Использование Набора средств Azure для IntelliJ для удаленной отладки приложений Apache Spark в HDInsight с помощью VPN
Рекомендуется удаленно выполнять отладку приложений Apache Spark с помощью SSH. См. инструкции в статье удаленной отладки приложений Apache Spark в кластере HDInsight с помощью Azure Toolkit для IntelliJ по протоколу SSH.
В этой статье приводятся пошаговые инструкции по использованию средств HDInsight в Наборе средств Azure для IntelliJ для отправки задания Spark в кластере HDInsight Spark, а затем удаленной отладки с классического компьютера. Чтобы выполнить эти задачи, необходимо выполнить следующие высокоуровневые действия.
- Создайте виртуальную сеть Azure типа "сеть — сеть" или "точка — сеть". В этом документе предполагается, что вы используете сеть типа "сеть — сеть".
- Создайте кластер Spark на HDInsight, который является частью виртуальной сети "точка-точка".
- Проверьте подключение между головным узлом кластера и рабочим столом.
- Создайте приложение Scala в IntelliJ IDEA и настройте его для удаленной отладки.
- Запустите и отладите приложение.
Предпосылки
- подписка Azure. Дополнительные сведения см. в статье "Получение бесплатной пробной версии Azure".
- Кластер Apache Spark в HDInsight. Для получения инструкций см. Создание кластеров Apache Spark в Azure HDInsight.
- Пакет средств разработки Oracle Java. Его можно установить на веб-сайте Oracle.
- IntelliJ IDEA. В этой статье используется версия 2017.1. Его можно установить на веб-сайте JetBrains.
- Средства HDInsight в Наборе средств Azure для IntelliJ. Средства HDInsight для IntelliJ доступны в составе набора средств Azure для IntelliJ. Инструкции по установке набора средств Azure см. в статье "Установка набора средств Azure для IntelliJ".
- Войдите в подписку Azure из IntelliJ IDEA. Следуйте инструкциям из статьи "Использование набора средств Azure для IntelliJ" для создания приложений Apache Spark для кластера HDInsight.
- Обход исключения. При запуске приложения Spark Scala для удаленной отладки на компьютере с Windows может возникнуть исключение. Это исключение объясняется в SPARK-2356 и возникает из-за отсутствия WinUtils.exe файла в Windows. Чтобы обойти эту ошибку, необходимо скачать Winutils.exe в папку, например, C:\WinUtils\bin. Добавьте переменную среды HADOOP_HOME и задайте для переменной значение C\WinUtils.
Шаг 1. Создание виртуальной сети Azure
Следуйте инструкциям из следующих ссылок, чтобы создать виртуальную сеть Azure, а затем проверить подключение между настольным компьютером и виртуальной сетью:
- Создание виртуальной сети с VPN-подключением типа "сеть — сеть" с помощью портала Azure
- Создание виртуальной сети с VPN-подключением типа "сеть — сеть" с помощью PowerShell
- Настройка подключения к виртуальной сети типа "точка — сеть" с помощью PowerShell
Шаг 2. Создание кластера HDInsight Spark
Рекомендуется также создать кластер Apache Spark в Azure HDInsight, который является частью созданной виртуальной сети Azure. Используйте сведения, доступные в разделе "Создание кластеров на основе Linux в HDInsight". В рамках необязательной настройки выберите виртуальную сеть Azure, созданную на предыдущем шаге.
Шаг 3. Проверка подключения между головным узлом кластера и рабочим столом
Получите IP-адрес головного узла. Откройте пользовательский интерфейс Ambari для кластера. В колонке кластера выберите панель мониторинга.
В пользовательском интерфейсе Ambari выберите Узлы.

Вы увидите список головных узлов, рабочих узлов и узлов ZooKeeper. Головные узлы имеют префикс hn*. Выберите первый головной узел.
В области сводки в нижней части открывающейся страницы скопируйте IP-адрес головного узла и имя узла.
