Начало работы с данными DICOM в рабочих нагрузках аналитики
В этой статье описывается, как приступить к использованию данных DICOM® в рабочих нагрузках аналитики с Фабрика данных Azure и Microsoft Fabric.
Необходимые компоненты
Прежде чем приступить к работе, выполните следующие действия.
-
Создайте учетную запись хранения с возможностями Azure Data Lake Storage 2-го поколения, включив иерархическое пространство имен:
- Создайте контейнер для хранения метаданных DICOM, например с именем
dicom.
- Создайте контейнер для хранения метаданных DICOM, например с именем
- Разверните экземпляр службы DICOM.
- (Необязательно) Разверните службу DICOM с помощью Data Lake Storage , чтобы обеспечить прямой доступ к файлам DICOM.
- Создайте экземпляр фабрики данных:
- Включите управляемое удостоверение, назначаемое системой.
- Создайте lakehouse в Fabric.
- Добавьте назначения ролей в управляемое удостоверение, назначаемое системой фабрики данных, для службы DICOM и учетной записи хранения Data Lake Storage 2-го поколения:
- Добавьте роль средства чтения данных DICOM, чтобы предоставить разрешение службе DICOM.
- Добавьте роль участника данных BLOB-объектов хранилища, чтобы предоставить разрешение учетной записи Data Lake Storage 2-го поколения.
Настройка конвейера фабрики данных для службы DICOM
В этом примере конвейер фабрики данных используется для записи атрибутов DICOM для экземпляров, рядов и исследований в учетной записи хранения в формате разностной таблицы.
В портал Azure откройте экземпляр Фабрики данных и выберите "Запустить студию", чтобы начать работу.

Создание связанных служб
Конвейеры фабрики данных считываются из источников данных и записываются в приемники данных, которые обычно являются другими службами Azure. Эти подключения к другим службам управляются как связанные службы.
Конвейер в этом примере считывает данные из службы DICOM и записывает выходные данные в учетную запись хранения, поэтому связанная служба должна быть создана для обоих.
Создание связанной службы для службы DICOM
В Фабрика данных Azure Studio выберите "Управление" в меню слева. В разделе "Подключения" выберите "Связанные службы" и нажмите кнопку "Создать".
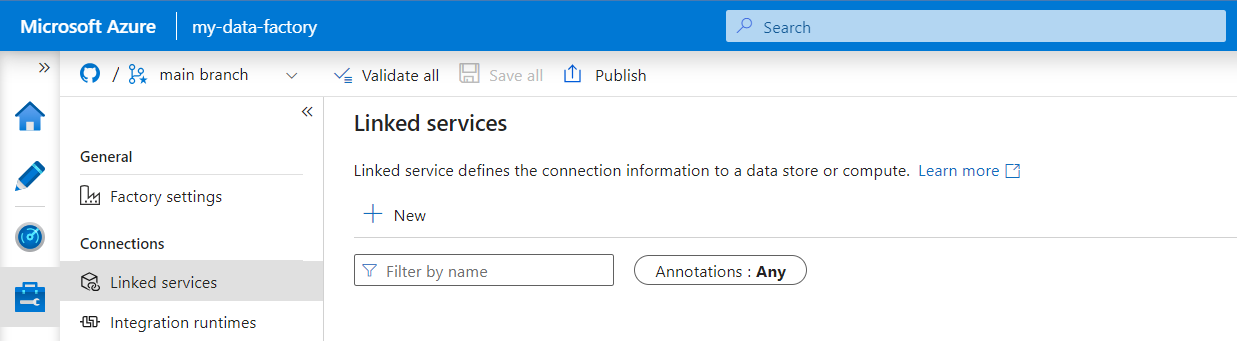
На панели "Новая связанная служба" найдите REST. Выберите плитку REST и нажмите кнопку "Продолжить".
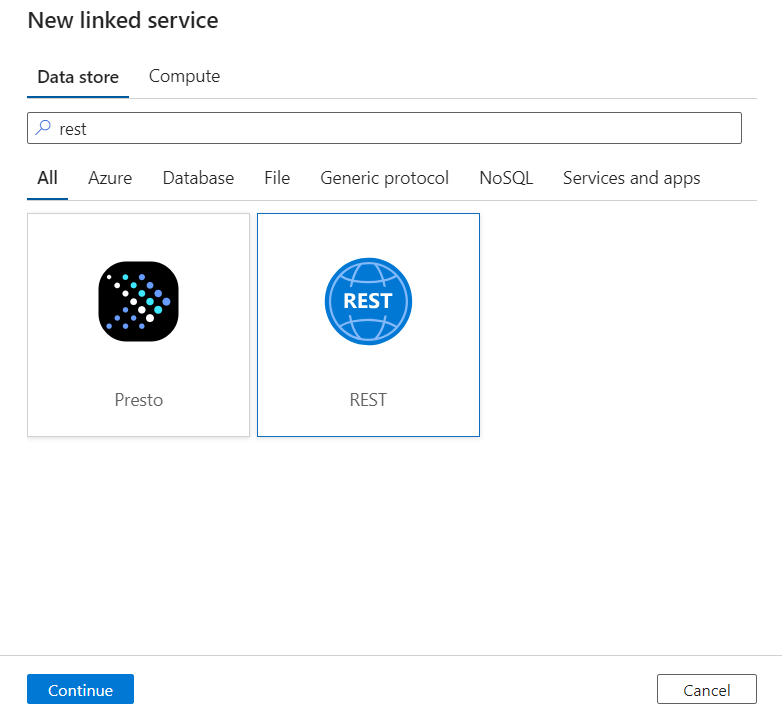
Введите имя и описание связанной службы.
В поле "Базовый URL-адрес" введите URL-адрес службы для службы DICOM. Например, служба DICOM с именем
contosoclinicвcontosohealthрабочей области имеет URL-адресhttps://contosohealth-contosoclinic.dicom.azurehealthcareapis.comслужбы.Для типа проверки подлинности выберите управляемое удостоверение, назначаемое системой.
Для ресурса AAD введите
https://dicom.healthcareapis.azure.com. Этот URL-адрес одинаков для всех экземпляров службы DICOM.После заполнения обязательных полей выберите "Проверить подключение" , чтобы убедиться, что роли удостоверения настроены правильно.
При успешном выполнении теста подключения нажмите кнопку "Создать".



Создание связанной службы для Azure Data Lake Storage 2-го поколения
В Студии фабрики данных выберите "Управление" в меню слева. В разделе "Подключения" выберите "Связанные службы" и нажмите кнопку "Создать".
На панели "Новая связанная служба" найдите Azure Data Lake Storage 2-го поколения. Выберите плитку Azure Data Lake Storage 2-го поколения и нажмите кнопку "Продолжить".
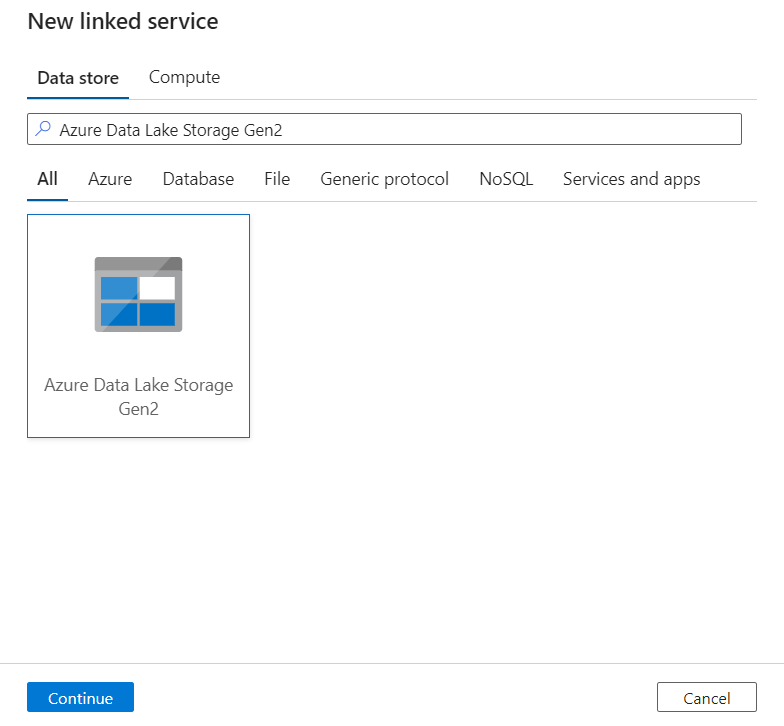
Введите имя и описание связанной службы.
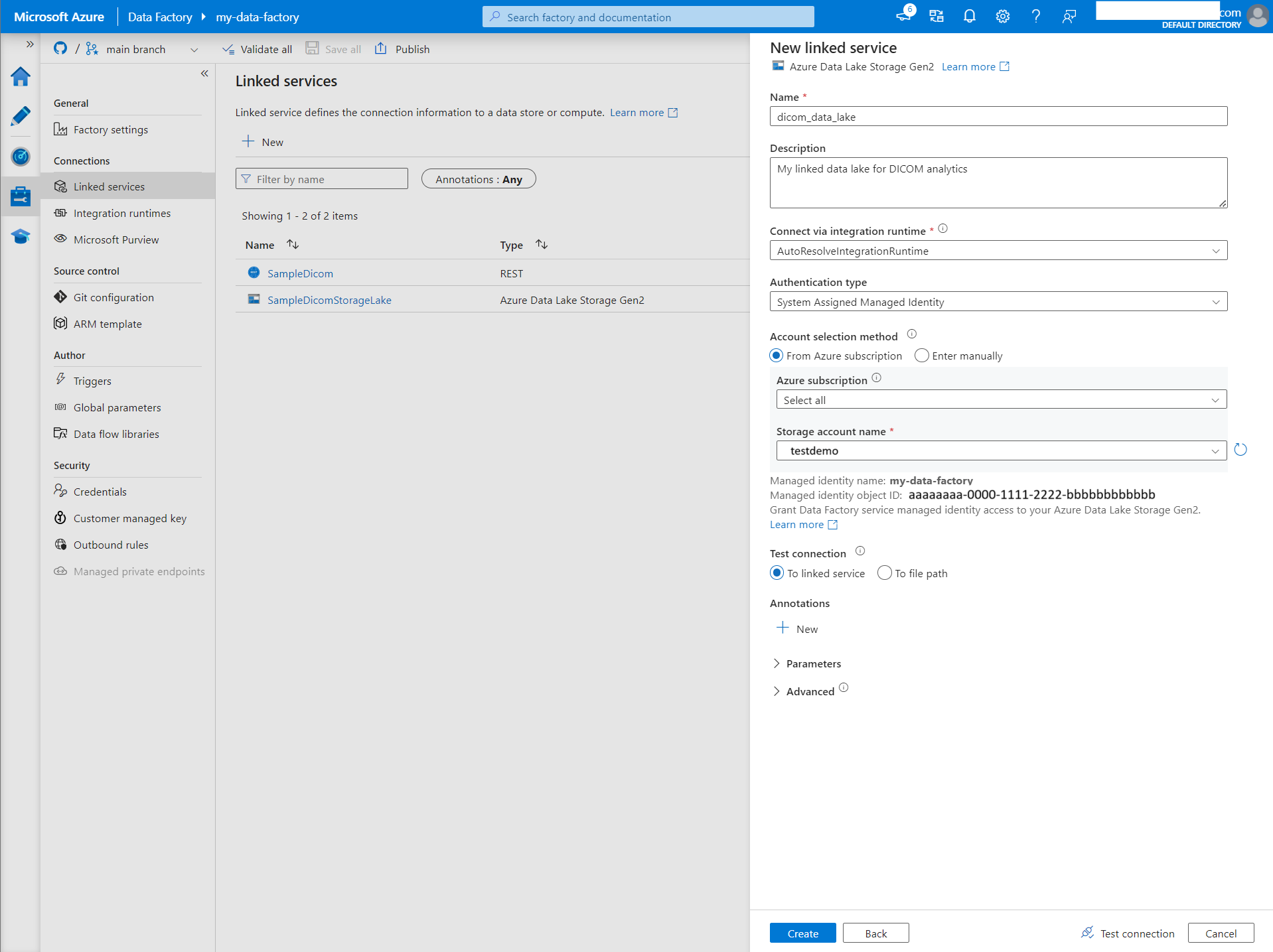
Для типа проверки подлинности выберите управляемое удостоверение, назначаемое системой.
Введите сведения о учетной записи хранения, введя URL-адрес учетной записи хранения вручную. Вы также можете выбрать подписку Azure и учетную запись хранения из раскрывающихся списков.
После заполнения обязательных полей выберите "Проверить подключение" , чтобы убедиться, что роли удостоверения настроены правильно.
При успешном выполнении теста подключения нажмите кнопку "Создать".


Создание конвейера для данных DICOM
Конвейеры фабрики данных — это коллекция действий , выполняющих задачу, например копирование метаданных DICOM в таблицы Delta. В этом разделе описывается создание конвейера, который регулярно синхронизирует данные DICOM с разностными таблицами в виде добавления, обновления и удаления из службы DICOM.
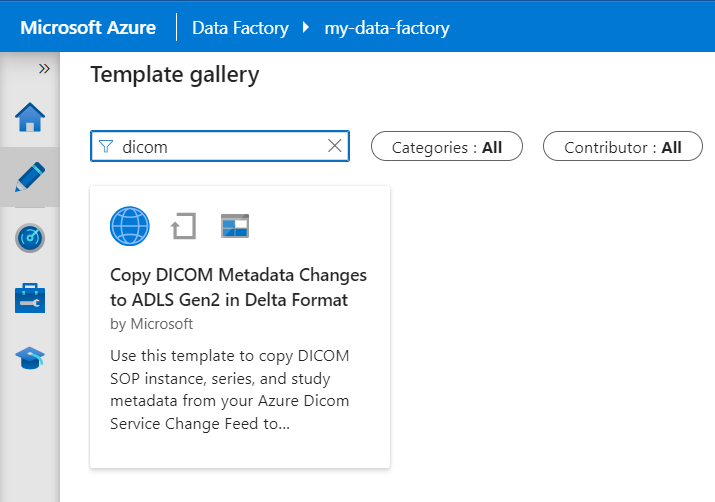
Выберите "Автор" в меню слева. В области "Ресурсы фабрики" выберите знак плюса (+), чтобы добавить новый ресурс. Выберите "Конвейер" и выберите коллекцию шаблонов в меню.

В коллекции шаблонов найдите DICOM. Выберите элемент Copy DICOM Metadata Changes to ADLS 2-го поколения в плитке Delta Format и нажмите кнопку "Продолжить".
В разделе "Входные данные" выберите связанные службы, ранее созданные для службы DICOM и Data Lake Storage 2-го поколения учетной записи.
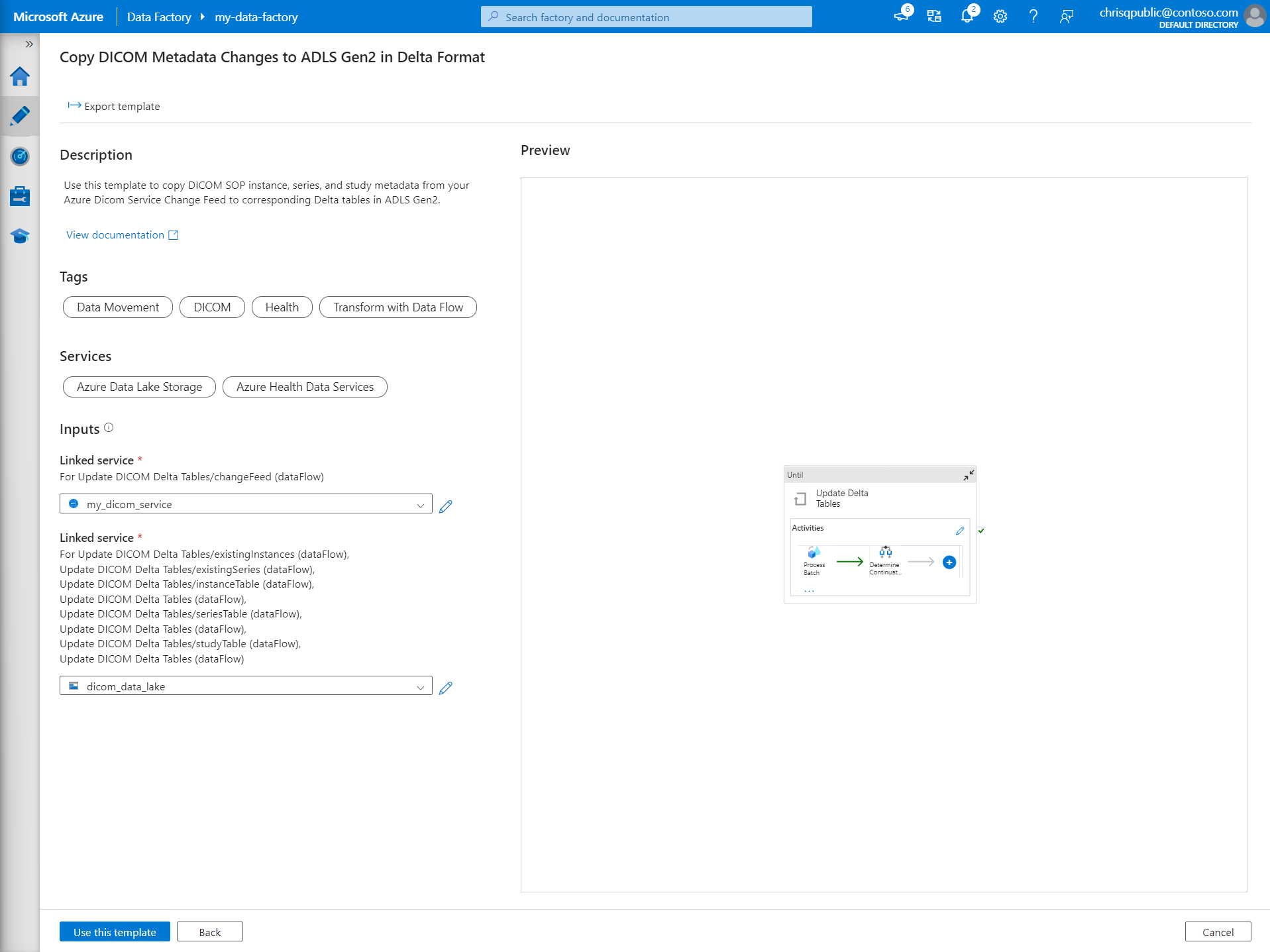
Выберите "Использовать этот шаблон " для создания нового конвейера.



Создание конвейера для данных DICOM
Если вы создали службу DICOM с помощью Azure Data Lake Storage, а не с помощью шаблона из коллекции шаблонов, необходимо использовать пользовательский шаблон для включения нового fileName параметра в конвейер метаданных. Чтобы настроить конвейер, выполните следующие действия.
Скачайте шаблон из GitHub. Файл шаблона — это сжатая (сжатая) папка. Вам не нужно извлекать файлы, так как они уже загружены в сжатой форме.
В Фабрика данных Azure выберите "Автор" в меню слева. На панели "Ресурсы фабрики" выберите знак плюса (+), чтобы добавить новый ресурс. Выберите "Конвейер" и выберите "Импорт" из шаблона конвейера.
В окне "Открыть" выберите скачанный шаблон. Выберите Открыть.
В разделе "Входные данные" выберите связанные службы, созданные для службы DICOM, и Azure Data Lake Storage 2-го поколения учетной записи.
Выберите "Использовать этот шаблон " для создания нового конвейера.
Создание расписания конвейера
Конвейеры запланированы триггерами. Существуют различные типы триггеров. Триггеры расписания позволяют запускать конвейеры в определенное время суток, например каждый час или каждый день в полночь. Триггеры вручную активируют конвейеры по запросу, что означает, что они выполняются всякий раз, когда они нужны.
В этом примере триггер переворачивающегося окна используется для периодического запуска конвейера с учетом начальной точки и регулярного интервала времени. Дополнительные сведения об триггерах см. в разделе "Выполнение конвейера" и "триггеры" в Фабрика данных Azure или Azure Synapse Analytics.
Создание триггера переворачивающегося окна
Выберите "Автор" в меню слева. Выберите конвейер для службы DICOM и выберите "Добавить триггер" и "Создать" или "Изменить" в строке меню.
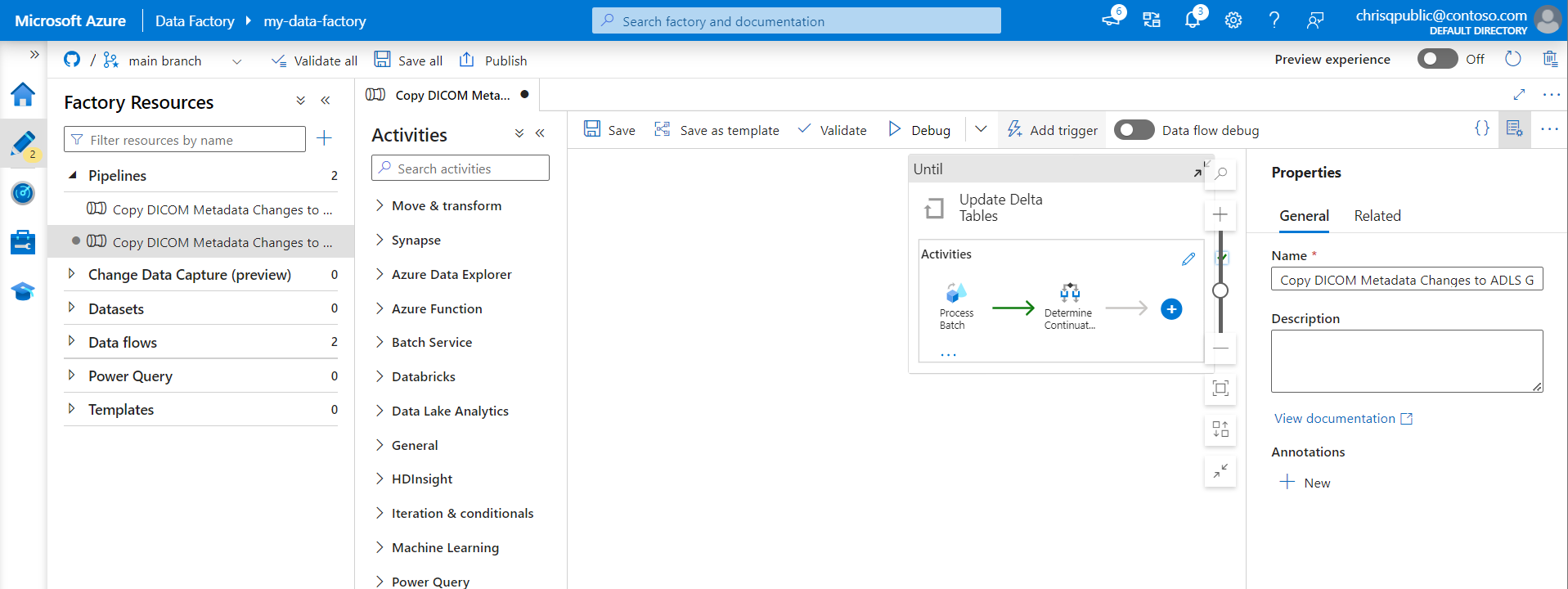
В области "Добавить триггеры" выберите раскрывающийся список "Выбрать триггер", а затем нажмите кнопку "Создать".
Введите имя и описание триггера.
