Пробелы между заданиями Spark
Таким образом, вы видите пробелы в временной шкале заданий, как показано ниже:
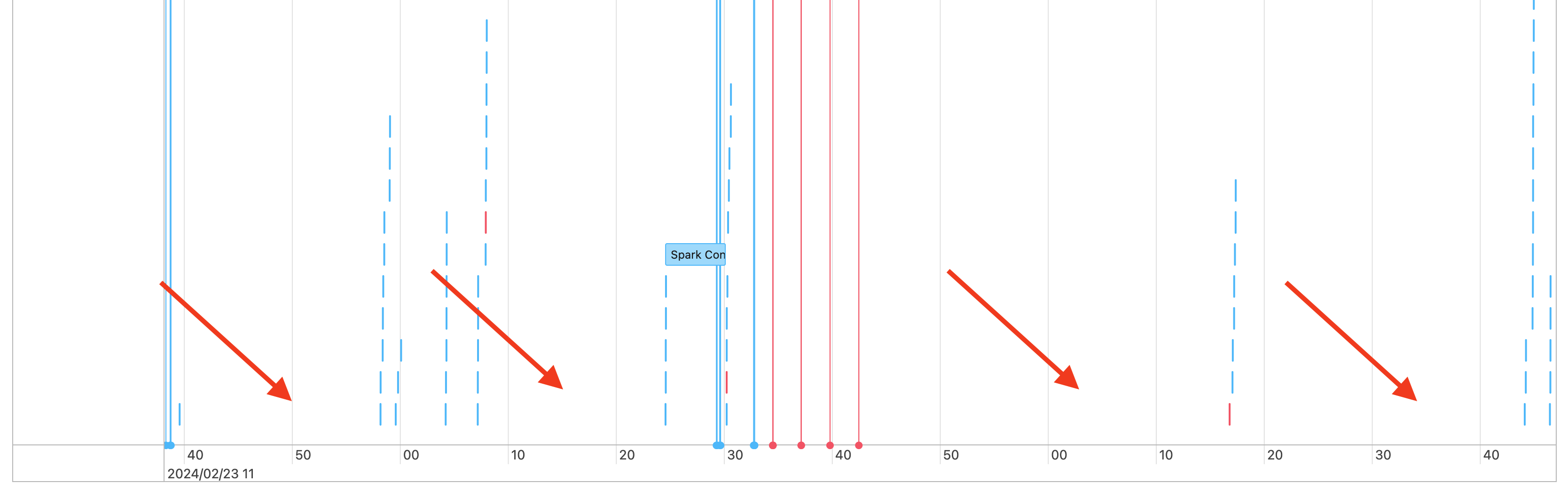
Существует несколько причин, по которым это может произойти. Если пробелы составляют большую часть времени, затраченного на рабочую нагрузку, необходимо выяснить, что вызывает эти пробелы, и если это ожидается или нет. Есть несколько вещей, которые могут произойти во время пробелов:
- Нет работы, чтобы сделать
- Драйвер компилируется сложный план выполнения
- Выполнение кода, отличного от spark
- Драйвер перегружен
- Кластер неисправен
Нет работы
На вычислительных узлах общего назначения , отсутствие работы, вероятно, является основным объяснением этих пробелов на. Так как кластер выполняется и пользователи отправляют запросы, ожидается пробелы. Эти пробелы — это время между отправками запросов.
Сложный план выполнения
Например, если вы используете withColumn() в цикле, он создает очень дорогой план обработки. Пробелы могут быть временем, когда водитель тратит просто строительство и обработку плана. Если это так, попробуйте упростить код. Используется selectExpr() для объединения нескольких withColumn() вызовов в одно выражение или преобразования кода в SQL. Вы по-прежнему можете внедрить SQL в код Python с помощью Python для управления запросом с помощью строковых функций. Это часто устраняет эту проблему.
