Глубокое обучение с помощью прогнозирования AutoML
В этой статье рассматриваются методы глубокого обучения для прогнозирования временных рядов в AutoML. Инструкции и примеры для обучения моделей прогнозирования в AutoML можно найти в нашей статье по настройке AutoML для прогнозирования временных рядов .
Глубокое обучение имеет многочисленные варианты использования в полях, начиная от моделирования языка до свертывания белка, среди многих других. Прогнозирование временных рядов также дает преимущества от последних достижений технологии глубокого обучения. Например, модели глубокой нейронной сети (DNN) имеют видную роль в верхней производительности моделей из четвертой и пятой итерации высокопрофилируемого конкурса Макридакис прогнозирования.
В этой статье мы описываем структуру и операцию модели TCNForecaster в AutoML, чтобы лучше всего применить модель к вашему сценарию.
Введение в TCNForecaster
TCNForecaster — это временная сверточная сеть или TCN, которая имеет архитектуру DNN, предназначенную для данных временных рядов. Модель использует исторические данные для целевого количества, а также связанных признаков, чтобы сделать вероятностные прогнозы целевого объекта до указанного горизонта прогнозирования. На следующем рисунке показаны основные компоненты архитектуры TCNForecaster:
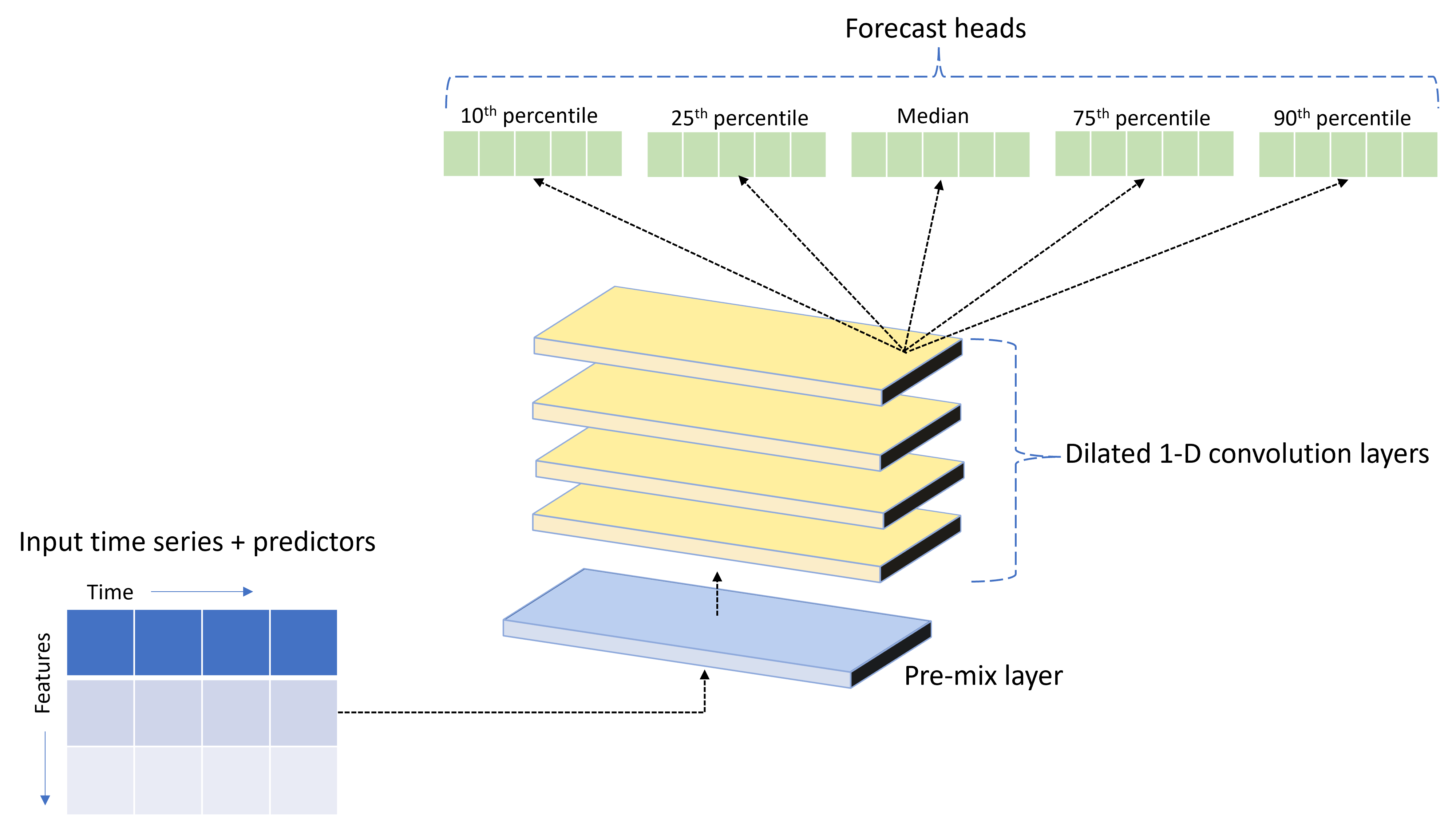
TCNForecaster имеет следующие основные компоненты:
- Слой предварительного смешивания, который смешивает входные временные ряды и данные признаков в массив каналов сигнала, которые обрабатывает стек сверток.