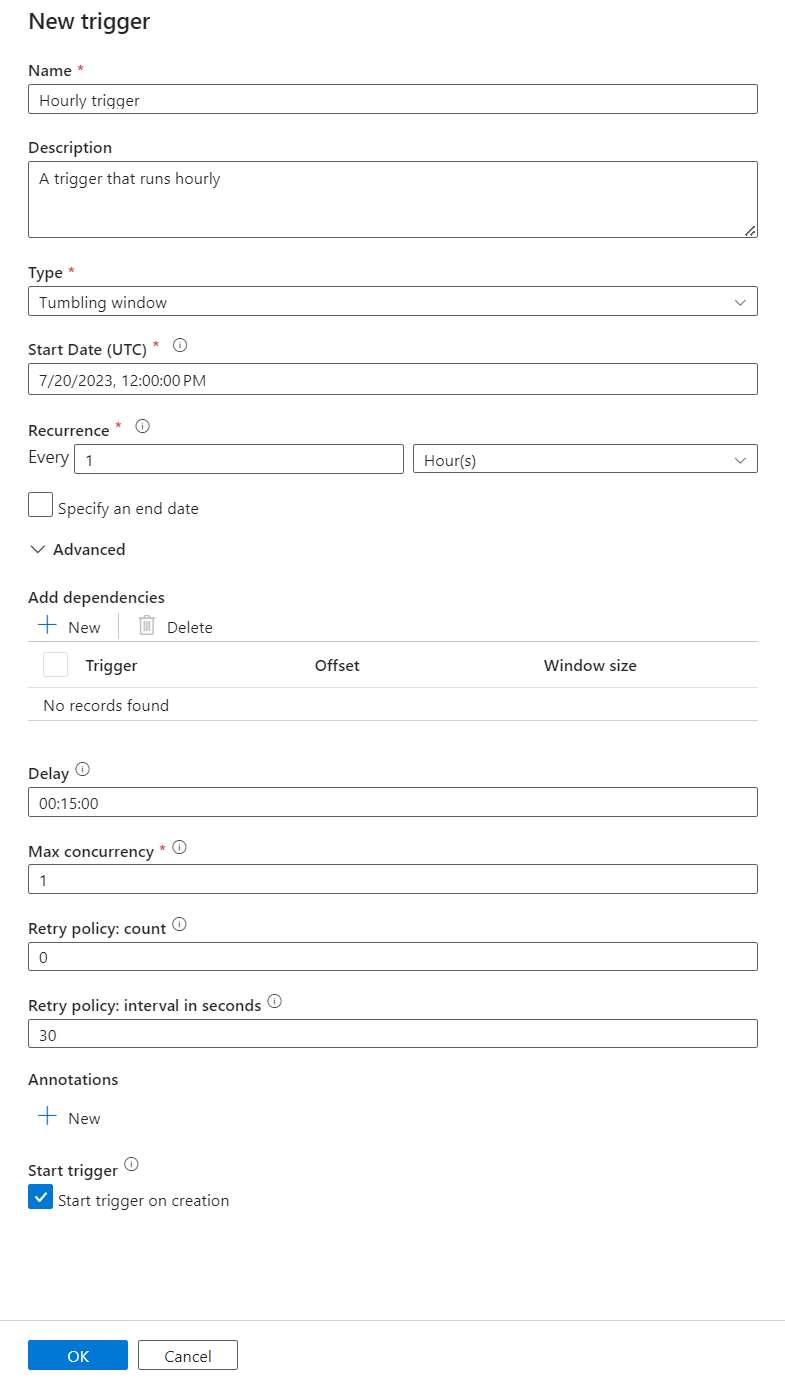
Выберите "Переворачивающееся" окно в качестве типа.
Чтобы настроить конвейер, который выполняется почасово, установите значение "Повторение " на 1 час.
Разверните раздел "Дополнительно" и введите задержку в течение 15 минут. Этот параметр позволяет выполнять все ожидающие операции в конце часа перед обработкой.
Задайте значение max concurrency равным 1 , чтобы обеспечить согласованность между таблицами.
Нажмите кнопку "ОК ", чтобы продолжить настройку параметров запуска триггера.


Настройка параметров запуска триггера
Триггеры определяют, когда выполняется конвейер. Они также включают параметры , передаваемые в выполнение конвейера. В шаблоне "Копирование метаданных DICOM" определяются параметры, описанные в следующей таблице. Если значение во время настройки не задано, для каждого параметра используется указанное значение по умолчанию.
| Наименование параметра | Description | Default value |
|---|---|---|
| BatchSize | Максимальное количество изменений для получения за раз из канала изменений (максимум 200) | 200 |
| ApiVersion | Версия API для службы Azure DICOM (минимум 2) | 2 |
| Время начала | Инклюзивное время начала изменений DICOM | 0001-01-01T00:00:00Z |
| EndTime | Эксклюзивное время окончания для изменений DICOM | 9999-12-31T23:59:59Z |
| ContainerName | Имя контейнера для результирующей разностной таблицы | dicom |
| InstanceTablePath | Путь, содержащий таблицу Delta для экземпляров SOP DICOM в контейнере | instance |
| SeriesTablePath | Путь, содержащий таблицу Delta для серии DICOM в контейнере | series |
| StudyTablePath | Путь, содержащий таблицу Delta для исследований DICOM в контейнере | study |
| RetentionHours | Максимальное хранение в часах для данных в таблицах Delta | 720 |
В области параметров запуска триггера введите значение ContainerName, соответствующее имени контейнера хранилища, созданного в предварительных требованиях.