Выполнение кода, отличного от Spark
Код Spark написан в SQL или с помощью API Spark, например PySpark. Любое выполнение кода, не являющегося Spark, будет отображаться на временной шкале в виде пробелов. Например, можно создать цикл в Python, который вызывает собственные функции Python. Этот код не выполняется в Spark, и он может отображаться как пробел в временной шкале. Если вы не уверены, запущен ли ваш код Spark, попробуйте запустить его в интерактивном режиме в записной книжке. Если код использует Spark, в ячейке будут отображаться задания Spark:

Вы также можете развернуть раскрывающийся список заданий Spark под ячейкой, чтобы узнать, активно ли выполняются задания (в случае простоя Spark). Если вы не используете Spark, вы не увидите задания Spark в ячейке или вы увидите, что нет активных. Если вы не можете запустить код в интерактивном режиме, попробуйте войти в код и увидеть, можно ли сопоставить пробелы с разделами кода по метке времени, но это может быть сложно.
Если вы видите пробелы в временной шкале, вызванные запуском кода, отличного от Spark, это означает, что все ваши работники простои и, вероятно, тратить деньги во время пробелов. Может быть, это намеренно и неизбежно, но если вы можете написать этот код для использования Spark, вы будете полностью использовать кластер. Начните с этого руководства , чтобы узнать, как работать с Spark.
Драйвер перегружен
Чтобы определить, перегружен ли драйвер, необходимо просмотреть метрики кластера.
Если кластер находится в DBR 13.0 или более поздней версии, щелкните Метрики , как выделено на этом снимке экрана:
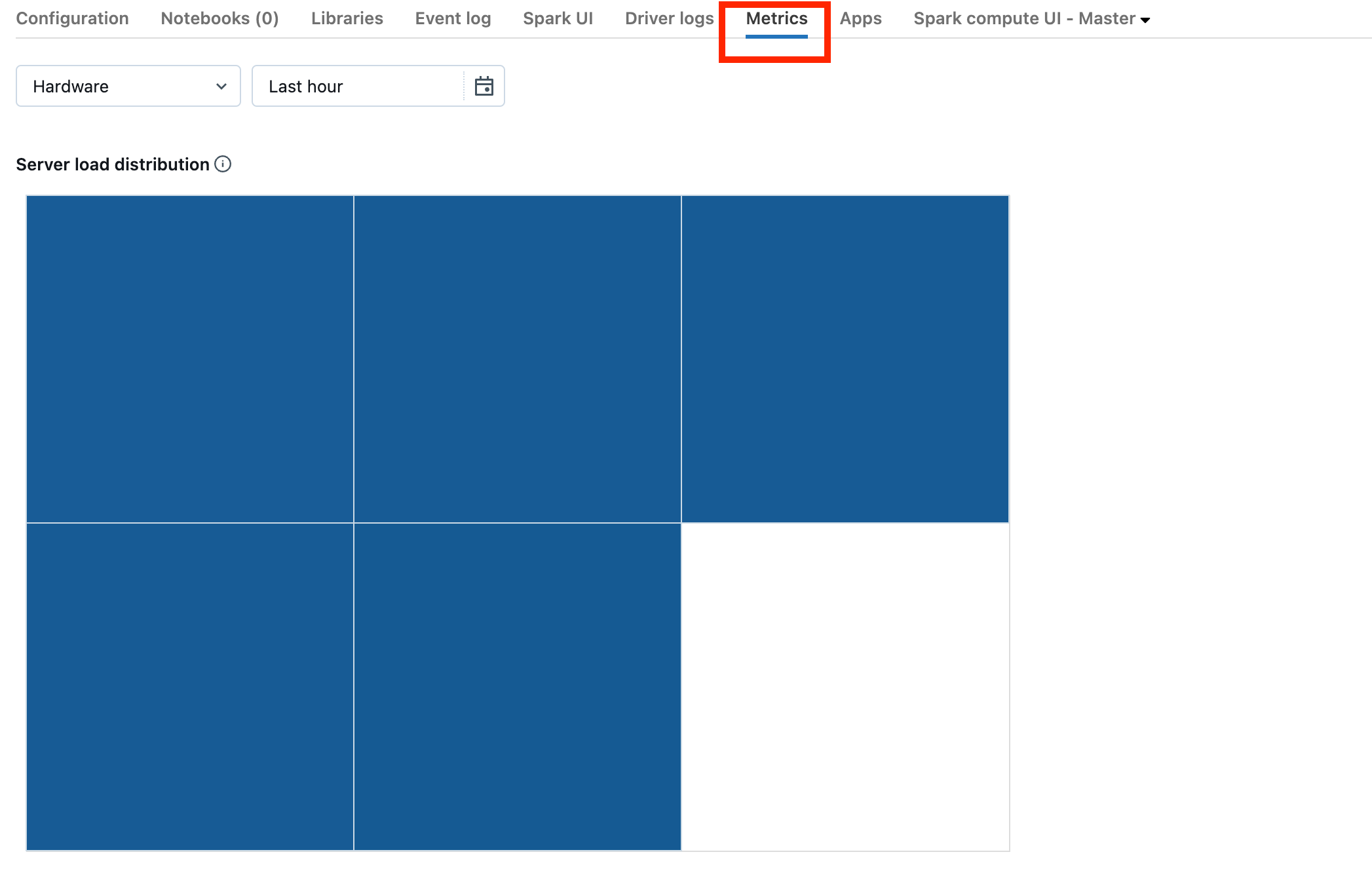
Обратите внимание на визуализацию распределения нагрузки сервера. Необходимо проверить, загружен ли драйвер. Эта визуализация имеет блок цвета для каждого компьютера в кластере. Красный означает сильно загруженную, и синий означает, что не загружено вообще.