- Стек расширенных слоев свертки , обрабатывающих массив каналов последовательно; каждый слой в стеке обрабатывает выходные данные предыдущего слоя для создания нового массива каналов. Каждый канал в этом выходе содержит смесь сверток отфильтрованных сигналов из входных каналов.
- Коллекция головных единиц прогноза, которые объединяет выходные сигналы из слоев свертки и создают прогнозы целевого количества из этого скрытого представления. Каждая головная единица создает прогнозы до горизонта для квантиля распределения прогнозов.
Дилатированная причинная свертка
Центральная операция TCN — это дилатированная сверточная свертка по измерению времени входного сигнала. Интуитивно свертка объединяет значения из ближайших точек времени во входных данных. Пропорции в смеси являются ядром, или весами, свертывания в то время как разделение между точками в смеси является диляция. Выходной сигнал создается из входных данных путем скольжения ядра во времени по входному и накапливающего смесь на каждой позиции. Причина свертки — это одна из них, в которой ядро только смешает входные значения в прошлом относительно каждой точки вывода, предотвращая "просмотр" выходных данных в будущее.
Стекирование сверток позволяет TCN моделировать корреляции в течение длительного времени в входных сигналах с относительно небольшим количеством весов ядра. Например, на следующем рисунке показаны три слоя с двумя весами ядра в каждом слое и экспоненциально увеличивающие коэффициенты диляций:
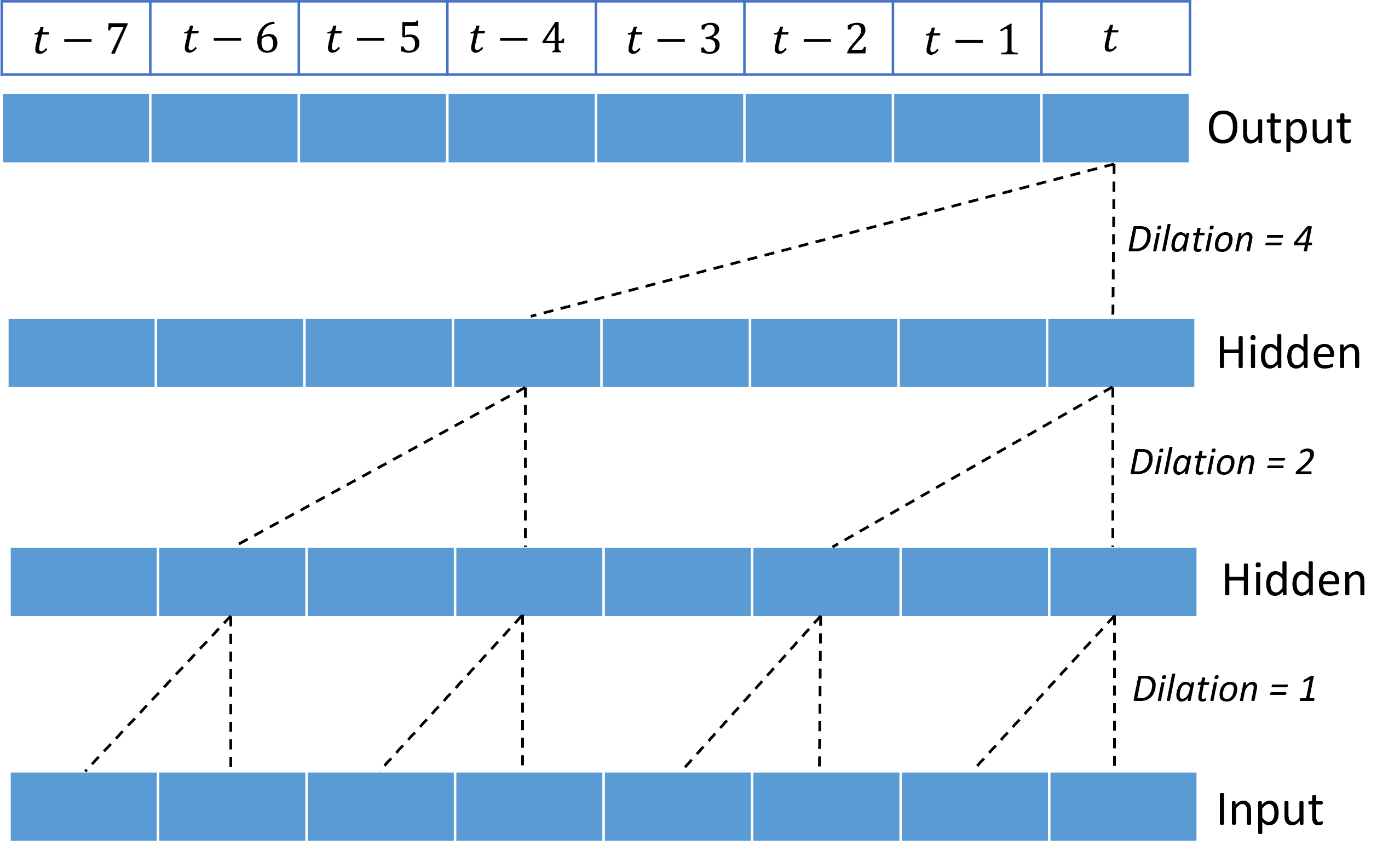
Пунктирные линии показывают пути через сеть, которая заканчивается на выходных данных за раз $t$. Эти пути охватывают последние восемь точек во входных данных, иллюстрируя, что каждая выходная точка является функцией восьми самых относительно последних точек во входных данных. Длина истории или "оглядывайся назад", что сверточная сеть использует для прогнозирования называется реффективным полем , и она полностью определяется архитектурой TCN.
Архитектура TCNForecaster
Основой архитектуры TCNForecaster является стек сверточных слоев между предварительной смесью и головками прогноза. Стек логически делится на повторяющиеся блоки, которые, в свою очередь, состоят из остаточных ячеек. Остаточная ячейка применяет причинные свертки при наборе диляций вместе с нормализацией и нелинейной активацией. Важно отметить, что каждая остаточная ячейка добавляет выходные данные в входные данные с помощью так называемого остаточного соединения. Эти подключения показано, чтобы воспользоваться обучением DNN, возможно, потому что они упрощают более эффективный поток информации через сеть. На следующем рисунке показана архитектура сверточных слоев для примера сети с двумя блоками и тремя остаточными ячейками в каждом блоке:
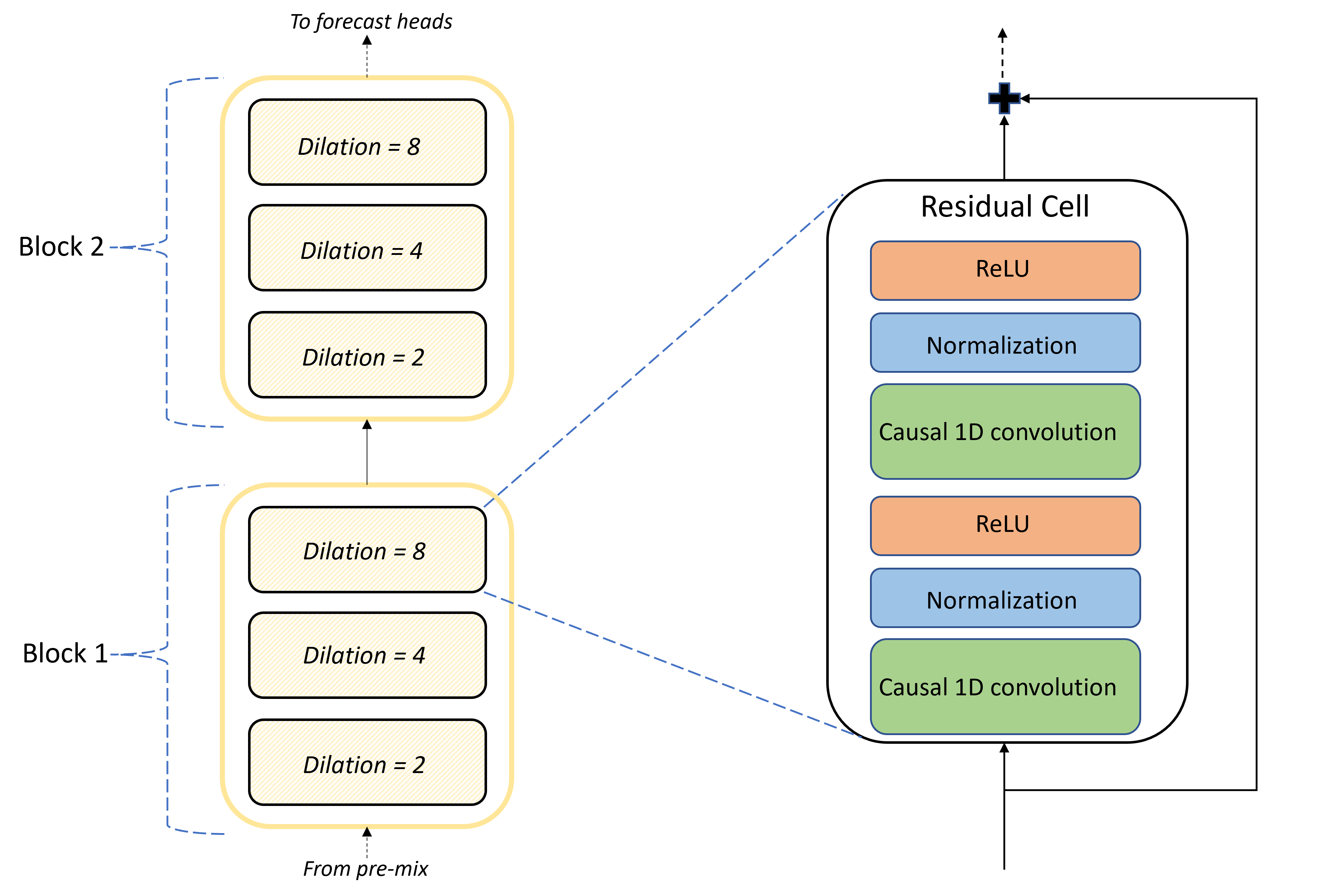
Количество блоков и ячеек, а также количество каналов сигнала в каждом слое, управляет размером сети. Архитектурные параметры TCNForecaster приведены в следующей таблице:
| Параметр | Описание |
|---|---|
| $n_{b}$ | Количество блоков в сети; также называется глубиной |
| $n_{c}$ | Количество ячеек в каждом блоке |
| $n_{\text{ch}}$ | Количество каналов в скрытых слоях |
Поле восприимчивого зависит от параметров глубины и определяется формулой.