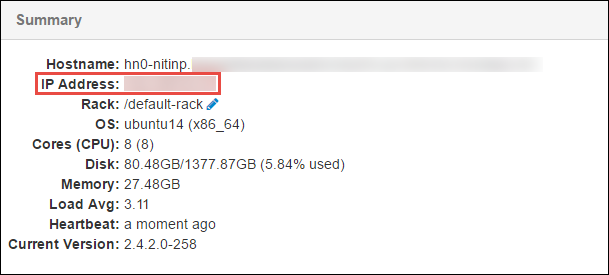
Добавьте IP-адрес и сетевое имя главного узла в файл hosts на компьютере, где вы хотите выполнять и удаленно отлаживать задание Spark. Это позволяет взаимодействовать с головным узлом с помощью IP-адреса, а также имени узла.
a. Откройте файл Блокнота с повышенными разрешениями. В меню "Файл" выберите "Открыть", а затем найдите расположение файла hosts. На компьютере Windows расположение — C:\Windows\System32\Drivers\etc\hosts.
б. Добавьте следующие сведения в файл hosts :
# For headnode0 192.xxx.xx.xx nitinp 192.xxx.xx.xx nitinp.lhwwghjkpqejawpqbwcdyp3.gx.internal.cloudapp.net # For headnode1 192.xxx.xx.xx nitinp 192.xxx.xx.xx nitinp.lhwwghjkpqejawpqbwcdyp3.gx.internal.cloudapp.netНа компьютере, подключенном к виртуальной сети Azure, используемой кластером HDInsight, убедитесь, что вы можете проверить связь с головными узлами с помощью IP-адреса, а также имени узла.
Используйте SSH для подключения к головному узлу кластера, следуя инструкциям в статье "Подключение к кластеру HDInsight с помощью SSH". Из головного узла кластера выполните ping IP-адреса настольного компьютера. Проверьте подключение к обоим IP-адресам, назначенным компьютеру:
- Один для сетевого подключения
- Один для виртуальной сети Azure
Повторите шаги для другого головного узла.
Шаг 4. Создание приложения Apache Spark Scala с помощью средств HDInsight в Azure Toolkit для IntelliJ и его настройка для удаленной отладки
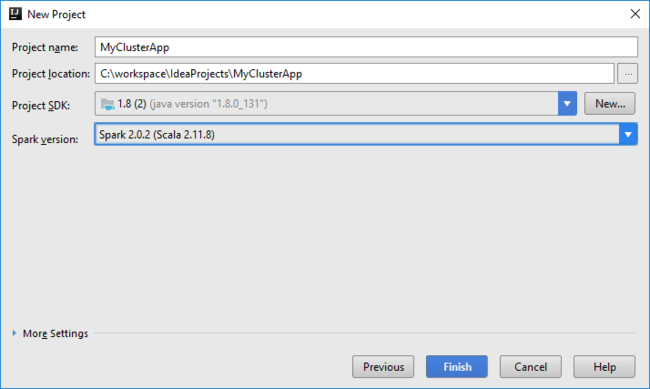
Откройте IntelliJ IDEA и создайте проект. В диалоговом окне "Новый проект" сделайте следующее:
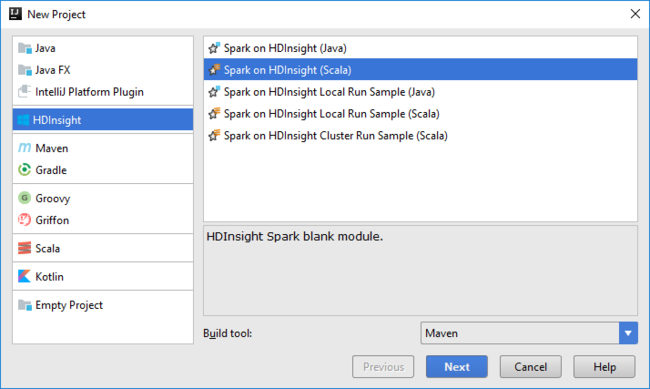
a. Выберите HDInsight>Spark в HDInsight (Scala).
б. Выберите Далее.
В следующем диалоговом окне "Создать проект " выполните указанные ниже действия и нажмите кнопку "Готово".
Введите имя и расположение проекта.
В раскрывающемся списке пакета SDK для Project выберите Java 1.8 для кластера Spark 2.x или выберите Java 1.7 для кластера Spark 1.x.
В раскрывающемся списке версий Spark мастер создания проекта Scala интегрирует правильную версию пакета SDK Spark и пакета SDK Scala. Если используется версия кластера Spark более ранняя, чем 2.0, выберите Spark 1.x. В противном случае выберите Spark2.x. В этом примере используется Spark 2.0.2 (Scala 2.11.8).
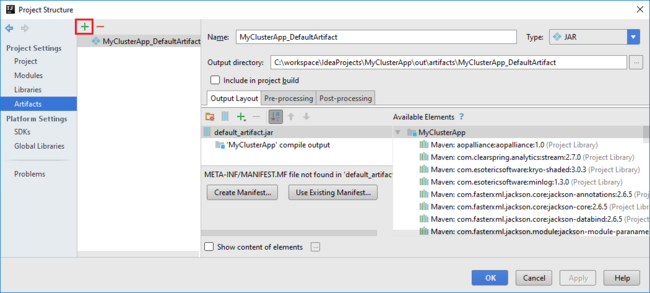
Проект Spark автоматически создает артефакт для вас. Чтобы просмотреть артефакт, сделайте следующее:
a. В меню "Файл" выберите "Структура проекта".
б. В диалоговом окне "Структура проекта" выберите артефакты , чтобы просмотреть созданный артефакт по умолчанию. Вы также можете создать собственный артефакт, выбрав знак плюса (+).
Добавьте библиотеки в проект. Чтобы добавить библиотеку, сделайте следующее:
a. Щелкните правой кнопкой мыши имя проекта в дереве проекта и выберите пункт "Открыть параметры модуля".
б. В диалоговом окне "Структура проекта " выберите библиотеки, выберите символ (+) и выберите "Из Maven".
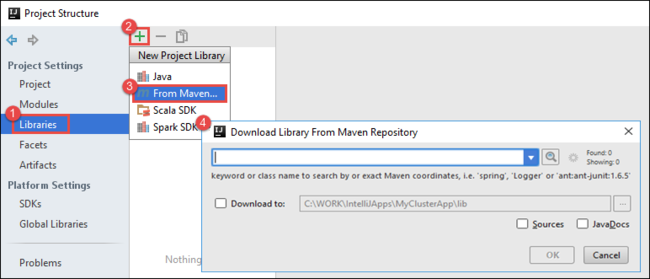
с. В диалоговом окне "Скачать библиотеку из репозитория Maven" найдите и добавьте следующие библиотеки:
org.scalatest:scalatest_2.10:2.2.1org.apache.hadoop:hadoop-azure:2.7.1
Скопируйте
yarn-site.xmlиcore-site.xmlиз головного узла кластера и добавьте их в проект. Чтобы скопировать файлы, используйте следующие команды. С помощью Cygwin можно выполнить следующиеscpкоманды, чтобы скопировать файлы из головного узла кластера:scp <ssh user name>@<headnode IP address or host name>://etc/hadoop/conf/core-site.xml .Так как мы уже добавили IP-адрес головного узла кластера и имена узлов для файла узлов на рабочем столе, мы можем использовать
scpкоманды следующим образом:scp sshuser@nitinp:/etc/hadoop/conf/core-site.xml . scp sshuser@nitinp:/etc/hadoop/conf/yarn-site.xml .Чтобы добавить эти файлы в проект, скопируйте их в папку /src в дереве проекта, например
<your project directory>\src.core-site.xmlОбновите файл, чтобы внести следующие изменения:a. Замените зашифрованный ключ. Файл
core-site.xmlсодержит зашифрованный ключ к учетной записи хранения, связанной с кластером.core-site.xmlВ файле, добавленном в проект, замените зашифрованный ключ фактическим ключом хранилища, связанным с учетной записью хранения по умолчанию. Для получения дополнительной информации, см. Управление ключами доступа к учетной записи хранения.<property> <name>fs.azure.account.key.hdistoragecentral.blob.core.windows.net</name> <value>access-key-associated-with-the-account</value> </property>б. Удалите следующие записи из
core-site.xml:<property> <name>fs.azure.account.keyprovider.hdistoragecentral.blob.core.windows.net</name> <value>org.apache.hadoop.fs.azure.ShellDecryptionKeyProvider</value> </property> <property> <name>fs.azure.shellkeyprovider.script</name> <value>/usr/lib/python2.7/dist-packages/hdinsight_common/decrypt.sh</value> </property> <property> <name>net.topology.script.file.name</name> <value>/etc/hadoop/conf/topology_script.py</value> </property>с. Сохраните файл.
Добавьте основной класс для приложения. В обозревателе проектов щелкните правой кнопкой мыши src, наведите указатель на "Создать", а затем выберите класс Scala.
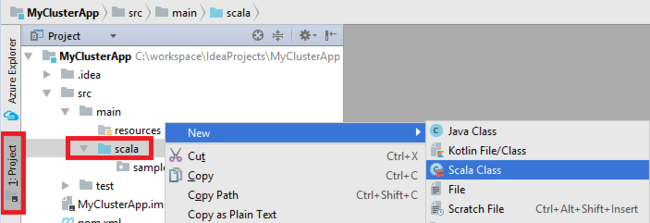
В диалоговом окне "Создание класса Scala" укажите имя, выберите "Объект " в поле "Тип " и нажмите кнопку "ОК".
MyClusterAppMain.scalaВ файле вставьте следующий код. Этот код создает контекст Spark и открываетexecuteJobметод изSparkSampleобъекта.import org.apache.spark.{SparkConf, SparkContext} object SparkSampleMain { def main (arg: Array[String]): Unit = { val conf = new SparkConf().setAppName("SparkSample") .set("spark.hadoop.validateOutputSpecs", "false") val sc = new SparkContext(conf) SparkSample.executeJob(sc, "wasb:///HdiSamples/HdiSamples/SensorSampleData/hvac/HVAC.csv", "wasb:///HVACOut") } }Повторите шаги 8 и 9, чтобы добавить новый объект
*SparkSampleScala. Добавьте следующий код в этот класс. Этот код считывает данные из HVAC.csv (доступно во всех кластерах HDInsight Spark). Он извлекает строки, имеющие только одну цифру в седьмом столбце в CSV-файле, а затем записывает выходные данные в /HVACOut в контейнер хранилища по умолчанию для кластера.import org.apache.spark.SparkContext object SparkSample { def executeJob (sc: SparkContext, input: String, output: String): Unit = { val rdd = sc.textFile(input) //find the rows which have only one digit in the 7th column in the CSV val rdd1 = rdd.filter(s => s.split(",")(6).length() == 1) val s = sc.parallelize(rdd.take(5)).cartesian(rdd).count() println(s) rdd1.saveAsTextFile(output) //rdd1.collect().foreach(println) } }Повторите шаги 8 и 9, чтобы добавить новый класс
RemoteClusterDebugging. Этот класс реализует платформу тестов Spark, которая используется для отладки приложений. Добавьте в классRemoteClusterDebuggingследующий код.import org.apache.spark.{SparkConf, SparkContext} import org.scalatest.FunSuite class RemoteClusterDebugging extends FunSuite { test("Remote run") { val conf = new SparkConf().setAppName("SparkSample") .setMaster("yarn-client") .set("spark.yarn.am.extraJavaOptions", "-Dhdp.version=2.4") .set("spark.yarn.jar", "wasb:///hdp/apps/2.4.2.0-258/spark-assembly-1.6.1.2.4.2.0-258-hadoop2.7.1.2.4.2.0-258.jar") .setJars(Seq("""C:\workspace\IdeaProjects\MyClusterApp\out\artifacts\MyClusterApp_DefaultArtifact\default_artifact.jar""")) .set("spark.hadoop.validateOutputSpecs", "false") val sc = new SparkContext(conf) SparkSample.executeJob(sc, "wasb:///HdiSamples/HdiSamples/SensorSampleData/hvac/HVAC.csv", "wasb:///HVACOut") } }Есть несколько важных вещей, которые следует отметить:
- Для
.set("spark.yarn.jar", "wasb:///hdp/apps/2.4.2.0-258/spark-assembly-1.6.1.2.4.2.0-258-hadoop2.7.1.2.4.2.0-258.jar")этого убедитесь, что JAR-файл сборки Spark доступен в хранилище кластера по указанному пути. - Для
setJarsукажите расположение, где создается JAR-файл артефакта. Как правило, это<Your IntelliJ project directory>\out\<project name>_DefaultArtifact\default_artifact.jar.