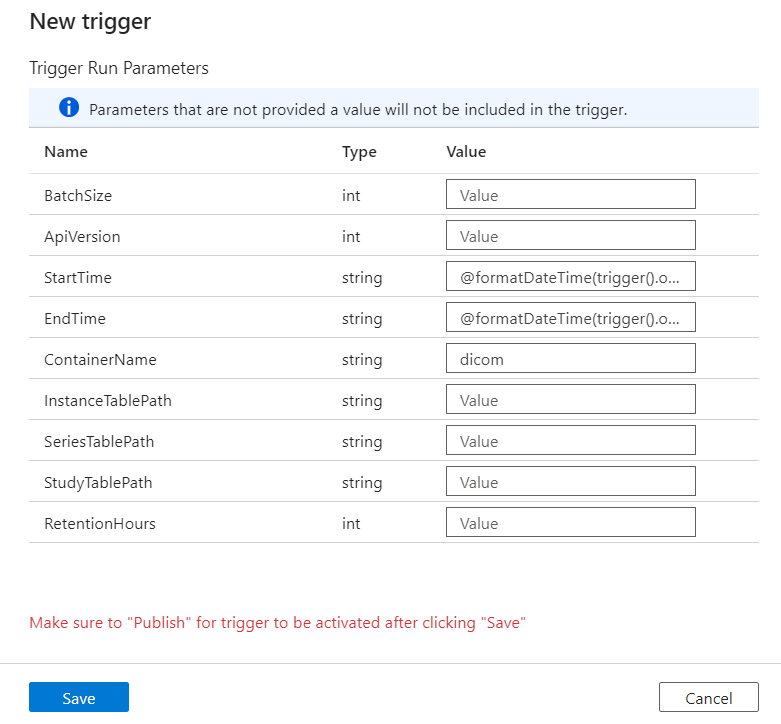
Для StartTime используйте системную переменную
@formatDateTime(trigger().outputs.windowStartTime).Для EndTime используйте системную переменную
@formatDateTime(trigger().outputs.windowEndTime).Примечание.
Только триггеры переворачивающегося окна поддерживают системные переменные:
-
@trigger().outputs.windowStartTimeи -
@trigger().outputs.windowEndTime.
Триггеры планирования используют разные системные переменные:
-
@trigger().scheduledTimeи -
@trigger().startTime.
Дополнительные сведения о типах триггеров.
-
Нажмите кнопку "Сохранить", чтобы создать новый триггер. Выберите "Опубликовать", чтобы начать запуск триггера в определенном расписании.


После публикации триггера его можно активировать вручную с помощью параметра Триггера . Если время начала было задано для значения в прошлом, конвейер запускается немедленно.
Мониторинг выполнений конвейера
Вы можете отслеживать запущенные запуски и связанные с ними конвейеры на вкладке "Монитор ". Здесь можно просмотреть время выполнения каждого конвейера и время его выполнения. Вы также можете отлаживать любые возникающие проблемы.

Microsoft Fabric
Fabric — это решение для аналитики с одним интерфейсом, которое находится на вершине Microsoft OneLake. Используя Lakehouse Fabric, вы можете управлять, структурировать и анализировать данные в OneLake в одном расположении. Любые данные за пределами OneLake, записанные в Data Lake Storage 2-го поколения, можно подключить к OneLake с помощью сочетаний клавиш для использования набора инструментов Fabric.
Создание ярлыков для таблиц метаданных
Перейдите к lakehouse, созданному в предварительных требованиях. В представлении обозревателя выберите меню с многоточием (...) рядом с папкой "Таблицы ".
Выберите новый ярлык, чтобы создать ярлык для учетной записи хранения, содержащей данные аналитики DICOM.
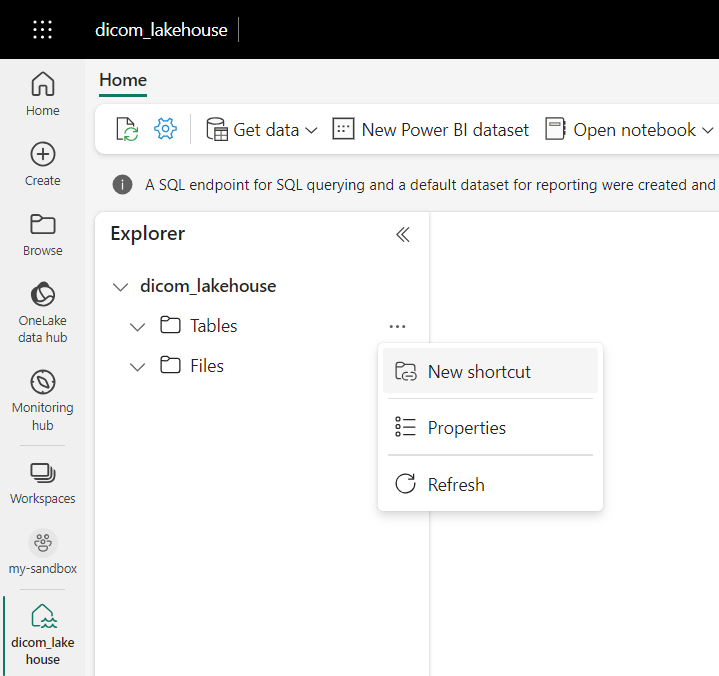
Выберите Azure Data Lake Storage 2-го поколения в качестве источника ярлыка.