$t_{\text{rf}} = 4n_{b}\left(2^{n_{c}} - 1\right) + 1.$
Мы можем дать более точное определение архитектуры TCNForecaster с точки зрения формул. Позвольте $X$ быть входным массивом, где каждая строка содержит значения признаков из входных данных. Мы можем разделить $X$ на числовые и категориальные массивы признаков, $X_{\text{num}}$ и $X_{\text{cat}}$. Затем TCNForecaster получает формулы,
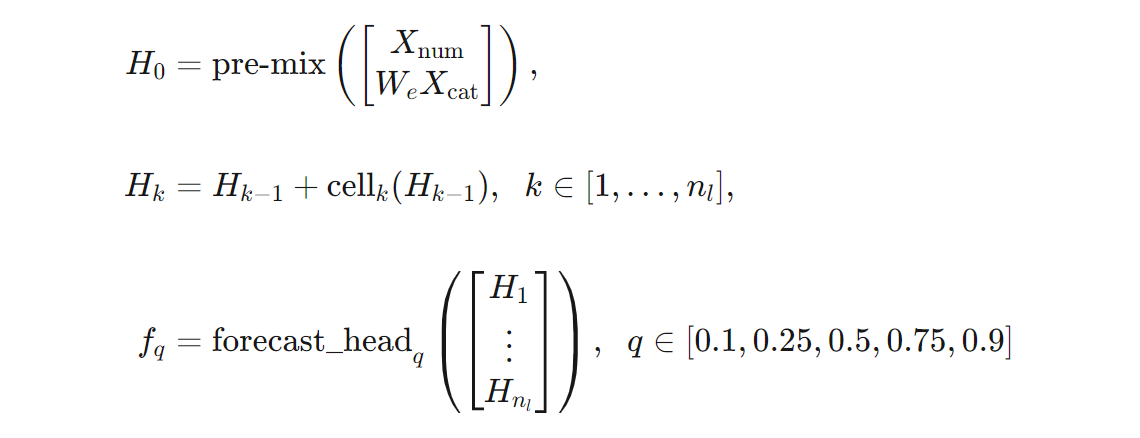
Где $W_{e}$ — это матрица внедрения для категориальных признаков, $n_{l} = n_{b}n_{c}$ — общее количество остаточных ячеек, $H_{k}$ обозначает выходные данные скрытого слоя, а $f_{q}$ — это прогнозируемые выходные данные для заданных квантиль прогнозов распределения прогнозов. Чтобы помочь понять, измерения этих переменных приведены в следующей таблице:
| «Переменная» | Description | Измерения |
|---|---|---|
| $X$ | Входной массив | $n_{\text{input}} \times t_{\text{rf}}$ |
| $H_{i}$ | Выходные данные скрытого слоя для $i=0,1,\ldots,n_{l}$ | $n_{\text{ch}} \times t_{\text{rf}}$ |
| $f_{q}$ | Прогноз выходных данных для квантильного $q$ | $h$ |
В таблице $n_{\text{input}} = n_{\text{features}} + 1$, количество переменных прогнозировщика или компонента, а также целевое количество. Руководители прогнозов создают все прогнозы до максимального горизонта, $h$, в одном проходе, поэтому TCNForecaster является прямым прогнозировщиком.
TCNForecaster в AutoML
TCNForecaster является необязательной моделью в AutoML. Сведения об использовании см. в статье "Включение глубокого обучения".
В этом разделе описано, как AutoML создает модели TCNForecaster с данными, включая объяснения предварительной обработки данных, обучения и поиска моделей.
Этапы предварительной обработки данных
AutoML выполняет несколько шагов предварительной обработки данных для подготовки к обучению модели. В следующей таблице описаны следующие действия в том порядке, в котором они выполняются:
| Этап | Description |
|---|---|
| Заполнение отсутствующих данных | Вмените отсутствующие значения и пробелы наблюдения, а также при необходимости заполнять короткие временные ряды или удалять короткие временные ряды |
| Создание функций календаря | Расширяйте входные данные с функциями, производными от календаря , например дня недели, и, при необходимости, праздники для определенной страны или региона. |
| Кодирование категориальных данных | Метка кодирует строки и другие категориальные типы. Это включает все столбцы идентификаторов временных рядов. |
| Целевое преобразование | При необходимости примените функцию естественного логарифма к целевому объекту в зависимости от результатов определенных статистических тестов. |
| нормализация | Оценка Z нормализует все числовые данные; нормализация выполняется для каждой функции и для каждой группы временных рядов, как определено столбцами идентификаторов временных рядов. |
Эти шаги включены в конвейеры преобразования AutoML, поэтому они автоматически применяются при необходимости во время вывода. В некоторых случаях обратная операция на шаг включается в конвейер вывода. Например, если AutoML применил преобразование $\log$ к целевому объекту во время обучения, необработанные прогнозы экспоненцируются в конвейере вывода.
