuilder = new UriBuilder(primaryReplicaAddress); primaryReplicaUriBuilder.Query = "lastname=" + lastname; string result = await this.httpClient.GetStringAsync(primaryReplicaUriBuilder.Uri);После выполнения обработки пишем вывод.
Последним шагом будет тестирование службы. Visual Studio использует параметры приложения для локального и облачного развертываний. Чтобы локально протестировать службу с 26 секциями, измените файл
Local.xmlв папке ApplicationParameters проекта AlphabetPartitions, как показано ниже.<Parameters> <Parameter Name="Processing_PartitionCount" Value="26" /> <Parameter Name="WebApi_InstanceCount" Value="1" /> </Parameters>Когда служба будет развернута, все ее секции можно будет проверить в обозревателе Service Fabric.
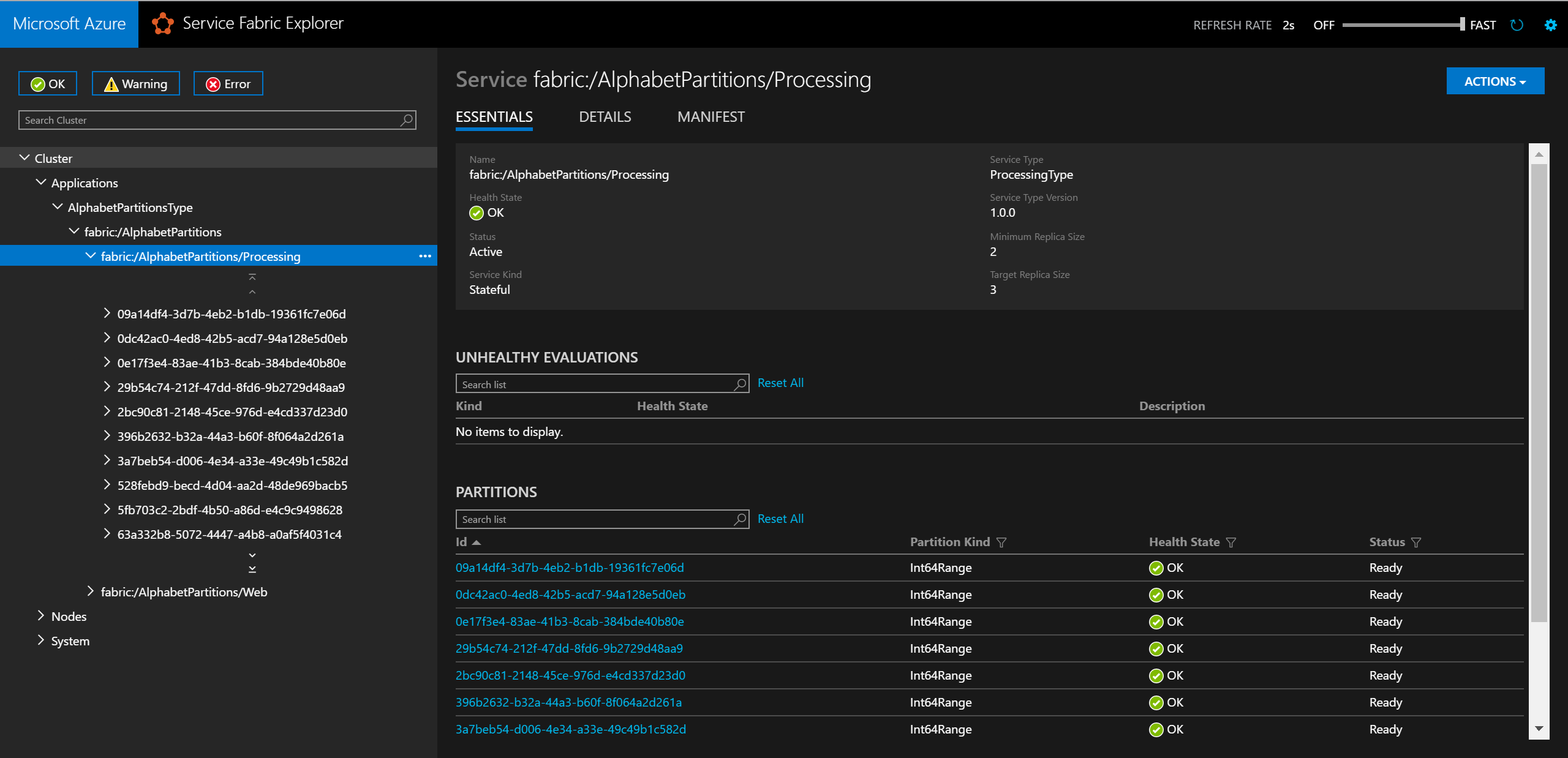
Чтобы проверить логику секционирования в браузере, введите в адресной строке
http://localhost:8081/?lastname=somename. Вы увидите, что все фамилии, начинающиеся с одинаковой буквы, хранятся в одной секции.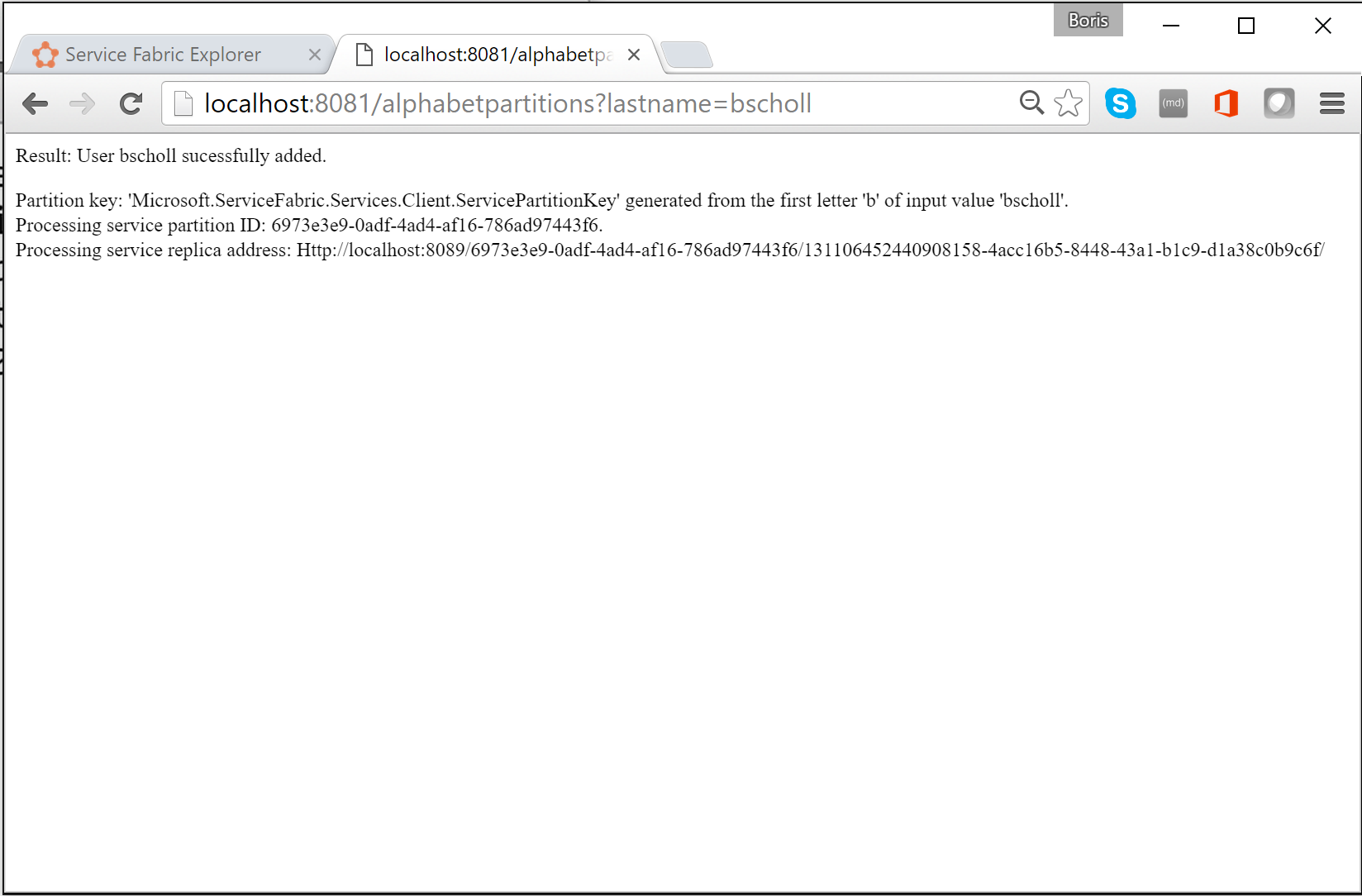
Полная версия кода, используемого в этой статье, размещена здесь: https://github.com/Azure-Samples/service-fabric-dotnet-getting-started/tree/classic/Services/AlphabetPartitions.
Следующие шаги
Дополнительные сведения о службах Service Fabric: