Ручное масштабирование кластеров Azure HDInsight
HDInsight обеспечивает гибкость, предоставляя возможность увеличивать и уменьшать количество рабочих узлов в кластерах. Такая эластичность позволяет уменьшать размер кластера в нерабочее время или в выходные дни и расширять его во время пиковых бизнес-нагрузок.
Перед периодической пакетной обработкой увеличьте масштаб кластера, чтобы у кластера было достаточно ресурсов. После завершения обработки и снижения потребления ресурсов уменьшите масштаб кластера HDInsight, сократив количество рабочих узлов.
Вы можете масштабировать кластер вручную с помощью одного из следующих методов. Вы также можете использовать параметры автомасштабирования для автоматического увеличения и уменьшения в зависимости от определенных метрик.
Примечание.
Поддерживаются только кластеры HDInsight версии 3.1.3 или более поздней. Если вы не знаете версию кластера, см. страницу «Свойства».
Служебные программы для масштабирования кластеров
Майкрософт предоставляет следующие служебные программы для масштабирования кластеров.
| Utility | Description |
|---|---|
| PowerShell Az |
Set-AzHDInsightClusterSize
-ClusterName CLUSTERNAME -TargetInstanceCount NEWSIZE
|
| Azure CLI |
az hdinsight resize
--resource-group RESOURCEGROUP --name CLUSTERNAME --workernode-count NEWSIZE
|
| Классический Azure CLI | azure hdinsight cluster resize CLUSTERNAME NEWSIZE |
| Портал Azure | Откройте панель кластера HDInsight, в меню слева выберите Размер кластера, затем на панели размера кластера введите число рабочих узлов и нажмите кнопку "Сохранить". |
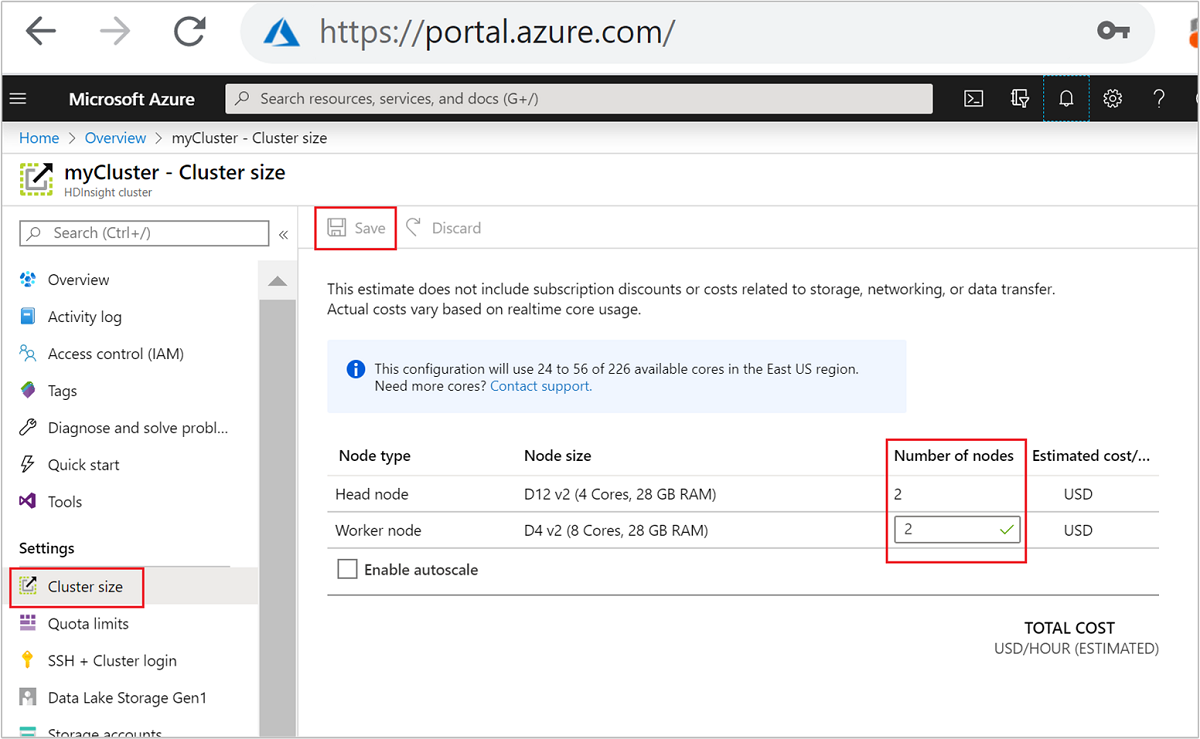
С помощью любого из этих методов можно увеличивать или уменьшать масштаб кластера HDInsight за считанные минуты.