Обучение
TCNForecaster следует рекомендациям по обучению DNN, общим для других приложений в изображениях и языках. AutoML делит предварительно обработанные данные обучения на примеры , которые перетасовываются и объединяются в пакеты. Сеть обрабатывает пакеты последовательно, используя обратное распространение и стохастический градиентный спуск для оптимизации весов сети в отношении функции потери. Для обучения может потребоваться много прохождения полных обучающих данных; каждый проход называется эпохой.
В следующей таблице перечислены и описываются входные параметры и параметры для обучения TCNForecaster:
| Входные данные для обучения | Description | Значение |
|---|---|---|
| Данные проверки | Часть данных, которая проводится из обучения, чтобы управлять оптимизацией сети и устранять проблемы с установкой. | Предоставляется пользователем или автоматически создается из обучающих данных, если они не предоставлены. |
| Основная метрика | Метрика, вычисленная из прогнозов медиана-значения на данные проверки в конце каждой эпохи обучения; используется для раннего остановки и выбора модели. | Выбран пользователь; нормализованная среднеквадратичная ошибка квадрата или нормализованная абсолютная ошибка. |
| Эпохи обучения | Максимальное количество эпох для оптимизации веса сети. | 100; автоматическая логика раннего остановки может завершить обучение на меньшем количестве эпох. |
| Ранние остановки терпения | Число эпох для ожидания первичного улучшения метрик до остановки обучения. | 20 |
| Функция потерь | Целевая функция оптимизации веса сети. | Квантиль потери в среднем составил более 10, 25,50, 75-го и 90-го процентильного прогноза. |
| Размер пакета | Количество примеров в пакете. Каждый пример имеет измерения $n_{\text{input}} \times t_{\text{rf}}$ для входных данных и $h$ для выходных данных. | Определяется автоматически из общего числа примеров в обучающих данных; максимальное значение 1024. |
| Измерения внедрения | Измерения встраиваемых пространств для категориальных признаков. | Автоматически устанавливается четвертый корень числа уникальных значений в каждой функции, округляя до ближайшего целого числа. Пороговые значения применяются по минимальному значению 3 и максимальному значению 100. |
| Сетевая архитектура* | Параметры, управляющие размером и формой сети: глубина, количество ячеек и количество каналов. | Определяется поиском модели. |
| Весы сети | Параметры, управляющие смесью сигналов, категориальным внедрением, весами ядра сверток и сопоставлениями с прогнозируемыми значениями. | Случайно инициализировано, а затем оптимизировано в отношении функции потери. |
| Скорость обучения* | Определяет, сколько весов сети можно настроить в каждой итерации градиентного спуска; динамически уменьшается почти конвергенция. | Определяется поиском модели. |
| Коэффициент выхода* | Управляет степенью нормализации выпадания, применяемой к весу сети. | Определяется поиском модели. |
Входные данные, помеченные звездочкой (*), определяются поиском гиперпараметров, описанным в следующем разделе.
Поиск модели
AutoML использует методы поиска моделей для поиска значений для следующих гипер-параметров:
- Глубина сети или количество сверточных блоков,
- Количество ячеек на блок,
- Количество каналов в каждом скрытом слое,
- Коэффициент удаления для нормализации сети,
- Скорость обучения.
Оптимальные значения этих параметров могут значительно отличаться в зависимости от сценария проблемы и обучающих данных, поэтому AutoML обучает несколько различных моделей в пространстве значений гиперпараметров и выбирает лучший в соответствии с основной оценкой метрик в данных проверки.
Поиск модели состоит из двух этапов:
- AutoML выполняет поиск более 12 "ориентиров" моделей. Ориентировые модели являются статическими и выбираются для разумного охвата пространства гиперпараметров.
- AutoML продолжает поиск по пространству гиперпараметров с помощью случайного поиска.
Поиск завершается при выполнении условий остановки. Критерии остановки зависят от конфигурации задания обучения прогноза, но некоторые примеры включают ограничения времени, ограничения на количество проб поиска для выполнения и ранней остановки логики, когда метрика проверки не улучшается.
Следующие шаги
- Узнайте, как настроить AutoML для обучения модели прогнозирования временных рядов.
- Узнайте о методологии прогнозирования в AutoML.
- Часто задаваемые вопросы о прогнозировании в AutoML.