Установка Jupyter Notebook на компьютере и ее подключение к Apache Spark в HDInsight
Из этой статьи вы узнаете, как установить Jupyter Notebook с пользовательскими ядрами PySpark (для Python) и Apache Spark (для Scala) с помощью магических команд Spark, а затем подключить эту записную книжку к кластеру HDInsight.
Для установки Jupyter и подключения к Apache Spark в HDInsight необходимо выполнить четыре основных шага.
- Настроить кластер Spark.
- Установить Jupyter Notebook.
- Установите ядра PySpark и Spark с помощью волшебной команды Spark.
- Настройте волшебную команду Spark для доступа к кластеру Spark в HDInsight.
Дополнительные сведения о пользовательских ядрах и магических командах Spark см. в разделе Ядра, доступные для Jupyter Notebook с кластерами Apache Spark Linux в HDInsight.
Необходимые компоненты
Кластер Apache Spark в HDInsight. Инструкции см. в статье Начало работы. Создание кластера Apache Spark в HDInsight на платформе Linux и выполнение интерактивных запросов с помощью SQL Spark. Локальная записная книжка подключается к кластеру HDInsight.
Опыт работы с записными книжками Jupyter и Spark в HDInsight.
Установка Jupyter Notebook на компьютер
Перед установкой Jupyter Notebook необходимо установить Python. Дистрибутив Anaconda установит как Python, так и Jupyter Notebook.
Скачайте установщик Anaconda для своей платформы и запустите программу установки. В мастере установки укажите параметр для добавления Anaconda в переменную PATH. См. также Установка Jupyter с помощью Anaconda.
Установка магических команд Spark
Введите команду
pip install sparkmagic==0.13.1, чтобы установить магические команды Spark для кластеров HDInsight версии 3.6 и 4.0. См. также документацию по sparkmagic.Убедитесь, что мини-приложение
ipywidgetsустановлено правильно. Для этого выполните следующую команду:jupyter nbextension enable --py --sys-prefix widgetsnbextension
Установка ядер PySpark и Spark
Определите место установки
sparkmagicс помощью следующей команды:pip show sparkmagicЗатем измените рабочий каталог на расположение, определенное с помощью команды выше.
В новом рабочем каталоге введите одну или несколько из приведенных ниже команд, чтобы установить требуемые ядра:
Ядро Команда Spark jupyter-kernelspec install sparkmagic/kernels/sparkkernelSparkR jupyter-kernelspec install sparkmagic/kernels/sparkrkernelPySpark jupyter-kernelspec install sparkmagic/kernels/pysparkkernelPySpark3 jupyter-kernelspec install sparkmagic/kernels/pyspark3kernelНеобязательно. Введите следующую команду, чтобы включить расширение сервера:
jupyter serverextension enable --py sparkmagic
Настройка волшебной команды Spark для подключения к кластеру HDInsight Spark
В этом разделе вы настроите подключение магической команды Spark, установленной ранее, к кластеру Apache Spark.
Запустите оболочку Python с помощью следующей команды:
pythonСведения о конфигурации Jupyter обычно хранятся в домашнем каталоге пользователей. Введите следующую команду, чтобы определить домашний каталог, и создайте папку с именем .sparkmagic. Будет выведен полный путь.
import os path = os.path.expanduser('~') + "\\.sparkmagic" os.makedirs(path) print(path) exit()В папке
.sparkmagicсоздайте файл config.json и добавьте в него следующий фрагмент кода JSON.{ "kernel_python_credentials" : { "username": "{USERNAME}", "base64_password": "{BASE64ENCODEDPASSWORD}", "url": "https://{CLUSTERDNSNAME}.azurehdinsight.net/livy" }, "kernel_scala_credentials" : { "username": "{USERNAME}", "base64_password": "{BASE64ENCODEDPASSWORD}", "url": "https://{CLUSTERDNSNAME}.azurehdinsight.net/livy" }, "custom_headers" : { "X-Requested-By": "livy" }, "heartbeat_refresh_seconds": 5, "livy_server_heartbeat_timeout_seconds": 60, "heartbeat_retry_seconds": 1 }Внесите в файл следующие изменения:
Значение шаблона Новое значение {USERNAME} Имя для входа в кластер, значение по умолчанию — admin.{CLUSTERDNSNAME} Имя кластера {BASE64ENCODEDPASSWORD} Фактический пароль в кодировке Base64. Сгенерировать пароль в кодировке base64 можно здесь: https://www.url-encode-decode.com/base64-encode-decode/. "livy_server_heartbeat_timeout_seconds": 60При использовании sparkmagic 0.12.7(кластеры версии 3.5 и 3.6) не заменяйте. При использованииsparkmagic 0.2.3(кластеры версии 3.4) замените на"should_heartbeat": true.Полный пример файла можно просмотреть в образце config.json.