Внимание
Влияние операций масштабирования
При добавлении узлов в запущенный кластер HDInsight (увеличение масштаба) задания остаются небезопасными. Во время масштабирования можно безопасно передать новые задания. Если операция масштабирования завершается сбоем, сбой покидает кластер в функциональном состоянии.
Если удалить узлы (уменьшить масштаб), ожидающие или выполняющиеся задания завершаются сбоем при завершении операции масштабирования. Этот сбой вызван тем, что некоторые службы перезапускаются во время процесса уменьшения масштаба. Кластер может зависнуть в защищенном режиме во время операции масштабирования вручную.
Ниже представлены возможности, связанные с изменением количества узлов данных в кластере каждого типа, поддерживаемого в HDInsight:
Apache Hadoop
Вы можете легко увеличивать количество рабочих узлов в работающем кластере Hadoop. Это не повлияет ни на какие задания. В ходе выполнения операции можно также отправлять новые задания. Сбои в операции масштабирования аккуратно обрабатываются. Кластер всегда остается в рабочем состоянии.
Когда в кластере Hadoop количество узлов данных сокращается, некоторые службы перезапускаются. Это приведет к сбою всех выполняющихся и ожидающих заданий при завершении операции масштабирования. Однако после завершения операции вы можете повторно отправить задания.
Apache HBase
Вы можете с легкостью добавлять и удалять узлы в работающем кластере HBase. Балансировка региональных серверов выполняется автоматически в течение нескольких минут после завершения операции масштабирования. Однако можно вручную сбалансировать региональные серверы. Войдите в кластер головного узла и выполните следующие команды.
pushd %HBASE_HOME%\bin hbase shell balancerДополнительные сведения об использовании оболочки HBase см. в статье Начало работы с примером Apache HBase в HDInsight.
Примечание.
Не несет ответственности за кластеры Kafka.
Apache Hive LLAP
После масштабирования до
Nрабочих узлов HDInsight автоматически установите следующие конфигурации и перезапустите Hive.- Максимальное число одновременных запросов:
hive.server2.tez.sessions.per.default.queue = min(N, 32) - Число узлов, используемых Hive LLAP:
num_llap_nodes = N - Число узлов для запуска управляющей программы Hive LLAP:
num_llap_nodes_for_llap_daemons = N
- Максимальное число одновременных запросов:
Безопасное уменьшение масштаба кластера
Уменьшение масштаба кластера с выполняющимися заданиями
Существует три способа избежать сбоя выполняющихся заданий во время операции уменьшения масштаба.
- Дождитесь завершения заданий, прежде чем уменьшать масштаб кластера.
- Завершите задания вручную.
- Повторно отправьте задания после завершения операции масштабирования.
Список ожидающих или выполняемых заданий можно просмотреть с помощью пользовательского интерфейса Resource Manager в YARN, выполнив следующие действия.
На портале Azure выберите свой кластер. Кластер откроется на новой странице портала.
В главном представлении последовательно выберите Панели мониторинга кластера>Домашняя страница Ambari. Введите учетные данные кластера.
В пользовательском интерфейсе Ambari выберите YARN в списке служб в меню слева.
На странице YARN выберите Быстрые ссылки и наведите указатель мыши на активный головной узел, а затем щелкните пользовательский интерфейс Resource Manager.
