Отправка запросов в Apache Hive с помощью драйвера JDBC в HDInsight
Узнайте, как использовать драйвер JDBC из приложения Java. Отправка запросов Apache Hive в Apache Hadoop в Azure HDInsight. Сведения в этом документе демонстрируют, как программно подключаться и от SQuirreL SQL клиента.
Дополнительные сведения об интерфейсе JDBC Hive см. в статье HiveJDBCInterface.
Необходимые компоненты
- Кластер HDInsight Hadoop. Дополнительные сведения о создании кластера см. в статье Приступая к работе с Hadoop в HDInsight. Убедитесь, что служба HiveServer2 запущена.
- Java Developer Kit (JDK) версии 11 или более поздней.
- SQuirreL SQL. SQuirreL представляет собой клиентское приложение JDBC.
Строка подключения JDBC
Подключения JDBC к кластеру HDInsight в Azure осуществляются через порт 443. Трафик защищен с помощью TLS/SSL. Открытый шлюз, за которым находятся кластеры, перенаправляет трафик к порту, который фактически прослушивается HiveServer2. В следующей строке подключения показан формат для HDInsight:
jdbc:hive2://CLUSTERNAME.azurehdinsight.net:443/default;transportMode=http;ssl=true;httpPath=/hive2
Замените CLUSTERNAME на имя вашего кластера HDInsight.
Имя узла в строке подключения
Имя узла CLUSTERNAME.azurehdinsight.net в строке подключения совпадает с URL-адресом кластера. Его можно получить на портале Azure.
Порт в строке подключения
Порт 443 можно использовать только для подключения к кластеру из некоторых мест за пределами виртуальной сети Azure. HDInsight — это управляемая служба, которая означает, что все подключения к кластеру управляются через безопасный шлюз. Вы не можете подключиться к HiveServer 2 напрямую через порты 10001 или 10000. Эти порты не видны снаружи.
Проверка подлинности
При установке подключения укажите имя администратора кластера HDInsight и пароль для проверки подлинности. При подключении клиентов JDBC, например SQuirreL SQL, необходимо ввести имя и пароль администратора в параметрах клиента.
При подключении из приложения Java необходимо использовать имя пользователя и пароль. Например, следующий код Java открывает новое соединение:
DriverManager.getConnection(connectionString,clusterAdmin,clusterPassword);
Подключение с использованием клиента SQuirreL SQL
SQuirreL SQL — клиент JDBC, который можно использовать для удаленного выполнения запросов Hive с кластером HDInsight. В следующих шагах предполагается, что SQuirreL SQL уже установлен.
Создайте каталог, в котором будут храниться определенные файлы, копируемые из кластера.
В следующем сценарии замените
sshuserименем учетной записи пользователя SSH для кластера. ЗаменитеCLUSTERNAMEименем кластера HDInsight. В командной строке измените рабочий каталог на созданный на предыдущем шаге, а затем введите следующую команду, чтобы скопировать файлы из кластера HDInsight:scp sshuser@CLUSTERNAME-ssh.azurehdinsight.net:/usr/hdp/current/hadoop-client/{hadoop-auth.jar,hadoop-common.jar,lib/log4j-*.jar,lib/slf4j-*.jar,lib/curator-*.jar} . -> scp sshuser@CLUSTERNAME-ssh.azurehdinsight.net:/usr/hdp/current/hadoop-client/{hadoop-auth.jar,hadoop-common.jar,lib/reload4j-*.jar,lib/slf4j-*.jar,lib/curator-*.jar} . scp sshuser@CLUSTERNAME-ssh.azurehdinsight.net:/usr/hdp/current/hive-client/lib/{commons-codec*.jar,commons-logging-*.jar,hive-*-*.jar,httpclient-*.jar,httpcore-*.jar,libfb*.jar,libthrift-*.jar} .Запустите приложение SQuirreL SQL. В левой части окна выберите Драйверы.

Среди значков в верхней части диалогового окна Drivers (Драйверы) щелкните значок + для создания драйвера.
В диалоговом окне "Добавленный драйвер" добавьте следующие сведения:
Свойство Значение Имя. Куст Пример URL-адреса jdbc:hive2://localhost:443/default;transportMode=http;ssl=true;httpPath=/hive2Путь к дополнительным классам Нажмите кнопку Добавить, чтобы добавить все скачанные ранее JAR-файлы. Имя класса org.apache.hive.jdbc.HiveDriver 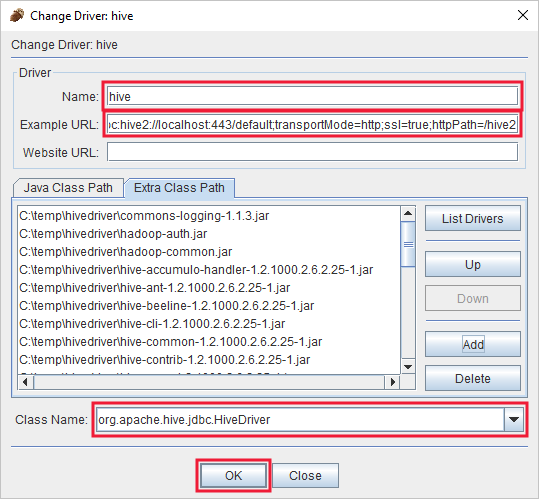
Нажмите кнопку ОК, чтобы сохранить эти параметры.
В левой части окна SQuirreL SQL выберите Псевдонимы. Затем щелкните значок +, чтобы создать псевдоним для подключения.
В диалоговом окне Добавить псевдоним укажите следующие значения:
Свойство Значение Имя. Hive в HDInsight Драйвер Выберите драйвер Hive в раскрывающемся списке. URL jdbc:hive2://CLUSTERNAME.azurehdinsight.net:443/default;transportMode=http;ssl=true;httpPath=/hive2. Замените CLUSTERNAME именем кластера HDInsight.Имя пользователя Имя пользователя для учетной записи входа кластера HDInsight. По умолчанию — admin. Пароль Пароль для учетной записи входа кластера. 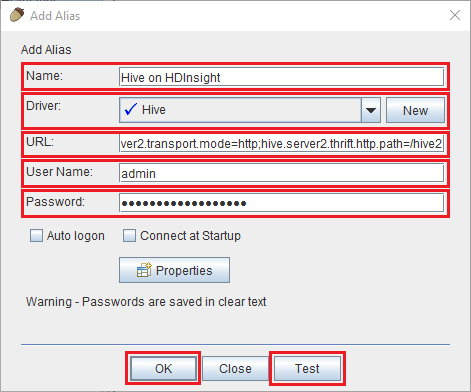
Внимание
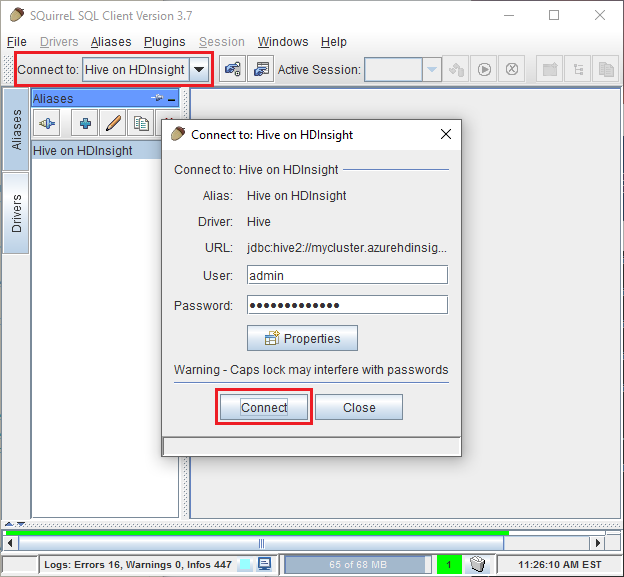
Нажмите кнопку Проверить, чтобы убедиться, что подключение работает. При появлении диалогового окна Connect to: Hive on HDInsight (Подключение: Hive в HDInsight) выберите Подключиться, чтобы выполнить проверку. Если проверка пройдет успешно, вы увидите диалоговое окно Connection successful (Подключение выполнено успешно). При возникновении ошибки см. раздел Устранение неполадок.
Чтобы сохранить псевдоним подключения, в нижней части диалогового окна Add Alias (Добавить псевдоним) нажмите кнопку ОК.
В раскрывающемся списке Подключиться к в верхней части окна SQuirreL SQL выберите Hive on HDInsight (Hive в HDInsight). При появлении запроса выберите Подключиться.
