Доступ к журналам приложений Apache Hadoop YARN в HDInsight под управлением Linux
Узнайте, как получить доступ к журналам для приложений Apache Hadoop YARN (еще один переговорщик ресурсов) в кластере Apache Hadoop в Azure HDInsight.
Что такое Apache YARN?
YARN поддерживает несколько моделей программирования (в том числе Apache Hadoop MapReduce), отделяя управление ресурсами от планирования и мониторинга приложений. YARN использует глобальный диспетчер ResourceManager, диспетчеры узлов на каждый рабочий узел и диспетчеры приложений на каждое приложение. Диспетчер приложений согласовывает ресурсы (ЦП, память, диск, сеть), необходимые для работы приложения, с диспетчером ресурсов. Диспетчер ресурсов совместно с диспетчером узлов предоставляют эти ресурсы в виде контейнеров. Диспетчер приложений отвечает за отслеживание хода выполнения контейнеров, назначаемых ему диспетчером ресурсов. Приложению может потребоваться много контейнеров в зависимости от характера приложения.
Для выполнения приложения может потребоваться несколько попыток. Если выполнение приложения завершается ошибкой, его можно повторить как новую попытку. Каждая попытка выполняется в контейнере. В некотором смысле контейнер обеспечивает контекст основной единице работы, выполняемой приложением YARN, и вся работа, выполняемая в контексте контейнера, выполняется на одном рабочем узле, где был предоставлен контейнер. Дополнительные сведения см. в статьях Hadoop: написание приложений YARNи Apache Hadoop YARN.
Чтобы масштабировать кластер для поддержки большей пропускной способности обработки, можно использовать автомасштабирование или масштабировать кластеры вручную с помощью нескольких разных языков.
YARN Timeline Server
Apache Hadoop YARN Timeline Server предоставляет общие сведения о приложениях, завершивших работу.
YARN Timeline Server содержит следующие типы данных:
- уникальный идентификатор приложения;
- имя пользователя, запустившего приложение;
- информация о попытках завершить приложение;
- информация о контейнерах, которые использовались во время каждой из попыток.
Приложения и журналы YARN
Журналы приложений (и соответствующие журналы контейнеров) крайне важны для отладки проблемных приложений Hadoop. YARN предоставляет хорошую платформу для сбора, объединения и хранения журналов приложений с функцией объединения журналов.
Функция объединения журналов делает доступ к журналам приложений более детерминированным, так как она объединяет журналы со всех контейнеров на рабочем узле и хранит их как один сводный файл журнала на рабочем узле в файловой системе по умолчанию после завершения приложения. Ваше приложение может использовать сотни или тысячи контейнеров, но журналы для всех контейнеров, выполненных на одном рабочем узле, всегда объединяются в один файл. Таким образом, существует только один журнал на рабочий узел, используемый приложением. Объединение журналов включено по умолчанию на кластерах HDInsight версии 3.0 и более поздних версий. Объединенные журналы находятся в хранилище по умолчанию для кластера. В качестве пути HDFS к журналам используется следующий путь:
/app-logs/<user>/logs/<applicationId>
В пути user — это имя пользователя, запустившего приложение. applicationId является уникальным идентификатором, назначенным YARN RM приложению.
Агрегированные журналы не доступны напрямую для чтения, так как они записываются в TFileдвоичном формате, индексированном контейнером. Чтобы отобразить эти журналы для интересующих вас приложений или контейнеров в виде обычного текста, используйте журналы YARN ResourceManager или средства CLI.
Журналы YARN в кластере ESP
К пользовательскому файлу конфигурации mapred-site в Ambari необходимо добавить две конфигурации.
В веб-браузере перейдите на страницу
https://CLUSTERNAME.azurehdinsight.net, гдеCLUSTERNAME— это имя вашего кластера.В пользовательском интерфейсе Ambari выберите MapReduce2>Configs (Конфигурации)>Advanced (Дополнительно)>Custom mapred-site (Пользовательский файл mapred-site).