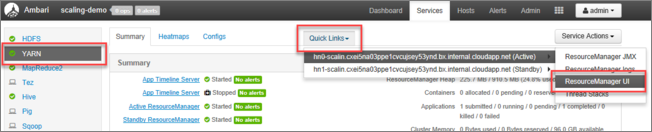
Вы можете открыть пользовательский интерфейс Resource Manager напрямую с помощью https://<HDInsightClusterName>.azurehdinsight.net/yarnui/hn/cluster.
Вы увидите список заданий и их текущее состояние. На снимке экрана видно, что в текущий момент выполняется одно задание:

Чтобы вручную завершить работу запущенного приложения, из оболочки SSH выполните команду ниже:
yarn application -kill <application_id>
Например:
yarn application -kill "application_1499348398273_0003"
Возникла проблема в безопасном режиме
При уменьшении масштаба кластера HDInsight использует интерфейсы управления Apache Ambari для первого списания лишних рабочих узлов. Узлы реплицируют свои блоки HDFS в другие сетевые рабочие узлы. После этого HDInsight безопасно уменьшает масштаб кластера. Во время операции масштабирования HDFS переходит в безопасный режим. Предполагается, что HDFS после завершения масштабирования вернется в нормальный режим. Однако в некоторых случаях HDFS застревает в безопасном режиме во время операции масштабирования из-за блокирования файла при репликации.
По умолчанию HDFS настраивается с параметром dfs.replication, имеющим значение 1. Этот параметр определяет, сколько копий каждого блока файлов доступно. Все копии блока файла хранятся на разных узлах кластера.
Если ожидаемое число копий блока недоступно, HDFS переходит в безопасный режим, а Ambari создает предупреждения. HDFS может переходить в безопасный режим для операции масштабирования. Кластер может застрять в безопасном режиме, если для репликации не обнаружено необходимое количество узлов.
Примеры ошибок, когда включен безопасный режим
org.apache.hadoop.hdfs.server.namenode.SafeModeException: Cannot create directory /tmp/hive/hive/819c215c-6d87-4311-97c8-4f0b9d2adcf0. Name node is in safe mode.
org.apache.http.conn.HttpHostConnectException: Connect to active-headnode-name.servername.internal.cloudapp.net:10001 [active-headnode-name.servername. internal.cloudapp.net/1.1.1.1] failed: Connection refused
Вы можете изучить журналы узла имени в папке /var/log/hadoop/hdfs/ примерно в то же время, когда было выполнено масштабирование кластера, чтобы проследить, когда был активирован безопасный режим. Файлам журнала присвоено имя Hadoop-hdfs-namenode-<active-headnode-name>.*.
Основной причиной была зависимость Hive от временных файлов в HDFS во время выполнения запросов. Когда HDFS переходит в безопасный режим, Hive не может выполнять запросы, так как не удается произвести запись в HDFS. Временные файлы в HDFS находятся на локальном диске, подключенном к виртуальным машинам отдельных рабочих узлов. Файлы реплицируются между другими рабочими узлами как минимум в трех репликах.
Как предотвратить застревание HDInsight в безопасном режиме
Есть несколько способов предотвратить зависание HDInsight в безопасном режиме.
- Остановите все задания Hive перед уменьшением масштаба HDInsight. Кроме того, можно запланировать операцию уменьшения масштаба, чтобы избежать конфликта с запущенными заданиями Hive.
- Вручную очистите пустые файлы в каталоге
tmpHive в HDFS, а затем приступите к уменьшению масштаба. - Выполните уменьшение масштаба HDInsight как минимум до трех рабочих узлов. Старайтесь избежать масштабирования до одного рабочего узла.
- При необходимости выполните команду, чтобы отключить безопасный режим.
В разделах ниже описываются эти параметры.
Остановка всех заданий Hive
Остановите все задания Hive перед уменьшением масштаба до одного рабочего узла. Если запланирована рабочая нагрузка, выполните уменьшение масштаба после завершения работы Hive.
Остановите задания Hive перед масштабированием, чтобы свести к минимуму количество цараповых файлов в папке tmp (если таковые есть).
