Устранение задержки или сбоя задания в кластере HDInsight
Если приложение, обрабатывающее данные в кластере HDInsight, работает медленно или завершается c кодом ошибки, есть несколько вариантов устранения этих неполадок. Если задания выполняются дольше ожидаемого времени или вы в целом наблюдаете малое время отклика, могут присутствовать неполадки с вышестоящими компонентами кластера, например, со службами, в которых он работает. Тем не менее самой распространенной причиной снижения производительности является недостаточное масштабирование. При создании кластера HDInsight выберите правильные размеры виртуальных машин.
Для диагностики задержки работы или сбоя кластера соберите сведения обо всех аспектах среды, например о связанных службах Azure, конфигурации кластера и выполнении задания. Можно также попытаться воспроизвести состояние ошибки на другом кластере.
- Шаг 1. Сбор сведений о проблеме.
- Шаг 2. Проверка среды кластера HDInsight.
- Шаг 3. Просмотр сведений о работоспособности кластера.
- Шаг 4. Просмотр версий и стека среды.
- Шаг 5. Анализ файлов журнала кластера.
- Шаг 6. Проверка параметров конфигурации.
- Шаг 7. Воспроизведение сбоя на другом кластере.
Шаг 1. Сбор сведений о проблеме
HDInsight предоставляет множество средств, которые можно использовать для определения и устранения проблем с кластерами. В приведенных ниже шагах описываются эти средства и приводятся возможные варианты выявления проблемы.
Определение проблемы
Чтобы определить проблему, стоит рассмотреть такие вопросы:
- Что должно было произойти согласно ожиданиям? Что произошло на самом деле?
- Сколько потребовалось времени для выполнения процесса? Сколько времени он должен был выполняться?
- Всегда ли задачи выполнялись медленно на этом кластере? Выполнялись ли они быстрее на другом кластере?
- Когда эта проблема была обнаружена впервые? Как часто она возникала с тех пор?
- Появились ли какие-либо изменения в конфигурации кластера?
Сведения о кластере
К важным сведениям о кластере относятся:
- Имя кластера
- регион кластера (проверьте сведения о простоях в регионе);
- тип и версия кластера HDInsight;
- тип и количество экземпляров HDInsight, указанных для головного и рабочего узлов.
Эти сведения можно получить на портале Azure:

Также можно использовать Azure CLI:
az hdinsight list --resource-group <ResourceGroup>
az hdinsight show --resource-group <ResourceGroup> --name <ClusterName>
Альтернативный вариант — использование PowerShell. Дополнительные сведения см. в статье Управление кластерами Apache Hadoop в HDInsight с помощью Azure PowerShell.
Шаг 2. Проверка среды кластера HDInsight
Работа каждого кластера HDInsight зависит от различных служб Azure и программного обеспечения с открытым кодом, например Apache HBase и Apache Spark. Другие службы Azure, например виртуальные сети Azure, также могут вызывать кластеры HDInsight. Сбой кластера может быть вызван любой запущенной в кластере службой или же внешней службой. Изменение конфигурации службы в кластере также может привести к сбою работы кластера.
Сведения о службах
- Проверьте версии выпуска библиотеки с открытым кодом.
- Проверьте наличие простоев службы Azure.
- Проверьте наличие ограничений использования службы Azure.
- Проверьте конфигурацию подсети в виртуальной сети Azure.
Просмотр параметров конфигурации кластера в пользовательском интерфейсе Ambari
Apache Ambari обеспечивает управление и мониторинг кластера HDInsight с помощью веб-интерфейса и REST API. Ambari есть в кластерах HDInsight на основе Linux. Выберите область Панель мониторинга кластера на странице HDInsight на портале Azure. Выберите область Панель мониторинга кластера HDInsight, чтобы открыть пользовательский интерфейс Ambari, и введите учетные данные для входа на кластер.
