Начало работы. Запрос и визуализация данных из записной книжки
В этой статье описано, как использовать записную книжку Azure Databricks для запроса примеров данных, хранящихся в каталоге Unity, с помощью SQL, Python, Scala и R, а затем визуализировать результаты запроса в записной книжке.
Требования
Чтобы выполнить задачи в этой статье, необходимо выполнить следующие требования:
- Рабочая область должна включать каталог Unity. Сведения о начале работы с каталогом Unity см. в разделе "Настройка каталога Unity" и управление ими.
- Необходимо иметь разрешение на использование существующего вычислительного ресурса или создать новый вычислительный ресурс. Ознакомьтесь с начните работу с Azure Databricks или свяжитесь с вашим администратором Databricks.
Шаг 1. Создание записной книжки
Чтобы создать записную книжку в рабочей области, нажмите кнопку ![]() "Создать" на боковой панели и нажмите кнопку "Записная книжка". Пустая записная книжка открывается в рабочей области.
"Создать" на боковой панели и нажмите кнопку "Записная книжка". Пустая записная книжка открывается в рабочей области.
Дополнительные сведения о создании записных книжек и управлении ими см. в статье Управление записными книжками.
Шаг 2. Запрос таблицы
Запросите таблицу samples.nyctaxi.trips в каталоге Unity с помощью выбранного языка.
Скопируйте и вставьте следующий код в новую пустую ячейку записной книжки. Этот код отображает результаты запроса
samples.nyctaxi.tripsтаблицы в каталоге Unity.SQL
SELECT * FROM samples.nyctaxi.tripsPython
display(spark.read.table("samples.nyctaxi.trips"))Scala
display(spark.read.table("samples.nyctaxi.trips"))R
library(SparkR) display(sql("SELECT * FROM samples.nyctaxi.trips"))Нажмите
Shift+Enter, чтобы запустить ячейку, а затем перейдите к следующей ячейке.Результаты запроса отображаются в записной книжке.
Шаг 3. Отображение данных
Отображение средней суммы тарифа по расстоянию поездки, сгруппированную по zip-коду пикапа.
Рядом с вкладкой "Таблица " щелкните + и щелкните " Визуализация".
Откроется редактор визуализации.
В раскрывающемся списке " Тип визуализации" убедитесь, что выбрана панель .
Выберите
fare_amountдля столбца X.Выберите
trip_distanceстолбец Y.Выберите
Averageв качестве типа агрегирования.Выберите
pickup_zipв качестве группы по столбцу.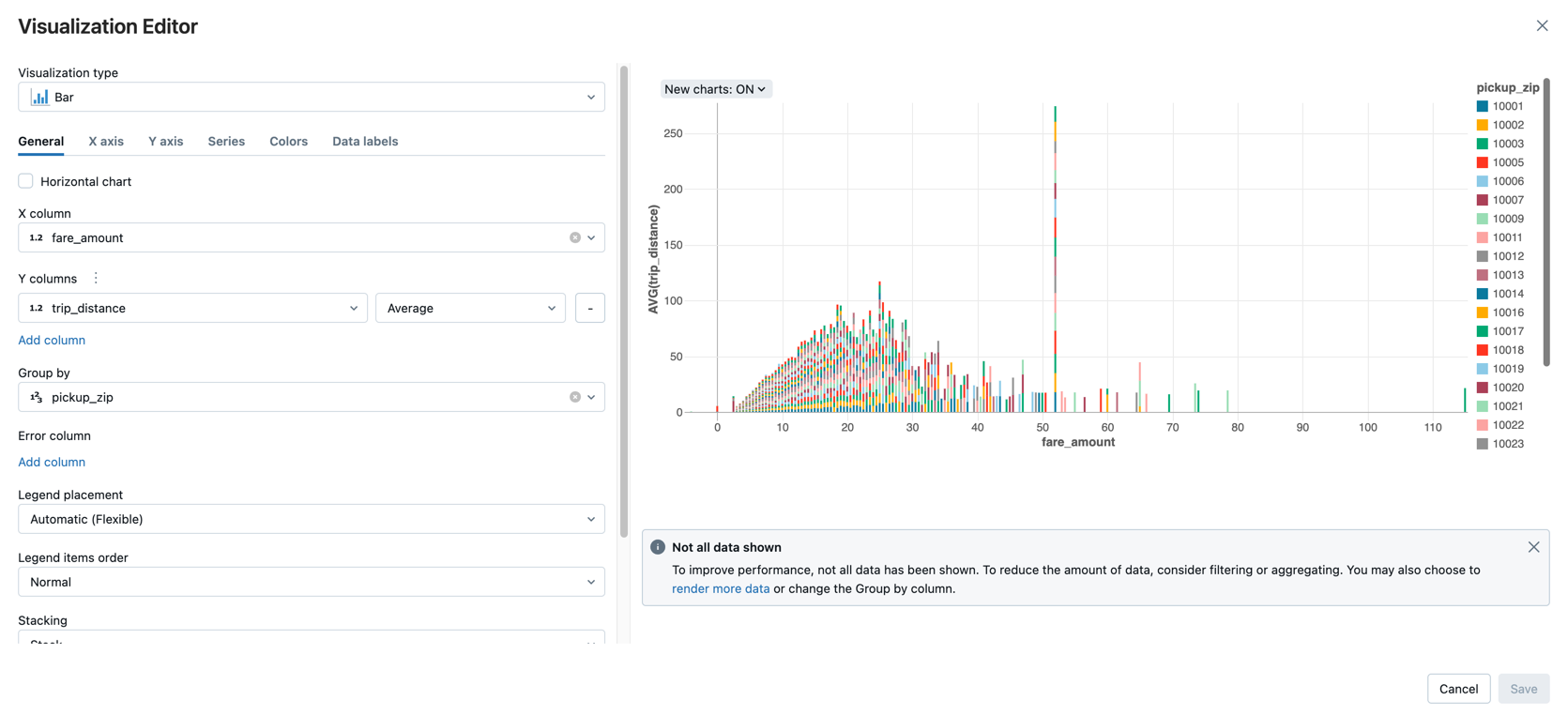
Нажмите кнопку Сохранить.
Следующие шаги
- Сведения о добавлении данных из CSV-файла в каталог Unity и визуализации данных см. в статье "Начало работы: импорт и визуализация CSV-данных из записной книжки".
- Сведения о загрузке данных в Databricks с помощью Apache Spark см. в руководстве по загрузке и преобразованию данных с помощью кадров данных Apache Spark.
- Дополнительные сведения о приеме данных в Databricks см . в разделе "Прием данных" в lakehouse Databricks.
- Дополнительные сведения о запросе данных с помощью Databricks см. в статье "Запрос данных".
- Дополнительные сведения о визуализациях см. в разделе "Визуализации" в записных книжках Databricks.