- Для
В классе
*RemoteClusterDebuggingщелкните правой кнопкой мыши на ключевом словеtest, затем выберите "Создать конфигурацию RemoteClusterDebugging".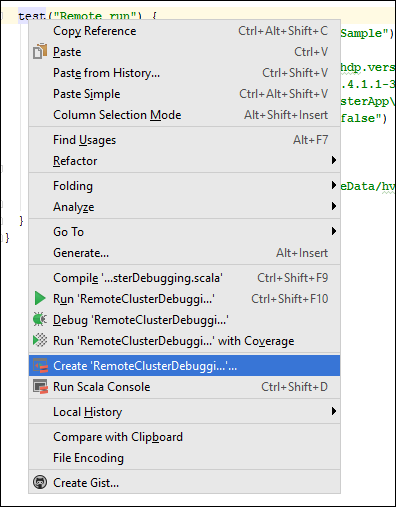
В диалоговом окне "Создание конфигурации RemoteClusterDebugging " укажите имя конфигурации, а затем выберите тип теста в качестве имени теста. Оставьте все остальные значения параметрами по умолчанию. Выберите Применить, а затем выберите ОК.
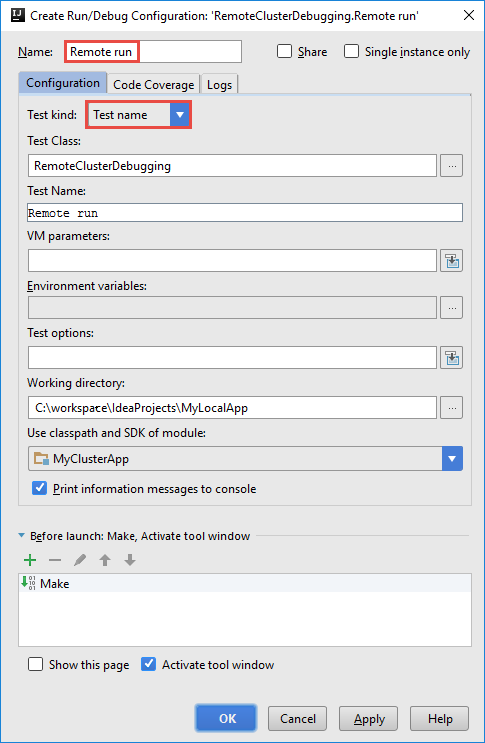
Теперь в строке меню появится раскрывающийся список конфигурации удаленного запуска .

Шаг 5. Запуск приложения в режиме отладки
В проекте IntelliJ IDEA откройте
SparkSample.scalaи создайте точку останова рядомval rdd1с ним. В всплывающем меню "Создать точку останова" выберите строку в функции executeJob.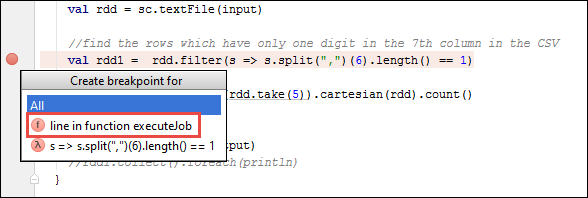
Чтобы запустить приложение, нажмите кнопку "Выполнить отладку " рядом с раскрывающимся списком конфигурации удаленного запуска .

