Прогнозирование в масштабе: многие модели и распределенное обучение
В этой статье описывается обучение моделей прогнозирования на больших количествах исторических данных. Инструкции и примеры для обучения моделей прогнозирования в AutoML можно найти в нашей статье по настройке AutoML для прогнозирования временных рядов .
Данные временных рядов могут быть большими из-за количества рядов в данных, количества исторических наблюдений или обоих. Многие модели и иерархические временные ряды или HTS — это решения масштабирования для бывшего сценария, где данные состоят из большого количества временных рядов. В таких случаях это может быть полезно для точности модели и масштабируемости для секционирования данных в группы и параллельного обучения большого количества независимых моделей в группах. И наоборот, существуют сценарии, в которых лучше реализовать одну или несколько моделей с высокой емкостью. Распределенное обучение DNN предназначено для этого случая. Мы рассмотрим концепции этих сценариев в оставшейся части статьи.
Многие модели
Многие компоненты моделей в AutoML позволяют параллельно обучать миллионы моделей и управлять ими. Например, предположим, что у вас есть исторические данные о продажах для большого количества магазинов. Вы можете использовать множество моделей для запуска параллельных заданий обучения AutoML для каждого магазина, как показано на следующей схеме:

Многие компоненты обучения моделей применяют очистку и выбор модели AutoML независимо от каждого хранилища в этом примере. Эта модель независимости помогает масштабируемости и может повысить точность модели, особенно если магазины имеют динамику продаж. Однако один подход к модели может дать более точные прогнозы, если существуют распространенные динамики продаж. Дополнительные сведения об этом случае см. в разделе о распределенном обучении DNN.
Вы можете настроить секционирование данных, параметры AutoML для моделей и степень параллелизма для многих заданий обучения моделей. Примеры см. в разделе "Руководство" по многим компонентам моделей.
Прогнозирование иерархических временных рядов
Обычно для временных рядов в бизнес-приложениях используются вложенные атрибуты, которые образуют иерархию. Атрибуты географического и каталога продуктов часто вложены, например. Рассмотрим пример, в котором иерархия имеет два географических атрибута, идентификатор состояния и хранилища, а также два атрибута продукта, категорию и номер SKU:

Эта иерархия показана на следующей схеме:

Важно отметить, что объемы продаж на уровне конечного уровня (SKU) добавляются к агрегированным объемам продаж на уровне штата и общего объема продаж. Иерархические методы прогнозирования сохраняют эти свойства агрегирования при прогнозировании количества, проданного на любом уровне иерархии. Прогнозы с этим свойством согласованы с иерархией.
AutoML поддерживает следующие функции иерархических временных рядов (HTS):
- Обучение на любом уровне иерархии. В некоторых случаях данные конечного уровня могут быть шумными, но агрегаты могут быть более приемлемыми для прогнозирования.
- Получение прогнозов точек на любом уровне иерархии. Если уровень прогноза "ниже" уровня обучения, прогнозы от уровня обучения разделены по средним историческим пропорциям или пропорциям исторических средних. Прогнозы уровня обучения суммируются в соответствии со структурой агрегирования, когда уровень прогноза "выше" уровня обучения.
- Получение квантилей/вероятностных прогнозов для уровней на уровне обучения или ниже. Текущие возможности моделирования поддерживают разбиение вероятностных прогнозов.
Компоненты HTS в AutoML основаны на многих моделях, поэтому HTS использует масштабируемые свойства многих моделей. Примеры см. в разделе руководства по компонентам HTS.
Обучение распределенного DNN (предварительная версия)
Внимание
Эта функция сейчас доступна в виде общедоступной предварительной версии. Эта предварительная версия предоставляется без соглашения об уровне обслуживания. Ее не следует использовать для производственных рабочих нагрузок. Некоторые функции могут не поддерживаться или их возможности могут быть ограничены.
Дополнительные сведения см. в статье Дополнительные условия использования Предварительных версий Microsoft Azure.
Сценарии данных с большим количеством исторических наблюдений и /или большого количества связанных временных рядов могут воспользоваться масштабируемым подходом к одной модели. Соответственно, AutoML поддерживает распределенное обучение и поиск модели на временных сверточных моделях сети (TCN), которые являются типом глубокой нейронной сети (DNN) для данных временных рядов. Дополнительные сведения о классе модели TCN AutoML см. в нашей статье DNN.
Распределенное обучение DNN обеспечивает масштабируемость с помощью алгоритма секционирования данных, который учитывает границы временных рядов. На следующей схеме показан простой пример с двумя секциями:
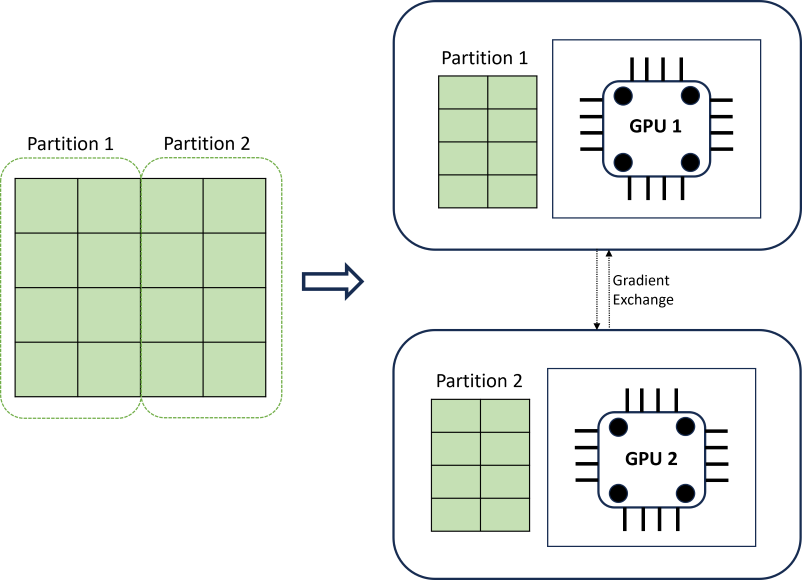
Во время обучения загрузчики данных DNN на каждой вычислительной нагрузке нужно выполнить итерацию обратного распространения; Весь набор данных никогда не считывается в память. Секции распределяются по нескольким вычислительным ядрам (обычно GPU) на нескольких узлах для ускорения обучения. Координация между вычислительными ресурсами обеспечивается платформой Horovod .
Следующие шаги
- Узнайте больше о настройке AutoML для обучения модели прогнозирования временных рядов.
- Узнайте, как AutoML использует машинное обучение для создания моделей прогнозирования.
- Сведения о моделях глубокого обучения для прогнозирования в AutoML