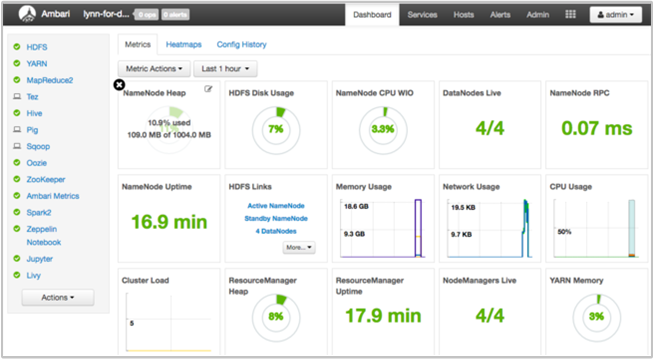
Чтобы открыть список представлений службы, на странице портала Azure выберите Просмотры Ambari. Этот список зависит от установленных библиотек. Например, в нем могут быть диспетчер очередей YARN, представления Hive и Tez. Выберите ссылку на службу для просмотра сведений о конфигурации и службе.
Проверка наличия простоев службы Azure
HDInsight использует несколько служб Azure. Он запускает виртуальные серверы на Azure HDInsight, хранит данные и скрипты в хранилище BLOB-объектов Azure или Azure Data Lake Storage, а также индексирует файлы журнала в табличном хранилище Azure. Сбои в этих службах, несмотря на их редкость, могут вызвать проблемы в работе кластера HDInsight. В случае задержки работы или сбоя кластера перейдите на панель мониторинга состояния Azure. Состояние каждой службы указывается по регионам. Проверьте регион кластера, а также регионы всех связанных служб.
Проверка ограничений использования службы Azure
Если вы запускаете большой кластер или запустили несколько кластеров одновременно, работа кластера может завершиться сбоем из-за превышения ограничений использования службы Azure. Ограничения использования службы различаются в зависимости от вашей подписки Azure. Дополнительные сведения см. в статье Подписка Azure, границы, квоты и ограничения службы. Можно отправить в корпорацию Майкрософт запрос на увеличение квоты ядер Resource Manager, чтобы увеличить количество доступных ресурсов HDInsight (например, ядер и экземпляров виртуальной машины).
Проверка версии выпуска
Сравните версию кластера с последним выпуском HDInsight. Каждый выпуск HDInsight содержит улучшения, например новые приложения, функции, обновления и исправления ошибок. Проблема, которая влияет на работу кластера, может быть исправлена в последней версии выпуска. Если возможно, повторно запустите кластер, используя последнюю версию HDInsight и связанных библиотек, таких как Apache HBase, Apache Spark и др.
Перезапуск служб кластера
В случае задержки в работе кластера мы рекомендуем перезапустить службы с помощью пользовательского интерфейса Ambari или классического интерфейса командной строки Azure. В кластере могут возникать нерегулярные ошибки, и перезапуск является наиболее быстрым способом стабилизации среды и возможного улучшения производительности.
Шаг 3. Просмотр сведений о работоспособности кластера
Кластеры HDInsight состоят из различных типов узлов, работающих на экземплярах виртуальной машины. Каждый узел можно отслеживать для обнаружения нехватки ресурсов, проблем с сетевым подключением и других проблем, которые могут замедлить работу кластера. Каждый кластер содержит два головных узла, а большинство типов кластера содержат рабочий и граничный узлы.
Описание различных узлов, используемых в каждом типе кластера, см. в статье Установка кластеров в HDInsight с использованием Hadoop, Spark, Kafka и других технологий.
В следующих разделах описывается, как проверить работоспособность каждого узла в кластере.
Получение снимка работоспособности кластера с помощью панели мониторинга пользовательского интерфейса Ambari
Панель мониторинга пользовательского интерфейса Ambari (https://<clustername>.azurehdinsight.net) предоставляет обзор работоспособности кластера, например время доступности, использование памяти, ЦП и сети, использование диска HDFS и прочее. Используйте раздел Ambari об узлах, чтобы просмотреть ресурсы на уровне узла. Можно также остановить и перезапустить службы.
Проверка службы WebHCat
Одним из типичных сценариев сбоя заданий Apache Hive, Apache Pig или Apache Sqoop является сбой службы WebHCat (или Templeton). WebHCat — это интерфейс REST для удаленного выполнения заданий, например Hive, Pig, Scoop и MapReduce. WebHCat преобразует запросы на отправку заданий в приложения Apache Hadoop YARN, а также возвращает состояние, производное от состояния приложения YARN. В следующих разделах описываются стандартные коды состояния HTTP в WebHCat.