Когда выполнение программы достигает точки останова, на нижней панели отображается вкладка отладчика .
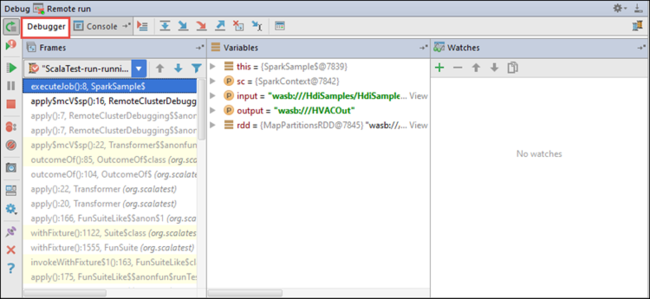
Чтобы добавить часы, щелкните значок (+).
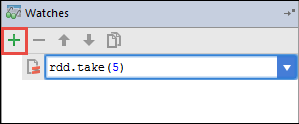
В этом примере приложение сломалось до того, как переменная
rdd1была создана. С помощью этого средства наблюдения можно увидеть первые пять строк в переменнойrdd. Выберите , введите.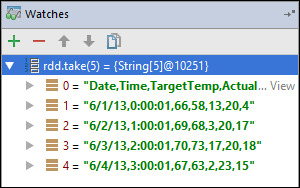
На предыдущем изображении видно, что во время выполнения можно запрашивать терабайты данных и отлаживать ход выполнения приложения. Например, в выходных данных, показанных на предыдущем изображении, видно, что первая строка выходных данных является заголовком. На основе этих выходных данных можно изменить код приложения, чтобы пропустить строку заголовка при необходимости.
Теперь можно выбрать значок "Возобновить программу ", чтобы продолжить выполнение приложения.
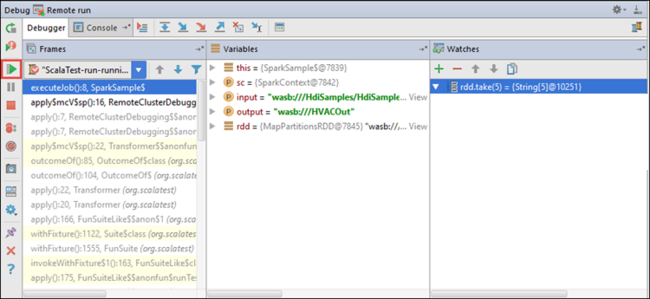
Если приложение завершится успешно, вы увидите следующие выходные данные:
Дальнейшие действия
Сценарии
- Apache Spark с BI: выполнение интерактивного анализа данных с использованием Spark в HDInsight и BI инструментов
- Apache Spark и Машинное обучение: использование Spark в HDInsight для анализа температуры в здании на основе данных HVAC
- Apache Spark и машинное обучение: использование Spark в HDInsight для прогнозирования результатов проверки пищевых продуктов
- Анализ журналов веб-сайтов с помощью Apache Spark в HDInsight
Создание и запуск приложений
- Создание автономного приложения с использованием Scala
- Удаленный запуск заданий с помощью Apache Livy в кластере Apache Spark
Инструменты и расширения
- Создание приложений Apache Spark для кластера HDInsight с помощью Azure Toolkit for IntelliJ
- Использование Набора средств Azure для IntelliJ для удаленной отладки приложений Apache Spark с помощью SSH
- Использование средств HDInsight в Azure Toolkit for Eclipse для создания приложений Apache Spark
- Используйте записные книжки Apache Zeppelin с кластером Apache Spark в HDInsight
- Ядра, доступные для Jupyter Notebook в кластере Apache Spark для HDInsight
- Использование внешних пакетов с Jupyter Notebook
- Установите Jupyter на свой компьютер и подключитесь к кластеру HDInsight Spark