На предыдущем снимка экрана показан простой кластер. Если драйвер перегружен, он будет выглядеть примерно так:
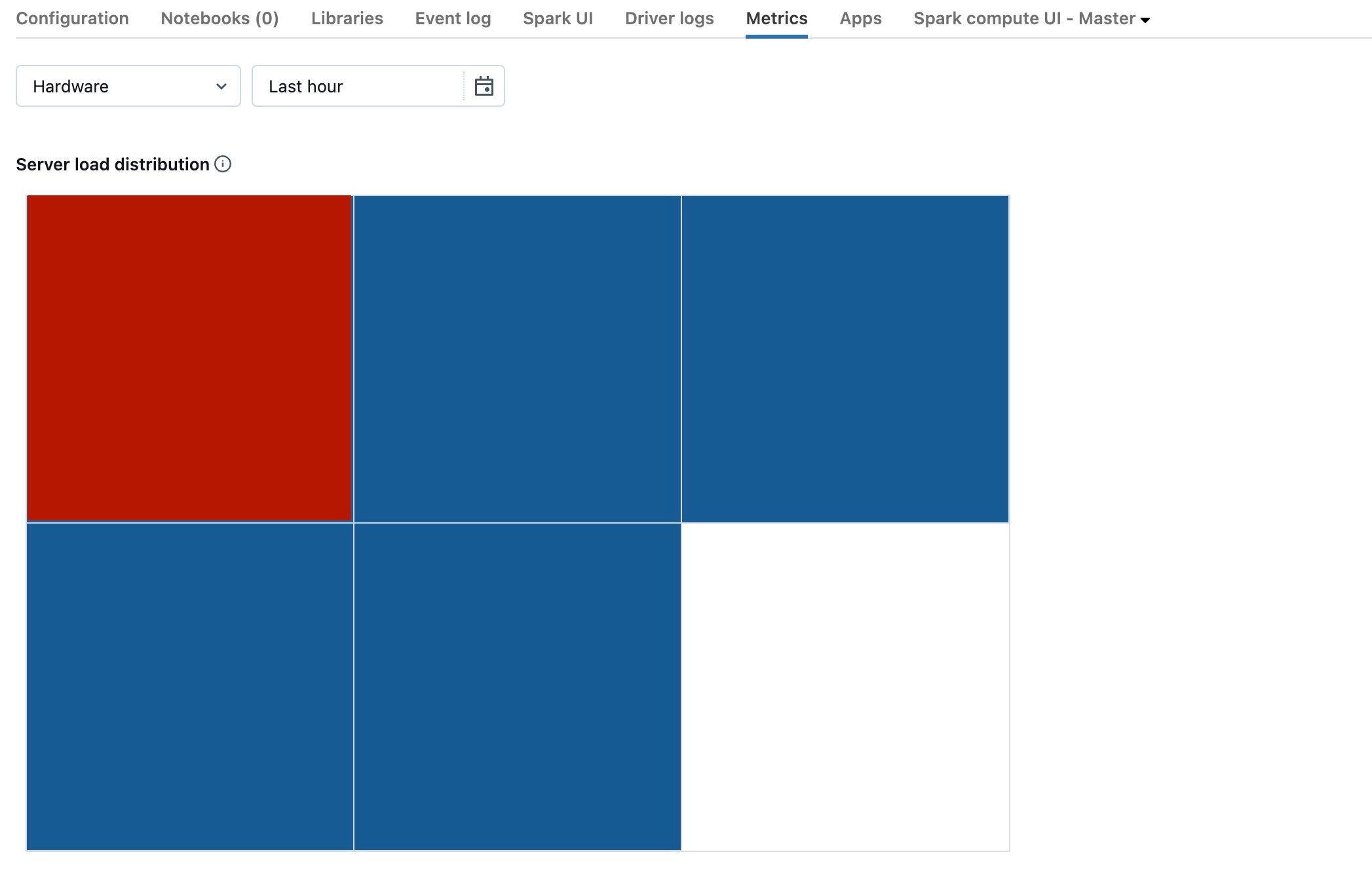
Мы видим, что один квадрат красный, а остальные — синие. Наведите указатель мыши на красный квадрат, чтобы убедиться, что красный блок представляет драйвер.