После подключения введите следующий запрос в диалоговое окно запроса SQL, а затем нажмите кнопку Запустить (значок в виде бегущего человека). В области результатов должны появиться результаты запроса.
select * from hivesampletable limit 10;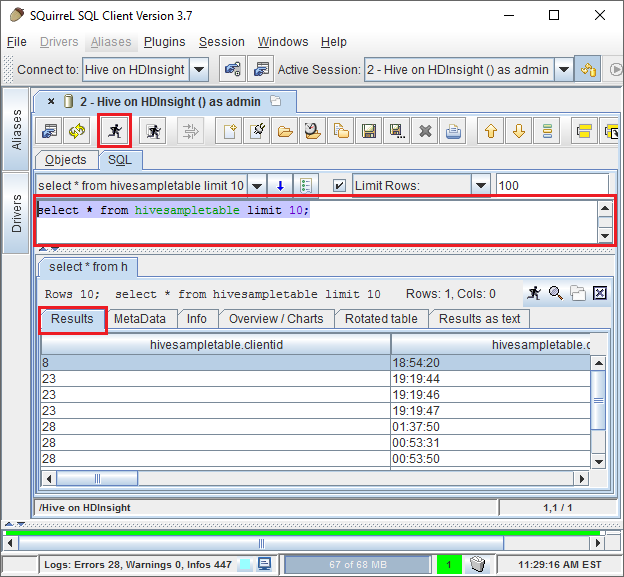
Подключение из примера приложения Java
Пример использования клиента Java для запросов Hive доступен в https://github.com/Azure-Samples/hdinsight-java-hive-jdbc. Следуйте инструкциям в репозитории, чтобы построить и запустить образец.
Устранение неполадок
Непредвиденная ошибка при попытке открыть подключение к SQL
Признаки. При подключении к кластеру HDInsight версии 3.3 или более поздней может появиться сообщение о возникновении непредвиденной ошибки. Трассировка стека для этой ошибки начинается со следующих строк:
java.util.concurrent.ExecutionException: java.lang.RuntimeException: java.lang.NoSuchMethodError: org.apache.commons.codec.binary.Base64.<init>(I)V
at java.util.concurrent.FutureTas...(FutureTask.java:122)
at java.util.concurrent.FutureTask.get(FutureTask.java:206)
Причина. Эту ошибку вызывают прежние версии файла commons-codec.jar в составе SQuirreL.
Решение. Чтобы устранить эту ошибку, выполните приведенные далее действия.
Закройте SQuirreL, а затем перейдите в каталог, где установлен SQuirreL, вероятно, это
C:\Program Files\squirrel-sql-4.0.0\lib. В каталоге SquirreL в каталогеlibзамените существующий файл commons-codec.ja файлом, скачанным из кластера HDInsight.Перезапустите SQuirreL. При последующих подключениях к Hive в HDInsight ошибка больше не должна возникать.
Подключение отключено с помощью HDInsight
Симптомы: HDInsight неожиданно отключает подключение при попытке скачать огромный объем данных (например, несколько ГБИТ) через JDBC/ODBC.
Причина. Ограничение узлов шлюза приводит к этой ошибке. При получении данных из JDBC/ODBC все данные должны передаваться через узел шлюза. Однако шлюз не предназначен для загрузки огромного объема данных, поэтому шлюз может закрыть подключение, если он не может обработать трафик.
Решение: избегайте использования драйвера JDBC/ODBC для загрузки огромных объемов данных. Вместо этого следует копировать данные непосредственно из хранилища больших двоичных объектов.
Следующие шаги
Теперь, когда вы узнали, как использовать JDBC для работы с Hive, воспользуйтесь следующими ссылками, чтобы изучить другие способы работы с Azure HDInsight.
- Визуализация данных Apache Hive с помощью Microsoft Power BI в Azure HDInsight
- Visualize Interactive Query Hive data with Microsoft Power BI using DirectQuery in Azure HDInsight (Визуализация данных Hive из кластера Interactive Query с помощью Microsoft Power BI и DirectQuery в Azure HDInsight).
- Подключение Excel к Hadoop в Azure HDInsight с помощью Microsoft Hive ODBC Driver
- Подключение Excel к Apache Hadoop с помощью Power Query
- Использование Apache Hive с HDInsight
- Использование Apache Pig с HDInsight
- Использование заданий MapReduce с HDInsight