Планирование емкости для приложений Service Fabric
В этом документе содержатся сведения об определении объема ресурсов (ЦП, ОЗУ, дискового хранилища), необходимых для выполнения приложений Service Fabric. Чаще всего требования к ресурсам со временем меняются. Как правило, при разработке или тестировании службы требуется незначительное количество ресурсов. Но при переходе в рабочую среду и росте популярности приложения объем ресурсов возрастает. При проектировании приложения следует рассмотреть требования в долгосрочной перспективе и принять решения, которые позволят масштабировать службу в соответствии с возросшими требованиями клиентов.
Создавая кластер Service Fabric, вы решаете, какого типа виртуальные машины будут входить в его состав. Каждая виртуальная машина имеет ограниченный объем ресурсов в виде ЦП (ядра и быстродействие), пропускной способности сети, ОЗУ и дискового пространства. По мере расширения службы можно выполнить обновление до виртуальных машин с более высоким объемом и/или добавить в кластер дополнительные виртуальные машины. Чтобы решить последнюю задачу, необходимо первоначально так разработать службу, чтобы она смогла поддерживать преимущества новых виртуальных машин, динамически добавляемых в кластер.
Некоторые службы управляют слишком малым объемом данных на самих виртуальных машинах либо не управляют вообще ничем. Следовательно, при планировании загрузки для этих служб следует главным образом сосредоточиться на производительности, то есть нужно выбрать ЦП виртуальных машин с соответствующим числом ядер и тактовой частотой. Кроме того, также следует учесть пропускную способность сети, включая частоту передачи данных и объем передаваемых данных. Если по мере увеличения степени использования функционирование службы должно оставаться на высоком уровне, в кластер можно добавить дополнительные виртуальные машины и обеспечить балансировку сетевых запросов на всех виртуальных машинах.
При планировании загрузки для служб, управляющих большим объемом данных на виртуальных машинах, особое внимание следует уделить размеру. Поэтому необходимо тщательно обдумать выделение виртуальной машине требуемого объема ОЗУ и дискового пространства. В системе управления виртуальной памятью Windows дисковое пространство выглядит как ОЗУ в коде приложения. Кроме того, среда выполнения Service Fabric предоставляет функцию Smart Paging, оставляя в памяти горячие (часто используемые) данные и перемещая холодные (редко используемые) данные на диск. Это позволяет приложениям использовать больше памяти, чем доступно физически на виртуальной машине. Увеличение объема памяти просто приводит к увеличению производительности, так как виртуальная машина может содержать больше дискового пространства в ОЗУ. У выбранной виртуальной машины должен быть достаточно большой диск для хранения данных, которые должны размещаться на этой виртуальной машине. Аналогично, у виртуальной машины должен быть достаточный объем оперативной памяти для обеспечения нужной вам производительности. По мере увеличения объема данных службы в кластер можно добавить дополнительные виртуальные машины и секционировать данные на всех виртуальных машинах.
Определение количества необходимых узлов
Секционирование службы позволяет горизонтально увеличить масштаб данных службы. Дополнительные сведения о секционировании см. в статье Секционирование служб Reliable Services в Service Fabric. Каждая секция должна помещаться на одной виртуальной машине. Однако на одной виртуальной машине также можно разместить несколько небольших секций. Следовательно, наличие большего количества небольших секций обеспечивает большую гибкость, чем небольшое количество более крупных секций. Компромисс заключается в том, что значительное количество секций увеличивает нагрузку на платформу Service Fabric, поэтому вы не можете выполнять транзакционные операции между секциями. Если коду службы часто требуется доступ к фрагментам данных, расположенным в разных секциях, увеличивается объем потенциального сетевого трафика. При разработке службы следует внимательно рассмотреть эти преимущества и недостатки, чтобы в результате прийти к эффективной стратегии секционирования.
Предположим, что приложение имеет одну службу с отслеживанием состояния, размер хранилища которой будет предположительно увеличиваться до DB_Size ГБ в год. Вам нужно добавить несколько приложений (и секций), так как ваше решение за год расширилось. Коэффициент репликации (RF), который определяет число реплик службы, влияющее на итоговое значение DB_Size. Итоговое значение DB_Size всех реплик равно произведению коэффициента репликации и значения DB_Size. Значение Node_Size представляет дисковое пространство/ОЗУ для каждого узла, используемого для службы. Для наилучшей производительности значение DB_Size должно соответствовать памяти в кластере, а значение Node_Size — ОЗУ виртуальной машины. Выделяя значение Node_Size, превышающее емкость ОЗУ, вы полагаетесь на функцию подкачки, предоставляемую средой выполнения Service Fabric. Поэтому производительность может оказаться неоптимальной, если все данные будут считаться горячими (после подкачки данных). Однако для многих служб, активно использующих только часть данных, этот подход является более экономичным.