Совет
Сигналы пульса отправляются, чтобы предотвратить утечку сеансов. При переходе в спящий режим или завершении работы компьютера пульс не отправляется, что приводит к очистке сеанса. Если вы хотите отключить такое поведение для кластеров версии 3.4, то можете настроить для параметра Livy
livy.server.interactive.heartbeat.timeoutзначение0с помощью пользовательского интерфейса Ambari. Если для кластеров версии 3.5 не настроить соответствующую конфигурацию, приведенную выше, то сеанс не будет удален.Запустите Jupyter. Выполните следующую команду из командной строки.
jupyter notebookУбедитесь, что вы можете использовать магическую команду Spark, доступную вместе с ядрами. Выполните следующие шаги.
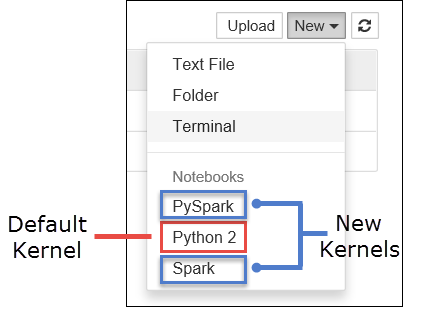
a. Создайте новую записную книжку. В правом верхнем углу щелкните Создать. Должны отобразиться ядро по умолчанию Python 2 или Python 3 и установленные ядра. Фактические значения могут отличаться в зависимости от выбранных вариантов установки. Выберите PySpark.
Внимание
Щелкнув Создать, проверьте оболочку на наличие ошибок. Если отображается сообщение об ошибке
TypeError: __init__() got an unexpected keyword argument 'io_loop', возможно, возникла известная проблема с определенными версиями Tornado. Если это так, завершите работу ядра, а затем перейдите на использование более ранней версии установки Tornado с помощью следующей команды:pip install tornado==4.5.3.b. Запустите следующий фрагмент кода.
%%sql SELECT * FROM hivesampletable LIMIT 5Если вы успешно получили выходные данные, подключение к кластеру HDInsight работает.
Если вы хотите обновить конфигурацию записной книжки для подключения к другому кластеру, измените файл config.json, указав новый набор значений, как показано на шаге 3.
Зачем устанавливать Jupyter на моем компьютере?
Причины, по которым требуется установить на компьютер Jupyter и подключить к кластеру Apache Spark в HDInsight.
- Предоставляет возможность создавать записные книжки локально, тестировать приложение в работающем кластере, а затем отправлять записные книжки в кластер. Для отправки записных книжек в кластер можно отправить их с помощью Jupyter Notebook, которая запущена на кластере, или сохранить их в папке
/HdiNotebooksв учетной записи хранения, связанной с кластером. Дополнительные сведения о хранении записных книжек в кластере см. в разделе Где хранятся записные книжки Jupyter. - С помощью локально доступных записных книжек вы сможете подключиться к различным кластерам Spark в зависимости от потребностей вашего приложения.
- Можно использовать GitHub для реализации системы управления версиями, чтобы контролировать версии записных книжек. Вы также можете создать среду совместной работы, в которой несколько пользователей будут работать с одной записной книжкой.
- Вы можете работать с записными книжками локально даже без кластера. Кластер нужен только для тестирования записных книжек, но не обязателен для ручного управления записными книжками или средой разработки.
- Возможно, вам будет проще настроить локальную среду разработки, чем настраивать установку Jupyter в кластере. Вы можете спокойно пользоваться любым программным обеспечением, установленным локально, не настраивая удаленные кластеры.
Предупреждение
Если Jupyter установлен на локальном компьютере, несколько пользователей могут одновременно запустить одну и ту же записную книжку в одном кластере Spark. В такой ситуации создаются несколько сеансов Livy. Если вы столкнетесь с проблемами и начнете их отладку, вам будет сложно определить, какой сеанс Livy какому пользователю принадлежит.