Неверный шлюз (код состояния 502)
Этот код обозначает универсальное сообщение от узлов шлюза и является наиболее распространенным кодом состояния при сбоях. Одна из возможных причин этой ошибки — служба WebHCat вышла из строя на активном головном узле. Чтобы проверить это, используйте команду CURL ниже:
curl -u admin:{HTTP PASSWD} https://{CLUSTERNAME}.azurehdinsight.net/templeton/v1/status?user.name=admin
Ambari отображает оповещение, показывающее узлы, на которых служба WebHCat не работает. Можно попытаться возобновить работу службы WebHCat, перезапустив ее на головном узле.
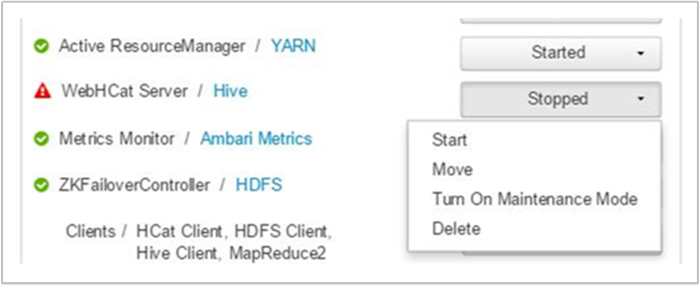
Если сервер WebHCat по-прежнему не работает, проверьте, есть ли в журнале операций сообщения о сбое. Чтобы получить более подробные сведения, проверьте файлы stderr и stdout, на которые приведена ссылка на узле.
Истекло время ожидания WebHCat
В шлюзе HDInsight время ожидания отклика истекает по окончании двух минут, после чего возвращается ошибка 502 BadGateway. WebHCat отправляет запросы состояний заданий к службам YARN, и если отклик YARN занимает более двух минут, время ожидания запроса истекает.
В таком случае просмотрите следующие журналы в каталоге /var/log/webhcat:
- webhcat.log — это журнал Log4j, на который сервер записывает журналы.
- webhcat-console.log представляет собой stdout сервера при запуске;
- webhcat-console-error.log представляет собой stderr процесса сервера.
Примечание.
Каждый журнал webhcat.log развертывается ежедневно, формируя файлы с именем webhcat.log.YYYY-MM-DD. Выберите соответствующий файл для исследуемого диапазона времени.
В следующих разделах описываются некоторые возможные причины истечения времени ожидания WebHCat.
Истечение времени ожидания на уровне WebHCat
При нагрузке WebHCat с более чем 10 открытыми сокетами требуется больше времени для установки новых подключений к сокету, что может привести к истечению времени ожидания. Чтобы получить список сетевых подключений к WebHCat и от нее, используйте команду netstat на текущем активном головном узле:
netstat | grep 30111
30111 — это порт, который прослушивает служба WebHCat. Количество открытых сокетов должно быть меньше 10.
Если нет открытых сокетов, предыдущая команда не создаст результат. Чтобы проверить, запущена и прослушивает ли служба Templeton на порте 30111, выполните команду:
netstat -l | grep 30111
Истечение времени ожидания на уровне YARN
Templeton вызывает YARN для выполнения заданий, а взаимодействие между Templeton и YARN может вызвать истечение времени ожидания.
На уровне YARN есть два типа истечения времени ожидания.
Отправка задания YARN может занять достаточно времени, чтобы вызвать истечение времени ожидания.
Если открыть файл журнала
/var/log/webhcat/webhcat.logи выполнить поиск задания, поставленного в очередь, можно увидеть несколько записей, где время выполнения чрезвычайно длительное (> 2000 мс), а также записи, в которых отображается превышенное время ожидания.Время для заданий, поставленных в очередь, постоянно увеличивается, так как скорость отправки новых заданий превышает скорость завершения старых заданий. После использования
joblauncher queueпамяти YARN 100 % емкость больше не может быть заимствована из очереди по умолчанию. Поэтому новые задания не могут быть приняты в очередь запуска заданий. Это поведение может увеличить время ожидания, что приведет к ошибке истечения времени ожидания, за которой последуют остальные ошибки.На следующем рисунке показана очередь средства запуска заданий с превышением 714,4 %. Достижение такого порога объясняется возможностью заимствовать свободную память в очереди по умолчанию. Тем не менее, когда кластер будет использоваться в полном объеме, а показатель потребления памяти YARN достигнет 100 %, новые задания будут поставлены в очередь, что в конечном итоге приведет к истечению времени ожидания.