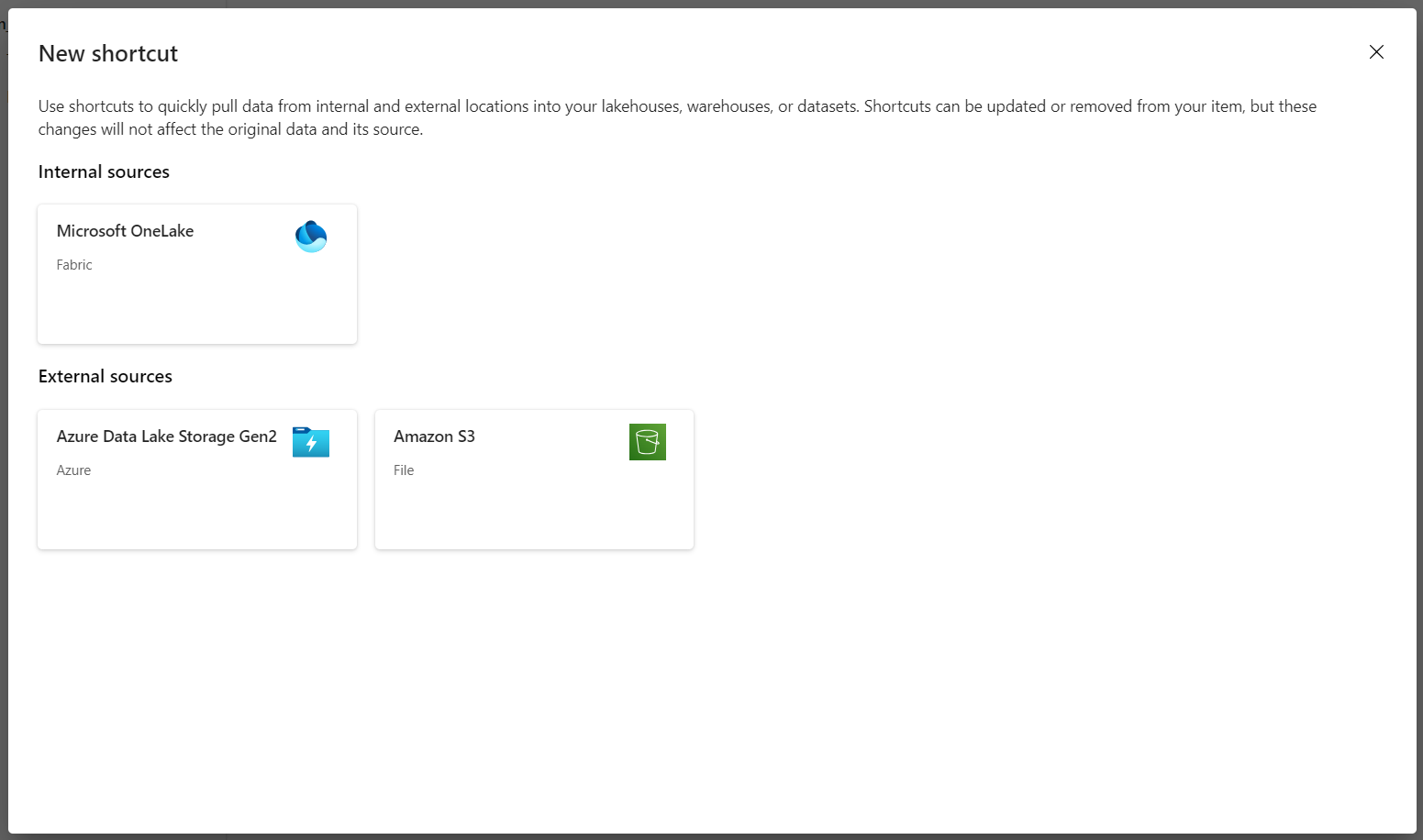
В разделе "Параметры подключения" введите URL-адрес, используемый в разделе "Связанные службы".
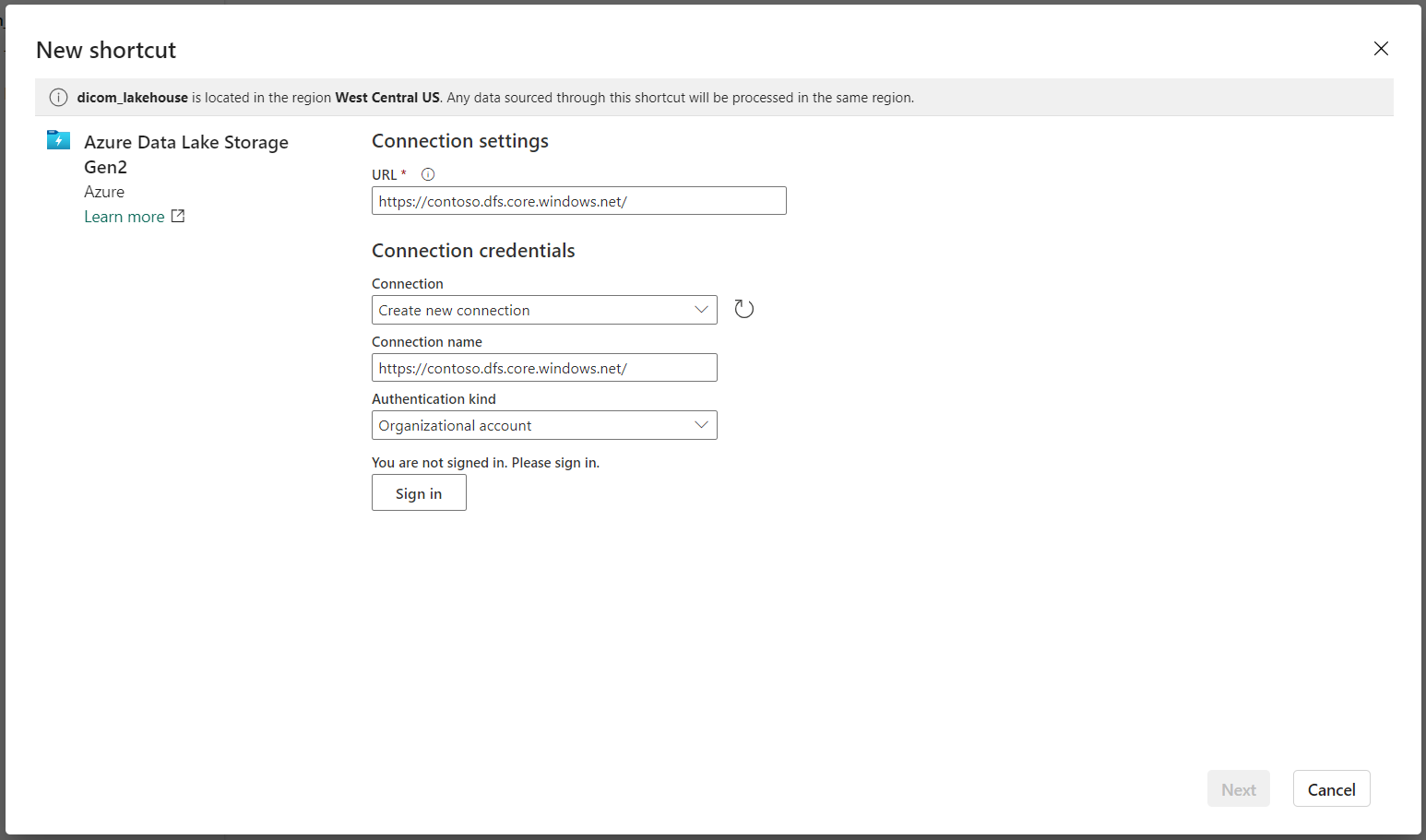
Выберите существующее подключение или создайте новое подключение, выбрав тип проверки подлинности, который вы хотите использовать.