Добавьте один из следующих наборов свойств:
Набор 1
mapred.acls.enabled=true mapreduce.job.acl-view-job=*Набор 2
mapreduce.job.acl-view-job=<user1>,<user2>,<user3>Сохраните изменения и перезапустите все затронутые службы.
Средства CLI для YARN
С помощью команды ssh command подключитесь к кластеру. Измените следующую команду, заменив CLUSTERNAME именем кластера, а затем введите команду:
ssh sshuser@CLUSTERNAME-ssh.azurehdinsight.netПолучите список всех идентификаторов текущих выполняемых приложений Yarn с помощью следующей команды:
yarn topЗапишите идентификатор приложения, журналы которого нужно скачать, из столбца
APPLICATIONID.YARN top - 18:00:07, up 19d, 0:14, 0 active users, queue(s): root NodeManager(s): 4 total, 4 active, 0 unhealthy, 0 decommissioned, 0 lost, 0 rebooted Queue(s) Applications: 2 running, 10 submitted, 0 pending, 8 completed, 0 killed, 0 failed Queue(s) Mem(GB): 97 available, 3 allocated, 0 pending, 0 reserved Queue(s) VCores: 58 available, 2 allocated, 0 pending, 0 reserved Queue(s) Containers: 2 allocated, 0 pending, 0 reserved APPLICATIONID USER TYPE QUEUE #CONT #RCONT VCORES RVCORES MEM RMEM VCORESECS MEMSECS %PROGR TIME NAME application_1490377567345_0007 hive spark thriftsvr 1 0 1 0 1G 0G 1628407 2442611 10.00 18:20:20 Thrift JDBC/ODBC Server application_1490377567345_0006 hive spark thriftsvr 1 0 1 0 1G 0G 1628430 2442645 10.00 18:20:20 Thrift JDBC/ODBC ServerЭти журналы можно отобразить в виде обычного текста, запустив одну из указанных ниже команд.
yarn logs -applicationId <applicationId> -appOwner <user-who-started-the-application> yarn logs -applicationId <applicationId> -appOwner <user-who-started-the-application> -containerId <containerId> -nodeAddress <worker-node-address>При выполнении этих команд необходимо указать параметры <applicationId>, <user-who-started-the-application>, <containerId> и <worker-node-address>.
Другие примеры команд
Скачайте журналы контейнеров Yarn для всех мастеров приложений с помощью следующей команды. На этом шаге создается файл журнала с именем
amlogs.txtв текстовом формате.yarn logs -applicationId <application_id> -am ALL > amlogs.txtСкачайте журналы только для последнего основного контейнера приложения Yarn с помощью следующей команды:
yarn logs -applicationId <application_id> -am -1 > latestamlogs.txtСкачайте журналы для первых двух основных контейнеров приложения Yarn с помощью следующей команды:
yarn logs -applicationId <application_id> -am 1,2 > first2amlogs.txtСкачайте все журналы контейнеров приложения Yarn с помощью следующей команды:
yarn logs -applicationId <application_id> > logs.txtСкачайте журнал контейнера Yarn для определенного контейнера с помощью следующей команды:
yarn logs -applicationId <application_id> -containerId <container_id> > containerlogs.txt
Пользовательский интерфейс YARN ResourceManager
Пользовательский интерфейс YARN ResourceManager работает на головном узле кластера. Доступ к нему осуществляется через веб-интерфейс Ambari. Чтобы просмотреть журналы YARN, выполните следующие действия:
В браузере перейдите по адресу
https://CLUSTERNAME.azurehdinsight.net. Замените CLUSTERNAME именем кластера HDInsight.В списке служб в левой части страницы выберите YARN.
В раскрывающемся списке Быстрые ссылки выберите один из головных узлов кластера, а затем —
ResourceManager Log.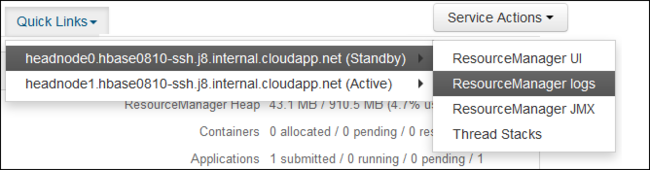
Отобразится список ссылок на журналы YARN.