Очистка пустых файлов Hive вручную
Если при работе Hive остались временные файлы, их можно вручную очистить, а затем выполнить уменьшение масштаба, чтобы избежать активации безопасного режима.
Проверьте, какое расположение используется для временных файлов Hive, просмотрев свойство конфигурации
hive.exec.scratchdir. Этот параметр задается в/etc/hive/conf/hive-site.xml:<property> <name>hive.exec.scratchdir</name> <value>hdfs://mycluster/tmp/hive</value> </property>Остановите службы Hive и убедитесь, что выполнены все задания и запросы.
Получите список содержимого указанного выше вспомогательного каталога
hdfs://mycluster/tmp/hive/, чтобы увидеть, содержит ли он какие-либо файлы:hadoop fs -ls -R hdfs://mycluster/tmp/hive/hiveНиже приведен пример выходных данных при наличии файлов:
sshuser@scalin:~$ hadoop fs -ls -R hdfs://mycluster/tmp/hive/hive drwx------ - hive hdfs 0 2017-07-06 13:40 hdfs://mycluster/tmp/hive/hive/4f3f4253-e6d0-42ac-88bc-90f0ea03602c drwx------ - hive hdfs 0 2017-07-06 13:40 hdfs://mycluster/tmp/hive/hive/4f3f4253-e6d0-42ac-88bc-90f0ea03602c/_tmp_space.db -rw-r--r-- 3 hive hdfs 27 2017-07-06 13:40 hdfs://mycluster/tmp/hive/hive/4f3f4253-e6d0-42ac-88bc-90f0ea03602c/inuse.info -rw-r--r-- 3 hive hdfs 0 2017-07-06 13:40 hdfs://mycluster/tmp/hive/hive/4f3f4253-e6d0-42ac-88bc-90f0ea03602c/inuse.lck drwx------ - hive hdfs 0 2017-07-06 20:30 hdfs://mycluster/tmp/hive/hive/c108f1c2-453e-400f-ac3e-e3a9b0d22699 -rw-r--r-- 3 hive hdfs 26 2017-07-06 20:30 hdfs://mycluster/tmp/hive/hive/c108f1c2-453e-400f-ac3e-e3a9b0d22699/inuse.infoЕсли эти файлы обработаны Hive, их можно удалить. Просмотрите страницу пользовательского интерфейса Yarn Resource Manager, чтобы убедиться в отсутствии запущенных запросов Hive.
Пример командной строки для удаления файлов из HDFS:
hadoop fs -rm -r -skipTrash hdfs://mycluster/tmp/hive/
Масштабирование HDInsight до трех или более рабочих узлов
Если кластеры постоянно задерживаются в безопасном режиме при сокращении количества рабочих узлов до менее трех, следует поддерживать по крайней мере три рабочих узла.
Наличие трех рабочих узлов обходится дороже, чем одного рабочего узла. Однако это действие предотвращает зависание кластера в безопасном режиме.
Уменьшение масштаба HDInsight до одного рабочего узла
Даже если кластер масштабируется до одного узла, рабочий узел 0 по-прежнему сохраняется. Рабочий узел 0 нельзя списать.
Выполнение команды для отключения безопасного режима
Последний вариант — выполнить команду выхода из безопасного режима. Если HDFS вошел в безопасный режим из-за файла Hive в процессе репликации, выполните следующую команду, чтобы выйти из безопасного режима:
hdfs dfsadmin -D 'fs.default.name=hdfs://mycluster/' -safemode leave
Уменьшение масштаба кластера Apache HBase
В течение нескольких минут после завершения операции масштабирования автоматически выполняется балансировка нагрузки на региональные серверы. Чтобы вручную распределить нагрузку между региональными серверами, выполните следующие действия.
Подключитесь к кластеру HDInsight по протоколу SSH. Дополнительные сведения см. в статье Подключение к HDInsight (Hadoop) с помощью SSH.
Запустите оболочку HBase:
hbase shellИспользуйте команду ниже, чтобы вручную распределить нагрузку между региональными серверами:
balancer
Следующие шаги
Подробные сведения о масштабировании кластера HDInsight см. в следующих статьях.