Примечание.
Существует несколько вариантов проверки подлинности между Data Lake Storage 2-го поколения и Fabric. Вы можете использовать учетную запись организации или субъект-службу. Мы не рекомендуем использовать ключи учетной записи или маркеры подписанного URL-адреса.
Выберите Далее.
Введите сочетание клавиш, представляющее данные, созданные конвейером фабрики данных. Например, для
instanceтаблицы Delta имя ярлыка должно быть экземпляром.Введите вложенный путь, соответствующий
ContainerNameпараметру из конфигурации параметров запуска, и имя таблицы для ярлыка. Например, используйте/dicom/instanceдля таблицы Delta путьinstanceв контейнереdicom.Нажмите кнопку "Создать", чтобы создать ярлык.
Повторите шаги 2–9, чтобы добавить остальные сочетания клавиш в другие таблицы Delta в учетной записи хранения (например,
seriesиstudy).



После создания ярлыков разверните таблицу, чтобы отобразить имена и типы столбцов.

Создание ярлыков для файлов
Если вы используете службу DICOM с Data Lake Storage, можно также создать ярлык для данных DICOM, хранящихся в озере данных.
Перейдите к lakehouse, созданному в предварительных требованиях. В представлении обозревателя выберите меню с многоточием (...) рядом с папкой "Файлы ".
Выберите новый ярлык, чтобы создать ярлык для учетной записи хранения, содержащей данные DICOM.
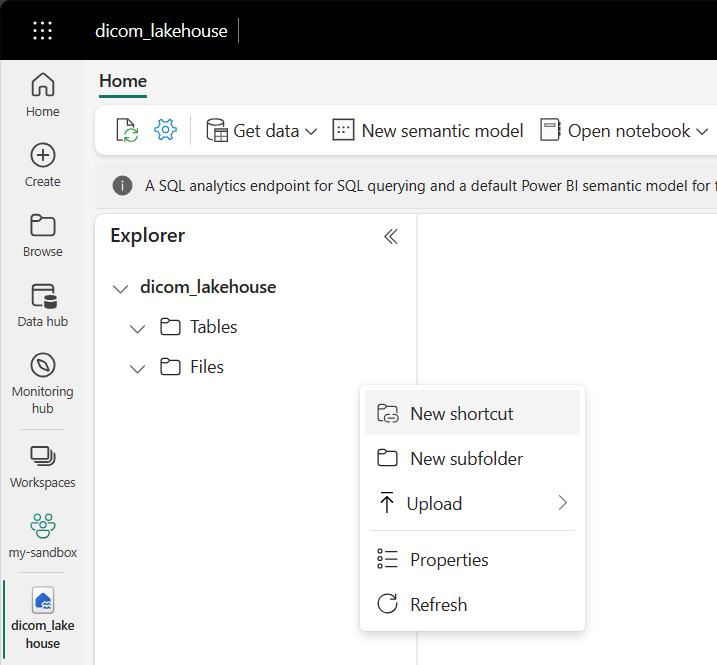
Выберите Azure Data Lake Storage 2-го поколения в качестве источника ярлыка.
В разделе "Параметры подключения" введите URL-адрес, используемый в разделе "Связанные службы".
Выберите существующее подключение или создайте новое подключение, выбрав тип проверки подлинности, который вы хотите использовать.
Выберите Далее.
Введите имя ярлыка, описывающее данные DICOM. Например, contoso-dicom-files.
Введите вложенный путь, соответствующий имени контейнера хранилища и папки, используемой службой DICOM. Например, если вы хотите связаться с корневой папкой, вложенный путь будет /dicom/AHDS. Корневая папка всегда
AHDSимеет значение, но при необходимости можно связать с дочерней папкой для определенной рабочей области или экземпляра службы DICOM.Нажмите кнопку "Создать", чтобы создать ярлык.


Выполнение записных книжек
После создания таблиц в lakehouse их можно запросить из записных книжек Fabric. Записные книжки можно создавать непосредственно из lakehouse, выбрав "Открыть записную книжку " в строке меню.
На странице записной книжки содержимое lakehouse можно просмотреть слева, включая только что добавленные таблицы. В верхней части страницы выберите язык записной книжки. Язык также можно настроить для отдельных ячеек. В следующем примере используется Spark SQL.
Запрос таблиц с помощью Spark SQL
В редакторе ячеек введите SQL-запрос Spark, например инструкцию SELECT .
SELECT * from instance
Этот запрос выбирает все содержимое instance таблицы. Когда вы будете готовы, выберите "Выполнить ячейку ", чтобы запустить запрос.

Через несколько секунд результаты запроса отображаются в таблице под ячейкой, как показано в следующем примере. Время может быть больше, если этот запрос Spark является первым в сеансе, так как контекст Spark должен быть инициализирован.

Доступ к данным файла DICOM в записных книжках
Если вы использовали шаблон для создания конвейера и создали ярлык для данных файла DICOM, можно использовать filePath столбец в instance таблице для сопоставления метаданных экземпляра с данными файла.
SELECT sopInstanceUid, filePath from instance

Итоги
Из этой статьи вы узнали, как выполнять следующие задачи:
- Используйте шаблоны фабрики данных для создания конвейера из службы DICOM в учетную запись Data Lake Storage 2-го поколения.
- Настройте триггер для извлечения метаданных DICOM в почасовом расписании.
- Используйте сочетания клавиш для подключения данных DICOM в учетной записи хранения к Lakehouse Fabric.
- Используйте записные книжки для запроса данных DICOM в lakehouse.
Следующие шаги
Примечание.
DICOM® является зарегистрированным товарным знаком Национальной ассоциации производителей электрических технологий для публикаций по стандартам, касающихся цифровых коммуникаций медицинской информации.