Количество узлов, необходимое для достижения максимальной производительности, можно вычислить следующим образом.
Number of Nodes = (DB_Size * RF)/Node_Size
Действия с учетом расширения службы
Чтобы вычислить количество узлов, вы можете использовать ожидаемое значение DB_Size для своей службы в дополнение к исходному значению DB_Size. По мере роста службы увеличивайте количество узлов, чтобы избежать их избыточной подготовки. Количество секций должно быть основано на количестве узлов, необходимых для работы службы на максимально эффективном уровне.
Рекомендуется иметь несколько дополнительных виртуальных машин под рукой, чтобы справляться с любыми непредвиденными скачками нагрузки или сбоями (например, при отказе нескольких виртуальных машин). Хотя дополнительные ресурсы следует определить согласно ожидаемым скачкам нагрузки, для начала можно зарезервировать несколько дополнительных виртуальных машин (дополнительно 5–10 %).
Изложенное выше предполагает, что у вас есть одна служба с отслеживанием состояния. Если у вас их несколько, то необходимо добавить в уравнение значение DB_Size, связанное с другими службами. Кроме того, можно отдельно вычислить количество узлов для каждой службы с отслеживанием состояния. У службы могут быть реплики или секции, которые не сбалансированы. Имейте в виду, что одни секции также могут содержать больше данных, чем другие. Дополнительные сведения о секционировании см. в статье Секционирование служб Reliable Services в Service Fabric. Тем не менее приведенное выше уравнение не зависит от количества секций или реплик, так как Service Fabric обеспечивает оптимальное распределение реплик между узлами.
Использование таблицы для расчета стоимости
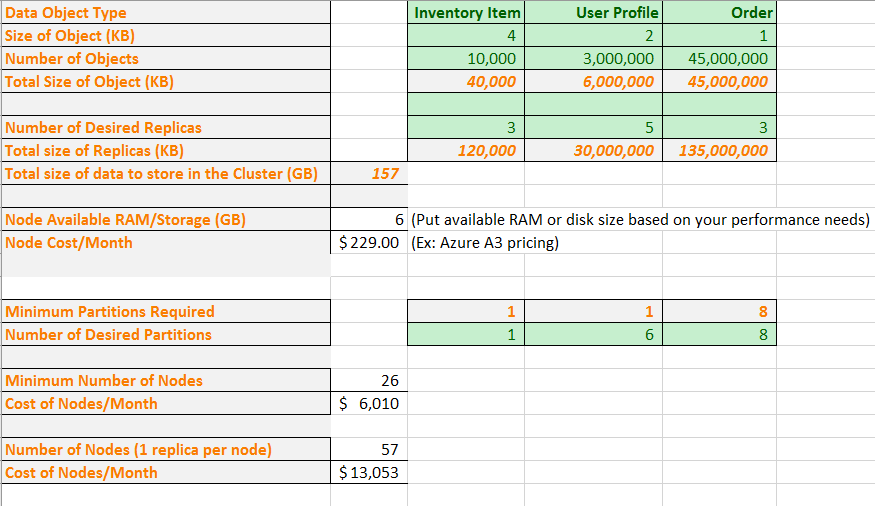
Теперь давайте введем несколько реальных чисел в нашу формулу. В этом примере таблицы показано планирование емкости для приложения, содержащего три типа объектов данных. Для каждого объекта мы приблизительно определяем его размер и планируемое количество объектов. Мы также выбираем требуемое количество реплик каждого типа объекта. Таблица вычисляет общий объем памяти для хранения в кластере.
Затем мы вводим размер виртуальной машины и ежемесячные расходы. В зависимости от размера виртуальной машины в таблице выводится минимальное количество секций, на которые необходимо разбить данные для физического размещения на узлах. В соответствии с конкретными вычислениями вашего приложения и потребностями сетевого трафика может потребоваться дополнительное количество секций. В таблице показано увеличение количества секций, управляющих объектами профиля пользователя, от 1 до 6.
Теперь на основе этой информации понятно, что вы можете физически получить все данные с нужными разделами и репликами в кластере с 26 узлами. Однако, так как этот кластер плотно упакован, могут потребоваться дополнительные узлы для обработки сбоев и обновлений. В таблице также показано, что наличие более 57 узлов не дает дополнительных преимуществ — у вас просто будут пустые узлы. Опять же, может потребоваться более 57 узлов для обслуживания сбоев и обновлений узлов. Таблицу можно настроить в соответствии с конкретными потребностями.
Следующие шаги
Дополнительные сведения о секционировании служб см. в статье Секционирование служб Reliable Services в Service Fabric.