Сведения об исправлении перегруженного драйвера см. в статье о перегруженном драйвере Spark.
Кластер неисправен
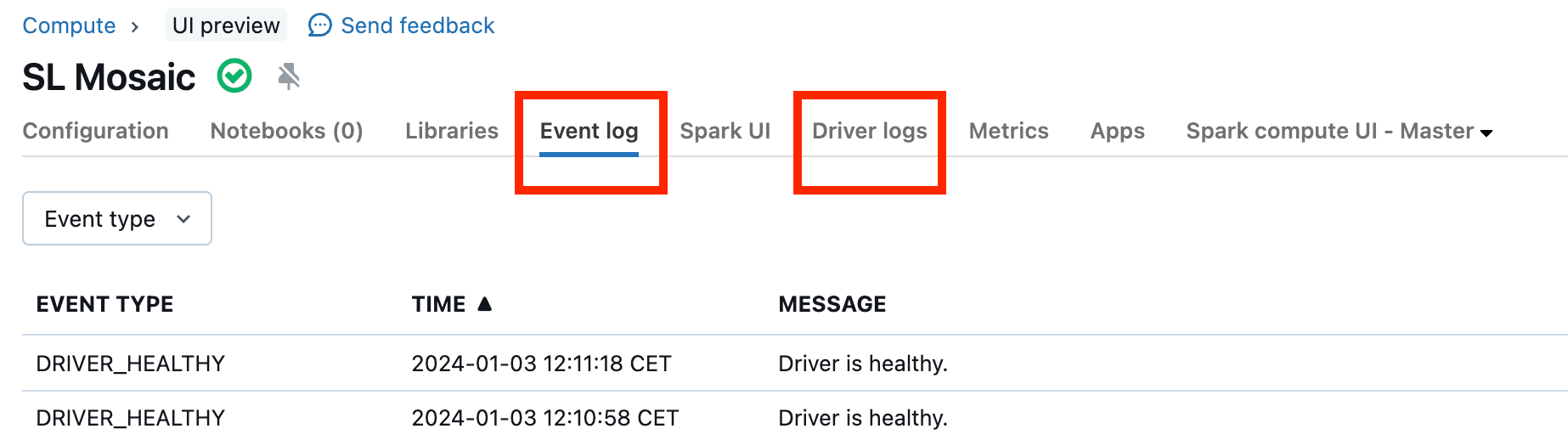
Неисправные кластеры редки, но если это так, может быть трудно определить, что произошло. Возможно, вы просто хотите перезапустить кластер, чтобы узнать, устранена ли проблема. Вы также можете просмотреть журналы, чтобы узнать, есть ли что-либо подозрительное. Вкладка "Журнал событий" и вкладки "Журналы драйверов", выделенные на снимке экрана ниже, будут выглядеть следующим образом:
Чтобы получить доступ к журналам рабочих ролей, может потребоваться включить доставку журналов кластера. Вы также можете изменить уровень журнала, но вам может потребоваться обратиться к группе учетных записей Databricks для получения справки.