Есть два способа решить эту проблему: снизить скорость отправки новых заданий или увеличить скорость потребления старых заданий с помощью увеличения масштаба кластера.
Обработка YARN может занять длительное время, что может привести к истечению времени ожидания.
Получение списка всех заданий — это вызов, требующий много времени для выполнения. Этот вызов перечисляет приложения из диспетчера ресурсов YARN и для каждого завершенного приложения получает состояние из YARN JobHistoryServer. При большом количестве заданий может произойти истечение времени ожидания этого вызова.
Получение списка заданий, выполненных более 7 дней назад, — на сервере HDInsight YARN JobHistoryServer настроено хранение сведений о завершенных заданиях в течение 7 дней (значение
mapreduce.jobhistory.max-age-ms). Попытка перечислить результаты очищенных заданий может вызвать истечение времени ожидания.
Чтобы диагностировать эти проблемы, сделайте следующее:
- Определите диапазон времени UTC для устранения неполадок.
- Выберите соответствующие файлы
webhcat.log. - Найдите предупреждающие сообщения и сообщения об ошибках, возникшие в течение этого времени.
Другие сбои WebHCat
Код состояния HTTP 500
В большинстве случаев, когда WebHCat возвращает код состояния 500, в сообщении об ошибке содержатся соответствующие сведения. Если же их нет, просмотрите, есть ли в журнале
webhcat.logпредупреждающие сообщения и сообщения об ошибках.Сбои задания
Возможны ситуации, когда взаимодействия с WebHCat выполняются успешно, но выполнение заданий завершается ошибкой.
Templeton собирает выходные данные в консоли задания как
stderrвstatusdir, что часто помогает в устранении сбоев.stderrсодержит идентификатор приложения YARN фактического запроса.
Шаг 4. Просмотр версий и стека среды
На странице стека и версии пользовательского интерфейса Ambari содержатся сведения о конфигурации служб в кластере и история версий служб. Неправильные версии библиотеки службы Hadoop могут стать причиной сбоя работы кластера. В пользовательском интерфейсе Ambari выберите меню Администратор, а затем — Стеки и версии. Выберите вкладку версий на странице, чтобы просмотреть сведения о версии службы:
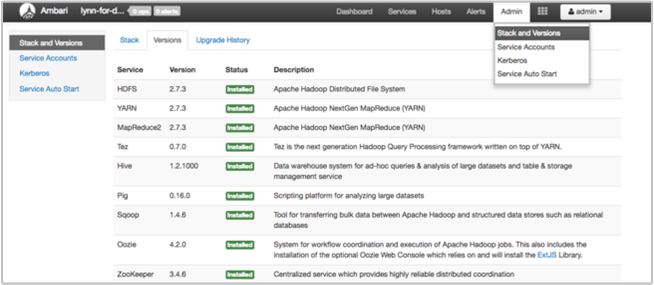
Шаг 5. Анализ файлов журнала
Есть несколько типов журналов, созданных из многих служб и компонентов, которые составляют кластер HDInsight. Файлы журнала WebHCat описаны выше. Есть несколько других полезных файлов журнала, которые можно изучить, чтобы сузить ряд возможных проблем в кластере. Этот вопрос рассматривается в разделах ниже.
Кластеры HDInsight состоят из нескольких узлов, большинство из которых ориентированы на запуск отправленных заданий. Задания выполняются одновременно, но в файлах журналов результаты могут отображаться только линейно. HDInsight выполняет новые задачи, а задачи, которые не удалось выполнить ранее, прерываются. Вся эта активность записывается в файлы
stderrиsyslog.В файлах журнала действий скрипта показаны ошибки или непредвиденные изменения конфигурации во время процесса создания в кластере.
Журналы шагов Hadoop идентифицируют задания Hadoop, запущенные как шаги, содержащие ошибки.
Проверка журналов действий скриптов
С помощью действий скриптов в HDInsight можно запускать скрипты в кластере вручную или в соответствии с указанным временем. Например, действия скрипта можно использовать для установки дополнительного программного обеспечения в кластере или изменения параметров конфигурации (сброса значений по умолчанию). Проверив журналы действий скрипта, вы получите дополнительные сведения об ошибках, случившихся во время настройки кластера. Состояние действия скрипта можно просмотреть, нажав кнопку ops в пользовательском интерфейсе Ambari, или с помощью журналов в учетной записи хранения по умолчанию.
Журналы действий скриптов находятся в каталоге \STORAGE_ACCOUNT_NAME\DEFAULT_CONTAINER_NAME\custom-scriptaction-logs\CLUSTER_NAME\DATE.
Просмотр журналов HDInsight с помощью быстрых ссылок Ambari
Пользовательский интерфейс Ambari HDInsight содержит ряд разделов быстрых ссылок. Чтобы получить доступ к ссылкам журнала определенной службы в кластере HDInsight, откройте пользовательский интерфейс Ambari для кластера, а затем выберите ссылку на службу в списке слева. Выберите раскрывающийся список быстрых ссылок, затем нужный узел HDInsight и выберите ссылку на ее связанный журнал.
Например, для журналов HDFS:
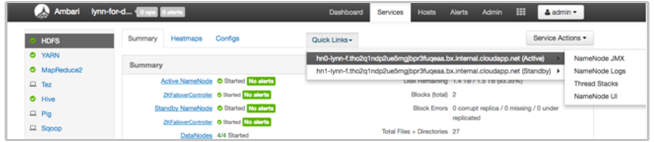
Просмотр файлов журнала, созданных в Hadoop
Кластер HDInsight создает журналы, которые записываются в таблицы и хранилище BLOB-объектов Azure. YARN создает собственные журналы выполнения. Дополнительные сведения см. в статье Управление журналами для кластера HDInsight.
Просмотр дампов кучи
Дампы кучи содержат снимок памяти приложения, включая значения переменных в это время, что полезно для диагностики проблем, возникающих во время выполнения. Дополнительные сведения см. в статье Включение дампов кучи для служб Apache Hadoop в HDInsight под управлением Linux.
Шаг 6. Проверка параметров конфигурации.
В кластерах HDInsight предварительно настроены параметры по умолчанию для связанных служб, таких как Hadoop, Hive, HBase и т. д. В зависимости от типа кластера, конфигурации оборудования, количества узлов, типов выполняемых заданий, а также данных, с которыми вы работаете (включая их обработку), может потребоваться оптимизация конфигурации.
Подробные инструкции по оптимизации конфигураций производительности для большинства сценариев см. в статье Использование Apache Ambari для оптимизации конфигураций кластеров HDInsight. При использовании Spark прочтите статью Оптимизация заданий Apache Spark.
Шаг 7. Воспроизведение ошибки на другом кластере
Для диагностики источника ошибки в кластере запустите новый кластер с той же конфигурацией, а затем последовательно выполните шаги, которые привели к сбою задания. Проверьте результаты каждого шага перед обработкой следующего. Этот метод позволяет исправить и повторно выполнить отдельный шаг, который вызвал сбой. Его преимущество также в том, что входные данные нужно загрузить только один раз.
- Создайте тестовый кластер с той же конфигураций, какая была у кластера, работа которого завершилась сбоем.
- Отправьте первый шаг задания в тестовый кластер.
- После того как он будет выполнен, проверьте наличие ошибок в файлах журнала шагов. Подключитесь к главному узлу тестового кластера и просмотрите на нем файлы журнала. Файлы журнала шагов появляются только после выполнения шага в течение определенного интервала, завершения или сбоя его выполнения.
- Если первый шаг выполнен успешно, запустите следующий. При наличии ошибки проанализируйте ее в файлах журнала. Если в коде есть ошибка, исправьте ее и выполните шаг повторно.
- Продолжайте, пока все шаги не будут выполнены без ошибок.
- После завершения отладки тестового кластера удалите его.
Следующие шаги
- Управление кластерами HDInsight с помощью веб-интерфейса Apache Ambari
- Анализ журналов HDInsight
- Доступ к журналам приложений Apache Hadoop YARN в HDInsight под управлением Linux
- Включение дампов кучи для служб Apache Hadoop в HDInsight под управлением Linux
- Известные проблемы в работе кластера Apache Spark в HDInsight